【学习笔记】卷积神经网络 (CNN )
前言
对于卷积神经网络(cnn)这一章不打算做数学方面深入了解,所以只是大致熟悉了一下原理和流程,了解了一些基本概念,所以只是做出了一些总结性的笔记。
感谢B站的视频 https://www.bilibili.com/video/BV1j7411f7Ru?spm_id_from=333.337.search-card.all.click
很不错的讲解
全连接神经网络的缺点
两个神经元,为了求出隐藏层和输出层最佳的(w,b),我们就要求四个偏导,期间还得为链式求导付出3次连乘的代价。倘若我们的网络层次越深,偏导连乘也就越多,付出的计算代价也就越大。紧接着,一个网络层不单止一个神经元,它可能会有多个神经元,那么多个神经元的输出作为下一级神经元的输入时,就会形成多个复杂的嵌套关系
卷积层
如果信息过于冗余,那么我们能否去除冗余取出精华部分呢?卷积层就是干这个的,通俗易懂来说就是压缩提纯。
卷积核是怎么工作呢,我们可以把蓝色矩阵看做卷积层的上一层,绿色矩阵看做卷积层,在蓝色矩阵上蠕动的便是卷积核。卷积核通过与他所覆盖蓝色矩阵的一部分进行卷积运算,然后把结果映射到绿色矩阵中。
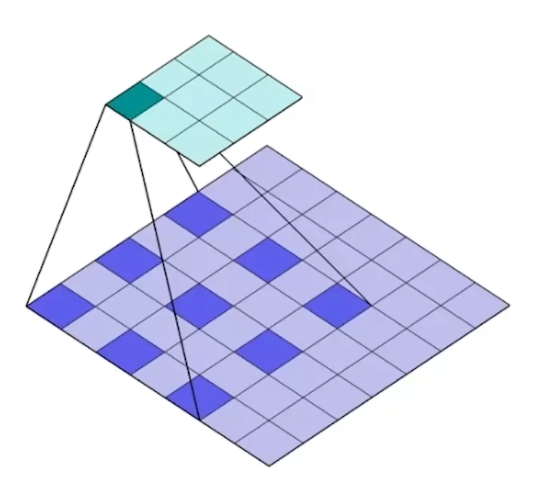
卷积核在滑动过程中做的卷积运算就是卷积核w与其所覆盖的区域的数进行点积,最后将结果映射到卷积层
卷积层的工作方式,就是个压缩提纯的过程,而且每个卷积层不单止一个卷积核,它是可以多个的,所以大家会看到输出的特征图在“变胖”,因为特征图的上一级经过多个卷积核压缩提纯,每个卷积核对应一层,多层叠加就会“变胖”。
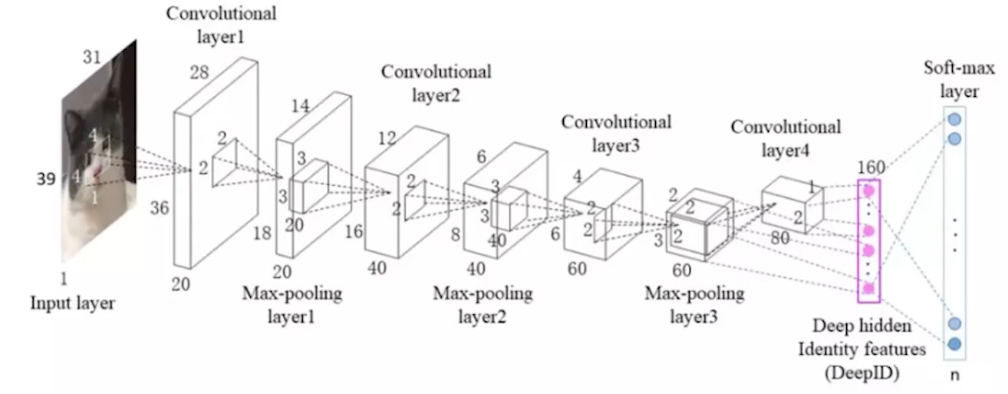
局部连接和权值共享
全连接神经网络的局限性在于它的网络层与层之间是全连接的,这就导致了整个训练过程要更新多对(w,b)为此CNN特定引入了局部连接和权值共享的两个特性,来减少训练的计算量。重点看权值共享这张图,它同时也采用了局部连接,总共就有3*4=12个权值,再加上权值共享,我们就只用求3个权值了,大大减少了我们的计算量。
池化层
般来说,卷积层后面都会加一个池化层,可以将它理解为对卷积层输出的特征图进一步特征抽样,池化层主要分为两种:
- Max pooling(最大池化) 就是在方块中直接选数值最大的方块投射到另一个矩阵中
- Average pooling(平均池化) 就是在方块中计算出所有包含值的平均值投射到另一个矩阵中
卷积网络的整体结构
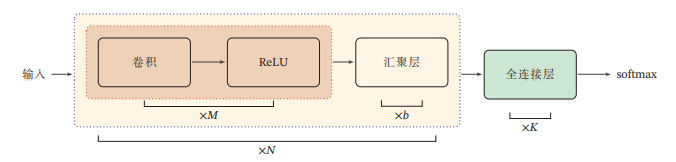
一个典型的卷积网络是由卷积层、汇聚层、全连接层交叉堆叠而成.目前常用的卷积网络整体结构如图所示.一个卷积块为连续M个卷积层和b个汇聚层(M通常设置为25,b为0或1).一个卷积网络中可以堆叠N个连续的卷积块,然后在后面接着K个全连接层(N的取值区间比较大,比如1100或者更大;K一般为0~2)
目前,卷积网络的整体结构趋向于使用更小的卷积核(比如 1 × 1 和 3 × 3)以及更深的结构(比如层数大于 50).此外,由于卷积的操作性越来越灵活(比如不同的步长),汇聚层的作用也变得越来越小,因此目前比较流行的卷积网络中,汇聚层的比例正在逐渐降低,趋向于全卷积网络.
几种典型的卷积神经网络
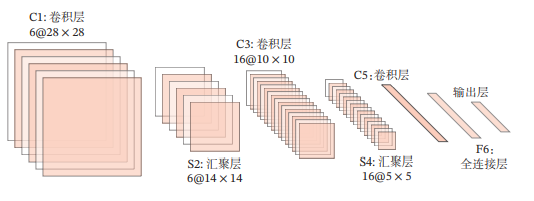
- LeNet-5
LeNet-5虽然提出的时间比较早,但它是一个非常成功的神经网络模型.基于LeNet-5的手写数字识别系统在 20世纪90 年代被美国很多银行使用,用来识别支票上面的手写数字.LeNet-5的网络结构如图
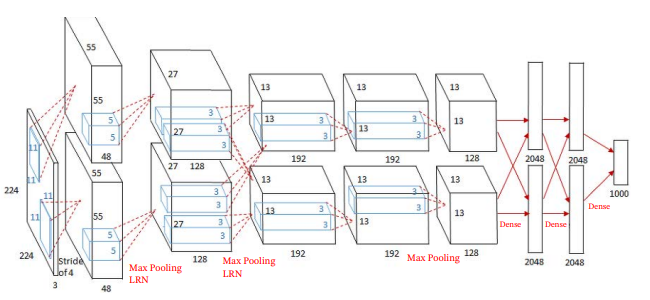
- AlexNet
AlexNet是第一个现代深度卷积网络模型,其首次使用了很多现代深度卷积网络的技术方法,比如使用 GPU 进行并行训练,采用了ReLU作为非线性激活函数,使用Dropout防止过拟合,使用数据增强来提高模型准确率等.AlexNet赢得了2012年ImageNet图像分类竞赛的冠军.AlexNet的结构如图所示,包括5个卷积层、3个汇聚层和3个全连接层(其中最后一层是使用 Softmax 函数的输出层).因为网络规模超出了当时的单个GPU的内存限制,AlexNet将网络拆为两半,分别放在两个GPU上,GPU间只在某些层(比如第3层)进行通信.
- Inception网络
在卷积网络中,如何设置卷积层的卷积核大小是一个十分关键的问题.在Inception 网络中,一个卷积层包含多个不同大小的卷积操作,称为Inception 模块.Inception网络是由有多个Inception模块和少量的汇聚层堆叠而成.Inception模块同时使用1 × 1、3 × 3、5 × 5等不同大小的卷积核,并将得到的特征映射在深度上拼接(堆叠)起来作为输出特征映射.
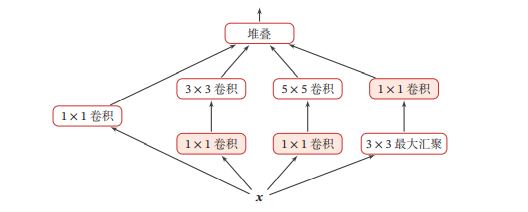
Inception 网络有多个版本,其中最早的 Inception v1 版本就是非常著名的GoogLeNet - 残差网络
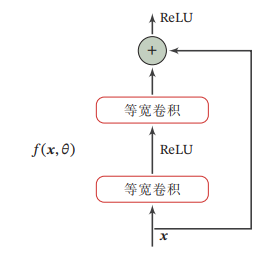
残差网络(Residual Network,ResNet)通过给非线性的卷积层增加直连边(Shortcut Connection)(也称为残差连接(Residual Connection))的方式来提高信息的传播效率假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层)f(x;O)去逼近一个目标函数为h(x).如果将目标函数拆分成两部分:恒等函数(Identity Function)x和残差函数(Residue Function)h(x)-x.
根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习 [He et al., 2016].因此,原来的优化问题可以转换为:让非线性单元𝑓(𝒙; 𝜃)去近似残差函数ℎ(𝒙) − 𝒙,并用𝑓(𝒙; 𝜃) + 𝒙去逼近ℎ(𝒙).
下面给出了一个典型的残差单元示例.残差单元由多个级联的(等宽)卷积层和一个跨层的直连边组成,再经过ReLU激活后得到输出.
小结
卷积神经网络其实是一个捷径,把大的图像变小,类似于我找电脑图片,不需要一张一张点开,只需要看缩略图就行了
目前卷积神经网络学习告一段落,打算开始进行一些实战,还没想好先开始pytorch还是先开始rnn
本文来自博客园,作者:Lugendary,转载请注明原文链接:https://www.cnblogs.com/lugendary/p/16093104.html

