【项目实战】pytorch实现逻辑斯蒂回归
视频指导:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6
一些数据集
在pytorch框架下,里面面有配套的数据集,pytorch里面有一个torchversion的包,他可以提供相应的,比如MNIST这种很基础的数据集,但是安装的时候这些数据集不会包含在包里面,所以需要下载,具体代码以及解释如下:
import torchvision
train_set = torchvision.datasets.MNIST(root= '../dataset/mnist', train=True, download=True) //root后面表示把数据集安装在什么位置,train表示是要训练集还是测试集,download表示是否需要下载(如果没有下载就需要下载)
text_set = torchvision.datasets.MNIST(root= '../dataset/mnist', train=False, download=True)
还有一个叫做CIFAR-10 的数据集,训练集里面包含了5w个样本,测试集包含了1w个样本,内容就是一些图片,被分成了十类,分别表示不同的事务
import torchvision
train_set = torchvision.datasets.CIFAR10(...)
text_set = torchvision.datasets.CIFAR10(...)
逻辑斯蒂回归
首先我们自己设计几个数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
然后开始设计模型
class LogisiticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisiticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self,x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
这里和昨天不一样的地方在于forward里面使用了逻辑斯蒂回归
然后是优化器和损失函数
model = LogisiticRegressionModel()
critertion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
损失函数采用的是BCE,就是交叉熵损失
开始训练
for epoch in range(1000):
y_pred = model(x_data)
loss = critertion(y_pred,y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果可视化
用matplotlib进行绘图可以使结果可视化,具体代码和解释如下
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) //意思就是在0到10之间弄出来两百个点
x_t = torch.Tensor(x).view((200, 1)) //把他变成200行一列的矩阵
y_t = model(x_t) //送入模型
y = y_t.data.numpy() //用numpy接收y_data的数据
plt.plot(x, y) //绘图
plt.plot([0, 10], [0.5, 0.5], c='r') //表示在0到10,0.5到0.5上面画一条线(显然是一条直线)
plt.ylabel('probability of pass')
plt.grid()
plt.show()
总结
第一遍跑有一个警告
UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead. warnings.warn
查了一下,把
F.sigmoid(self.hidden(x))
#修改成以下语句
torch.sigmoid(self.hidden(x))
即可
估计是版本问题吧
然后我有魔改了一下代码,具体如下
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisiticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisiticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self,x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisiticRegressionModel()
critertion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(50000):
y_pred = model(x_data)
loss = critertion(y_pred,y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 100, 2000)
x_t = torch.Tensor(x).view((2000, 1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 100], [0.5, 0.5], c='r')
plt.xlabel('hours')
plt.ylabel('pass')
plt.grid()
plt.show()
最后的结果,我愿称之为,过拟合之王
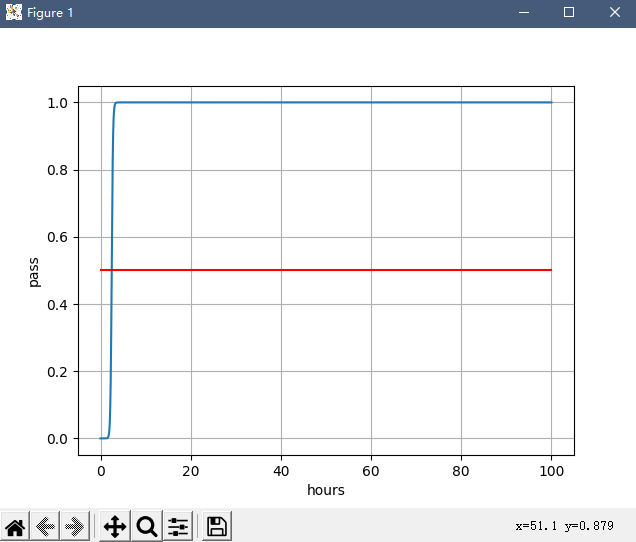
哈哈哈哈哈,很有意思
- 总之整个代码编写就分这几步:
- 准备数据;
- 设计模型;
- 构造损失函数和优化器;
- 训练过程;
- 打印结果
熟悉了就可以搞出自己的模型了
本文来自博客园,作者:Lugendary,转载请注明原文链接:https://www.cnblogs.com/lugendary/p/16135497.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号