【学习笔记】循环神经网络(RNN)
前言
多方寻找视频于博客、学习笔记,依然不能完全熟悉RNN,因此决定还是回到书本(《神经网络与深度学习》第六章),一点点把啃下来,因为这一章对于整个NLP学习十分重要,我想打好基础。
当然,依然感谢这个视频对我理解RNN的帮助,链接在此: https://www.bilibili.com/video/BV1z5411f7Bm?spm_id_from=333.337.search-card.all.click
循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络.在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构
循环神经网络的参数学习可以通过随时间反向传播算法来学习.随时间反向传播算法即按照时间的逆序将错误信息一步步地往前传递.当输入序列比较长时,会存在梯度爆炸和消失问题,也称为长程依赖问题.为了解决这个问题,人们对循环神经网络进行了很多的改进,其中最有效的改进方式引入门控机制.
给网络增加记忆能力#
延时神经网络#
一种简单的利用历史信息的方法是建立一个额外的延时单元,用来存储网络的历史信息(可以包括输入、输出、隐状态等).比较有代表性的模型是延时神经网络,延时神经网络是在前馈网络中的非输出层都添加一个延时器,记录神经元的最近几次活性值.在第 t 个时刻,第 𝑙 层神经元的活性值依赖于第 𝑙 − 1 层神经元的最近𝐾 个时刻的活性值
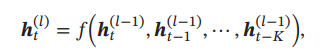
表示H在t时刻l层H的活性值与H在最近k个时刻上一层的激活值h(l-1)建立函数关系
通过延时器,前馈网络就具有了短期记忆的能力
有外部输入的非线性自回归模型#
-
自回归模型是统计学上常用的一类时间序列模型,用一个变量𝒚𝑡 的历史信息来预测自己.
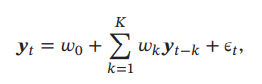
超参数K指的是最近K个时刻,w是可学习参数,后面的y是代表y在各个时刻的取值,最后一项是噪声 -
有外部输入的非线性自回归模型是自回归模型的扩展,在每个时刻𝑡 都有一个外部输入𝒙𝑡,产生一个输出𝒚𝑡.NARX通过一个延时器记录最近𝐾𝑥 次的外部输入和最近𝐾𝑦 次的输出
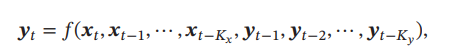
这里就代表我y的值不仅仅和我之前每个时刻y值有关,还和我外界输入的x各个时刻的值有关系
循环神经网络#
循环神经网络(Recurrent Neural Network,RNN)通过使用带自反馈的神经元,能够处理任意长度的时序数据.
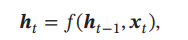
这里x指的是输入序列,第一个h代表当前时刻的活性值,第二个代表第t-1个时刻的活性值,包在外面的f,就可以是一个前馈网络了
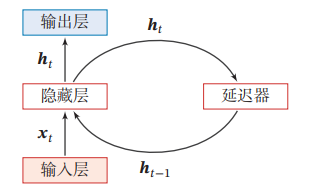
延时器就是一个虚拟单元,记录神经元最近一次或几次(取决于超参数)活性值
由于循环神经网络具有短期记忆能力,相当于存储装置,因此其计算能力十分强大.理论上,循环神经网络可以近似任意的非线性动力系统.前馈神经网络可以模拟任何连续函数,而循环神经网络可以模拟任何程序.
简单循环网络#
简单循环网络是一个非常简单的循环神经网络,只有一个隐藏层的神经网络.在一个两层的前馈神经网络中,连接存在相邻的层与层之间,隐藏层的节点之间是无连接的.而简单循环网络增加了从隐藏层到隐藏层的反馈连接.简而言之就是我不仅在这一层考虑上一层的输出,还考虑上一层节点的活性值
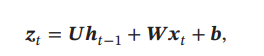
从上式可以看出,原来的公式基础上,增加了Uh(t-1),这里U代表一个可以学习的状态权重矩阵
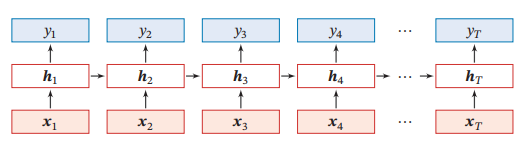
如果我们把每个时刻的状态都看作前馈神经网络的一层,循环神经网络可以看作在时间维度上权值共享的神经网络
应用到机器学习#
循环神经网络可以应用到很多不同类型的机器学习任务.根据这些任务的特点可以分为以下几种模式:序列到类别模式、同步的序列到序列模式、异步的序列到序列模式.
序列到类别模式#
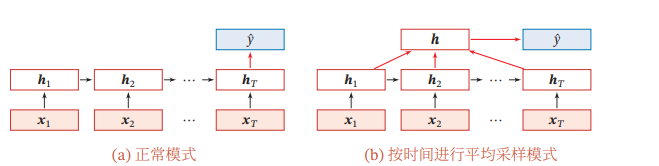
假设有一个样本X是一个长度为T的序列,就可以把X按照不同时刻输入到循环神经网络中,并得到到不同时刻的隐藏状态h1,h2,....,ht,那我们可以把ht看作整个序列的最终表示,并且输入给分类器分类,也可以对整个序列所有状态进行平均,并用这个平均状态作为整个序列的表示
同步的序列到序列模式#
同步的序列到序列模式主要用于序列标注(Sequence Labeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同.比如在词性标注(Part-of-Speech Tagging)中,每一个单词都需要标注其对应的词性标签.
在同步的序列到序列模式中,输入一个长度为T的序列X1,输出为Y1,样本X按照不同时刻输入到循环神经网络中,并得到不同时刻的隐状态h1,h2....,每个时刻的h状态都代表了当前时刻和历史的信息,并输入给分类器得到当前时刻的标签
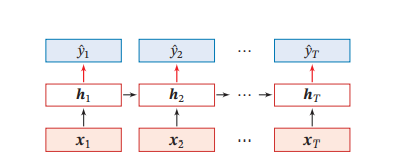
异步的序列到序列模式#
异步的序列到序列模式也称为编码器-解码器(Encoder-Decoder)模型,即输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度.比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列.
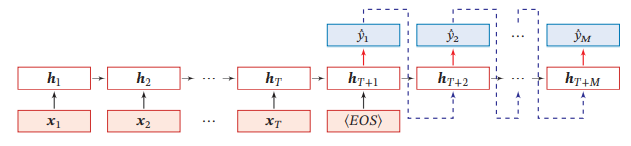
比如输入长度为T的序列X,输出长度为M的序列Y,异步的序列到序列模式会先编码再解码。先把X按照不同时刻输入到一个循环神经网络,得到Ht,然后用另一个循环神经网络得到输出序列Ym,

图给出了异步的序列到序列模式示例,其中⟨𝐸𝑂𝑆⟩表示输入序列的结束,虚线表示将上一个时刻的输出作为下一个时刻的输入.
参数学习#
整个序列的损失函数ℒ关于参数𝑼 的梯度为
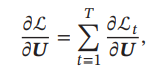
循环神经网络中存在一个递归调用的函数 𝑓(⋅),因此其计算参数梯度的方式和前馈神经网络不太相同.在循环神经网络中主要有两种计算梯度的方式:随时间反向传播(BPTT)算法和实时循环学习(RTRL)算法.
随时间反向传播算法#
随时间反向传播(BackPropagation Through Time,BPTT)算法的主要思想是通过类似前馈神经网络的误差反向传播算法来计算梯度
BPTT算法将循环神经网络看作一个展开的多层前馈网络,其中“每一层”对应循环网络中的“每个时刻”.这样,循环神经网络就可以按照前馈网络中的反向传播算法计算参数梯度.在“展开”的前馈网络中,所有层的参数是共享的,因此参数的真实梯度是所有“展开层”的参数梯度之和.
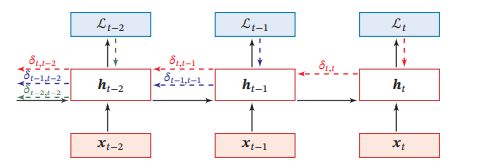
在BPTT算法中,参数的梯度需要在一个完整的“前向”计算和“反向”计算后才能得到并进行参数更新.
实时循环学习算法#
与反向传播的 BPTT 算法不同的是,实时循环学习(Real-Time RecurrentLearning,RTRL)是通过前向传播的方式来计算梯度
这一部分内容实在是太抽象了,我的理解就是,用比较复杂的手段,和前馈一样老老实实计算每个参数的梯度并更新
- 两种算法比较 :RTRL算法和BPTT算法都是基于梯度下降的算法,分别通过前向模式和反向模式应用链式法则来计算梯度.在循环神经网络中,一般网络输出维度远低于输入维度,因此 BPTT 算法的计算量会更小,但是 BPTT 算法需要保存所有时刻的中间梯度,空间复杂度较高.RTRL算法不需要梯度回传,因此非常适合用于需要在线学习或无限序列的任务中.
长程依赖问题#
循环神经网络在学习过程中的主要问题是由于梯度消失或爆炸问题,很难建模长时间间隔(Long Range)的状态之间的依赖关系.
虽然简单循环网络理论上可以建立长时间间隔的状态之间的依赖关系,但是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系.这样,如果时刻 𝑡 的输出 𝑦𝑡 依赖于时刻 𝑘 的输入 𝒙𝑘,当间隔 𝑡 − 𝑘 比较大时,简单神经网络很难建模这种长距离的依赖关系,称为长程依赖问题
改进方案#
为了避免梯度爆炸或消失问题,一种最直接的方式就是选取合适的参数,同时使用非饱和的激活函数,尽量使得diag(𝑓′(𝒛))𝑼T ≈ 1,这种方式需要足够的人工调参经验,限制了模型的广泛应用.比较有效的方式是通过改进模型或优化方法来缓解循环网络的梯度爆炸和梯度消失问题
- 梯度爆炸:一般而言,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断来避免
- 梯度消失:梯度消失是循环网络的主要问题.除了使用一些优化技巧外,更有效的方式就是改变模型
但是各种优化方法依然存在很多问题,为了解决这些问题,可以通过引入门控机制来进一步改进模型
基于门控的循环神经网络#
为了改善循环神经网络的长程依赖问题,一种非常好的解决方案是在基础上引入门控机制来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息.这一类网络可以称为基于门控的循环神经网络(Gated RNN).本节中,主要介绍两种基于门控的循环神经网络:长短
期记忆网络和门控循环单元网络.
长短期记忆网络#
书上对于LSTM的描述过于专业和抽象了,我简单描述一下就是在原来的RNN基础上,本来他可以让超参数K很大,这样可以记住很长时间的东西,但是这样会导致梯度消失或者梯度爆炸,那么我怎样才能让K很大呢,我加入一个筛选机制,专业点叫做门控机制,我把要记住的按权重留下,不要的直接丢掉,这就是lstm。
LSTM网络引入一个新的内部状态(internal state)𝒄𝑡 ∈ ℝ𝐷 专门进行线性的循环信息传递,同时(非线性地)输出信息给隐藏层的外部状态𝒉𝑡 ∈ ℝ𝐷.内部状态𝒄𝑡 通过下面公式计算:
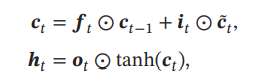
在每个时刻𝑡,LSTM网络的内部状态𝒄𝑡 记录了到当前时刻为止的历史信息
遗忘门𝒇𝑡 控制上一个时刻的内部状态𝒄𝑡−1 需要遗忘多少信息.
输入门𝒊𝑡 控制当前时刻的候选状态𝒄̃𝑡 有多少信息需要保存.
输出门 𝒐𝑡 控制当前时刻的内部状态 𝒄𝑡 有多少信息需要输出给外部状态𝒉𝑡.
LSTM 网络的循环单元结构,计算过程为:
1)首先利用上一时刻的外部状态𝒉𝑡−1 和当前时刻的输入𝒙𝑡,计算出三个门,以及候选状态𝒄̃𝑡;
2)结合遗忘门 𝒇𝑡 和输入门 𝒊𝑡 来更新记忆单元 𝒄𝑡;
3)结合输出门 𝒐𝑡,将内部状态的信息传递给外部状态𝒉𝑡.
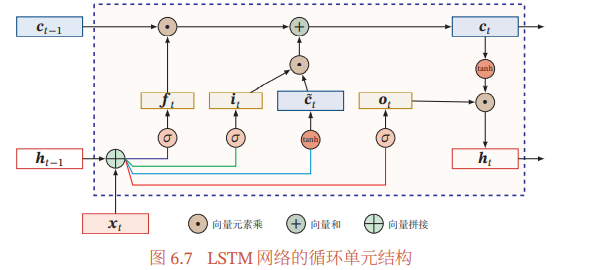
(这图我也看不懂,不过问题不大)
- 注意:一般在深度网络参数学习时,参数初始化的值一般都比较小.但是在训练 LSTM 网络时,过小的值会使得遗忘门的值比较小.这意味着前一时刻的信息大部分都丢失了,这样网络很难捕捉到长距离的依赖信息.并且相邻时间间隔的梯度会非常小,这会导致梯度弥散问题.因此遗忘的参数初始值一般都设得比较大,其偏置向量𝒃𝑓 设为1或2.
门控循环单元网络#
门控循环单元(Gated Recurrent Unit,GRU)网络 是一种比LSTM网络更加简单的循环神经网络.
GRU 网络引入门控机制来控制信息更新的方式.和 LSTM 不同,GRU 不引入额外的记忆单元,GRU网络是在基础上引入一个更新门(Up-date Gate)来控制当前状态需要从历史状态中保留多少信息(不经过非线性变换),以及需要从候选状态中接受多少新信息,在LSTM网络中,输入门和遗忘门是互补关系,具有一定的冗余性.GRU网络直接使用一个门来控制输入和遗忘之间的平衡
GRU网络的状态更新方式为
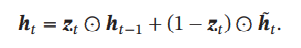
所以简单来说,GRU就是用了点数学知识,使得我们的模型比LSTM参数更少,计算起来也就更方便,速度更快
小结
终于啃完,其中的兴奋和成就感无以言表,果然不能畏难,对于不懂得问题多查多看多想,不行就手写去试图理解每一个字母,每一个式子,每一个字的含义,终会有所收获!最近学习状态真的很好,明天准备attention机制!
本来打算明天开始pytorch的,但是还是觉得不急,先搞完这本书,再去看cs224n,在开始实战,我觉得这样很好,很符合认知路径!
作者:Lugendary
出处:https://www.cnblogs.com/lugendary/p/16096716.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
本博文版权归Lugendary所有,未经授权不得转载




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?