ubuntu安装伪分布式Hadoop3.1.2
本文是基于已经安装好的ubuntu环境上搭建伪分布式hadoop,在virtualbox安装ubuntu可以参考小编的
”virtualbox安装ubuntu16.04 LTS及其配置“
一、Hadoop的三种运行模式(启动模式)
1.1、单机模式(独立模式)(Local或Standalone Mode)
-默认情况下,Hadoop即处于该模式,用于开发和调式。
-不对配置文件进行修改。
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
-用于对MapReduce程序的逻辑进行调试,确保程序的正确。
1.2、伪分布式模式(Pseudo-Distrubuted Mode)
-Hadoop的守护进程运行在本机机器,模拟一个小规模的集群
-在一台主机模拟多主机。
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
-修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
-格式化文件系统
1.3、全分布式集群模式(Full-Distributed Mode)
-Hadoop的守护进程运行在一个集群上
-Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
-在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
-修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数
-格式化文件系统
二、准备系统环境
2.1、运行虚拟机,进行静态网络配置:
在终端上输入ifconfig -a命令查看网卡名,我的主机有三个网络接口,分别是enp0s3(桥接网卡),enp0s8(NAT),lo(动态获取ip)
# ifconfig -a
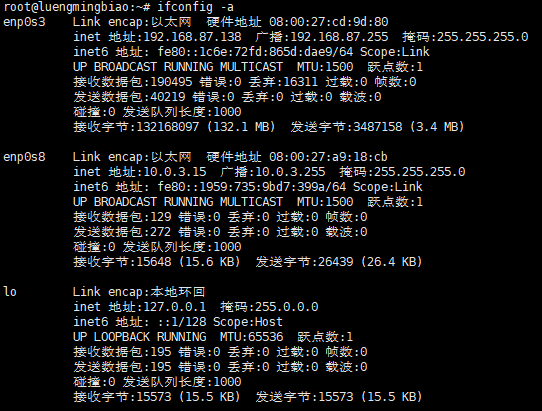
对/etc/network/interfaces文件进行编辑,以下是在终端上执行的命令:
sudo vim /etc/network/interfaces

上图是ubuntu的/etc/network/interfaces文件默认的内容,默认动态获取方法的配置。
但是在业务上需要给ubuntu主机配置静态ip网络,在这里我只对enp0s3进行修改,以下是静态分配的配置方法(根据自己的需求改):
auto enp0s3 iface enp0s3 inet static address 192.168.87.138 netmask 255.255.255.0 gateway 192.168.87.254
接下来需要添加域名服务器,编辑/etc/resolv.conf文件,添加域名服务器,在这里我选择了全球通用的DNS域名服务器,国内用户推荐使用,速度较快!
sudo vim /etc/resolv.conf
nameserver 114.114.114.114
或者
nameserver 8.8.8.8
配置已经完成了,接下来需要重启网络,网络重启有多种方法,在这里只列出两种方法,二选一即可。
1. 重启网卡
/etc/init.d/networking restart
2. 这两条命令是重启某个网络接口,一个系统可能有多个网络接口
# ifdown enp0s3
# ifup enp0s3
检查网络配置参数是否正确:
# ifconfig

检查是否能ping通:
ping www.qq.com
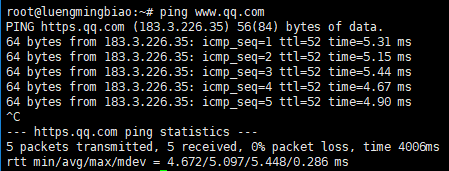
已成功ping通,静态网络已配置好了。
2.2、修改主机名与IP地址的对应关系
查看主机名:
# hostname

修改/etc/hosts文件:
# vim /etc/hosts
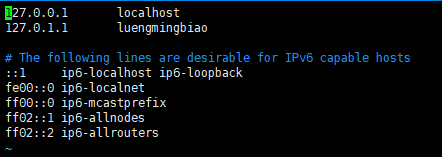
/etc/hosts文件默认是上图所示,修改文件为以下内容,注释127.0.1.1,添加主机静态地址与主机名:
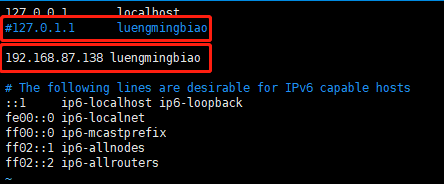
2.3、配置本机ssh免密码登录
单机配置ssh免密登陆的话,输入以下的命令即可:
提示输入信息,一直回车按默认即可。
# ssh-keygen -t rsa # cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # chmod 600 ~/.ssh/authorized_keys

完成之后,以 root 用户登录,修改 ssh 配置文件:
vim /etc/ssh/sshd_config
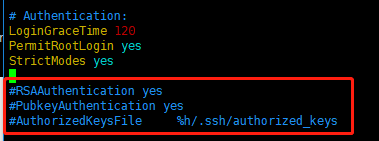
把文件中的下面几条信息的注释去掉,如图所示:
RSAAuthentication yes # 启用RSA认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径(和上面生成的文件同)
然后重启服务:
# service sshd restart
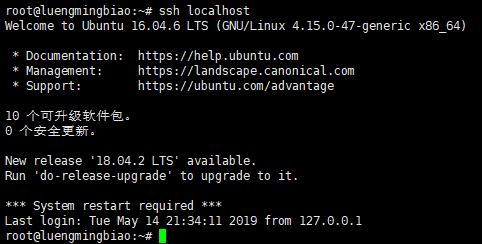
输入ssh localhost验证出现如下界面,中间不需要输入密码,即配置完成。
# ssh localhost
2.4、 安装Oracle Java,并配置环境变量
2. 解压tar包,指定解压/usr/local/目录
# tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
3. 配置环境变量
# vim /etc/profile
然后添加以下配置在文件尾:
export JAVA_HOME=/usr/local/jdk1.8.0_211 export PATH=$PATH:$JAVA_HOME/bin export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
保存退出即可。
4. 测试jdk配置成功否
刷新环境变量:
# source /etc/profile
输入java -verion,如配置成功,有下图的java版本在终端上显示:

到此,hadoop需要的系统环境已经搭建完毕了,接下来开始搭建伪分布式hadoop集群~
三、搭建伪分布式hadoop集群
3.1 安装hadoop
从官网下载hadoop3.1.2,解压hadoop安装包到/usr/local/目录下:
# tar -zxvf hadoop-3.1.2.tar.gz -C /usr/local
在环境变量配置hadoop:
# vim /etc/profile
然后添加以下配置在文件尾:
export HADOOP_HOME=/usr/local/hadoop-3.1.2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_HDFS_HOME=/usr/local/hadoop-3.1.2 export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.2/etc/hadoop
使用source /etc/profile刷新环境变量后,用hadoop version命令测试是否安装成功:
# source /etc/profile
# hadoop version

3.2 伪分布式hadoop配置
hadoop的配置文件统一放在$HADOOP_HOME/etc/hadoop目录下,在这里我们只需要修改5个文件,分别是hadoop-env.sh,core-site.xml,mapred-site.xml,yarn-site.xml,yarn-site.xml。
1. hadoop-env.sh
在文件中修改如下:
export JAVA_HOME=/usr/local/jdk1.8.0_211 export HADOOP_HOME=/usr/local/hadoop-3.1.2
2. core-site.xml
<configuration>
<property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000/</value> </property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///usr/local/hadoop/data/dfs/namesecondary</value>
</property>
</configuration>
3. hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.http.address</name>
<value>luengmingbiao:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/dfs/data</value>
</property>
</configuration>
4. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. yarn-site.xml
<configuraion>
<property> <name>yarn.resourcemanager.hostname</name> <value>luengmingbiao</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.application.classpath</name> <value>/usr/local/hadoop-3.1.2/etc/hadoop:/usr/local/hadoop-3.1.2/share/hadoop/common/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/common/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/hdfs/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/mapreduce/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn:/usr/local/hadoop-3.1.2/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.1.2/share/hadoop/yarn/*</value> </property> </configuraion>
注: “yarn.application.classpath“可以通过在终端上输入如下命令获取:
# hadoop classpath
对hdfs(Hadoop Distributed File System)进行格式化,hdfs是用来存储数据的分布式文件系统。
# hdfs namenode -format
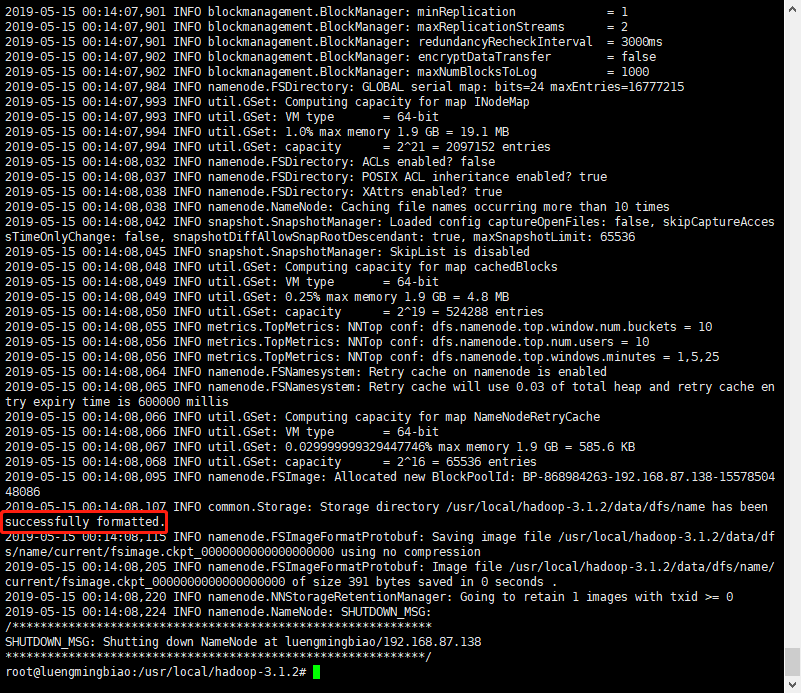
出现上述图所示,代表成功格式化。
Hadoop3.x以上版本在启动上有一个坑,不添加以下配置启动进程的时候会报以下的错并打印到终端上:
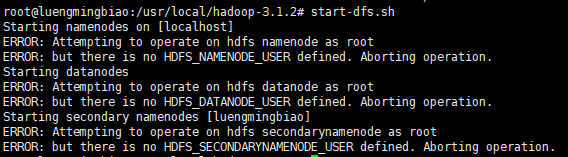
解决方案(可以只针对ERROR出现的变量进行定义,如果不行再配置全部):
# vim $HADOOP_HOME/sbin/start-dfs.sh

# vim $HADOOP_HOME/sbin/stop-dfs.sh

# vim $HADOOP_HOME/sbin/start-yarn.sh
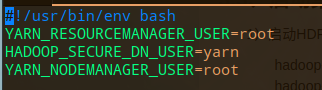
# vim $HADOOP_HOME/sbin/stop-yarn.sh
3.3 启动Hadoop
1. 启动HDFS
# hdfs --daemon start namenode # hdfs --daemon start datanode
# hdfs --daemon start secondarynamenode
或
# start-dfs.sh
2. 启动YARN集群
# yarn --daemon start resourcemanager
# yarn --daemon start nodemanager
或
# start-yarn.sh
3. jps命令查看是否启动成功
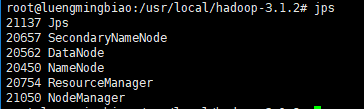
4. HDFS和YARN集群都有默认的Web可视化页面
HDFS: http://主机ip:50070
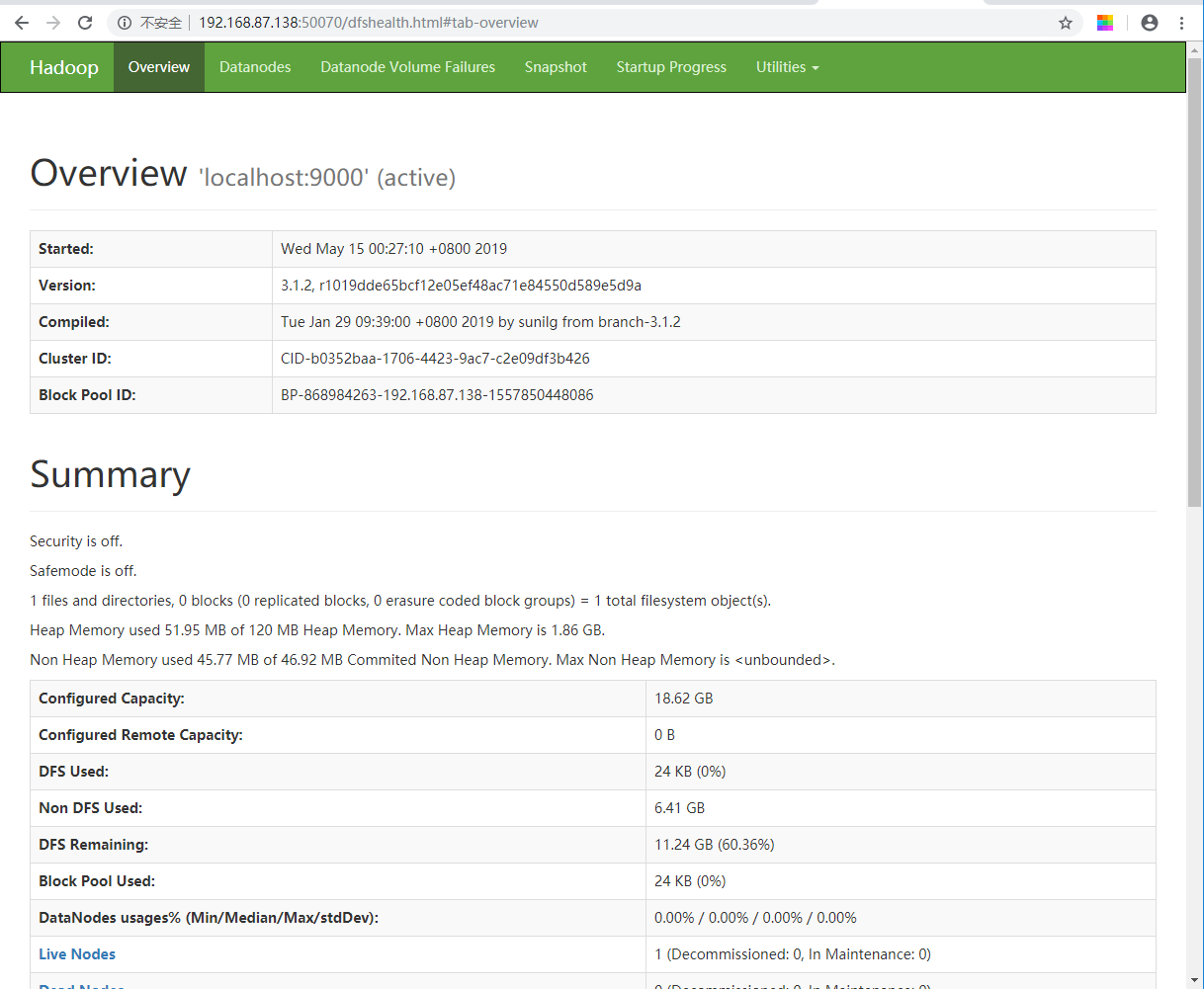
YARN:http://主机ip:8088
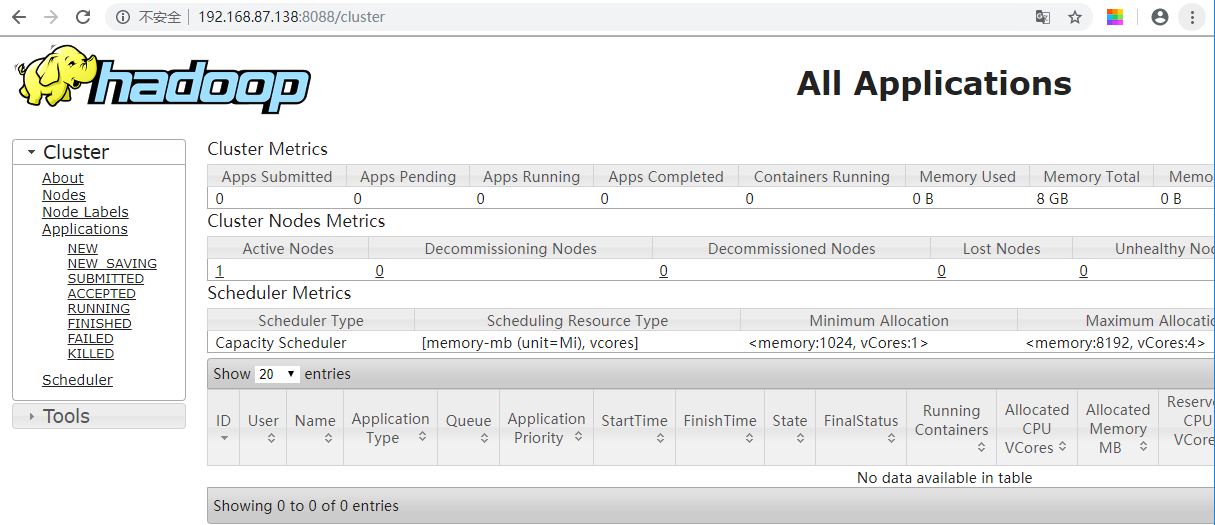
3.4 测试Hadoop
建立测试文件:
# vim test.txt
然后输入如下数据:
hello hadoop hello World Hello Java Hey man i am a programmer
将测试文件放到测试目录中:
# hdfs dfs -mkdir hdfs:///hadoop # hdfs dfs -mkdir hdfs:///hadoop/input # hdfs dfs -put ./test.txt hdfs:///hadoop/input
执行hadoop自带的wordcount程序:
# hadoop jar /usr/local/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount hdfs:///hadoop/input hdfs:///output


然后在命令行输入 hdfs dfs -cat hdfs:///output/part-r-00000 查看词频统计结果:
# hdfs dfs -cat hdfs:///output/part-r-00000
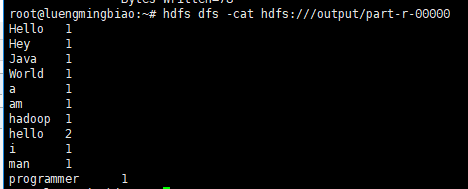
到此,伪分布式Hadoop已经搭建成功了~
作者:buildings
声明 :对于转载分享我是没有意见的,出于对博客园社区和作者的尊重请保留原文地址哈。
致读者 :坚持写博客不容易,写高质量博客更难,我也在不断的学习和进步,希望和所有同路人一道用技术来改变生活。觉得有点用就点个赞哈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号