【项目实战】用Pytorch实现线性回归
视频教程:https://www.bilibili.com/video/BV1Y7411d7Ys?p=5
准备数据#
首先配置了环境变量,这里使用python3.9.7版本,在Anaconda下构建环境运行,并且安装pytorch
决定使用模型y=wx+b
然后根据视频在pycharm中输入如下代码
import torch
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[2.0],[4.0],[6.0]])
首先这里预期使用小批量梯度下降
而在使用numpy的时候会有广播机制存在,会自动把不能相加的矩阵直接扩充广播成相同大小,而我们的Tensor构造的时候就需要注意了,我们必须要保证我们构造的数据一开始就是矩阵,所以必须用[1.0],[2.0],[3.0]的方法来进行构造
设计模型#
在pytorch中目标不再是人工求出导数,重点变成了构造计算图
构造计算图首先要知道X的维度,还需要知道输出的y是几维的,这样就可以确定w权重以及b偏值的形状
这样就可以输入x,经过w和b计算出y,再由y算出算是loss,由loss调用反向传播,拿到所有损失还需要求和求均值,否则无法反向传播
首先要把我们的模型定义成一个类,而我们在构造模型的时候使用的都是这样一个模板,必须掌握这样的一个编写方式
class LinearModel(torch.nn.Module): //所有编写的模型都要记成Module,这里面有很多方法,要从这个模块里面把继承下来
//类里面至少要有两个函数,一个是init,属于构造函数,还有一个forward函数(必须叫这个),而module里面会根据计算图自动帮你实现反向传播过程,如果你觉得他的计算效率不高,你也可以用torch里面的一个function类来构造自己的计算方法
def __init__(self):
super(LinearModel,self).__init__() //调用父类的构造
self.Linear = torch.nn.Linear(1, 1) //torch.nn.Linear是torch里面的一个类,这里是构造一个对象,这里包含了权重和偏置
def forward(self,x):
y_pred = self.Linear(x) //这里表示实现一个可调用的对象
return y_pred
model1 = LinearModel()
这里给出class torch.nn.Linear的具体文档

这里的size表示维度,这里的bias是一个布尔类型,来决定你是否需要偏置量(默认是ture)
构造损失函数和优化器#
criterion = torch.nn.MSELoss(size_average=False) //size.average表示最后是否需要求均值
optimizer = torch.optim.SGD(model1.parameters(),lr=0.01) //parameters可以把模型中所有的参数全部找出来,lr就是学习率,而这个optimizer,他就知道需要对哪些东西做优化
训练过程#
for epoch in range(100):
y_pred = model1(x_data) //先算出y
loss = criterion(y_pred,y_data) //利用criterion算出损失函数
print(epoch, loss.item()) //打印出来
optimizer.zero_grad() //先梯度归零
loss.backward() //反向传播
optimizer.step() //更新参数
打印结果#
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_text = model(x_test)
print('y_pred=', y_text.data)
一开始给我报错
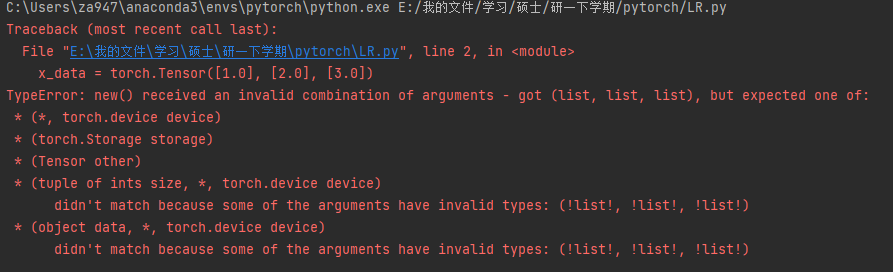
原来最上面X,Y赋值少了一对中括号,导致识别不出来
然后成功跑出!
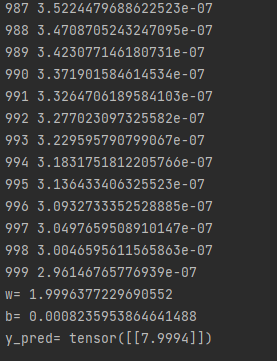
输入4,1000次迭代输出7.9994,很不错了
然后我们修改一下,加一个数据4和8,然后输入10,训练2000次
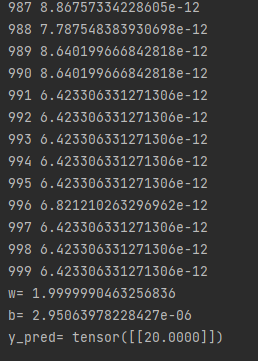
帅的嘛不谈了!
完整代码如下:
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0], [4.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0], [8.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=', model.linear.weight.item())
print('b=', model.linear.bias.item())
x_test = torch.Tensor([[10.0]])
y_text = model(x_test)
print('y_pred=', y_text.data)
打算修改步长再试试
后记:果然学习率设置过程就是炼丹
作者:Lugendary
出处:https://www.cnblogs.com/lugendary/p/16130630.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
本博文版权归Lugendary所有,未经授权不得转载




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异