从0开始手写RPC
01 什么是RPC?原理是什么?
什么是RPC?
RPC(Remote Procedure Call)即远程过程调用
为什么要RPC?
两个不同的服务器上的服务提供的方法不在一个内存空间,所以需要通过网络编程才能传递方法调用所需参数。并且,方法调用的结果也需要网络编程来接收。但是如果自己手动网络编程来实现这个调用过程的话工作量太大,因为需要考虑底层传输方式(TCP还是UDP)、序列化等等方面。
RPC能帮助我们做什么?
通过RPC可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且不需要了解底层网络编程的具体细节。
RPC的出现就是让你调用远程方法就像调用本地方法一样简单
RPC原理是什么?
为了便于理解,我们可以把整个RPC的核心功能看作是下面6个部分实现的:
1、客户端(服务消费端):调用远程方法的一端。
2、客户端Stub(桩):其实是一代理类。代理类主要做的事情就是帮你调用方法、类、方法参数等信息传递到服务端。
3、网络传输:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种,比如最基本的Socket或者性能以及封装更加优秀的Netty(推荐)。
4、服务端Stub(桩):这个桩不是代理类。我觉得理解为桩不太好,大家注意一下。这里的服务器Stub实际指的就是接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。
5、服务端(服务提供端):提供远程方法的一端。
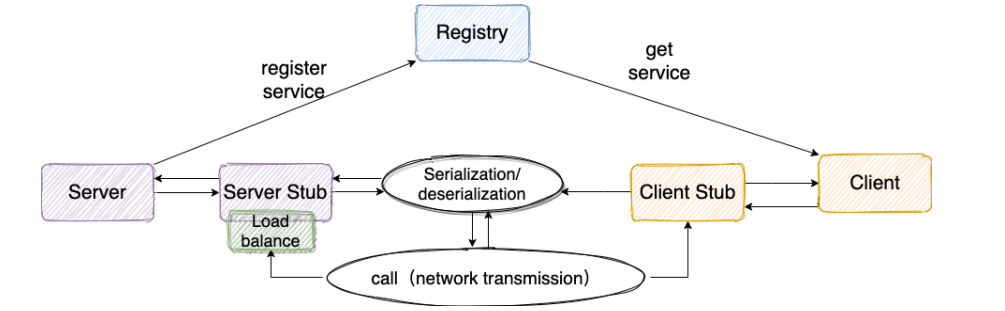
具体原理图如下:
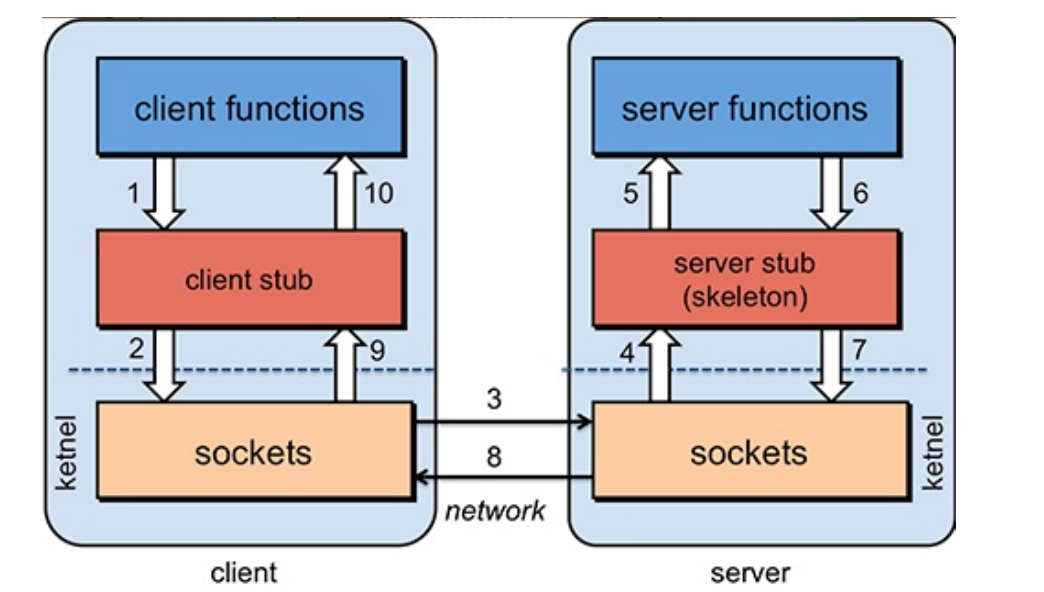
1、服务消费端(client) 以本地调用的方式调用远程服务;
2、客户端Stub(client stub)接收调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):RpcRequest;
3、客户端Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
4、服务端Stub(桩) 收到消息将消息反序列化为java对象:RpcRequest;
5、服务端Stub(桩) 根据RpcRequest中的类、方法、方法参数等信息调用本地的方法;
6、服务器Stub(桩) 得到方法执行结果并将组装成能够进行网络传输的消息体:RpcRequest(序列化)发送至消费方;
7、客户端Stub(client stub) 接收到消息并将反序列化为java对象:RpcResponse,这样也就得到了最终结果。
相信大家看完上面的讲解后,已经了解了RPC的原理,虽然篇幅不多,但是基本把RPC框架的核心原理讲清楚了!对于上面的技术细节,后面章节会介绍。
最后
对于RPC的原理,不只能简单理解,还要能够自己画出来并且能够给别人讲出来。面试中关于PRC相关问题基本都会碰到原理。
02 常见RPC框架介绍
我们这里说的 RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架,比如我下面介绍的 Dubbo、Motan、gRPC这些。 如果需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”,比如Feign。
Dubbo

Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案, 涵盖 Java、Golang 等多种语言 SDK 实现。
Dubbo 提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh (Dubbo3 赋予了很多云原生友好的新特性)等特性。
Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
· Github :https://github.com/apache/incubator-dubbo
· 官网:https://dubbo.apache.org/zh/
Motan
Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑着千亿次调用。不过笔者倒是很少看到有公司使用,而且网上的资料也比较少。很多人喜欢拿 Motan 和 Dubbo 作比较,毕竟都是国内大公司开源的。笔者在查阅了很多资料,以及简单查看了其源码之后发现:Motan 更像是一个精简版的 Dubbo,可能是借鉴了 Dubbo 的思想,Motan 的设计更加精简,功能更加纯粹。
不过,我不推荐你在实际项目中使用 Motan。如果你要是公司实际使用的话,还是推荐 Dubbo ,其社区活跃度以及生态都要好很多。
· 从 Motan 看 RPC 框架设计:http://kriszhang.com/motan-rpc-impl/
· Motan 中文文档:https://github.com/weibocom/motan/wiki/zh_overview
gRPC
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
何谓 ProtoBuf? ProtoBuf( Protocol Buffer) 是一种更加灵活、高效的数据格式,可用于通讯协议、数据存储等领域,基本支持所有主流编程语言且与平台无关。不过,通过 ProtoBuf 定义接口和数据类型还挺繁琐的,这是一个小问题。 不得不说,gRPC 的通信层的设计还是非常优秀的,Dubbo-go 3.0 的通信层改进主要借鉴了 gRPC。
不过,gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
· Github:https://github.com/grpc/grpc
· 官网:https://grpc.io/
Thrift
Apache Thrift 是 Facebook 开源的跨语言的 RPC 通信框架,目前已经捐献给 Apache 基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于 thrift 研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
Thrift支持多种不同的编程语言,包括C++、Java、Python、PHP、Ruby等(相比于 gRPC 支持的语言 更多 )。
· 官网:https://thrift.apache.org/
· Thrift 简单介绍:https://www.jianshu.com/p/8f25d057a5a9
总结
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是它们只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑。
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的。而且,Dubbo在国内有很多成功的案例比如当当网、滴滴等等,是一款经得起生产考验的成熟稳定的 RPC 框架。最重要的是你还能找到非常多的 Dubbo 参考资料,学习成本相对也较低。
下图展示了 Dubbo 的生态系统。
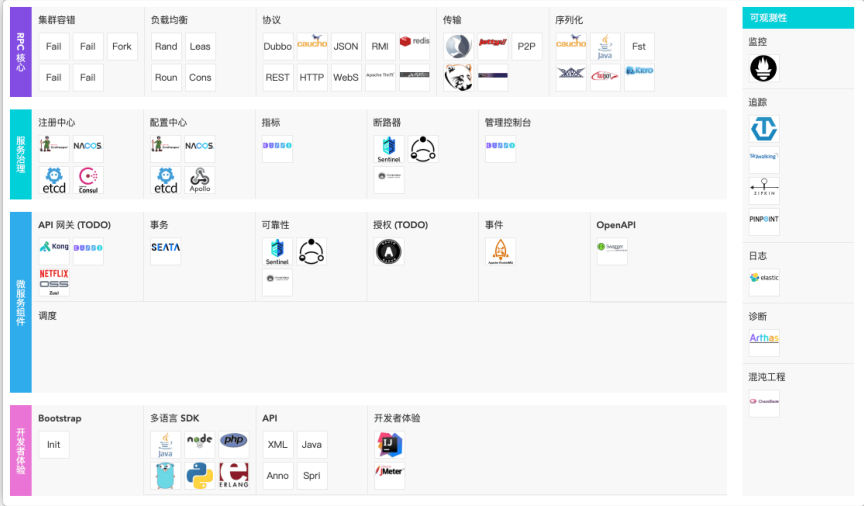
Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
但是,Dubbo 和 Motan 主要是给 Java 语言使用。虽然,Dubbo 和 Motan 目前也能兼容部分语言,但是不太推荐。如果需要跨多种语言调用的话,可以考虑使用 gRPC。
综上,如果是 Java 后端技术栈,并且你在纠结选择哪一种 RPC 框架的话,我推荐你考虑一下 Dubbo。
03 如何自己实现一个RPC框架?
像设计一个 RPC 框架/消息队列这类问题在面试中还是非常常见的。这是一道你花点精力稍微准备一下 就能回答上来的一个问题。如果你回答的比较好的话,那面试官肯定会对你印象非常不错! 消息队列的设计实际上和 RPC 框架/非常类似,我这里就先拿 RPC 框架开涮。
如果让你自己设计 RPC 框架你会如何设计?
一般情况下, RPC 框架不仅要提供服务发现功能,还要提供负载均衡、容错等功能,这样的 RPC 框架才算真正合格的。
为了便于小伙伴们理解,我们先从一个最简单的 RPC 框架使用示意图开始。这也是 guide-rpcframework 目前的架构 。
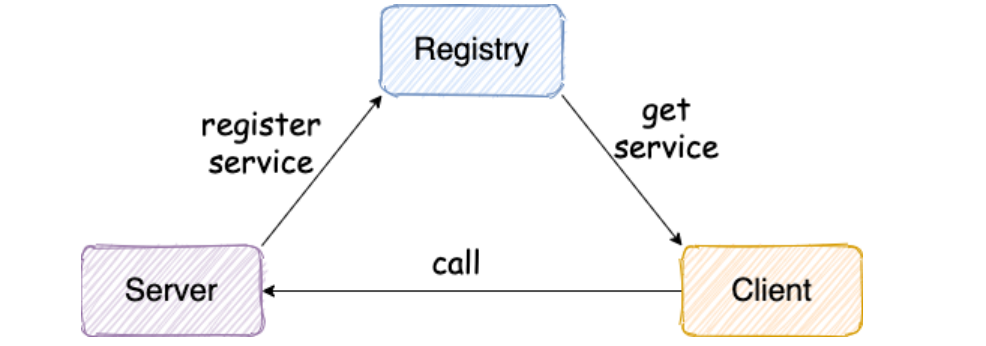
从上图我们可以看出:服务提供端 Server 向注册中心注册服务,服务消费者 Client 通过注册中心拿到 服务相关信息,然后再通过网络请求服务提供端 Server。
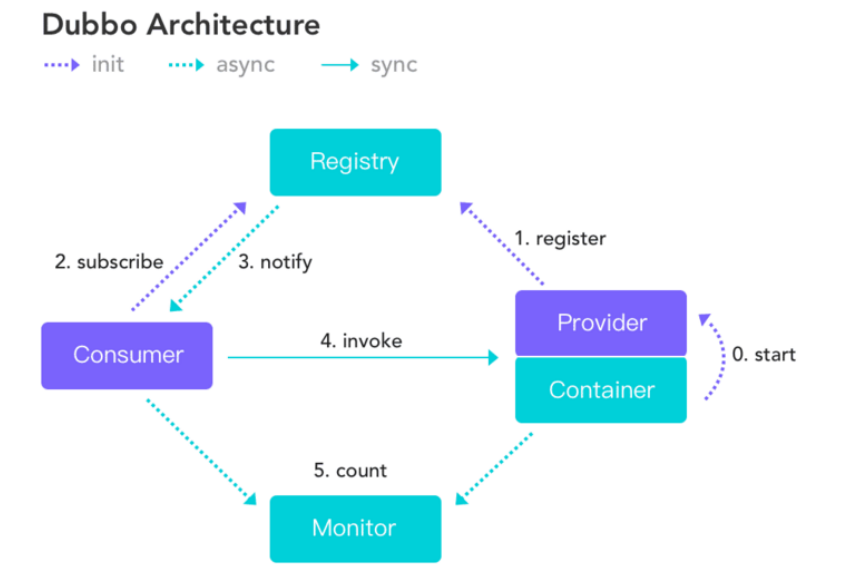
作为 RPC 框架领域的佼佼者Dubbo的架构如下图所示,和我们上面画的大体也是差不多的。
下面我们再来看一个比较完整的 RPC 框架使用示意图如下:
参考上面这张图,我们简单说一下设计一个最基本的 RPC 框架的思路或者说实现一个最基本的 RPC 框 架需要哪些东西:
注册中心
注册中心首先是要有的。比较推荐使用 Zookeeper 作为注册中心。当然了,你也可以使用 Nacos ,甚 至是 Redis。 ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数 据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队 列等功能。并且,ZooKeeper 将数据保存在内存中,性能是非常棒的。 在“读”多于“写”的应用程序中尤 其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。
当然了,如果你想通过文件来存储服务地址的话也是没问题的,不过性能会比较差。
注册中心负责服务地址的注册与查找,相当于目录服务。 服务端启动的时候将服务名称及其对应的地址 (ip+port)注册到注册中心,服务消费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消 费端就可以通过网络请求服务端了。 我们再来结合 Dubbo 的架构图来理解一下!
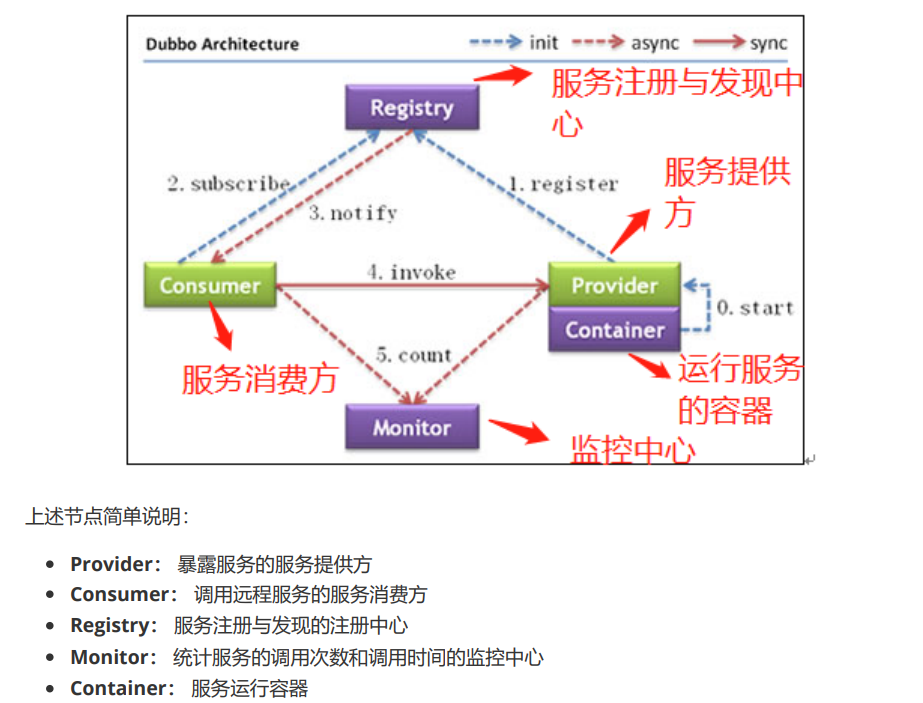
调用关系说明:
-
服务容器负责启动,加载,运行服务提供者。
-
服务提供者在启动时,向注册中心注册自己提供的服务。
-
服务消费者在启动时,向注册中心订阅自己所需的服务。
-
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给 消费者。
-
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
-
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
网络传输
既然我们要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的参数等数据到服务提供端。
网络传输具体实现你可以使用 Socket ( Java 中最原始、最基础的网络通信方式。但是,Socket 是阻塞 IO、性能低并且功能单一)。
你也可以使用同步非阻塞的 I/O 模型 NIO ,但是用它来进行网络编程真的太麻烦了。不过没关系,你可 以使用基于 NIO 的网络编程框架 Netty ,它将是你最好的选择!
我先简单介绍一下 Netty ,后面的文章中我会详细介绍到。
-
Netty 是一个基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应 用程序。
-
它极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至 都要更好。
-
支持多种协议如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
序列化和反序列化
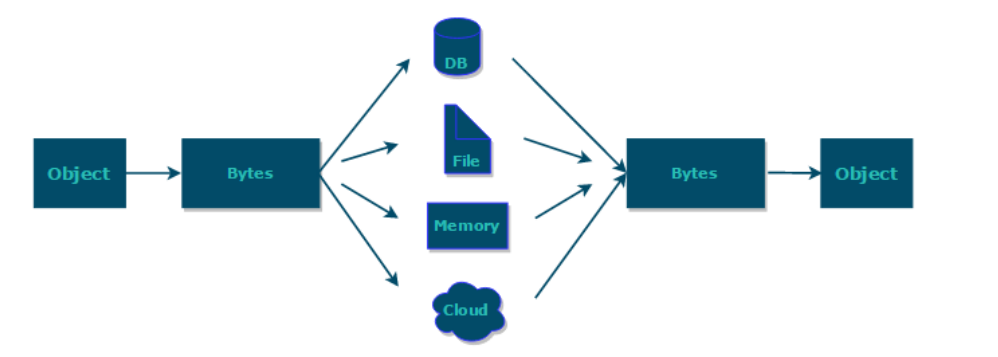
要在网络传输数据就要涉及到序列化。为什么需要序列化和反序列化呢? 因为网络传输的数据必须是二进制的。因此,我们的 Java 对象没办法直接在网络中传输。为了能够让 Java 对象在网络中传输我们需要将其序列化为二进制的数据。我们最终需要的还是目标 Java 对象,因此 我们还要将二进制的数据“解析”为目标 Java 对象,也就是对二进制数据再进行一次反序列化。 另外,不仅网络传输的时候需要用到序列化和反序列化,将对象存储到文件、数据库等场景都需要用到 序列化和反序列化。
JDK 自带的序列化,只需实现 java.io.Serializable 接口即可,不过这种方式不推荐,因为不支持跨 语言调用并且性能比较差。 现在比较常用序列化的有 hessian、kryo、protostuff ......。我会在下一篇文章中简单对比一下这些序列化方式。
动态代理
动态代理也是需要的。很多人可能不清楚为啥需要动态代理?我来简单解释一下吧! 我们知道代理模式就是: 我们给某一个对象提供一个代理对象,并由代理对象来代替真实对象做一些事 情。你可以把代理对象理解为一个幕后的工具人。 举个例子:我们真实对象调用方法的时候,我们可以 通过代理对象去做一些事情比如安全校验、日志打印等等。但是,这个过程是完全对真实对象屏蔽的。 讲完了代理模式,再来说动态代理在 RPC 框架中的作用。 前面第一节的时候,我们就已经提到 :RPC 的主要目的就是让我们调用远程方法像调用本地方法一样简 单,我们不需要关心远程方法调用的细节比如网络传输。 怎样才能屏蔽远程方法调用的底层细节呢? 答案就是动态代理。简单来说,当你调用远程方法的时候,实际会通过代理对象来传输网络请求,不然的话,怎么可能直接就调用到远程方法。
负载均衡
负载均衡也是需要的。为啥? 举个例子:我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户 端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关 键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。 负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡 的这四个字就能明显感受到它的意义。
传输协议
我们还需要设计一个私有的 RPC 协议,这个协议是客户端(服务消费方)和服务端(服务提供方)交流 的基础。
简单来说:通过设计协议,我们定义需要传输哪些类型的数据, 并且还会规定每一种类型的数据应该占 多少字节。这样我们在接收到二进制数据之后,就可以正确的解析出我们需要的数据。这有一点像密文传输的感觉。
通常一些标准的 RPC 协议包含下面这些内容:
· 魔数 : 通常是 4 个字节。这个魔数主要是为了筛选来到服务端的数据包,有了这个魔数之后,服务端首先取出前面四个字节进行比对,能够在第一时间识别出这个数据包并非是遵循自定义协议 的,也就是无效数据包,为了安全考虑可以直接关闭连接以节省资源。
· 序列化器编号 :标识序列化的方式,比如是使用 Java 自带的序列化,还是 json,kryo 等序列化 方式。
· 消息体长度 : 运行时计算出来。
......
实现一个最基本的 RPC 框架需要哪些技术?
刚刚我们已经聊了如何实现一个 RPC 框架,下面我们就来看看实现一个最基本的 RPC 框架需要哪些技术吧!
按照我实现的这一款基于 Netty+kryo+Zookeeper 实现的 RPC 框架来说的话,你需要下面这些技术支 撑:
Java
-
动态代理机制;
-
序列化机制以及各种序列化框架的对比,比如 hession2、kryo、protostuff;
-
线程池的使用;
-
CompletableFuture 的使用;
-
......
Netty
-
使用 Netty 进行网络传输;
-
ByteBuf 介绍;
-
Netty 粘包拆包;
-
Netty 长连接和心跳机制;
-
......
Zookeeper
-
基本概念;
-
数据结构;
-
如何使用 Netflix 公司开源的 Zookeeper 客户端框架 Curator 进行增删改查;
-
......
总结
实现一个最基本的 RPC 框架应该至少包括下面几部分:
-
注册中心 :注册中心负责服务地址的注册与查找,相当于目录服务。
-
网络传输 :既然我们要调用远程的方法,就要发送网络请求来传递目标类和方法的信息以及方法的 参数等数据到服务提供端。
-
序列化和反序列化 :要在网络传输数据就要涉及到序列化。
-
动态代理 :屏蔽远程方法调用的底层细节。
-
负载均衡 : 避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题。
-
传输协议 :这个协议是客户端(服务消费方)和服务端(服务提供方)交流的基础。
-
更完善的一点的 RPC 框架可能还有监控模块(拓展:你可以研究一下 Dubbo 的监控模块的设计)。
04 序列化介绍以及序列化协议选择
什么是序列化和反序列化?
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都 需要用到序列化。简单来说:
· 序列化: 将数据结构或对象转换成二进制字节流的过程
· 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class), 但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
下面是序列化和反序列化常见应用场景:
· 对象在进行网络传输(比如远程方法调用 RPC 的时候之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化;
· 将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化;
· 将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序 列化;
· 将对象存储到内存之前需要进行序列化,从内存中读取出来之后需要进行反序列化。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
序列化协议对应于 TCP/IP 四 层模型的哪一层?
我们知道网络通信的双方必须要采用和遵守相同的协议。TCP/IP 四层模型是下面这样的,序列化协议属于哪一层呢?
-
应用层 2. 传输层 3. 网络层 4. 网络接口层
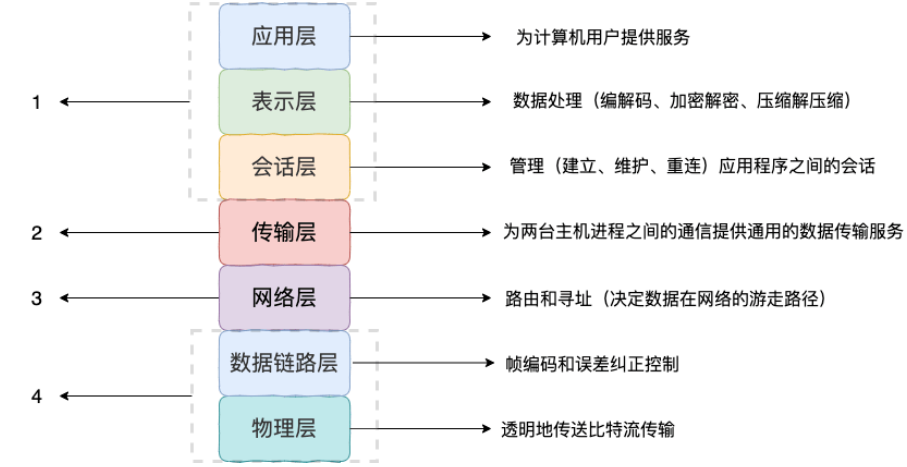
如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
因为,OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序 列化协议属于 TCP/IP 协议应用层的一部分。
常见序列化协议有哪些?
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存在安全问题。比较常用的序列化协议有 Hessian、Kryo、Protobuf、ProtoStuff,这些都是基于二进制的序列化协议。 像 JSON 和 XML 这种属于文本类序列化方式。虽然可读性比较好,但是性能较差,一般不会选择。
JDK 自带的序列化方式
JDK 自带的序列化,只需实现 java.io.Serializable接口即可。
serialVersionUID 有什么作用?
序列化号 serialVersionUID 属于版本控制的作用。反序列化时,会检查 serialVersionUID 是否和当 前类的 serialVersionUID 一致。如果 serialVersionUID 不一致则会抛出 InvalidClassException 异常。强烈推荐每个序列化类都手动指定其 serialVersionUID ,如果不手 动指定,那么编译器会动态生成默认的 serialVersionUID 。
serialVersionUID 不是被 static 变量修饰了吗?为什么还会被“序列化”?
static 修饰的变量是静态变量,位于方法区,本身是不会被序列化的。 static 变量是属于类的而不 是对象。你反序列之后, static 变量的值就像是默认赋予给了对象一样,看着就像是 static 变量被 序列化,实际只是假象罢了。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,可以使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时, 被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
· transient 只能修饰变量,不能修饰类和方法。
· transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类 型,那么反序列后结果就是 0 。
· static 变量因为不属于任何对象(Object),所以无论有没有 transient 关键字修饰,均不会被序列化。
为什么不推荐使用 JDK 自带的序列化?
我们很少或者说几乎不会直接使用 JDK 自带的序列化方式,主要原因有下面这些原因:
· 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
· 性能差 :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
· 存在安全问题 :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制, 那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
Kryo
Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高 的运行速度和较小的字节码体积。 另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开 源项目(如 Hive、Storm)中广泛的使用。
Protobuf
Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于 繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不灵活,但是,另一方面导致 protobuf 没有序列化漏洞的风险。
ProtoStuff
由于 Protobuf 的易用性,它的哥哥 Protostuff 诞生了。 protostuff 基于 Google protobuf,但是提供了更多的功能和更简易的用法。虽然更加易用,但是不代 表 ProtoStuff 性能更差。
Hessian
Hessian 是一个轻量级的,自定义描述的二进制 RPC 协议。Hessian 是一个比较老的序列化实现了,并 且同样也是跨语言的。Dubbo2.x 默认启用的序列化方式是 Hessian2 ,但是,Dubbo 对 Hessian2 进行了修改,不过大体结构 还是差不多。
总结
Kryo 是专门针对 Java 语言序列化方式并且性能非常好,如果你的应用是专门针对 Java 语言的话可以考 虑使用,并且 Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地 址:https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/)
像 Protobuf、 ProtoStuff、hessian 这类都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使 用。 除了我上面介绍到的序列化方式的话,还有像 Thrift,Avro 这些。
推荐阅读
· 美团技术团队-序列化和反序列化:https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html
· 在 Dubbo 中使用高效的 Java 序列化(Kryo 和 FST): https://dubbo.apache.org/zh/docs/v3.0/references/serializations/serialization/
05 Socket 网络通信实战
前言
guide-rpc-framework 的第一版使用的是 JDK 提供了 socket 进行网络编程。为了搞懂具体原理,我们 首先要学会使用 Socket 进行网络通信。
什么是 Socket(套接字)
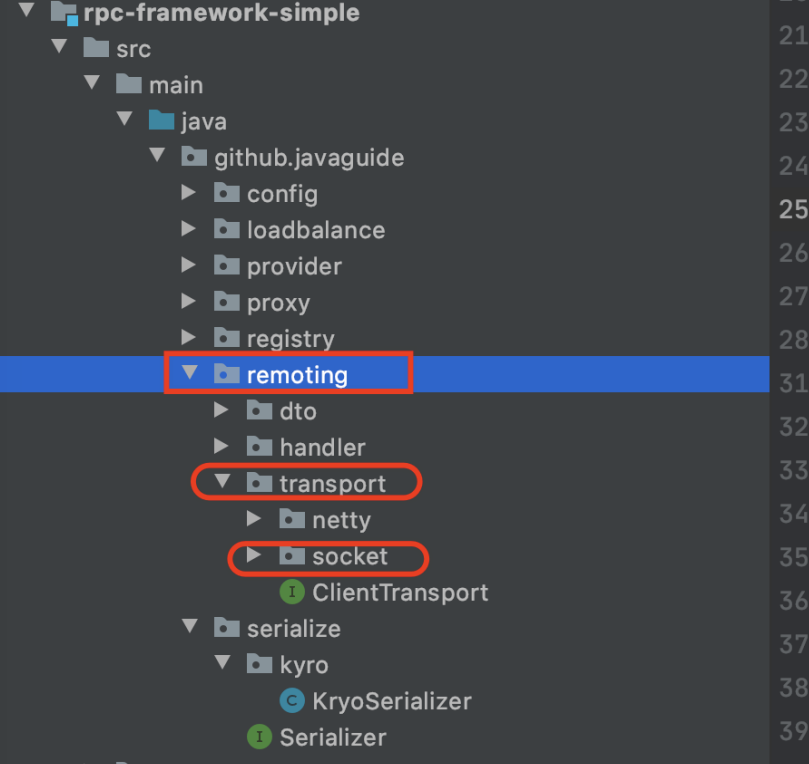
Socket 是一个抽象概念,应用程序可以通过它发送或接收数据。在使用 Socket 进行网络通信的时候, 通过 Socket 就可以让我们的数据在网络中传输。操作套接字的时候,和我们读写文件很像。
套接字是 IP 地址与端口的组合,套接字 Socket=(IP 地址:端口号)。
要通过互联网进行通信,至少需要一对套接字:
-
运行于服务器端的 Server Socket。
-
运行于客户机端的 Client Socket。
在 Java 开发中使用 Socket 时会常用到两个类,都在 java.net 包中:
-
Socket: 一般用于客户端
-
ServerSocket :用于服务端
Socket 网络通信过程
Socket 网络通信过程如下图所示:
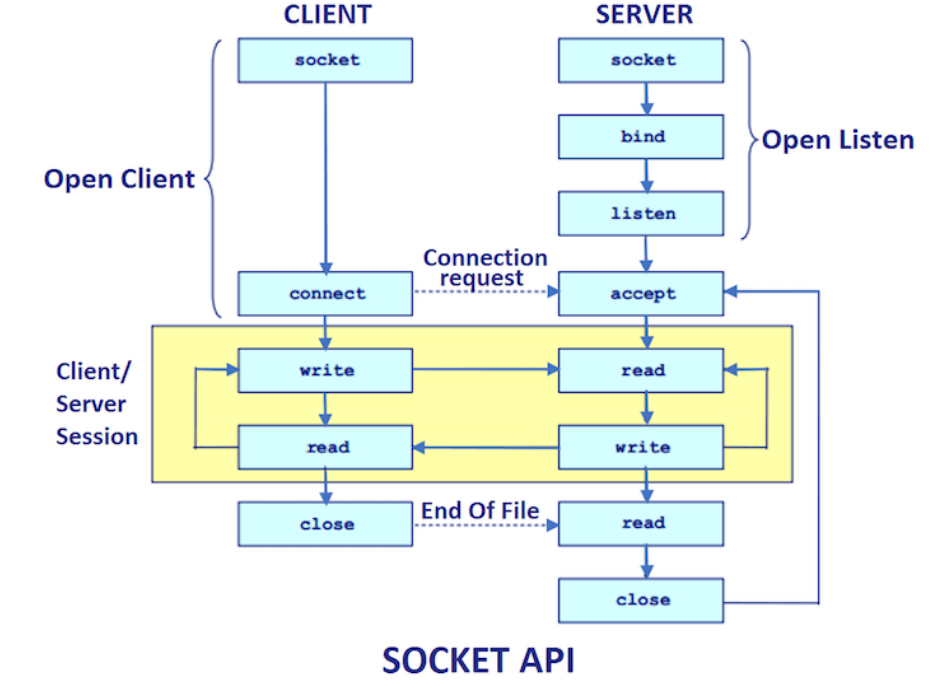
Socket 网络通信过程简单来说分为下面 4 步:
-
建立服务端并且监听客户端请求
-
客户端请求,服务端和客户端建立连接
-
两端之间可以传递数据
-
关闭资源
对应到服务端和客户端的话,是下面这样的。
服务器端:
-
创建 ServerSocket 对象并且绑定地址(ip)和端口号(port):server.bind(new InetSocketAddress(host, port))
-
通过 accept()方法监听客户端请求
-
连接建立后,通过输入流读取客户端发送的请求信息
-
通过输出流向客户端发送响应信息
-
关闭相关资源
客户端:
-
创建Socket 对象并且连接指定的服务器的地址(ip)和端口号(port): socket.connect(inetSocketAddress)
-
连接建立后,通过输出流向服务器端发送请求信息
-
通过输入流获取服务器响应的信息
-
关闭相关资源
Socket 网络通信实战
服务端
public class HelloServer {
private static final Logger logger =
LoggerFactory.getLogger(HelloServer.class);
public void start(int port) {
//1.创建 ServerSocket 对象并且绑定一个端口
try (ServerSocket server = new ServerSocket(port);) {
Socket socket;
//2.通过 accept()方法监听客户端请求
while ((socket = server.accept()) != null) {
logger.info("client connected");
try (ObjectInputStream objectInputStream = new
ObjectInputStream(socket.getInputStream());
ObjectOutputStream objectOutputStream = new
ObjectOutputStream(socket.getOutputStream())) {
//3.通过输入流读取客户端发送的请求信息
Message message = (Message)
objectInputStream.readObject();
logger.info("server receive message:" +
message.getContent());
message.setContent("new content");
//4.通过输出流向客户端发送响应信息
objectOutputStream.writeObject(message);
objectOutputStream.flush();
} catch (IOException | ClassNotFoundException e) {
logger.error("occur exception:", e);
}
}
} catch (IOException e) {
logger.error("occur IOException:", e);
}
}
public static void main(String[] args) {
HelloServer helloServer = new HelloServer();
helloServer.start(6666);
}
}
ServerSocket 的 accept() 方法是阻塞方法,也就是说 ServerSocket 在调用 accept() 等待客 户端的连接请求时会阻塞,直到收到客户端发送的连接请求才会继续往下执行代码。
很明显,我上面演示的代码片段有一个很严重的问题:只能同时处理一个客户端的连接,如果需要管理 多个客户端的话,就需要为我们请求的客户端单独创建一个线程。 如下图所示:
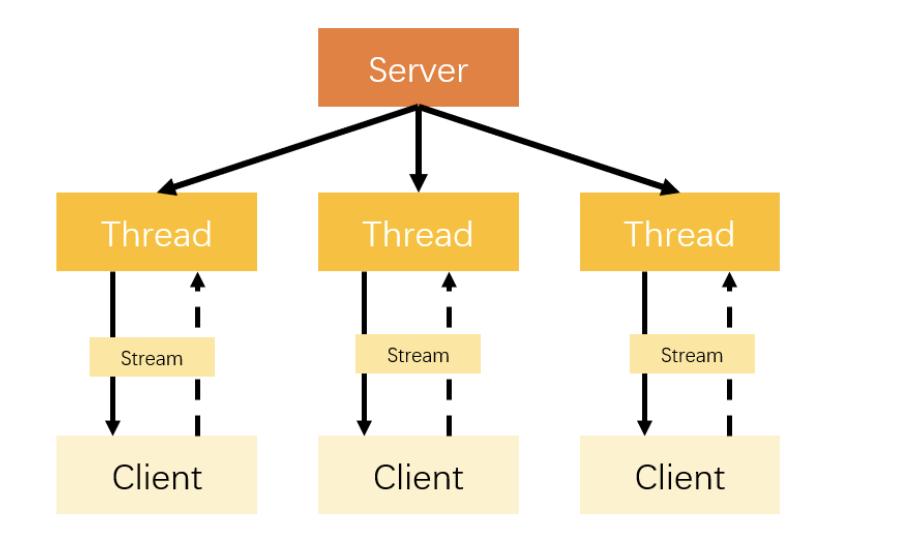
但是,这样会导致一个很严重的问题:资源浪费。
我们知道线程是很宝贵的资源,如果我们为每一次连接都用一个线程处理的话,就会导致线程越来越 多,最后达到了极限之后,就无法再创建线程处理请求了。处理的不好的话,甚至可能直接就宕机掉了。 很多人就会问了:那有没有改进的方法呢?
当然有! 比较简单并且实际的改进方法就是使用线程池。线程池还可以让线程的创建和回收成本相对较低,并且我们可以指定线程池的可创建线程的最大数量,这样就不会导致线程创建过多,机器资源被不 合理消耗。
ThreadFactory threadFactory = Executors.defaultThreadFactory();
ExecutorService threadPool = new ThreadPoolExecutor(10, 100, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<>(100), threadFactory);
threadPool.execute(() -> {
// 创建 socket 连接
});
但是,即使你再怎么优化和改变。也改变不了它的底层仍然是同步阻塞的 BIO 模型的事实,因此无法从 根本上解决问题。
为了解决上述的问题,Java 1.4 中引入了 NIO ,一种同步非阻塞的 I/O 模型。 由于使用同步非阻塞的 I/O 模型 NIO 来进行网络编程真的太麻烦了。你可以使用基于 NIO 的网络编程框架 Netty ,它将是你最 好的选择(前面的章节提到过,后面的章节会详细讲解如何使用 Netty 进行网络编程)!
客户端
public class HelloClient {
private static final Logger logger =
LoggerFactory.getLogger(HelloClient.class);
public Object send(Message message, String host, int port) {
//1. 创建Socket对象并且指定服务器的地址和端口号
try (Socket socket = new Socket(host, port)) {
ObjectOutputStream objectOutputStream = new
ObjectOutputStream(socket.getOutputStream());
//2.通过输出流向服务器端发送请求信息
objectOutputStream.writeObject(message);
//3.通过输入流获取服务器响应的信息
ObjectInputStream objectInputStream = new
ObjectInputStream(socket.getInputStream());
return objectInputStream.readObject();
} catch (IOException | ClassNotFoundException e) {
logger.error("occur exception:", e);
}
return null;
}
public static void main(String[] args) {
HelloClient helloClient = new HelloClient();
Message message = (Message) helloClient.send(new Message("content
from client"), "127.0.0.1", 6666);
System.out.println("client receive message:" +
message.getContent());
}
}
发送的消息实体类:
首先运行服务端,然后再运行客户端,控制台输出如下:
服务端:
[main] INFO github.javaguide.socket.HelloServer - client connected
[main] INFO github.javaguide.socket.HelloServer - server receive
message:content from client
客户端:
client receive message:new content
好的!我们的第一个使用 Socket 进行网络编程的案例已经完成了。
下一篇我们来看看如何使用 Netty 进行网络编程。
06 Netty从入门到网络通信实战
Netty 介绍
简单用 3 点概括一下 Netty 吧!
-
Netty 是一个基于 NIO 的 client-server(客户端服务器)框架,使用它可以快速简单地开发网络应用程序。
-
它极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面甚至都要更好。
-
支持多种协议如 FTP,SMTP,HTTP 以及各种二进制和基于文本的传统协议。
用官方的总结就是:Netty 成功地找到了一种在不妥协可维护性和性能的情况下实现易于开发,性能,稳定性和灵活性的方法。
Netty 特点
根据官网的描述,我们可以总结出下面一些特点: · 统一的 API,支持多种传输类型,阻塞和非阻塞的。 · 简单而强大的线程模型。 · 自带编解码器解决 TCP 粘包/拆包问题。 · 自带各种协议栈。 · 真正的无连接数据包套接字支持。 · 比直接使用 Java 核心 API 有更高的吞吐量、更低的延迟、更低的资源消耗和更少的内存复制。 · 安全性不错,有完整的 SSL/TLS 以及 StartTLS 支持。 · 社区活跃 · 成熟稳定,经历了大型项目的使用和考验,而且很多开源项目都使用到了 Netty 比如我们经常接触的 Dubbo、RocketMQ 等等。 ......
使用Netty能做什么?
这个应该是老铁们最关心的一个问题了,凭借自己的了解,简单说一下,理论上 NIO 可以做的事情 ,使用 Netty 都可以做并且更好。Netty 主要用来做网络通信 : · 作为 RPC 框架的网络通信工具 : 我们在分布式系统中,不同服务节点之间经常需要相互调用,这个时候就需要 RPC 框架了。不同服务节点的通信是如何做的呢?可以使用 Netty 来做。比如我调用另外一个节点的方法的话,至少是要让对方知道我调用的是哪个类中的哪个方法以及相关参数吧! · 实现一个自己的 HTTP 服务器 :通过 Netty 我们可以自己实现一个简单的 HTTP 服务器,这个大家应该不陌生。说到 HTTP 服务器的话,作为 Java 后端开发,我们一般使用 Tomcat 比较多。一个最基本的 HTTP 服务器可要以处理常见的 HTTP Method 的请求,比如 POST 请求、GET 请求等等。 · 实现一个即时通讯系统 : 使用 Netty 我们可以实现一个可以聊天类似微信的即时通讯系统,这方面的开源项目还蛮多的,可以自行去 Github 找一找。 · 消息推送系统 :市面上有很多消息推送系统都是基于 Netty 来做的。 ......
哪些开源项目用到了 Netty?
我们平常经常接触的 Dubbo、RocketMQ、Elasticsearch、gRPC 等等都用到了 Netty。 可以说大量的开源项目都用到了 Netty,所以掌握 Netty 有助于你更好的使用这些开源项目并且让你有能力对其进行二次开发。 实际上还有很多很多优秀的项目用到了 Netty,Netty 官方也做了统计,统计结果在这里:https://netty.io/wiki/related-projects.html 。
Netty 使用 kryo 序列化传输对象实战
注意 :Kryo不支持没有无参构造函数的对象进行反序列化,因此如果某个对象希望使用Kryo来进行序列化操作的话,需要有相应的无参构造函数才可以。
传输实体类
我们首先定义两个对象,这两个对象是客户端与服务端进行交互的实体类。 客户端将 RpcRequest 类型的对象发送到服务端,服务端进行相应的处理之后将得到结果 RpcResponse 对象返回给客户端。
客户端请求
服务器响应
@AllArgsConstructor
@Getter
@NoArgsConstructor
@Builder
@ToString
public class RpcResponse {
//服务器响应实体类
private String message;
}
客户端
初始化客户端
客户端中主要有一个用于向服务端发送消息的 sendMessage()方法,通过这个方法你可以将消息也就是RpcRequest 对象发送到服务端,并且你可以同步获取到服务端返回的结果也就是RpcResponse 对象。
public class NettyClient {
private static final Logger logger =
LoggerFactory.getLogger(NettyClient.class);
private final String host;
private final int port;
private static final Bootstrap b;
public NettyClient(String host, int port) {
this.host = host;
this.port = port;
}
// 初始化相关资源比如 EventLoopGroup, Bootstrap
static {
EventLoopGroup eventLoopGroup = new NioEventLoopGroup();
b = new Bootstrap();
KryoSerializer kryoSerializer = new KryoSerializer();
b.group(eventLoopGroup)
.channel(NioSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
// 连接的超时时间,超过这个时间还是建立不上的话则代表连接失败
// 如果 15 秒之内没有发送数据给服务端的话,就发送一次心跳请求
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000)
.handler(new ChannelInitializer<SocketChannel>() {