词向量的运算
1 - 词向量运算
- 如何加载训练好了的词向量
- 使用余弦相似性计算相似度
- 使用词嵌入来解决“男人与女人相比就像国王与____ 相比”之类的词语类比问题
- 修改词嵌入以减少性别偏见等
读数据:
- words:单词的集合
- word_to_vec_map : 字典类型,单词到GloVe向量的映射
- 使用50维的向量来表示单词
from torch.nn.parameter import Parameter #参数更新和优化函数
from collections import Counter #Counter 计数器
import numpy as np
import random
import math
import pandas as pd
import scipy #SciPy是基于NumPy开发的高级模块,它提供了许多数学算法和函数的实现
import sklearn
from sklearn.metrics.pairwise import cosine_similarity #余弦相似度函数
def read_glove_vecs(glove_file):
with open(glove_file, 'r', encoding='utf8') as f:
words = set()
word_to_vec_map = {}
for line in f:
line = line.strip().split()
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
return words, word_to_vec_map
words, word_to_vec_map = read_glove_vecs('./datasets/glove.6B.50d.txt')
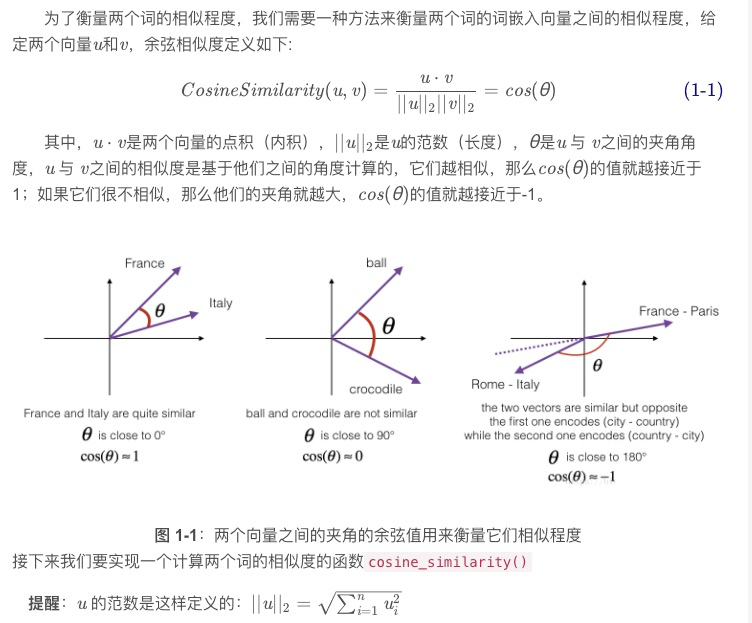
def cosine_similarity(u, v):
"""
u与v的余弦相似度反映了u与v的相似程度
参数:
u -- 维度为(n,)的词向量
v -- 维度为(n,)的词向量
返回:
cosine_similarity -- 由上面公式定义的u和v之间的余弦相似度。
"""
distance = 0
# 计算u与v的内积(点积)
dot = np.dot(u, v) # 得到一个数
norm_u = np.sqrt(np.sum(np.power(u, 2)))
norm_v = np.sqrt(np.sum(np.power(v, 2)))
cosine_similarity = np.divide(dot, norm_u * norm_v) # dot / (norm_u * norm_v)结果一样
return cosine_similarity
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
cosine_similarity(father, mother) = 0.8909038442893615
cosine_similarity(ball, crocodile) = 0.2743924626137942
cosine_similarity(france - paris, rome - italy) = -0.6751479308174202
1.2 - 词类类比
男人与女人相比就像国王与____ 相比
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
参数:
word_a -- 一个字符串类型的词
word_b -- 一个字符串类型的词
word_c -- 一个字符串类型的词
word_to_vec_map -- 字典类型,单词到GloVe向量的映射
返回:
best_word -- 满足(v_b - v_a) 最接近 (v_best_word - v_c) 的词
"""
# 把单词转换为小写
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
# 获取对应单词的词向量
e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c]
# 获取全部的单词
words = word_to_vec_map.keys()
# 将max_cosine_sim初始化为一个比较大的负数
max_cosine_sim = -100
best_word = None
for word in words:
# 要避免匹配到输入的数据
if word in [word_a, word_b, word_c]:
continue
# 计算余弦相似度
cosine_sim = cosine_similarity((e_b - e_a), (word_to_vec_map[word] - e_c))
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = word
return best_word
triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')]
for triad in triads_to_try:
print ('{} -> {} <====> {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))
italy -> italian <====> spain -> spanish
india -> delhi <====> japan -> tokyo
man -> woman <====> boy -> girl
small -> smaller <====> large -> larger

 浙公网安备 33010602011771号
浙公网安备 33010602011771号