搭建RNN和字符级语言模型
搭建RNN
声明:

1 - RNN的前向传播
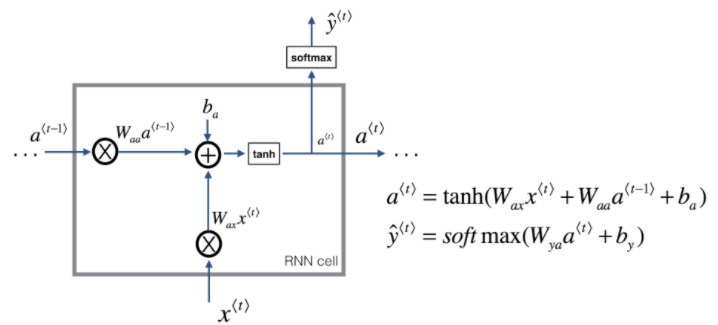
1.1 - RNN单元

from torch.nn.parameter import Parameter #参数更新和优化函数
from collections import Counter #Counter 计数器
import numpy as np
import random
import math
import time
import cllm_utils
import pandas as pd
import scipy #SciPy是基于NumPy开发的高级模块,它提供了许多数学算法和函数的实现
import sklearn
from sklearn.metrics.pairwise import cosine_similarity #余弦相似度函数
```python
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def rnn_cell_forward(xt, a_prev, parameters):
"""
参数:
xt -- 时间步“t”输入的数据,维度为(n_x, m)
a_prev -- 时间步“t - 1”的隐藏隐藏状态,维度为(n_a, m) # n_a是RNN神经单元数量
parameters -- 字典,包含了以下内容:
Wax -- 矩阵,输入乘以权重,维度为(n_a, n_x)
Waa -- 矩阵,隐藏状态乘以权重,维度为(n_a, n_a)
Wya -- 矩阵,隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
ba -- 偏置,维度为(n_a, 1)
by -- 偏置,隐藏状态与输出相关的偏置,维度为(n_y, 1)
返回:
a_next -- 下一个隐藏状态,维度为(n_a, m)
yt_pred -- 在时间步“t”的预测,维度为(n_y, m)
cache -- 反向传播需要的元组,包含了(a_next, a_prev, xt, parameters)
"""
# 从“parameters”获取参数
Wax = parameters["Wax"]
Waa = parameters["Waa"]
Wya = parameters["Wya"]
ba = parameters["ba"]
by = parameters["by"]
# 计算下一个激活值
a_next = np.tanh(np.dot(Waa, a_prev) + np.dot(Wax, xt) + ba)
# 使计算当前单元的输出
yt_pred = softmax(np.dot(Wya, a_next) + by)
# 保存反向传播需要的值
cache = (a_next, a_prev, xt, parameters)
return a_next, yt_pred, cache
测试:
np.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
Waa = np.random.randn(5,5)
Wax = np.random.randn(5,3)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", a_next.shape)
print("yt_pred[1] =", yt_pred[1])
print("yt_pred.shape = ", yt_pred.shape)
a_next[4] = [ 0.59584544 0.18141802 0.61311866 0.99808218 0.85016201 0.99980978
-0.18887155 0.99815551 0.6531151 0.82872037]
a_next.shape = (5, 10)
yt_pred[1] = [0.9888161 0.01682021 0.21140899 0.36817467 0.98988387 0.88945212
0.36920224 0.9966312 0.9982559 0.17746526]
yt_pred.shape = (2, 10)
1.2 - RNN的前向传播
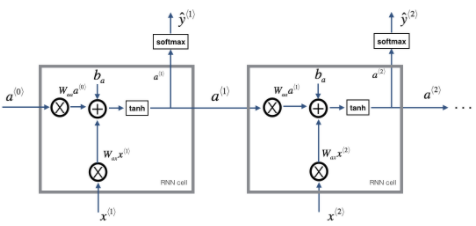
步骤:

def rnn_forward(x, a0, parameters):
"""
参数:
x -- 输入的全部数据,维度为(n_x, m, T_x)
a0 -- 初始化隐藏状态,维度为 (n_a, m)
parameters -- 字典,包含了以下内容:
Wax -- 矩阵,输入乘以权重,维度为(n_a, n_x)
Waa -- 矩阵,隐藏状态乘以权重,维度为(n_a, n_a)
Wya -- 矩阵,隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
ba -- 偏置,维度为(n_a, 1)
by -- 偏置,隐藏状态与输出相关的偏置,维度为(n_y, 1)
返回:
a -- 所有时间步的隐藏状态,维度为(n_a, m, T_x)
y_pred -- 所有时间步的预测,维度为(n_y, m, T_x)
caches -- 为反向传播的保存的元组,维度为(【列表类型】cache, x))
"""
caches = []
# 获取 x 与 Wya 的维度信息
n_x, m, T_x = x.shape # T_x时间步
n_y, n_a = parameters["Wya"].shape
# 使用0来初始化“a” 与“y”
a = np.zeros([n_a, m, T_x])
y_pred = np.zeros([n_y, m, T_x])
# 初始化“next”
a_next = a0
# 遍历所有时间步
for t in range(T_x):
# 1.使用rnn_cell_forward函数来更新“next”隐藏状态与cache
a_next, yt_pred, cache = rnn_cell_forward(x[:, :, t], a_next, parameters)
# 2.使用 a 来保存“next”隐藏状态(第 t )个位置
a[:, :, t] = a_next
# 3.使用 y 来保存预测值
y_pred[:, :, t] = yt_pred
# 4.把cache保存到“caches”列表中
caches.append(cache)
# 保存反向传播所需要的参数
caches = (caches, x) # 维度为(【列表类型】cache, x))
return a, y_pred, caches
np.random.seed(1)
x = np.random.randn(3,10,4)
a0 = np.random.randn(5,10)
Waa = np.random.randn(5,5)
Wax = np.random.randn(5,3)
Wya = np.random.randn(2,5)
ba = np.random.randn(5,1)
by = np.random.randn(2,1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}
a, y_pred, caches = rnn_forward(x, a0, parameters)
print("a[4][1] = ", a[4][1])
print("a.shape = ", a.shape)
print("y_pred[1][3] =", y_pred[1][3])
print("y_pred.shape = ", y_pred.shape)
print("caches[1][1][3] =", caches[1][1][3])
print("len(caches) = ", len(caches))
a[4][1] = [-0.99999375 0.77911235 -0.99861469 -0.99833267]
a.shape = (5, 10, 4)
y_pred[1][3] = [0.79560373 0.86224861 0.11118257 0.81515947]
y_pred.shape = (2, 10, 4)
caches[1][1][3] = [-1.1425182 -0.34934272 -0.20889423 0.58662319]
len(caches) = 2
2 - LSTM网络
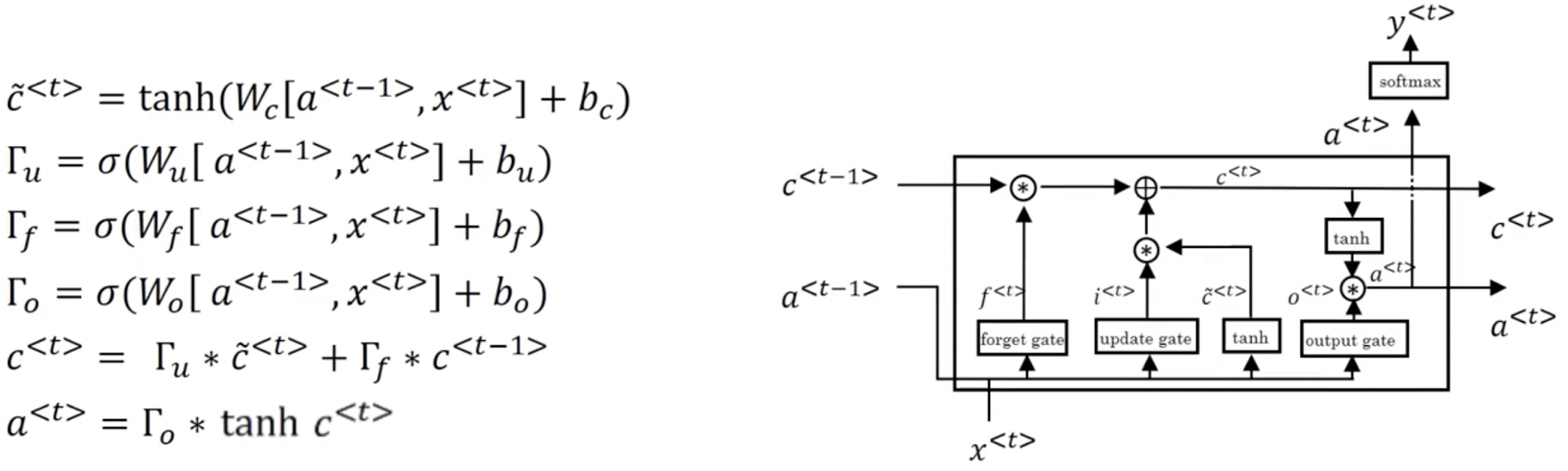
遗忘门;更新门;输出门
2.1 - LSTM单元
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def lstm_cell_forward(xt, a_prev, c_prev, parameters):
"""
参数:
xt -- 在时间步“t”输入的数据,维度为(n_x, m)
a_prev -- 上一个时间步“t-1”的隐藏状态,维度为(n_a, m)
c_prev -- 上一个时间步“t-1”的记忆状态,维度为(n_a, m)
parameters -- 字典类型的变量,包含了:
Wf -- 遗忘门的权值,维度为(n_a, n_a + n_x)
bf -- 遗忘门的偏置,维度为(n_a, 1)
Wi -- 更新门的权值,维度为(n_a, n_a + n_x)
bi -- 更新门的偏置,维度为(n_a, 1)
Wc -- 第一个“tanh”的权值,维度为(n_a, n_a + n_x)
bc -- 第一个“tanh”的偏置,维度为(n_a, n_a + n_x)
Wo -- 输出门的权值,维度为(n_a, n_a + n_x)
bo -- 输出门的偏置,维度为(n_a, 1)
Wy -- 隐藏状态与输出相关的权值,维度为(n_y, n_a)
by -- 隐藏状态与输出相关的偏置,维度为(n_y, 1)
返回:
a_next -- 下一个隐藏状态,维度为(n_a, m)
c_next -- 下一个记忆状态,维度为(n_a, m)
yt_pred -- 在时间步“t”的预测,维度为(n_y, m)
cache -- 包含了反向传播所需要的参数,包含了(a_next, c_next, a_prev, c_prev, xt, parameters)
注意:
ft/it/ot表示遗忘/更新/输出门,cct表示候选值(c tilda),c表示记忆值。
"""
# 从“parameters”中获取相关值
Wf = parameters["Wf"]
bf = parameters["bf"]
Wi = parameters["Wi"]
bi = parameters["bi"]
Wc = parameters["Wc"]
bc = parameters["bc"]
Wo = parameters["Wo"]
bo = parameters["bo"]
Wy = parameters["Wy"]
by = parameters["by"]
# 获取 xt 与 Wy 的维度信息
n_x, m = xt.shape
n_y, n_a = Wy.shape
# 1.连接 a_prev 与 xt
contact = np.zeros([n_a + n_x, m])
contact[:n_a, :] = a_prev
contact[n_a:, :] = xt
# 2.根据公式计算ft、it、cct、c_next、ot、a_next
## 遗忘门
ft = sigmoid(np.dot(Wf, contact) + bf)
## 更新门
it = sigmoid(np.dot(Wi, contact) + bi)
cct = np.tanh(np.dot(Wc, contact) + bc)
c_next = ft * c_prev + it * cct
## 输出门
ot = sigmoid(np.dot(Wo, contact) + bo)
a_next = ot * np.tanh(c_next)
# 3.计算LSTM单元的预测值
yt_pred = softmax(np.dot(Wy, a_next) + by)
# 保存包含了反向传播所需要的参数
cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
return a_next, c_next, yt_pred, cache
测试:
np.random.seed(1)
xt = np.random.randn(3,10)
a_prev = np.random.randn(5,10)
c_prev = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a_next, c_next, yt, cache = lstm_cell_forward(xt, a_prev, c_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", c_next.shape)
print("c_next[2] = ", c_next[2])
print("c_next.shape = ", c_next.shape)
print("yt[1] =", yt[1])
print("yt.shape = ", yt.shape)
print("cache[1][3] =", cache[1][3])
print("len(cache) = ", len(cache))
a_next[4] = [-0.66408471 0.0036921 0.02088357 0.22834167 -0.85575339 0.00138482
0.76566531 0.34631421 -0.00215674 0.43827275]
a_next.shape = (5, 10)
c_next[2] = [ 0.63267805 1.00570849 0.35504474 0.20690913 -1.64566718 0.11832942
0.76449811 -0.0981561 -0.74348425 -0.26810932]
c_next.shape = (5, 10)
yt[1] = [0.79913913 0.15986619 0.22412122 0.15606108 0.97057211 0.31146381
0.00943007 0.12666353 0.39380172 0.07828381]
yt.shape = (2, 10)
cache[1][3] = [-0.16263996 1.03729328 0.72938082 -0.54101719 0.02752074 -0.30821874
0.07651101 -1.03752894 1.41219977 -0.37647422]
len(cache) = 10
2.2 - LSTM的前向传播
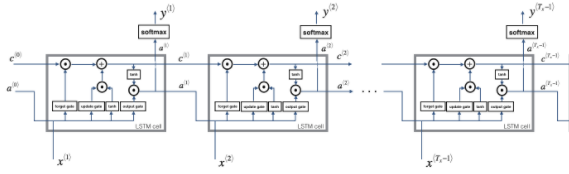
def lstm_forward(x, a0, parameters):
"""
参数:
x -- 所有时间步的输入数据,维度为(n_x, m, T_x)
a0 -- 初始化隐藏状态,维度为(n_a, m)
parameters -- python字典,包含了以下参数:
Wf -- 遗忘门的权值,维度为(n_a, n_a + n_x)
bf -- 遗忘门的偏置,维度为(n_a, 1)
Wi -- 更新门的权值,维度为(n_a, n_a + n_x)
bi -- 更新门的偏置,维度为(n_a, 1)
Wc -- 第一个“tanh”的权值,维度为(n_a, n_a + n_x)
bc -- 第一个“tanh”的偏置,维度为(n_a, n_a + n_x)
Wo -- 输出门的权值,维度为(n_a, n_a + n_x)
bo -- 输出门的偏置,维度为(n_a, 1)
Wy -- 隐藏状态与输出相关的权值,维度为(n_y, n_a)
by -- 隐藏状态与输出相关的偏置,维度为(n_y, 1)
返回:
a -- 所有时间步的隐藏状态,维度为(n_a, m, T_x)
y -- 所有时间步的预测值,维度为(n_y, m, T_x)
caches -- 为反向传播的保存的元组,维度为(【列表类型】cache, x))
"""
caches = []
# 获取 xt 与 Wy 的维度信息
n_x, m, T_x = x.shape
n_y, n_a = parameters["Wy"].shape
# 使用0来初始化“a”、“c”、“y”
a = np.zeros([n_a, m, T_x])
c = np.zeros([n_a, m, T_x])
y = np.zeros([n_y, m, T_x])
# 初始化“a_next”、“c_next”
a_next = a0
c_next = np.zeros([n_a, m])
# 遍历所有的时间步
for t in range(T_x):
# 更新下一个隐藏状态,下一个记忆状态,计算预测值,获取cache
a_next, c_next, yt_pred, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters)
# 保存新的下一个隐藏状态到变量a中
a[:, :, t] = a_next
# 保存下一个单元状态到变量c中
c[:, :, t] = c_next
# 保存预测值到变量y中
y[:, :, t] = yt_pred
# 把cache添加到caches中
caches.append(cache)
caches = (caches, x)
return a, y, c, caches
np.random.seed(1)
x = np.random.randn(3,10,7)
a0 = np.random.randn(5,10)
Wf = np.random.randn(5, 5+3)
bf = np.random.randn(5,1)
Wi = np.random.randn(5, 5+3)
bi = np.random.randn(5,1)
Wo = np.random.randn(5, 5+3)
bo = np.random.randn(5,1)
Wc = np.random.randn(5, 5+3)
bc = np.random.randn(5,1)
Wy = np.random.randn(2,5)
by = np.random.randn(2,1)
parameters = {"Wf": Wf, "Wi": Wi, "Wo": Wo, "Wc": Wc, "Wy": Wy, "bf": bf, "bi": bi, "bo": bo, "bc": bc, "by": by}
a, y, c, caches = lstm_forward(x, a0, parameters)
print("a[4][3][6] = ", a[4][3][6])
print("a.shape = ", a.shape)
print("y[1][4][3] =", y[1][4][3])
print("y.shape = ", y.shape)
print("caches[1][1[1]] =", caches[1][1][1])
print("c[1][2][1]", c[1][2][1])
print("len(caches) = ", len(caches))
a[4][3][6] = 0.17211776753291672
a.shape = (5, 10, 7)
y[1][4][3] = 0.9508734618501101
y.shape = (2, 10, 7)
caches[1][1[1]] = [ 0.82797464 0.23009474 0.76201118 -0.22232814 -0.20075807 0.18656139
0.41005165]
c[1][2][1] -0.8555449167181982
len(caches) = 2
字符级语言模型 - 恐龙岛
1 - 数据集与预处理
# 获取名称
data = open("./datasets/dinos.txt", "r").read()
# 转化为小写字符
data = data.lower()
# 转化为无序且不重复的元素列表。字符是a-z(26个英文字符)加上“\n”(换行字符)
chars = list(set(data))
# 获取大小信息
data_size, vocab_size = len(data), len(chars)
print(chars)
print("共计有%d个字符,唯一字符有%d个"%(data_size,vocab_size))
['p', 'e', 'n', 'g', 'b', 'q', 'r', 's', 'w', 'l', 'o', 't', 'd', 'z', '\n', 'm', 'a', 'i', 'f', 'u', 'j', 'h', 'k', 'x', 'y', 'v', 'c']
共计有19909个字符,唯一字符有27个
- char_to_ix:创建一个字典,每个字符映射到0-26的索引
- ix_to_char:将每个索引映射回相应的字符字符,它能帮助找出softmax层的概率分布输出中的字符
char_to_ix = {ch:i for i, ch in enumerate(sorted(chars))}
ix_to_char = {i:ch for i, ch in enumerate(sorted(chars))}
print(char_to_ix)
print()
print(ix_to_char)
{'\n': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10, 'k': 11, 'l': 12, 'm': 13, 'n': 14, 'o': 15, 'p': 16, 'q': 17, 'r': 18, 's': 19, 't': 20, 'u': 21, 'v': 22, 'w': 23, 'x': 24, 'y': 25, 'z': 26}
{0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
2 - 构建模块
- 梯度修剪:避免梯度爆炸
- 取样:一种用来产生字符的技术
2.1 梯度修剪
实现一个修剪函数,该函数输入一个梯度字典输出一个已经修剪过了的梯度。
这里使用一个比较简单的方法:梯度向量的每一个元素都被限制在[-N,N]的范围。比如有一个maxValue = 10,如果梯度的任何值大于10,那么它将被设置为10,如果梯度的任何值小于-10,那么它将被设置为-10,如果它在-10与10之间,那么它将不变。
np.clip(a, a_min, a_max, out=None):是一个截取函数,用于截取数组中小于或者大于某值的部分,并使得被截取部分等于固定值。
- a:输入矩阵;
- a_min:被限定的最小值,所有比a_min小的数都会强制变为a_min;
- a_max:被限定的最大值,所有比a_max大的数都会强制变为a_max;
- out:可以指定输出矩阵的对象,shape与a相同
def clip(gradients, maxValue):
"""
使用maxValue来修剪梯度
参数:
gradients -- 字典类型,包含了以下参数:"dWaa", "dWax", "dWya", "db", "dby"
maxValue -- 阈值,把梯度值限制在[-maxValue, maxValue]内
返回:
gradients -- 修剪后的梯度
"""
# 获取参数
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
# 梯度修剪
for gradient in [dWaa, dWax, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
gradients["dWaa"][1][2] = 10.0
gradients["dWax"][3][1] = -10.0
gradients["dWya"][1][2] = 0.2971381536101662
gradients["db"][4] = [10.]
gradients["dby"][1] = [8.45833407]
2.2 - 采样
假设模型已经训练过了,希望生成新的文本:
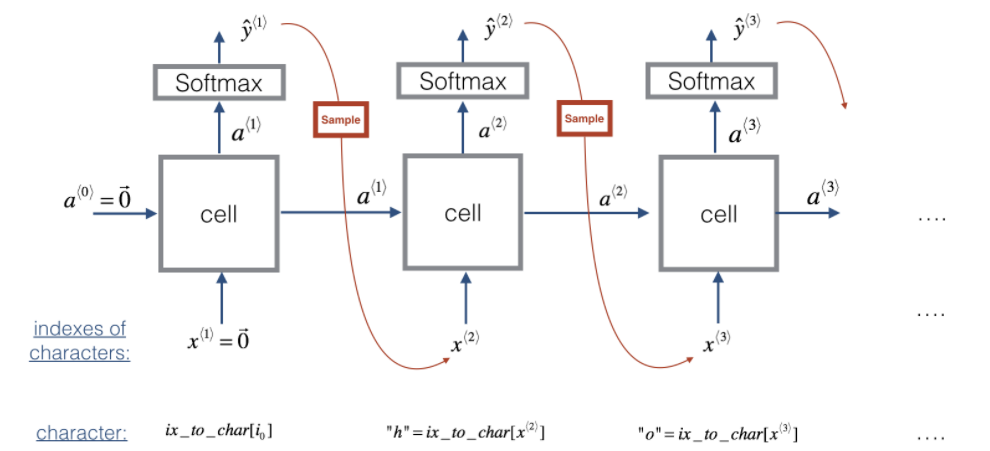
采样:
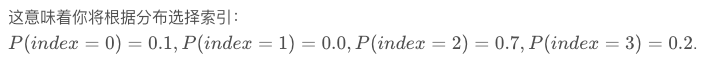
# np.random.seed(0)
# p = np.array([0.1, 0.0, 0.7, 0.2])
# index = np.random.choice([0, 1, 2, 3], p = p.ravel()) # p(2) = 0.7意味着index = 2的概率最大
# index
def sample(parameters, char_to_is, seed):
"""
根据RNN输出的概率分布序列对字符序列进行采样
参数:
parameters -- 字典,包含Waa, Wax, Wya, by, b
char_to_ix -- 字符映射到索引的字典
seed -- 随机种子
返回:
indices -- 包含采样字符索引的长度为n的列表。
"""
# 从parameters 中获取参数
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
# 步骤1
## 创建向量x
x = np.zeros((vocab_size,1)) # x开始输入也是0,自动采样输出一段文字
## 使用0初始化a_prev
a_prev = np.zeros((n_a,1))
# 创建索引的空列表,这是包含要生成的字符的索引的列表。
indices = []
# IDX是检测换行符的标志,初始化为-1。
idx = -1
# 循环遍历时间步骤t。在每个时间步中,从概率分布中抽取一个字符,并将其索引附加到“indices”上
# 如果达到50个字符,就停止循环(有助于调试并防止进入无限循环)
counter = 0
newline_character = char_to_ix["\n"]
while (idx != newline_character and counter < 50):
# 步骤2:前向传播
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z) # [vocab_size, 1]?
# 设定随机种子
np.random.seed(counter + seed)
# 步骤3:从概率分布y中抽取词汇表中字符的索引
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
# 添加到索引中
indices.append(idx)
# 步骤4:将输入字符重写为与采样索引对应的字符。
x = np.zeros((vocab_size,1))
x[idx] = 1 # one-hot表示
# 更新a_prev为a
a_prev = a
# 累加器
seed += 1
counter +=1
if(counter == 50):
indices.append(char_to_ix["\n"])
return indices
np.random.seed(2)
_, n_a = 20, 100
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indices)
print()
print("list of sampled characters:", [ix_to_char[i] for i in indices])
Sampling:
list of sampled indices: [12, 17, 24, 14, 13, 9, 10, 22, 24, 6, 13, 11, 12, 6, 21, 15, 21, 14, 3, 2, 1, 21, 18, 24, 7, 25, 6, 25, 18, 10, 16, 2, 3, 8, 15, 12, 11, 7, 1, 12, 10, 2, 7, 7, 11, 17, 24, 12, 19, 1, 0]
list of sampled characters: ['l', 'q', 'x', 'n', 'm', 'i', 'j', 'v', 'x', 'f', 'm', 'k', 'l', 'f', 'u', 'o', 'u', 'n', 'c', 'b', 'a', 'u', 'r', 'x', 'g', 'y', 'f', 'y', 'r', 'j', 'p', 'b', 'c', 'h', 'o', 'l', 'k', 'g', 'a', 'l', 'j', 'b', 'g', 'g', 'k', 'q', 'x', 'l', 's', 'a', '\n']
3 - 构建语言模型
3.1 - 梯度下降
实现一个执行随机梯度下降的一个步骤的函数(带有梯度修剪):
-
前向传播计算损失
-
反向传播计算关于参数的梯度损失
-
修剪梯度
-
使用梯度下降更新参数
# def rnn_backward(X, Y, parameters, cache):
# # Initialize gradients as an empty dictionary
# gradients = {}
# # Retrieve from cache and parameters
# (y_hat, a, x) = cache
# Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
# # each one should be initialized to zeros of the same dimension as its corresponding parameter
# gradients['dWax'], gradients['dWaa'], gradients['dWya'] = np.zeros_like(Wax), np.zeros_like(Waa), np.zeros_like(Wya)
# gradients['db'], gradients['dby'] = np.zeros_like(b), np.zeros_like(by)
# gradients['da_next'] = np.zeros_like(a[0])
# ### START CODE HERE ###
# # Backpropagate through time
# for t in reversed(range(len(X))):
# dy = np.copy(y_hat[t])
# dy[Y[t]] -= 1
# gradients = rnn_step_backward(dy, gradients, parameters, x[t], a[t], a[t-1])
# ### END CODE HERE ###
# return gradients, a
# def update_parameters(parameters, gradients, lr):
# parameters['Wax'] += -lr * gradients['dWax']
# parameters['Waa'] += -lr * gradients['dWaa']
# parameters['Wya'] += -lr * gradients['dWya']
# parameters['b'] += -lr * gradients['db']
# parameters['by'] += -lr * gradients['dby']
# return parameters
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
执行训练模型的单步优化
参数:
X -- 整数列表,其中每个整数映射到词汇表中的字符。
Y -- 整数列表,与X完全相同,但向左移动了一个索引。
a_prev -- 上一个隐藏状态
parameters -- 字典,包含了以下参数:
Wax -- 权重矩阵乘以输入,维度为(n_a, n_x)
Waa -- 权重矩阵乘以隐藏状态,维度为(n_a, n_a)
Wya -- 隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
b -- 偏置,维度为(n_a, 1)
by -- 隐藏状态与输出相关的权重偏置,维度为(n_y, 1)
learning_rate -- 模型学习的速率
返回:
loss -- 损失函数的值(交叉熵损失)
gradients -- 字典,包含了以下参数:
dWax -- 输入到隐藏的权值的梯度,维度为(n_a, n_x)
dWaa -- 隐藏到隐藏的权值的梯度,维度为(n_a, n_a)
dWya -- 隐藏到输出的权值的梯度,维度为(n_y, n_a)
db -- 偏置的梯度,维度为(n_a, 1)
dby -- 输出偏置向量的梯度,维度为(n_y, 1)
a[len(X)-1] -- 最后的隐藏状态,维度为(n_a, 1)
"""
# 前向传播
loss, cache = cllm_utils.rnn_forward(X, Y, a_prev, parameters)
# 反向传播
gradients, a = cllm_utils.rnn_backward(X, Y, parameters, cache)
# 梯度修剪,[-5 , 5]
gradients = clip(gradients,5)
# 更新参数
parameters = cllm_utils.update_parameters(parameters,gradients,learning_rate)
return loss, gradients, a[len(X)-1]
测试:
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])
Loss = 126.5039757216534
gradients["dWaa"][1][2] = 0.19470931534726443
np.argmax(gradients["dWax"]) = 93
gradients["dWya"][1][2] = -0.007773876032004488
gradients["db"][4] = [-0.06809825]
gradients["dby"][1] = [0.01538192]
a_last[4] = [-1.]
3.2 - 训练模型
- 使用数据集的每一行(一个名称)作为一个训练样本
- 每100步随机梯度下降,抽样10个随机选择的名字,看看算法是怎么做的
- 打乱数据集,以便随机梯度下降以随机顺序访问样本
def model(data, ix_to_char, char_to_ix, num_iterations=3500,
n_a=50, dino_names=7,vocab_size=27):
"""
训练模型并生成恐龙名字
参数:
data -- 语料库
ix_to_char -- 索引映射字符字典
char_to_ix -- 字符映射索引字典
num_iterations -- 迭代次数
n_a -- RNN单元数量
dino_names -- 每次迭代中采样的数量(生成的个数)
vocab_size -- 在文本中的唯一字符的数量
返回:
parameters -- 学习后了的参数
"""
# 从vocab_size中获取n_x、n_y
n_x, n_y = vocab_size, vocab_size
# 初始化参数
parameters = cllm_utils.initialize_parameters(n_a, n_x, n_y)
# 初始化损失
loss = cllm_utils.get_initial_loss(vocab_size, dino_names)
# 构建恐龙名称列表
with open("./datasets/dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# 打乱全部的恐龙名称
np.random.seed(0)
np.random.shuffle(examples)
# 初始化LSTM隐藏状态
a_prev = np.zeros((n_a,1))
# 循环
for j in range(num_iterations):
# 定义一个训练样本
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]] # X[i]的预测是Y[i]
# 执行单步优化:前向传播 -> 反向传播 -> 梯度修剪 -> 更新参数
# 选择学习率为0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
# 使用延迟来保持损失平滑,加速训练
loss = cllm_utils.smooth(loss, curr_loss)
# 每2000次迭代
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss))
# seed = 0
# for name in range(dino_names):
# # 采样,通过sample()生成“\n”字符,检查模型是否学习正确
# sampled_indices = sample(parameters, char_to_ix, seed)
# cllm_utils.print_sample(sampled_indices, ix_to_char)
# # 为了得到相同的效果,随机种子+1
# seed += 1
# print("\n")
return parameters
#开始时间
start_time = time.clock()
#开始训练
parameters = model(data, ix_to_char, char_to_ix, num_iterations=35000)
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")
Iteration: 0, Loss: 23.087336
Iteration: 2000, Loss: 27.884160
Iteration: 4000, Loss: 25.901815
Iteration: 6000, Loss: 24.608779
Iteration: 8000, Loss: 24.070350
Iteration: 10000, Loss: 23.844446
Iteration: 12000, Loss: 23.291971
Iteration: 14000, Loss: 23.382338
Iteration: 16000, Loss: 23.257770
Iteration: 18000, Loss: 22.870333
Iteration: 20000, Loss: 22.998602
Iteration: 22000, Loss: 22.784517
Iteration: 24000, Loss: 22.615296
Iteration: 26000, Loss: 22.792294
Iteration: 28000, Loss: 22.552533
Iteration: 30000, Loss: 22.533824
Iteration: 32000, Loss: 22.374718
Iteration: 34000, Loss: 22.488935
执行了:0分34秒
cllm_utils.py
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def smooth(loss, cur_loss):
return loss * 0.999 + cur_loss * 0.001
def print_sample(sample_ix, ix_to_char):
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
txt = txt[0].upper() + txt[1:] # capitalize first character
print ('%s' % (txt, ), end='')
def get_initial_loss(vocab_size, seq_length):
return -np.log(1.0/vocab_size)*seq_length
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
def initialize_parameters(n_a, n_x, n_y):
"""
Initialize parameters with small random values
Returns:
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
"""
np.random.seed(1)
Wax = np.random.randn(n_a, n_x)*0.01 # input to hidden
Waa = np.random.randn(n_a, n_a)*0.01 # hidden to hidden
Wya = np.random.randn(n_y, n_a)*0.01 # hidden to output
b = np.zeros((n_a, 1)) # hidden bias
by = np.zeros((n_y, 1)) # output bias
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b,"by": by}
return parameters
def rnn_step_forward(parameters, a_prev, x):
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
a_next = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b) # hidden state
p_t = softmax(np.dot(Wya, a_next) + by) # unnormalized log probabilities for next chars # probabilities for next chars
return a_next, p_t
def rnn_step_backward(dy, gradients, parameters, x, a, a_prev):
gradients['dWya'] += np.dot(dy, a.T)
gradients['dby'] += dy
da = np.dot(parameters['Wya'].T, dy) + gradients['da_next'] # backprop into h
daraw = (1 - a * a) * da # backprop through tanh nonlinearity
gradients['db'] += daraw
gradients['dWax'] += np.dot(daraw, x.T)
gradients['dWaa'] += np.dot(daraw, a_prev.T)
gradients['da_next'] = np.dot(parameters['Waa'].T, daraw)
return gradients
def update_parameters(parameters, gradients, lr):
parameters['Wax'] += -lr * gradients['dWax']
parameters['Waa'] += -lr * gradients['dWaa']
parameters['Wya'] += -lr * gradients['dWya']
parameters['b'] += -lr * gradients['db']
parameters['by'] += -lr * gradients['dby']
return parameters
def rnn_forward(X, Y, a0, parameters, vocab_size = 27):
# Initialize x, a and y_hat as empty dictionaries
x, a, y_hat = {}, {}, {}
a[-1] = np.copy(a0)
# initialize your loss to 0
loss = 0
for t in range(len(X)):
# Set x[t] to be the one-hot vector representation of the t'th character in X.
# if X[t] == None, we just have x[t]=0. This is used to set the input for the first timestep to the zero vector.
x[t] = np.zeros((vocab_size,1))
if (X[t] != None):
x[t][X[t]] = 1
# Run one step forward of the RNN
a[t], y_hat[t] = rnn_step_forward(parameters, a[t-1], x[t])
# Update the loss by substracting the cross-entropy term of this time-step from it.
loss -= np.log(y_hat[t][Y[t],0])
cache = (y_hat, a, x)
return loss, cache
def rnn_backward(X, Y, parameters, cache):
# Initialize gradients as an empty dictionary
gradients = {}
# Retrieve from cache and parameters
(y_hat, a, x) = cache
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
# each one should be initialized to zeros of the same dimension as its corresponding parameter
gradients['dWax'], gradients['dWaa'], gradients['dWya'] = np.zeros_like(Wax), np.zeros_like(Waa), np.zeros_like(Wya)
gradients['db'], gradients['dby'] = np.zeros_like(b), np.zeros_like(by)
gradients['da_next'] = np.zeros_like(a[0])
### START CODE HERE ###
# Backpropagate through time
for t in reversed(range(len(X))):
dy = np.copy(y_hat[t])
dy[Y[t]] -= 1
gradients = rnn_step_backward(dy, gradients, parameters, x[t], a[t], a[t-1])
### END CODE HERE ###
return gradients, a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号