I/O模型
I/O到底是什么?
I/O(input/output)是指内存与外部设备之间的交互(数据拷贝)。
- 磁盘 I/O
- 指的是硬盘和内存之间的输入输出。读取本地文件的时候,要将磁盘的数据拷贝到内存中,修改本地文件的时候,需要把修改后的数据拷贝到磁盘中
- 网络 I/O
- 指的是网卡与内存之间的输入输出。当网络上的数据到来时,网卡需要将数据拷贝到内存中。当要发送数据给网络上的其他人时,需要将数据从内存拷贝到网卡里
socket(套接字)通信
网络通信分为 TCP 与 UDP 两种,可以认为它们都是基于 socket 的,下面以 TCP 通信为例来阐述 socket 的通信流程。
1、创建 socket
首先服务端需要先创建一个 socket。在 Linux 中一切都是文件,那么创建的 socket 也是文件,每个文件都有一个整型的文件描述符(fd)来指代这个文件。
int socket(int domain, int type, int protocol);
- domain:用于选择通信的协议族,比如选择 IPv4 通信,还是 IPv6 通信等
- type:选择套接字类型,可选字节流套接字、数据报套接字等
- protocol:指定使用的协议
方法的返回值为 int ,其实就是创建的 socket 的 fd。
2、bind
服务器应用需要指明 IP 和端口,这样客户端才能请求相应服务。
创建的 socket 绑定地址和端口:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
- sockfd : 创建的 socket 的 fd
3、listen
执行了 socket、bind 之后,此时的 socket 还处于 closed 的状态,也就是不对外监听的,然后我们需要调用 listen 方法,让 socket 进入被动监听状态,这样的 socket 才能够监听到客户端的连接请求。
int listen(int sockfd, int backlog);
- backlog:Linux 使用两个队列分别存储已完成连接和半连接,且 backlog 仅为已完成连接的队列大小
4、accept
三次握手完成后的连接会被加入到已完成连接队列中:
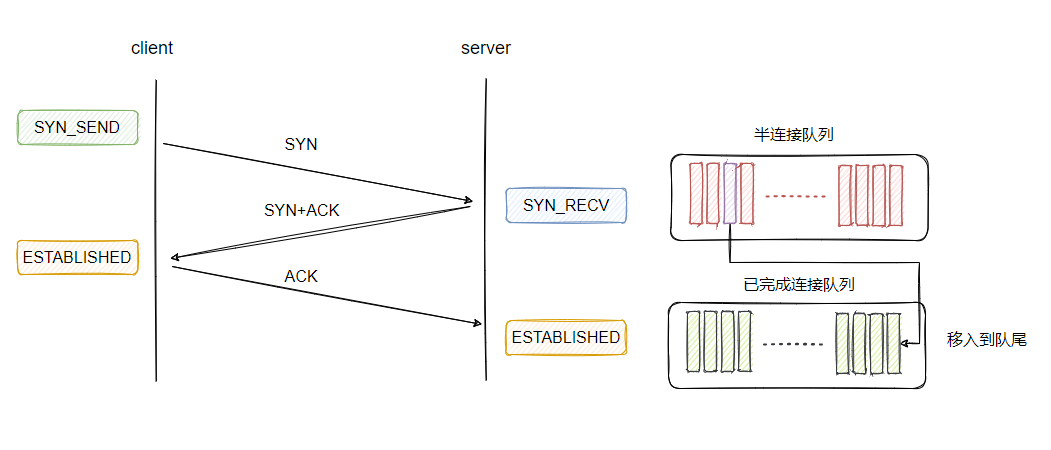
通过 accpet 从已完成连接队列中拿到连接进行处理:
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
方法返回的 int 值就是拿到的已完成连接的 socket 的文件描述符,之后操作这个 socket 就可以进行通信了。
如果已完成连接队列没有连接可以取,那么调用 accept 的线程会阻塞等待。
5、connect
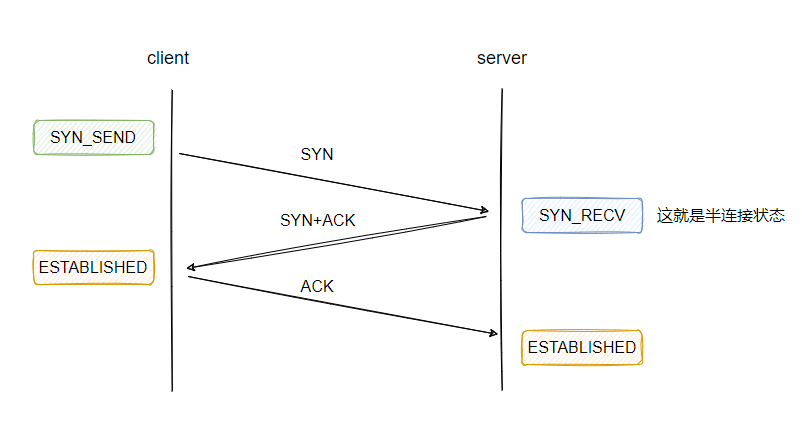
- 客户端调用 socket()创建一个 socket,并调用 connect 之后,连接处于 SYN_SEND 状态
- 收到服务端的 SYN+ACK 之后,连接就变为 ESTABLISHED 状态(代表三次握手完毕)
客户端这边不需要调用 bind 操作,默认会选择源 IP 和随机端口。
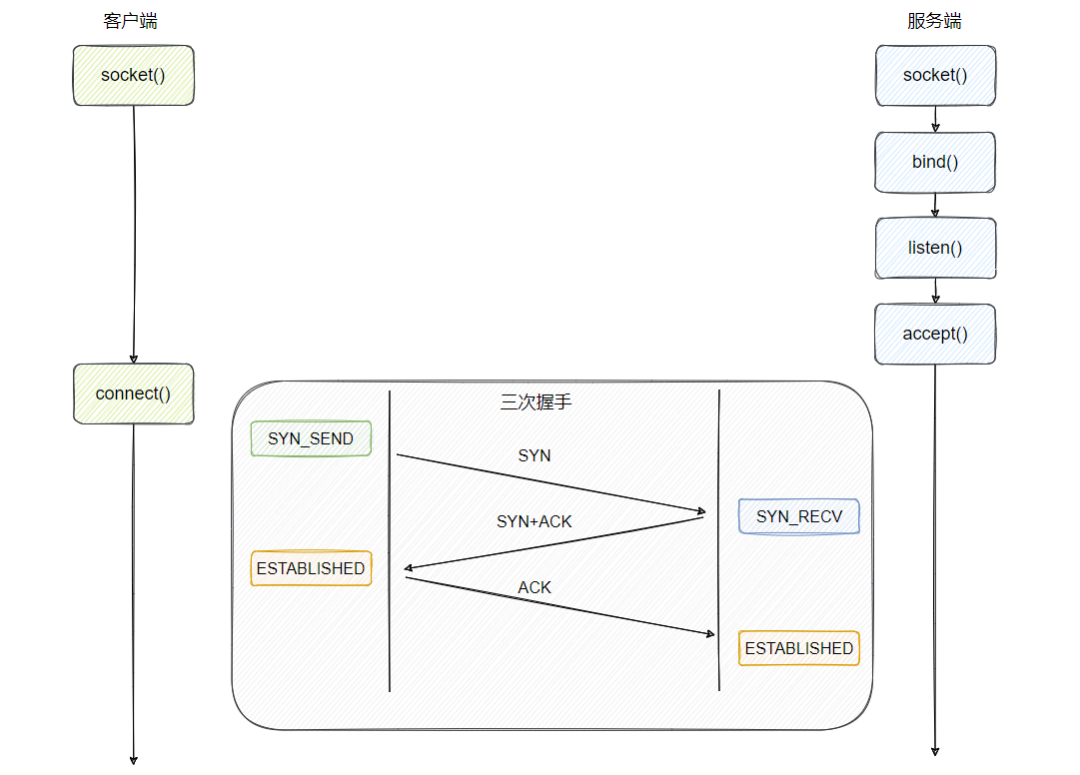
这里有两个阻塞点:
- connect:需要阻塞等待三次握手的完成
- accept:需要等待可用的已完成的连接,如果已完成连接队列为空,则被阻塞
6、read、write
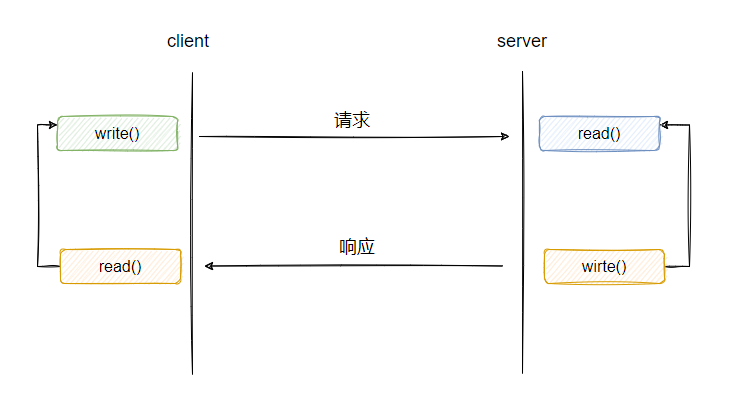
- read 为读数据
- 从服务端来看就是等待客户端的请求,如果客户端不发请求,那么调用 read 会处于阻塞等待状态
- write 为写数据
- 发送不是直接发出去,会把数据先拷贝到 TCP 的发送缓冲区,由 TCP 自行控制发送的时间和逻辑。如果发送缓存区满了, write 就会发生阻塞
read 和 write 都会发生阻塞。
I/O 模型
网络 I/O 会有很多阻塞点,阻塞 I/O 随着用户数的增长只能利用增加线程的方式来处理更多的请求,而线程不仅会占用内存资源且太多的线程竞争会导致频繁地上下文切换产生巨大的开销,因此提出了多种 I/O 模型。
在 UNIX 系统下,一共有五种 I/O 模型。
内核态和用户态
CPU 划分了非特权指令和特权指令,做了权限控制,一些危险的指令不会开放给普通程序,只会开放给操作系统等特权程序。普通程序要进行像内存的分配回收,磁盘文件读写,网络数据读写这些操作,只能调用操作系统开放出来的 API (系统调用)。
普通程序的代码是跑在用户空间上的,而操作系统的代码跑在内核空间上,用户空间无法直接访问内核空间的。
当一个进程运行在用户空间时就处于用户态,运行在内核空间时就处于内核态。
当处于用户空间的程序进行系统调用时,就会进行上下文的切换,切换到内核态中。
当程序请求获取网络数据的时候,需要经历两次拷贝:
- 程序需要等待数据从网卡拷贝到内核空间
- 因为用户程序无法访问内核空间,所以内核又得把数据拷贝到用户空间,这样处于用户空间的程序才能访问这个数据
五种 I/O 模型
1、同步阻塞 I/O
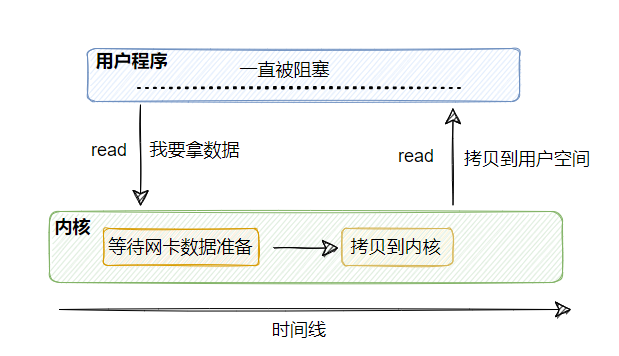
- 当用户程序的线程调用 read 获取网络数据的时候,网卡先将收到的客户端数据拷贝到内核中,然后再被拷贝到用户空间内,这整一个过程用户线程都是被阻塞的
- 假设没有客户端发数据过来,那么这个用户线程就会一直阻塞等着
优缺点
- 优点:简单。调用 read 之后就不管了,直到数据来了且准备好了进行处理即可
- 缺点:一个线程对应一个连接,一直被霸占着,即使网卡没有数据到来,也同步阻塞等着
2、同步非阻塞 I/O
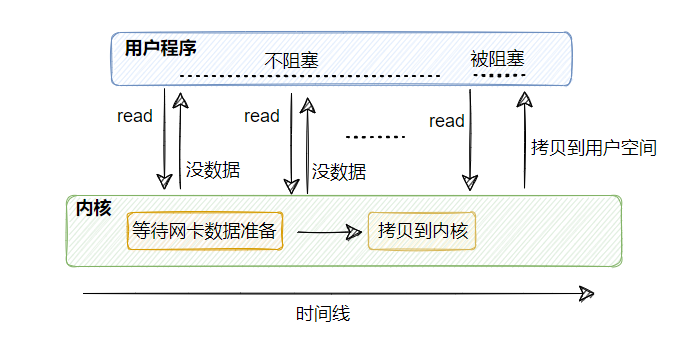
在没数据的时候直接返回错误,告知暂无准备就绪的数据。
- 从内核拷贝到用户空间这一步,用户线程还是会被阻塞的
这个模型相比于同步阻塞 I/O 而言比较灵活,比如调用 read 如果暂无数据,则线程可以先去干干别的事情,然后再来继续调用 read 看看有没有数据。但是如果服务器需要处理海量的连接,那么就有海量的线程不断调用,导致上下文切换频繁,CPU 也会做无用功而忙死。
3、I/O 多路复用
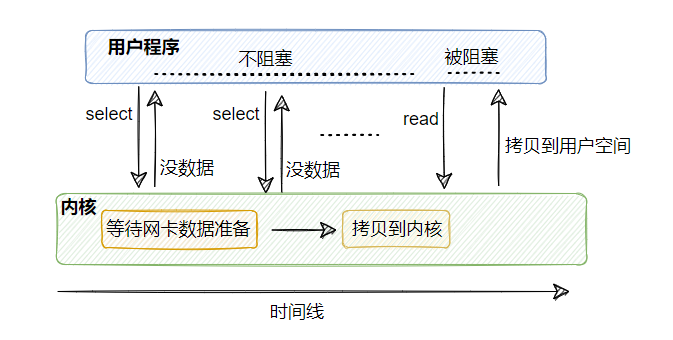
用专门的线程(select、poll、epoll)查看多个连接是否有数据已准备就绪。
专门的线程可以同时监控多个fd的操作,任何一个返回内核数据就绪,就通知别的线程来 read 读取数据,这个 read 和之前的一样,还是会阻塞用户线程。
这样用专门的线程去监控多条连接,减少了线程的数量,也降低了内存的消耗和上下文切换的次数。
4、信号驱动式I/O
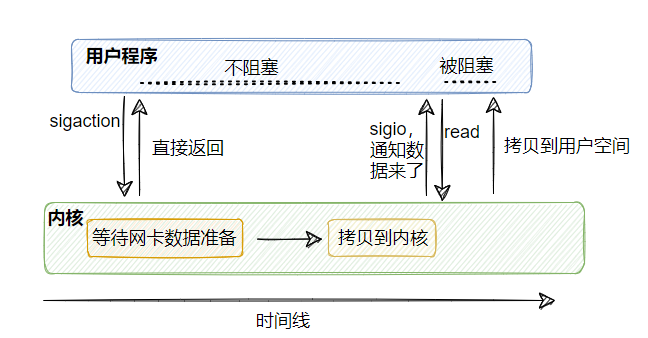
信号驱动 I/O :由内核告知数据已准备就绪,然后用户线程再去 read(还是会阻塞),不用 select 时刻去查询看看是否有数据已经准备就绪。
为什么市面上用的都是 I/O 多路复用而不是信号驱动?
一般的应用通常用的都是 TCP 协议,而 TCP 协议的 socket 可以产生信号事件有七种,这导致应用程序无法区分到底是什么事件产生的这个信号。只有当应用程序用的是 UDP 协议,这种协议不会产生那么多事件才能使用。
5、异步 I/O
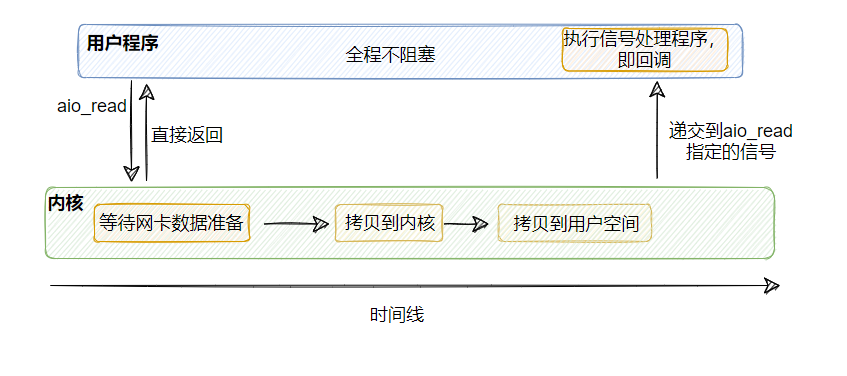
让内核直接把数据拷贝到用户空间之后再告知用户线程。在整个过程中,用户线程没有任何阻塞点,这才是真正的非阻塞I/O。
为什么常用的还是I/O多路复用,而不是异步I/O?
因为 Linux 对异步 I/O 的支持不足,可以认为还未完全实现,所以用不了异步 I/O。
select/poll/epoll
select/poll/epoll 是用来实现多路复用的。
select/poll
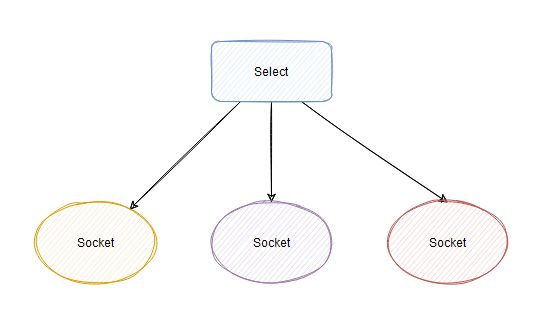
应用进程通过调用select函数,可以同时监控多个fd,在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数就会返回可读状态。如果没有一个 socket 有事件发生,那么 select 的线程就需要让出 cpu 阻塞等待。
睡眠队列
每个 socket 有个属于自己的睡眠队列,select 会把其管理的 socket 的睡眠队列里塞入一个 entry。
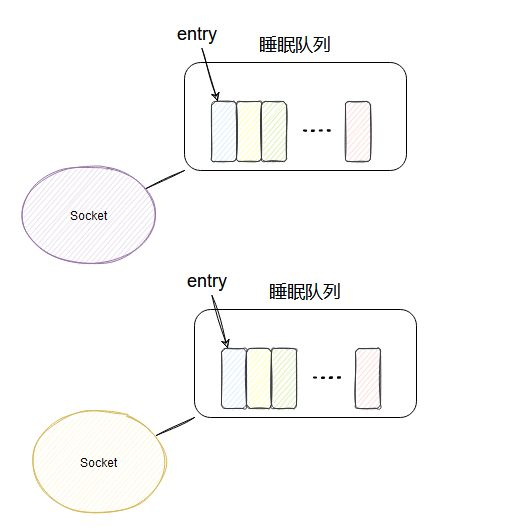
当 socket 接收到网卡的数据后,就会去它的睡眠队列里遍历 entry,调用 entry 设置的 callback 方法唤醒 select。
select 被唤醒时并不知道具体是哪个 socket 来数据了,只能遍历所有 socket ,然后把所有来数据的 socket 封装成事件返回。
select 的限制
因为被管理的 socket fd 需要从用户空间拷贝到内核空间,为了控制拷贝的大小而做了限制,即每个 select 能拷贝的 fds 集合大小只有1024。
poll
poll 相对于 select 主要是优化了 fds 的结构,不再是 bit 数组,也就没有了 1024 的限制。
epoll
为了解决select/poll存在的问题,多路复用模型epoll诞生,它采用事件驱动来实现。
优化:
- 在内核里维护监控的 fds
- 唤醒时知道哪个 socket 来数据了
epoll_ctl
用来管理维护 epoll 所监控的哪些 socket。
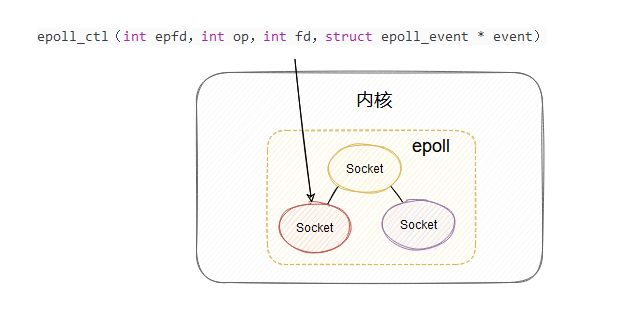
在内核里面就维护了此 epoll 管理的 socket 集合,这样就不用每次调用的时候都得把所有管理的 fds 拷贝到内核了。
- socket 集合是用红黑树实现的
ready_list
和 select 类似,每个 socket 的睡眠队列里都会加个 entry,当每个 socket 来数据之后,同样也会调用 entry 对应的 callback。
除此之外还引入了一个 ready_list 双向链表,callback 里面会把当前的 socket 加入到 ready_list 然后唤醒 epoll。
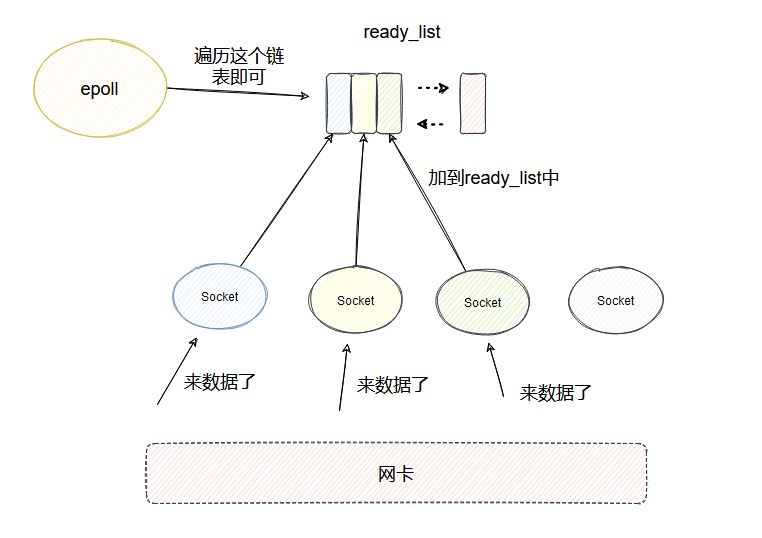
这样被唤醒的 epoll 只需要遍历 ready_list 即可,这个链表里一定是有数据可读的 socket,相比于 select 就不会做无用的遍历了。
MySQL为什么不用 epoll
MySQL使用的是 select+线程池,因为网络I/O接收请求特别快,但是在实际数据操作,因为涉及磁盘I/O导致DB层处理非常慢,所以没有必要去用epoll。
Mysql 的整个任务是把数据组织成树表,在磁盘和内存之间进行转换,并且进行大量的查找和排序,所有这些操作花费的时间都很长。假设每次操作平均占用 30 ms,而通过网络返回只需要 1 ms,则总花费 31 ms。时间主要花费在 cpu 和内存占用,而不是网络等待上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号