【项目实战】天猫重复购买预测 数据探索
工具导入和数据读取
工具导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
数据读取
test_data = pd.read_csv('./data_format1/test_format1.csv') // 确定测试集
train_data = pd.read_csv('./data_format1/train_format1.csv') // 确定训练集
user_info = pd.read_csv('./data_format1/user_info_format1.csv') // 用户特征数据
user_log = pd.read_csv('./data_format1/user_log_format1.csv') // 商店数据
#user_info = pd.read_csv('./data_format1/user_info_format1.csv').drop_duplicates() // 删除用户特征数据中的重复项
#user_log = pd.read_csv('./data_format1/user_log_format1.csv').rename(columns={"seller_id":'merchant_id'}) // 把商店数据信息中的索引merchant_id改为seller_id
数据集样例查看
train_data.head(5)
| user_id | merchant_id | label |
|---|---|---|
| 0 | 34176 | 3906 |
| 1 | 34176 | 121 |
| 2 | 34176 | 4356 |
| 3 | 34176 | 2217 |
| 4 | 230784 | 4818 |
test_data.head(5)
| user_id | merchant_id | prob |
|---|---|---|
| 0 | 163968 | 4605 |
| 1 | 360576 | 1581 |
| 2 | 98688 | 1964 |
| 3 | 98688 | 3645 |
| 4 | 295296 | 3361 |
user_info.head(5)
| user_id | age_range | gender |
|---|---|---|
| 0 | 376517 | 6.0 |
| 1 | 234512 | 5.0 |
| 2 | 344532 | 5.0 |
| 3 | 186135 | 5.0 |
| 4 | 30230 | 5.0 |
user_log.head(5)
| user_id | item_id | cat_id | seller_id | brand_id | time_stamp | action_type |
|---|---|---|---|---|---|---|
| 0 | 328862 | 323294 | 833 | 2882 | 2661.0 | 829 |
| 1 | 328862 | 844400 | 1271 | 2882 | 2661.0 | 829 |
| 2 | 328862 | 575153 | 1271 | 2882 | 2661.0 | 829 |
| 3 | 328862 | 996875 | 1271 | 2882 | 2661.0 | 829 |
| 4 | 328862 | 1086186 | 1271 | 1253 | 1049.0 | 829 |
单变量数据分析
数据类型和数据大小
用户信息数据
- 数据集中共有2个float64类型和1个int64类型的数据
- 数据大小9.7MB
- 数据集共有424170条数据
用户行为数据 - 数据集中共有6个int64类型和1个float64类型的数据
- 数据大小2.9GB
- 数据集共有54925330条数据
用户购买训练数据 - 数据均为int64类型
- 数据大小6MB
- 数据集共有260864条数据
缺失值查看
年龄缺失
- 年龄值为空的缺失率为0.5%
- 年龄值缺失或者年龄值为缺省值0共计95131条数据
(user_info.shape[0]-user_info['age_range'].count())/user_info.shape[0] //这里count函数可以统计不为空的数据个数,shape函数可以统计数据样本的个数
user_info[user_info['age_range'].isna() | (user_info['age_range'] == 0)].count() //这里isna函数用于统计一个值是否为空,整句代码用于计算数据中年龄缺失或者为0的数据数目
user_info.groupby(['age_range'])[['user_id']].count() //这里groupby函数用于对数据的分组
性别缺失
- 性别值为空的缺失率 1.5%
- 性别值缺失或者性别为缺省值2共计95131条数据
(user_info.shape[0]-user_info['gender'].count())/user_info.shape[0]
user_info[user_info['gender'].isna() | (user_info['gender'] == 2)].count()
user_info.groupby(['gender'])[['user_id']].count()
年龄或者性别其中有一个有缺失
- 共计106330条数据
user_info[user_info['age_range'].isna() | (user_info['age_range'] == 0) | user_info['gender'].isna() | (user_info['gender'] == 2)].count()
用户行为日志信息
- brand_id字段有91015条缺失数据
user_log.isna().sum()
user_id 0
,item_id 0
,cat_id 0
,seller_id 0
,brand_id 91015
,time_stamp 0
,action_type 0
,dtype: int64
观察数据分布
整体数据统计信息
user_info.describe()
user_log.describe() //就是返回这两个核心数据结构的统计变量。其目的在于观察这一系列数据的范围、大小、波动趋势等等,为后面的模型选择打下基础
| user_id | age_range | gender |
|---|---|---|
| count | 424170.000000 | 421953.000000 |
| mean | 212085.500000 | 2.930262 |
| std | 122447.476179 | 1.942978 |
| min | 1.000000 | 0.000000 |
| 25% | 106043.250000 | 2.000000 |
| 50% | 212085.500000 | 3.000000 |
| 75% | 318127.750000 | 4.000000 |
| max | 424170.000000 | 8.000000 |
| user_id | item_id | cat_id | seller_id | brand_id | time_stamp | action_type |
|---|---|---|---|---|---|---|
| count | 5.492533e+07 | 5.492533e+07 | 5.492533e+07 | 5.492533e+07 | 5.483432e+07 | 5.492533e+07 |
| mean | 2.121568e+05 | 5.538613e+05 | 8.770308e+02 | 2.470941e+03 | 4.153348e+03 | 9.230953e+02 |
| std | 1.222872e+05 | 3.221459e+05 | 4.486269e+02 | 1.473310e+03 | 2.397679e+03 | 1.954305e+02 |
| min | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 5.110000e+02 |
| 25% | 1.063360e+05 | 2.731680e+05 | 5.550000e+02 | 1.151000e+03 | 2.027000e+03 | 7.300000e+02 |
| 50% | 2.126540e+05 | 5.555290e+05 | 8.210000e+02 | 2.459000e+03 | 4.065000e+03 | 1.010000e+03 |
| 75% | 3.177500e+05 | 8.306890e+05 | 1.252000e+03 | 3.760000e+03 | 6.196000e+03 | 1.109000e+03 |
| max | 4.241700e+05 | 1.113166e+06 | 1.671000e+03 | 4.995000e+03 | 8.477000e+03 | 1.112000e+03 |
查看正负样本的的分布
label_gp = train_data.groupby('label')['user_id'].count() //把标签为0和1的数目分别统计计算输出
print('正负样本的数量:\n',label_gp)
_,axe = plt.subplots(1,2,figsize=(12,6)) //指定画布大小
train_data.label.value_counts().plot(kind='pie',autopct='%1.1f%%',shadow=True,explode=[0,0.1],ax=axe[0]) //在第一张图上面画出扇形图
sns.countplot('label',data=train_data,ax=axe[1],) //在第二张图上面画出直方图
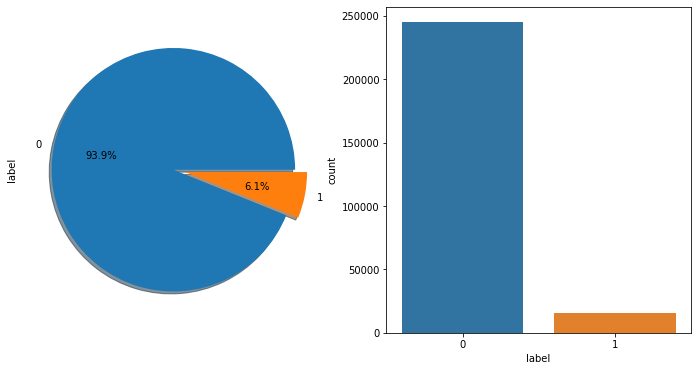
可以看出样本的分布不均衡,需要采取一定的措施处理样本不均衡的问题
探查店铺、用户、性别以及年龄对复购的影响
查看不同商家与复购的关系
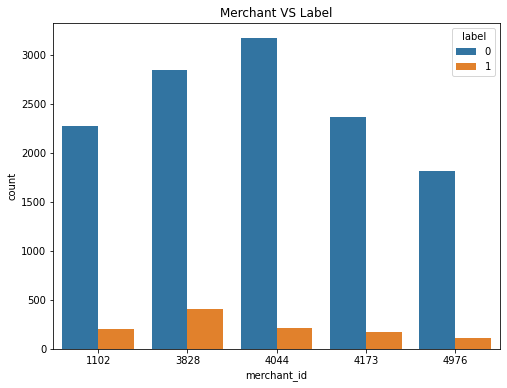
print('选取top5店铺\n店铺\t购买次数')
print(train_data.merchant_id.value_counts().head(5))
train_data_merchant = train_data.copy()
train_data_merchant['TOP5'] = train_data_merchant['merchant_id'].map(lambda x: 1 if x in [4044,3828,4173,1102,4976] else 0) //copy深拷贝父对象(一级目录),子对象(二级目录)不拷贝,子对象是引用,这里用一个匿名函数之传入top5店铺
train_data_merchant = train_data_merchant[train_data_merchant['TOP5']==1]
plt.figure(figsize=(8,6))
plt.title('Merchant VS Label')
ax = sns.countplot('merchant_id',hue='label',data=train_data_merchant)
for p in ax.patches:
height = p.get_height()
选取top5店铺
店铺 购买次数
4044 3379
3828 3254
4173 2542
1102 2483
4976 1925
Name: merchant_id, dtype: int64
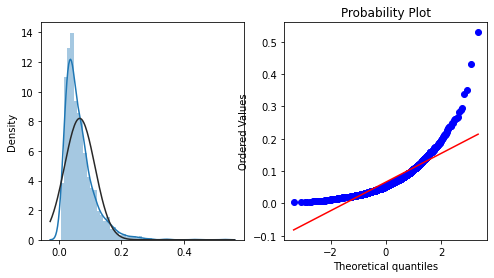
查看店铺复购概率分布
merchant_repeat_buy = [ rate for rate in train_data.groupby(['merchant_id'])['label'].mean() if rate <= 1 and rate > 0]
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.distplot(merchant_repeat_buy, fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(merchant_repeat_buy, plot=plt) //这是一种检验样本数据概率分布(例如正态分布)的方法。红色线条表示正态分布,蓝色线条表示样本数据,蓝色越接近红色参考线,说明越符合预期分布(这是是正态分布)
查看用户大于一次复购概率分布
user_repeat_buy = [rate for rate in train_data.groupby(['user_id'])['label'].mean() if rate <= 1 and rate > 0]
plt.figure(figsize=(8,6))
ax=plt.subplot(1,2,1)
sns.distplot(user_repeat_buy, fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(user_repeat_buy, plot=plt)
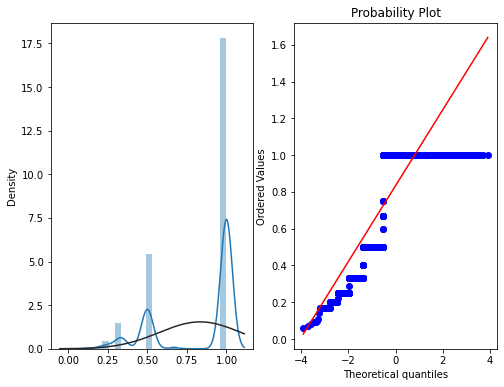
可以看出近6个月,用户复购率很小,基本买一次为主
查看用户性别与复购的关系
plt.figure(figsize=(8,8))
plt.title('Gender VS Label')
ax = sns.countplot('gender',hue='label',data=train_data_user_info)
for p in ax.patches:
height = p.get_height()
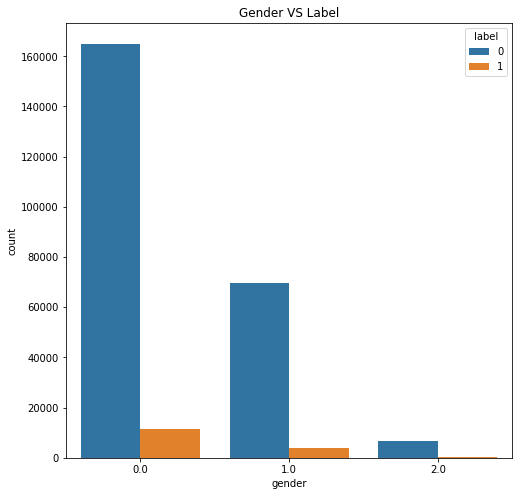
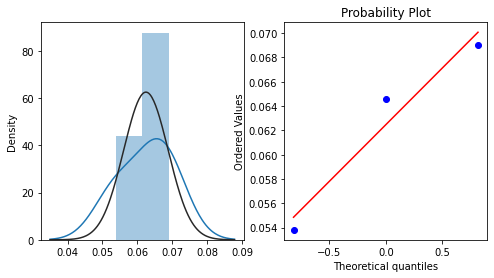
查看用户性别复购的分布
repeat_buy = [rate for rate in train_data_user_info.groupby(['gender'])['label'].mean()]
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.distplot(repeat_buy, fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(repeat_buy, plot=plt)
查看用户年龄与复购的关系
plt.figure(figsize=(8,8))
plt.title('Age VS Label')
ax = sns.countplot('age_range',hue='label',data=train_data_user_info)
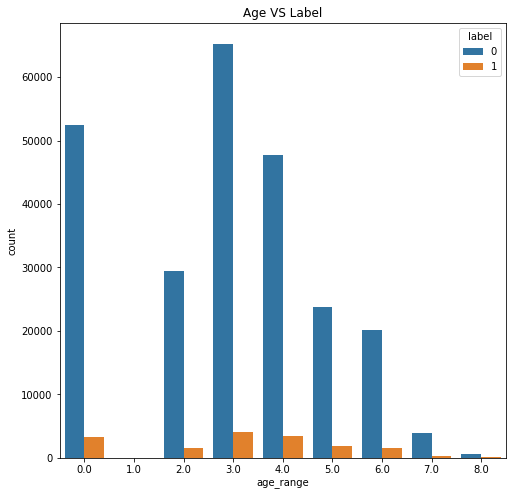
查看用户年龄复购的分布
repeat_buy = [rate for rate in train_data_user_info.groupby(['age_range'])['label'].mean()]
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.distplot(repeat_buy, fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(repeat_buy, plot=plt)
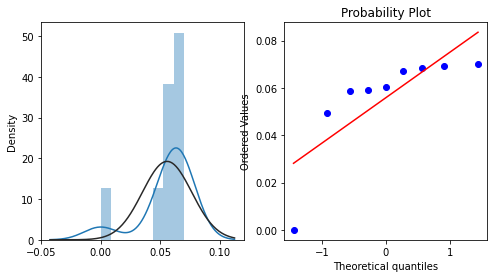
可以看出不同年龄段,复购概率不同
本文来自博客园,作者:Lugendary,转载请注明原文链接:https://www.cnblogs.com/lugendary/p/16037200.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号