浅层神经网络实现平面数据分类
构建具有单隐藏层的2类分类神经网络
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
# 使用的是Jupyter Notebook的话取消注释
%matplotlib inline
np.random.seed(1) # set a seed so that the results are consistent
Dataset
X, Y = load_planar_dataset()
plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral) #绘制散点图
<matplotlib.collections.PathCollection at 0x7fb0e322ef90>
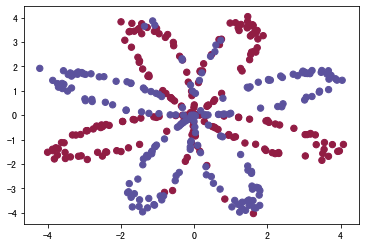
- X:一个numpy的矩阵,包含了这些数据点的数值
- Y:一个numpy的向量,对应着的是X的标签【0 | 1】(红色:0 , 蓝色 :1)
Exercise: How many training examples do you have? In addition, what is the shape of the variables X and Y?
shape_X = X.shape
shape_Y = Y.shape
m = X.shape[1]
print ('The shape of X is: ' + str(shape_X))
print ('The shape of Y is: ' + str(shape_Y))
print ('I have m = %d training examples!' % (m))
The shape of X is: (2, 400)
The shape of Y is: (1, 400)
I have m = 400 training examples!
Neural Network model
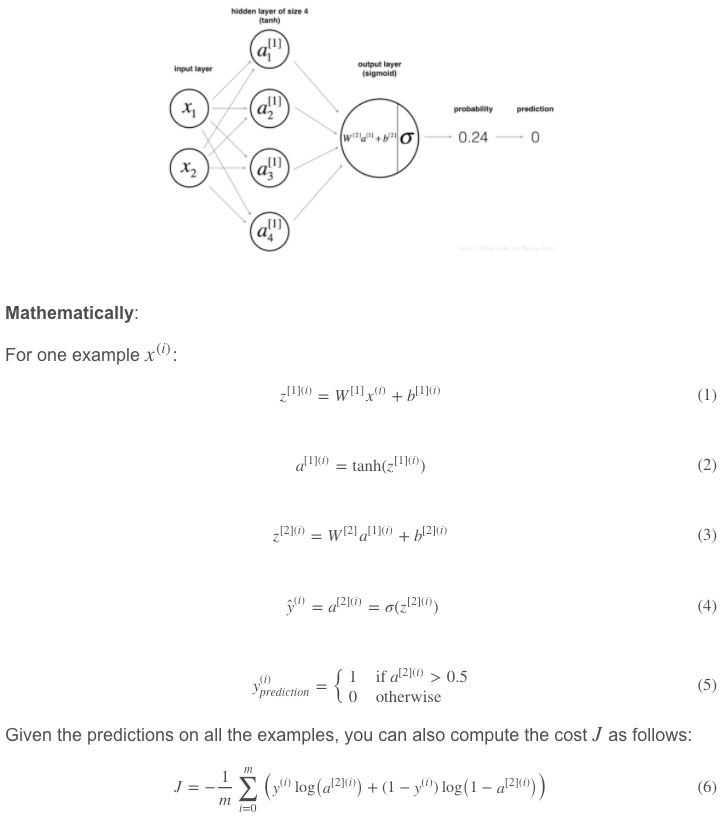
Defining the neural network structure
Exercise: Define three variables
def layer_sizes(X, Y):
"""
Arguments:
X -- input dataset of shape (input size, number of examples)
Y -- labels of shape (output size, number of examples)
Returns:
n_x -- the size of the input layer
n_h -- the size of the hidden layer
n_y -- the size of the output layer
"""
n_x = X.shape[0]
n_h = 4
n_y = Y.shape[0]
return (n_x, n_h, n_y) # 没括号也可以
X_assess, Y_assess = layer_sizes_test_case()
(n_x, n_h, n_y) = layer_sizes(X_assess, Y_assess)
print("The size of the input layer is: n_x = " + str(n_x))
print("The size of the hidden layer is: n_h = " + str(n_h))
print("The size of the output layer is: n_y = " + str(n_y))
The size of the input layer is: n_x = 5
The size of the hidden layer is: n_h = 4
The size of the output layer is: n_y = 2
Initialize the model’s parameters
Exercise: Implement the function initialize_parameters().
def initialize_parameters(n_x, n_h, n_y):
"""
Argument:
n_x -- size of the input layer
n_h -- size of the hidden layer
n_y -- size of the output layer
Returns:
params -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(2) #指定一个随机种子
W1 = np.random.randn(n_h,n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters
n_x, n_h, n_y = initialize_parameters_test_case()
parameters = initialize_parameters(n_x, n_h, n_y)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
W1 = [[-0.00416758 -0.00056267]
[-0.02136196 0.01640271]
[-0.01793436 -0.00841747]
[ 0.00502881 -0.01245288]]
b1 = [[0.]
[0.]
[0.]
[0.]]
W2 = [[-0.01057952 -0.00909008 0.00551454 0.02292208]]
b2 = [[0.]]
The Loop
前向传播
Question: Implement forward_propagation().
def forward_propagation(X, parameters):
"""
Argument:
X -- input data of size (n_x, m)
W1 -- weight matrix of shape (n_h, n_x)
W2 -- weight matrix of shape (n_y, n_h)
b1 -- bias vector of shape (n_h, 1)
b2 -- bias vector of shape (n_y, 1)
parameters -- python dictionary containing your parameters (output of initialization function)
Returns:
A2 -- The sigmoid output of the second activation
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2"
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
#使用断言确保我的数据格式是正确的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
X_assess, parameters = forward_propagation_test_case()
A2, cache = forward_propagation(X_assess, parameters)
# Note: we use the mean here just to make sure that your output matches ours.
print(np.mean(cache['Z1']) ,np.mean(cache['A1']),np.mean(cache['Z2']),np.mean(cache['A2']))
-0.0004997557777419902 -0.000496963353231779 0.00043818745095914653 0.500109546852431
Exercise: Implement compute_cost() to compute the value of the cost J.
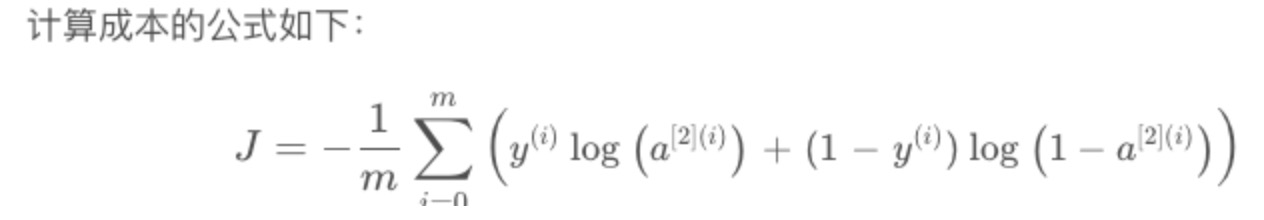
def compute_cost(A2, Y, parameters):
"""
Computes the cross-entropy cost given in equation (13)
Arguments:
A2 -- The sigmoid output of the second activation, of shape (1, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
parameters -- python dictionary containing your parameters W1, b1, W2 and b2
Returns:
cost -- cross-entropy cost given equation (13)
"""
m = Y.shape[1] # number of example
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert(isinstance(cost, float))
return cost
A2, Y_assess, parameters = compute_cost_test_case()
print("cost = " + str(compute_cost(A2, Y_assess, parameters)))
cost = 0.6929198937761266
反向传播
Question: Implement the function backward_propagation().

def backward_propagation(parameters, cache, X, Y):
"""
Arguments:
parameters -- python dictionary containing our parameters
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2".
X -- input data of shape (2, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
Returns:
grads -- python dictionary containing your gradients with respect to different parameters
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
### START CODE HERE ###
dZ2 = A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
### END CODE HERE ###
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
grads = backward_propagation(parameters, cache, X_assess, Y_assess)
print ("dW1 = "+ str(grads["dW1"]))
print ("db1 = "+ str(grads["db1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("db2 = "+ str(grads["db2"]))
dW1 = [[ 0.01018708 -0.00708701]
[ 0.00873447 -0.0060768 ]
[-0.00530847 0.00369379]
[-0.02206365 0.01535126]]
db1 = [[-0.00069728]
[-0.00060606]
[ 0.000364 ]
[ 0.00151207]]
dW2 = [[ 0.00363613 0.03153604 0.01162914 -0.01318316]]
db2 = [[0.06589489]]
更新参数
Question: Implement the update rule. Use gradient descent. You have to use (dW1, db1, dW2, db2) in order to update (W1, b1, W2, b2).
def update_parameters(parameters, grads, learning_rate = 1.2):
"""
Updates parameters using the gradient descent update rule given above
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients
Returns:
parameters -- python dictionary containing your updated parameters
"""
W1,W2 = parameters["W1"],parameters["W2"]
b1,b2 = parameters["b1"],parameters["b2"]
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
W1 = [[-0.00643025 0.01936718]
[-0.02410458 0.03978052]
[-0.01653973 -0.02096177]
[ 0.01046864 -0.05990141]]
b1 = [[-1.02420756e-06]
[ 1.27373948e-05]
[ 8.32996807e-07]
[-3.20136836e-06]]
W2 = [[-0.01041081 -0.04463285 0.01758031 0.04747113]]
b2 = [[0.00010457]]
整合
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
"""
Arguments:
X -- dataset of shape (2, number of examples)
Y -- labels of shape (1, number of examples)
n_h -- size of the hidden layer
num_iterations -- Number of iterations in gradient descent loop
print_cost -- if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters, then retrieve W1, b1, W2, b2.
# Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Loop (gradient descent)
for i in range(num_iterations):
A2, cache = forward_propagation(X,parameters)
cost = compute_cost(A2,Y,parameters)
grads = backward_propagation(parameters,cache,X,Y)
parameters = update_parameters(parameters,grads,learning_rate = 1.2)
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print("Cost after iteration %i: %f" %(i, cost))
return parameters
X_assess, Y_assess = nn_model_test_case()
parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10000, print_cost=False)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:16: RuntimeWarning: divide by zero encountered in log
app.launch_new_instance()
W1 = [[-4.1849398 5.33220663]
[-7.52989385 1.24306179]
[-4.19294487 5.32632401]
[ 7.52983712 -1.24309427]]
b1 = [[ 2.32926815]
[ 3.79458991]
[ 2.33002576]
[-3.7946886 ]]
W2 = [[-6033.83672154 -6008.12980759 -6033.10095295 6008.06637359]]
b2 = [[-52.66607715]]
预测
def predict(parameters, X):
"""
Using the learned parameters, predicts a class for each example in X
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (n_x, m)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
A2, cache = forward_propagation(X, parameters)
predictions = (A2 > 0.5)
return predictions
parameters, X_assess = predict_test_case()
predictions = predict(parameters, X_assess)
print("predictions mean = " + str(np.mean(predictions)))
predictions mean = 0.6666666666666666
正式运行
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000, print_cost=True)
#绘制边界 plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral) c 需要一维的array
plot_decision_boundary(lambda x: predict(parameters, x.T), X, np.squeeze(Y)) # Y降维
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('准确率: %d' % float((np.dot(Y, predictions.T) +
np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
Cost after iteration 0: 0.693048
Cost after iteration 1000: 0.288083
Cost after iteration 2000: 0.254385
Cost after iteration 3000: 0.233864
Cost after iteration 4000: 0.226792
Cost after iteration 5000: 0.222644
Cost after iteration 6000: 0.219731
Cost after iteration 7000: 0.217504
Cost after iteration 8000: 0.219506
Cost after iteration 9000: 0.218621
准确率: 90%


 浙公网安备 33010602011771号
浙公网安备 33010602011771号