


扩容的场景这里不累赘讲了,比如第一次put的时候,还有就是插入完以后,也还要判断是否要扩容。直接看源码吧。
1.扩容的方法如下,主要干这几件事情,第一件,算出新数组长度和新数组扩容阈值,创建新数组。第二件,扩容前的数组元素迁移到扩容后的数组当中去。主要分为单个元素的迁移,链表的迁移,红黑树的迁移(下期再讲),下面我们依次来看一下hashmap它是怎么玩的吧。
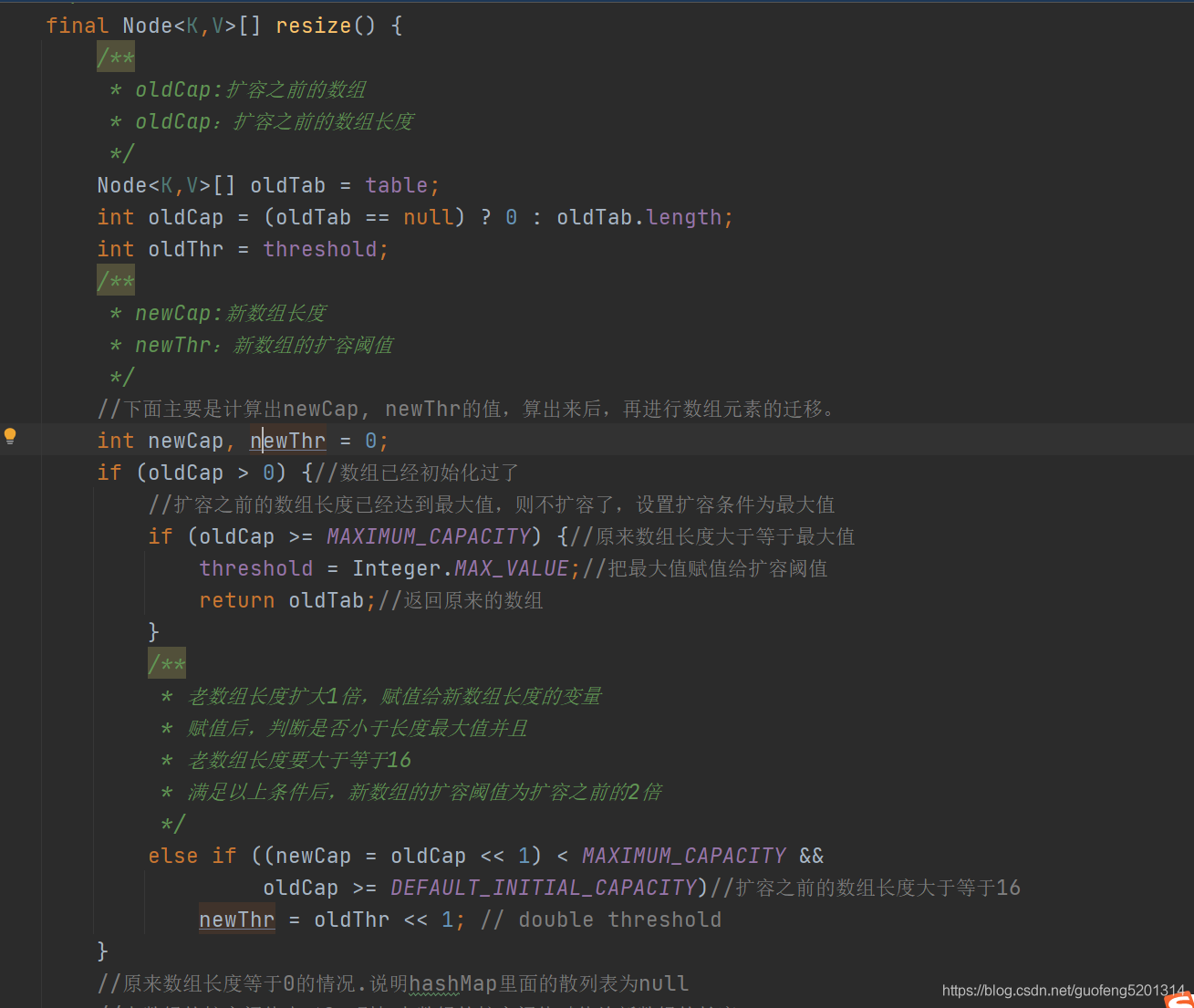
首先我们看下新数组长度和新数组扩容阈值是怎么算出来的。这里也分为两种情况,第一种是数组已经初始化过了。第二种是hashMap里面的散列表为null的情况。先看下数组已经初始化过的情况。如下图所示。
先判断,扩容前数组长度是否已经达到最大值,如果达到了最大值,则不扩容了,并设置扩容条件为最大值,返回扩容前的数组。一般这种情况比较少见。

如果是正常情况,则先把老数组扩容1倍,赋值给新数组长度的变量,赋值后,判断是否小于长度最大值并且老数组长度要大于等于16,满足以上条件后,新数组的扩容阈值为扩容之前的2倍。

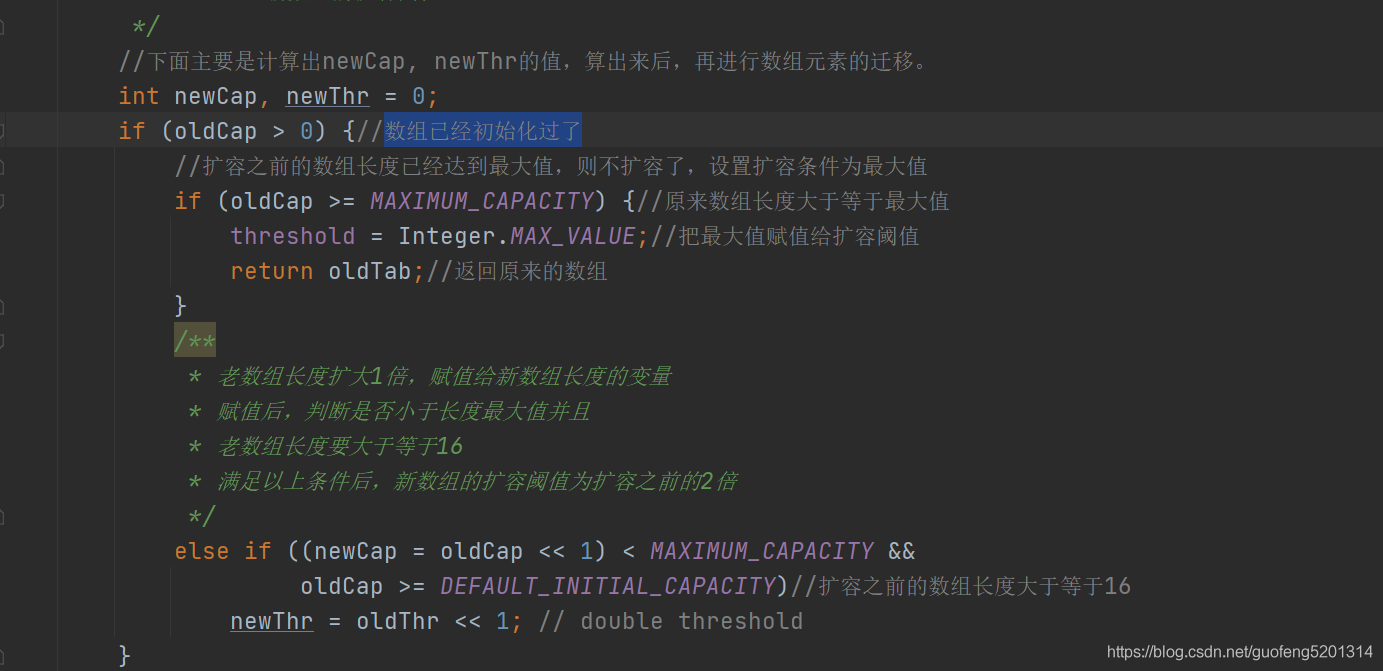
然后我们再看下ashMap里面的散列表为null的情况. 如果老数组的扩容阈值大于0,则把老数组的扩容阈值赋值给新数组的长度 ,如果是老数组的长度和老数组的扩容阈值都为0的时候,则设置默认值,newCap=16,newThr=16*0.75.

如果新数组的扩容阈值等于0,则设置它的扩容阈值。设置完以后,创建新的数组并且长度为newCap。
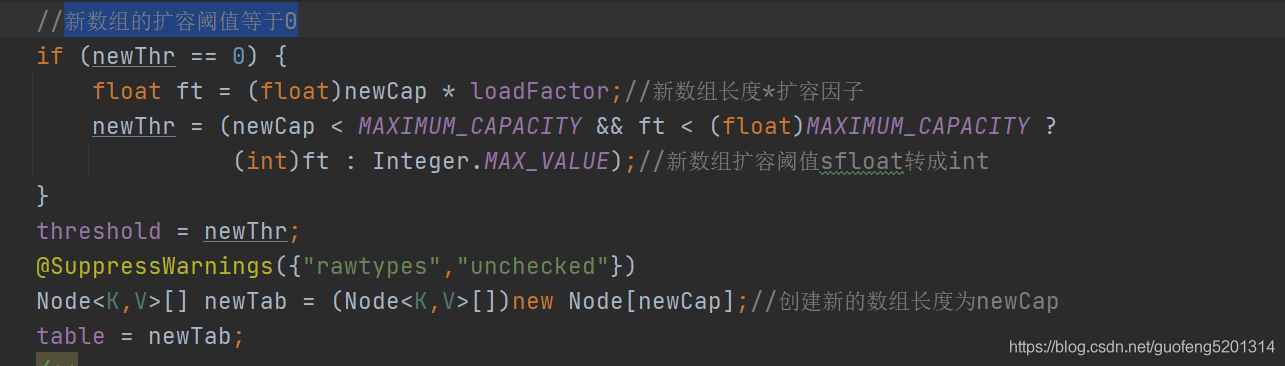
接下来就是数据迁移的过程了。先判断老数组是否为空,不为空则开始数据迁移。循环数组中的每个元素,如果是单个元素,先把数组下标的值设为null,方便jvm回收,然后根据e.hash & (newCap - 1)算出新数组的下标位置,直接迁移到新数组。

如果是链表,则有高位链和低位链,先根据e.hash & oldCap算出当前节点的高位是0还是1,如果是0,则把当前节点放入低位链,如果为1,则把当前节点放入高位链。
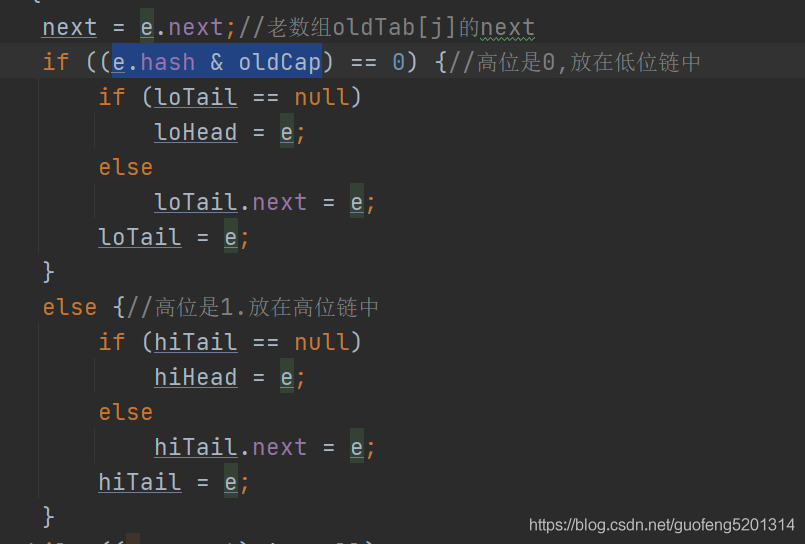
链表遍历完以后,判断高低位链表是否为空,低位链表不为空,则把loTail.next = null并且新数组的同一个下标指向该低位链。高位链不为空,则把hiTail.next = null,然后新数组j + oldCap的下标位置指向该高位链。迁移结束,返回新数组。红黑树迁移,下期再讲。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!