

面试题总结
## python基础
# 1、简述面向对象的三大特性。
封装:
封装指的是把一堆数据属性与方法数据放在一个容器中,这个容器就是对象。让对象可以通过 "." 来调用对象中的数据属性与方法属性。
继承:
继承指的是子类可以继承父类的数据属性与方法属性,并可以对其进行修改或使用。
多态:
在python中的多态指的是让多种类若具备类似的数据属性与方法属性,都统一好命名规范,这样可以提高开发者的代码统一性,使得调用者更方便去理解。
# 2、什么是鸭子模型?
在python中不会强制性要求所有人的代码都统一规范,不统一也不会报错,若使用抽象类就会使python代码强制统一规范,这样不符合python动态语言的特性。所以让大家都自觉统一好规范,若大家的对象方法都类似的话就一种规范,只要长得像鸭子,就称之为鸭子类型。
# 3、super 的作用?
'''
使用super()可以在子类中调用父类的方法或属性, 可能你会说, 子类本来就可以调用父类中所有非私有的属性或方法,而我现在说的是, 当子类中实现了某个方法, 父类中也有这个方法, 当你调用这个方法时, 既想执行子类的又想执行父类的, 在这种情况下就可以使用super()
'''
# 4、什么是反射以及常用的方法
反射指的是通过字符串来操作对象的属性,涉及到四个内置函数的使用(Python中一切皆对象,类和对象都可以用下
述四个方法)基于反射可以十分灵活地操作对象的属性,比如将用户交互的结果反射到具体的功能执行
反射本质就是在使用内置函数,其中反射有以下四个内置函数:
1. hasattr:判断一个方法是否存在与这个类中
2. getattr:根据字符串去获取obj对象里的对应的方法的内存地址,加"()"括号即可执行
3. setattr:通过setattr将外部的一个函数绑定到实例中
4. delattr:删除一个实例或者类中的方法
# 5、什么是上下文管理,以及使用
with语句,为了让一个对象兼容with语句,必须在这个对象的类中声明__enter__和__exit__方法
class Open:
def init(self, name):
self.name = name
def __enter__(self):
print('出现with语句,对象的__enter__被触发,有返回值则赋值给as声明的变量')
# return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('with中代码块执行完毕时执行我啊')
with Open('a.txt') as f:
print('=====>执行代码块')
# print(f,f.name)
# 6、import和from...import...的异同
相同点:
两者都会执行模块对应的文件,两者都会产生模块的名称空间
两者调用功能时,需要跑到定义时寻找作用域关系,与调用位置无关
不同点
import需要加前缀;from...import...不需要加前缀
# 7、简述下python3中深度优先和广度优先和他们的区别?
新式类:(py3中全是新式类):广度优先---》从左侧开始,一直往上找,找到菱形的顶点结束(不包括顶点)
经典类:(只有py2中才有):深度优先---》从左侧开始,一直往上找,找到菱形的顶点结束(包括菱形顶点),继续下一个继承的父类
# 8、面向对象的优点和缺点是什么?
优点是:复杂的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)
缺点是:一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
# 9、简述什么是可迭代对象和迭代器两者之间是什么关系?
python中一切皆对象,对于这一切的对象中,但凡有__iter__方法的对象,都是可迭代对象。执行可迭代对象的__iter__方法,拿到的返回值就是迭代器对象。迭代器有三个特点:内置__next__方法,执行该方法会拿到迭代器对象中的一个值;内置有__iter__方法,执行该方法会拿到迭代器本身;文件本身就是迭代器对象。
# 10、自定义元类的中的三个方法(__call__,__init__,__new__)分别代表什么意思,在生成类的过程中,他们的执行顺序是怎样的?
__call__:类实例化时调用
__new__:创建类时调用,生成一个类对象
__init__:创建类时调用,对类进行初始化
执行循序,先call,再new,最后init
# 11、可以用什么方法去查看一个类继承的所有父类(按照继承顺序)?
类.mro()方法
# 12、面向对象深度优先和广度优先是什么?
深度优先主要体现在经典类在菱形继承的背景下,查找属性的方式
广度优先主要体现在新式类在菱形继承的背景下,查找属性的方式,
经典类只在python2中,由于的python2不支持服务的倒计时,推荐用python3,python3中的所有类都是新式类。
# 13、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
# 14、简述python引用计数机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数算法
当有1个变量保存了对象的引用时,此对象的引用计数就会加1
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除
# 15.、python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
2、复制的值是可变对象(列表和字典)
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表), 改变原来的值 中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:
完全复制独立,包括内层列表和字典
# 16、python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
# 17、迭代器和生成器是什么?有什么区别
迭代器:迭代器不仅要实现__iter__方法,还需要实现__next__方法,迭代器是可迭代对象的一个子集,它是一个可以记住遍历的位置的对象,它与列表、元组、集合、字符串这些可迭代对象的区别就在于next方法的实现,其他列表、元组、集合、字符串这些可迭代对象可以很简单的转化成迭代器,通过
生成器:在Python中一个函数可以用yiled替代return返回值,这样的话这个函数就变成了一个生成器对象
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了__iter__()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保持程序状态的自动生成,当发生器终结时,还会自动跑出StopIterration异常。
# 18、什么是序列解包?序列解包支持哪些数据类型?
序列解包就是将数据字符等从列表、字典、字符串等装有元素的容器取出需要的元素。
元组,列表,字符串,迭代器,生成器
# 19、什么是常量?python有没有常量? 如何实现真正的常量
常量则是不变的量
python中定义常量本质上就是变量。如果非要定义常量,变量名必须全大写
class _const:
class ConstError(TypeError) : pass
```python
def __setattr__(self, key, value):
# self.__dict__
if key in self.__dict__:
data="Can't rebind const (%s)" % key
raise self.ConstError(data)
self.__dict__[key] = value
import sys
sys.modules[__name__] = _const()
20、什么是递归,python递归的最大层数?
在函数内部,可以调用其他函数。如果在调用一个函数的过程中直接或间接调用自身本身
998
21、什么是python异常处理,写出几个常见的异常类型
异常就是程序运行时发生错误的信号(在程序出现错误时,则会产生一个异常,若程序没有处理它,则会抛出该异常,程序的运行也随之终止)
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
22、assert是什么?有什么作用?
判断一个表达式,在表达式条件为 false 的时候触发异常
用于程序的测试
23、如何python脚本执行CMD命令并返回结果?
第一种情况
os.system('ps aux')
执行系统命令,没有返回值
第二种情况
result = os.popen('ps aux')
res = result.read()
for line in res.splitlines():
print line
第三种情况
p = subprocess.Popen('ps aux',shell=True,stdout=subprocess.PIPE)
out,err = p.communicate()
for line in out.splitlines():
print line
第四种情况
commands.getstatusoutput('ps aux')
Django面试题
- 20、什么是递归,python递归的最大层数?
- 21、什么是python异常处理,写出几个常见的异常类型
- 22、assert是什么?有什么作用?
- 23、如何python脚本执行CMD命令并返回结果?
- Django面试题
- 中间件是介于request与response处理之间的一道处理过程,用于在全局范围内改变Django的输入和输出。
- 简单的来说中间件是帮助我们在视图函数执行之前和执行之后都可以做一些额外的操作
- 例如:
- 1.Django项目中默认启用了csrf保护,每次请求时通过CSRF中间件检查请求中是否有正确#token值
- 2.当用户在页面上发送请求时,通过自定义的认证中间件,判断用户是否已经登陆,未登陆就去登陆。
- 3.当有用户请求过来时,判断用户是否在白名单或者在黑名单里
- 1.process_request : 请求进来时,权限认证
- 2.process_view : 路由匹配之后,能够得到视图函数
- 3.process_exception : 异常时执行
- 4.process_template_responseprocess : 模板渲染时执行
- 5.process_response : 请求有响应时执行
- 参与排序的字段
- 参与搜索的字段
- 参与分类筛选的字段:所有字段都可以,但是用于分组的字段更有意义
- filter_fields = ['course_category'] # 分类字段
- filters.py
- 配置自定义分页器类,继承PageNumberPagination,LimitOffsetPagination,CursorPagination
- paginations.py
- mysql面试题
Django面试题
1. 什么是wsgi,uwsgi,uWSGI?
WSGI:
web服务器网关接口,是一套协议。用于接收用户请求并将请求进行初次封装,然后将请求交给web框架。
实现wsgi协议的模块:wsgiref,本质上就是编写一socket服务端,用于接收用户请求(django)
werkzeug,本质上就是编写一个socket服务端,用于接收用户请求(flask)
uwsgi:
与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型。 uWSGI:
是一个web服务器,实现了WSGI的协议,uWSGI协议,http协议
2. django开发中数据做过什么优化?
1.设计表时,尽量少使用外键,因为外键约束会影响插入和删除性能
2.使用缓存,减少对数据库的访问
3.orm框架下设置表时,能使用varchar确定字段长度时,就别用text
4.可以给搜索频率搞得字段属性,在定义时创建索引。
5.django orm 框架下的Querysets 本来就有缓存的。
6.如果一个页面需要多次链接数据库,最好一次性去除所有需要的数据,减少数据库的查询次数。
7, 若页面只需要数据库里面的某一两个字段时,可以用QuerySet.values()
8.在模板标签里使用with标签可以缓存Qset查询结果。
3. 说一下Django,MIDDLEWARES中间件的作用和应用场景?
中间件是介于request与response处理之间的一道处理过程,用于在全局范围内改变Django的输入和输出。
简单的来说中间件是帮助我们在视图函数执行之前和执行之后都可以做一些额外的操作
例如:
1.Django项目中默认启用了csrf保护,每次请求时通过CSRF中间件检查请求中是否有正确#token值
2.当用户在页面上发送请求时,通过自定义的认证中间件,判断用户是否已经登陆,未登陆就去登陆。
3.当有用户请求过来时,判断用户是否在白名单或者在黑名单里
4. 列举django中间件的5个方法?
1.process_request : 请求进来时,权限认证
2.process_view : 路由匹配之后,能够得到视图函数
3.process_exception : 异常时执行
4.process_template_responseprocess : 模板渲染时执行
5.process_response : 请求有响应时执行
5. 在django项目中静态文件一般有哪些?这些文件怎么配置?
一般都是写前端网站代码时所需要的js代码(自己写好),css代码(自己写好),第三方框架(bootstrap fontwesome,sweetalert)
这些静态文件统一放在static文件夹(需要手动创建),同时还需要去settings配置文件,添加配置:
在配置文件里找到 static_URL = ‘/static/’这行代码,它含义是访问静态资源的接口前缀,在这行代码的下面写我们所添加的静态文件,格式如下:
STATICFILES_DIRS=[
os.path.join(BASE_DIR,’static’),
]
然后我们就可以在html文件添加上
{% load static %}
<link rel= “stylesheet” href=”{% static 'bootstrap/css/bootstrap.min.css' %}”>
<script src=”{% static 'bootstrap/js/bootstrap.min.js' %}”>
接口前缀 动态解析
6. request.POST和request.GET这两行代码是什么意思?其中POST和GET我可以小写吗?它们分别是怎么获取数据的?
Request.POST 获取post请求带来的数据
Request.GET 获取get请求带来的数据
Get和post后端获取用户的数据规律是一样的
Request.POST.get()默认只取列表最后一个元素
如果想将列表完整的取出,必须要用getlist()
7. django版本区别?
url和path
path第一个参数不支持正则 写什么就匹配什么 精准匹配
re_path跟url是一模一样的用法
8. 后端如何获取前端用户想要编辑的数据对象?
1.利用get请求url后面可以携带参数的方式 将数据的主键值传递给后端
9. select_related和prefetch_related的区别?
前提:有外键存在时,可以很好的减少数据库请求的次数,提高性能
select_related通过多表join关联查询,一次性获得所有数据,只执行一次SQL查询
prefetch_related分别查询每个表,然后根据它们之间的关系进行处理,执行两次查询
10. django的Model中的ForeignKey字段中的on_delete参数有什么作用?
删除关联表中的数据时,当前表与其关联的field的操作
django2.0之后,表与表之间关联的时候,必须要写on_delete参数,否则会报异常
11. Django ORM字段参数
null,某个字段可以为空
unique=True,该字段在该表中必须唯一
db_index=True,为该字段设置索引
default,为该字段设置默认值
DateField和DateTimeField
auto_now_add=True,创建数据记录的时候会在数据库中添加当前时间
auto_now=True,每次更新数据记录会更新该字段
12. 列举QuerySet对象的所有方法
1.all(): 查询所有结果
2.filter(\*\*kwargs): 它包含了与所给筛选条件相匹配的对象
3.get(\*\*kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
4.exclude(\**kwargs): 它包含了与所给筛选条件不匹配的对象
5.order_by(\*field): 对查询结果排序('-id')
6.reverse(): 对查询结果反向排序
7.count(): 返回数据库中匹配查询(QuerySet)的对象数量。
8.first(): 返回第一条记录
9.last(): 返回最后一条记录
10.exists(): 如果QuerySet包含数据,就返回True,否则返回False
11.values(\*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
12.values_list(\*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
13.distinct(): 从返回结果中剔除重复纪录
13. 创建Django工程、Django app、以及运行的命令
```python
django-admin startproject proj_name
python manage.py startapp app_name
python manage.py runserver
## 14. Auth组件与Form组件用法:
略
## 简述django的请求生命周期
1wsgi,请求封装后交给web框架(Flask、Django)
2请求中间件,对请求进行校验或在请求对象中添加其他相关数据,例如:csrf、request.session -
3路由匹配,根据浏览器发送的不同url去匹配不同的视图函数
4视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm、templates => 渲染 -
5响应中间件,对响应的数据进行处理。
6wsgi,将响应的内容发送给浏览器。
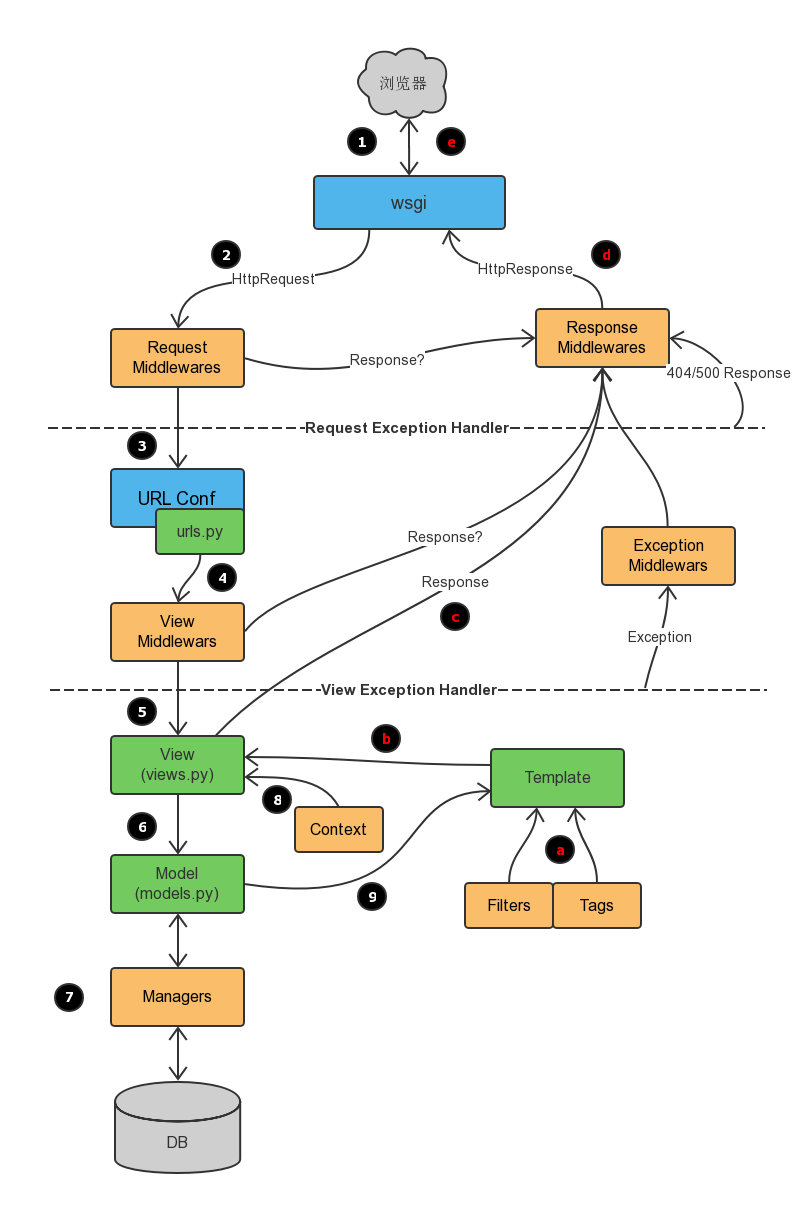
## 简述FBV和CBV
FBV(function base views)就是在视图函面使用函数处理请求
CBV(class base views)就是在视图里面使用类处理请求
## 列举django的内置组件?
- .Admin是对model中对应的数据表进行增删改查提供的组件
- .model组件:负责操作数据库
- .form组件:1.生成HTML代码2.数据有效性校验3校验信息返回并展示
- .ModelForm组件即用于数据库操作,也可用于用户请求的验证
## values和values_list的区别?
- values : queryset类型的列表中是字典
- values_list : queryset类型的列表中是元组
## 简述Django下的(内建)缓存机制
Django根据设置的缓存方式,浏览器第一次请求时,cache会缓存单个变量或整个网页等内容到硬盘或者内存中,同时设置response头部,当浏览器再次发起请求时,附带f-Modified-Since请求时间到Django,Django 发现f-Modified-Since会先去参数之后,会与缓存中的过期时间相比较,如果缓存时间比较新,则会重新请求数据,并缓存起来然后返回response给客户端,如果缓存没有过期,则直接从缓存中提取数据,返回给response给客户端。
## Django 本身提供了 runserver,为什么不能用来部署?
runserver 方法是调试 Django 时经常用到的运行方式,它使用 Django 自带的 WSGI Server 运行,主要在测试和开发中使用,并且 runserver 开启的方式也是单进程 。
uWSGI 是一个 Web 服务器,它实现了 WSGI 协议、uwsgi、http 等协议。注意 uwsgi 是一种通信协议,而 uWSGI 是实现 uwsgi 协议和 WSGI 协议的 Web 服务器。
uWSGI 具有超快的性能、低内存占用和多 app 管理等优点,并且搭配着 Nginx 就是一个生产环境了,能够将用户访问请求与应用 app 隔离开,实现真正的部署 。相比来讲,支持的并发量更高,方便管理多进程,发挥多核的优势,提升性能。
## drf面试题
[TOC]
### 一、简述drf中的视图类
- APIView
1)继承自View,封装了Django 本身的HttpRequest对象为Request对象。
2)认证&权限&限流。
- GenericAPIView
1)继承自APIView,提供了操作序列化器和数据库数据的方法,通常和Mixin扩展类配合使用。
2)过滤&排序&分页。
### 二、五大扩展类
1)ListModelMixin
提供list方法,封装了‘返回模型数据列表’信息的通用流程。
2)CreateModelMixin
提供create方法,封装了‘创建一条模型对象’数据信息的通用流程。
3)RetrieveModelMixin
提供retrieve方法,封装了‘获取一条模型对象’数据信息的通用流程。
4)UpdateModelMixin
提供update方法,封装了‘更新一条模型对象’数据信息的通用流程。
5)DestroyModelMixin
提供destroy方法,封装了‘删除一条模型对象’数据信息的通用流程。
### 三、简述drf中的常用子类视图。
- 子类视图类都继承(GenericAPIView)
ListAPIView
继承ListModelMixin,适用于定义一个视图只提供列出模型所有信息的接口。
CreateAPIView
继承CreateModelMixin,适用于定义一个视图只提供创建一个模型信息的接口。
RetrieveAPIView
继承RetrieveModelMixin,适用于定义一个视图只提供获取一个模型信息的接口。
UpdateAPIView
继承UpdateModelMixin,适用于定义一个视图只提供更新一个模型信息的接口。
DestroyAPIView
继承DestroyModelMixin,适用于定义一个视图只提供删除一个模型信息的接口。
ListCreateAPIView
继承ListModelMixin,CreateModelMixin,
适用于定义一个视图提供列出模型所有和创建一个模型信息的接口。
RetrieveUpdateAPIView
继承RetrieveModelMixin,UpdateModelMixin,
适用于定义一个视图提供获取一个模型信息和更新一个模型信息的接口
RetrieveUpdateDestoryAPIView
继承RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin。
适用于定义一个视图提供获取一个模型信息和更新一个模型信息和删除一个模型信息的接口。
### 四、简述drf中的视图集类ViewSet。
- ViewSet
继承自ViewSetMixin和APIView,提供了身份认证、权限校验、流量管理等。
ViewSet视图集类不再实现get()、post()等方法,而是实现动作 action 下列动作:
list() 提供一组数据
retrieve() 提供单个数据
create() 创建数据
update() 保存数据
destory() 删除数据
视图集只在使用as_view()方法的时候,才会将action动作与具体请求方式对应上。
### 五、为什么要配置解析模块
1)drf给我们提供了多种解析数据包方式的解析类,有JSONParser,FormParser和MultiPartParser类
2)我们可以通过配置(全局或者局部配置),前台提交的哪些格式的数据后台要解析,哪些数据不要解析,比如视图类下局部设置了parser_classes = [JSONParseer],那么只解析json数据包,其他的数据格式就不解析。
3)全局配置就是针对view.py下所有的视图类配置,局部配置就是针对指定的视图类,让它们可以按照配置规则选择性解析数据。
### 六、为什么要自定义异常模块
1)drf默认提供了异常处理exception_handler方法,但是处理范围有限,有的异常需要手动处理
2)drf提供的处理方案两种,处理了返回异常现象,没处理就返回None(后续就是服务器抛异常给前台)
3)自定义异常的目的就是解决drf没有处理的异常,让前台得到合理的异常信息返回,后台记录异常具体信息
### 七、什么是前后端分离?请介绍一下它的工作机制?
只要你的网页是在浏览器端,内容是通过接口从后端拿到的纯数据,这就是前后端分离。
工作机制:
1.前端浏览器负责
- 数据展示与收集
- 事件响应与处理
- DOM操作
- 请求的发送与响应的处理
2.Node负责 - 页面渲染
- 路由分发
- 数据转发
3.后端负责 - 提供服务接口
- 封装业务逻辑
- 序列化
### 八、什么是drf组件?
- drf的全称是Django RESTful Framework
- 它是一个基于django开发的组件,本质是一个django的app
- drf可以帮我们快速开发出一个遵循restful规范的程序
### 九、序列化时,many=True与many=False的区别?
在使用APIView时,数据展示的时候序列化**多个数据**的时候用many=True,序列化**单个数据**的时候用many=False。
案例:
category_all = models.Category.objects.all()
ser_category = serializer.HomeCategorySerializer(instance=category_all, many=True)
article_obj = models.Article.objects.filter(id=pk).first()
ser = serializer.OneArticleSerializer(instance=article_obj, many=False)
### 十、什么是jwt? 它的优势是什么?
jwt的全称是json web token, 一般用于用户认证
优势:
- token只在前端保存,后端只负责校验。
- 内部集成了超时时间,后端可以根据时间进行校验是否超时。
- 由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
### 十一、你对drf的三大认证是怎样理解的
三大认证分别是:
- **认证**模块:校验用户是是否登陆
self.perform_authentication(request)
- **权限**模块:校验用户是否拥有权限
self.check_permissionsn(request)
- **频率**模块:访问接口的次数在设定的时间范围内是否过快(配置访问频率、缓存计次、超次后需要等待的时间)
self.check_throttles(request)
### 十二、你是怎样自定义一个频率类的?
- 自定义一个继承 SimpleRateThrottle 类 的频率类
- 设置一个 scope 类属性,属性值为任意见名知意的字符串
- 在settings配置文件中,配置drf的DEFAULT_THROTTLE_RATES,格式为
- 在自定义频率类中重写 get_cache_key 方法
限制的对象返回 与限制信息有关的字符串
不限制的对象返回 None (此处只能返回None,不能是False或是''等)
### 十三、简述一下jwt校验方式
用户登陆成功后,后台会将登录用户签发的token返回给前台。用户访问需要登陆权限的接口时,会将token以前缀+空格+token的格式提交给后台,后台会分离出token,解析登录用户信息。其中头和载荷,以反向解析的方式解析,而第三部分通过碰撞解析的方式及析出数据,进而完成身份验证。
### 十四、模型序列化器(modelserializer)的使用方式,与序列化器(serializer)的区别
- 序列化的对象是djaogo模型类,可以使用模型序列化类进行序列化。
- 指定序列化字段:fields = (),括号内填入字段名,如序列化全部字段,则填入__all__
- 排除掉指定字段:exclude = (),括号内填入字段名。
- 指明只读字段:read_only_fields = (),括号内填入字段名。
- 添加额外参数:extra_kwargs = {},字典内填入参数。
- 显式指明字段。
- modelserializer相比于serializer
- 可以基于模型类自动化生成相应字段
- 可以基于模型类自动为serializer生成validatoes
- 自带create()方法和update()方法
### 十五、说说drf请求模块对数据的处理。
drf的request是在wsgi的request基础上再次封装
wsgi的request作为drf的request一个属性:_request
新的request对旧的request做了完全兼容
新的request对数据解析更规范化:
所有的拼接参数都解析到query_params中,
所有数据包数据都被解析到data中
query_params和data属于QueryDict类型,可以 .dict() 转化成原生dict类型
### 十六、项目中drf的群查接口过滤器有哪些,如何使用?
- 备注:可分为怎么实现(搜索、排序),分页,(分类、区间
)三个问题
- 群查过滤器:搜索、排序、分页、分类、区间
- 排序过滤器
filter_backends = [OrderingFilter]
参与排序的字段
ordering_fields = ['price', 'id', 'students']
- 搜索过滤器
filter_backends = [SearchFilter]
参与搜索的字段
search_fields = ['name', 'brief']
- 分类过滤器,区间过滤器
filter_backends = [DjangoFilterBackend]
参与分类筛选的字段:所有字段都可以,但是用于分组的字段更有意义
filter_fields = ['course_category'] # 分类字段
filter_class = CourseFilterSet # 自定义区间过滤器
filters.py
class CourseFilterSet(FilterSet):
max_price = filters.NumberFilter(field_name='price', lookup_expr='lte')
min_price = filters.NumberFilter(field_name='price', lookup_expr='gte')
class Meta:
model = models.Course
fields = ['course_category', 'max_price', 'min_price']
- 分页器
配置自定义分页器类,继承PageNumberPagination,LimitOffsetPagination,CursorPagination
pagination_class = CoursePageNumberPagination
paginations.py
class CoursePageNumberPagination(PageNumberPagination):
page_size = 2 # 默认一页条数
page_query_param = 'page' # 选择哪一页的key
page_size_query_param = 'page_size' # 用户自定义一页条数
max_page_size = 10 # 用户自定义一页最大控制条数
### 十七、jwt的优势有哪些?
token只在前端保存,后端只负责校验。
内部集成了超时时间,后端可以根据时间进行校验是否超时。
由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
### 十八、FBV和CBV的区别:
FBV是函数处理请求,代码冗余比较多,不是面向对象编程
CBV使用类中的不同方法来处理请求,是面向对象编程。
相比FBV的优点:
1、提高了代码的复用性,可以使用面向对象的计算,比如Mixin(多继承)
2、可以用不同的函数针对不同的http请求方法处理,而不是通过过多的if判断,提高了代码的可读性、
### 十九、什么是restful规范
restful规范是一套规则,用于API中之间进行数据交换的约定。
它的具体规则有:
1、https代替http,保证数据传输时的安全
2、在url中一般要体现api标识,这样看到url就知道他是一个api
建议:https://www.zdr.com/api/...(不会存在跨域问题)
3、在接口中要体现版本,可放在url中也可以放在请求头中
建议:https://www.zdr.com/api/v1/...
4、restful也称为面向资源编程,视网络上的一切都是资源,对资源可以进行操作,所以一般资源都用名词
5、如果要加入一些筛选条件,可以添加在url中
https://www.zdr.com/api/v1/user/?page=1&type=9
6、根据method请求方法不同做不同操作
get/post/put/patch/delete
7、根据请求方法不同返回不同的值
get全部/post返回添加的值/put/patch/delete不返回值
8、给用户返回状态码
- 200——成功
- 300——301是永久重定向,302是临时重定向
- 400——403拒绝中间件的csrftoken认证 /404找不到
- 500——服务端代码错误
9、操作异常时,要返回错误信息
### 二十、drf组件认证的实现过程
- 运行as_view方法
- 进入APIView的dispatch方法
- 执行user方法中的self._authenticate()方法
- 执行了自定义类中的authenticate方法
- 得到user和auth赋值给了request.user:是登录用户的对象,request.auth:是认证的信息字典
### 二十一、简述JWT签发Token
校验方式
post方法将请求数据交给 rest_framework_jwt.serializer.JSONWebTokenSerializer 处理
PS: 完成数据的校验,会走序列化类的 全局钩子校验规则,校验得到登录用户并签发token存储在序列化对象中
签发token第1步:用账号密码得到user对象
签发token第2步:通过user得到payload,payload包含着用户信息与过期时间,
在视图类中,可以通过 序列化对象.object.get('user'或者'token') 拿到user和token
签发token第3步:通过payload签发出token
手动签发token
(1)通过username password 生成user对象
(2)通过user对象生成载荷(payload)
jwt_payload_handler(user) => payloadfrom rest_framework_jwt.serializers import jwt_payload_handler
通过载荷签发token
jwt_encode_handler(payload) => token
from rest_framework_jwt.serializers import jwt_encode_handler
## 在线教育面试题
[TOC]
### 1 上线有哪些问题(注意点)出现:(可自由发挥)
例:
1、 真实环境和虚拟环境都要安装uwsgi,将真实环境下的uwsgi建立软连接
2、 redis服务一定要后台启动:redis-server &
3、 uwsgi启动django项目一定要进入虚拟环境下,因为环境都是安装在虚拟环境中
4、 服务器的日志都会被记录在于uwsgi配置文件 luffyapi.xml 同类目下的 uwsgi.log 中
### 2 简单介绍一下Celery架构以及使用场景:
celery架构:
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件Broker
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis等等
任务执行单元Worker
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务执行结果存储Backend
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis等
使用场景:
同步任务:没必要使用Celery,因为Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列
异步任务:将耗时操作任务提交给Celery去异步执行,比如发送短信/邮件、消息推送、音视频处理等等
定时任务:定时执行某件事情,比如每天数据统计
### 3、 你这个项目是怎么保证客户的唯一性登录的?(cookie和session)
通过cookie和session来管理用户以及限制唯一登录的问题.
首先我们搞清楚session是存储在服务器上的,cookie是存储在客户端浏览器上的,两者是相辅相成的.
当用户首次访问服务器的时候,服务器会为每个用户单独创建一个session对象,并且为每个session分配一个id(sessionid),sessionid通过cookie保存到用户端,当用户再次访问服务器的时候,需要将对应的sessionid携带并发送给服务器,服务器通过这个唯一的sessionid就可以找到用户对应的session对象,从而判定用户登录的状态.
### 4、你这个项目是用什么方式管理版本的?本地保存?异地备份?github还是gitlab?简单介绍一下(github和gitlab的用法及区别)
相同点:
(1). 二者都是基于web的Git仓库,在很大程度上GitLab是仿照GitHub来做的
(2). 它们都提供了分享开源项目的平台,为开发团队提供了存储、分享、发布和合作开发项目的中心化云存储的场所。
不同点:
GitHub:
GitHub作为开源代码库及版本控制系统,拥有超过900万的开发者用户,目前仍然是最火的开源项目托管系统。GitHub同时提供公共仓库和私有仓库,但如果要使用私有仓库,是需要付费的。
GitLab:
GitLab可以在上面创建私人的免费仓库。GitLab让开发团队对他们的代码仓库拥有更多的控制,相比于GitHub,它有不少的特色:允许免费设置仓库权限;允许用户选择分享一个project的部分代码;允许用户设置project的获取权限,进一步的提升安全性;可以设置获取到团队整体的改进进度;通过innersourcing让不在权限范围内的人访问不到该资源。
总的来说,从代码私有性方面来看,有时公司并不希望员工获取到全部的代码,这个时候GitLab无疑是更好的选择。但对于开源项目而言,GitHub依然是代码托管的首选。
### 5、 使用jwt做登录认证,如何解决token注销问题?
```python
答:jwt的缺陷是token生成后无法修改,因此无法让token失效。只能采用其它方案来弥补,基本思路如下:
1)适当减短token有效期,让token尽快失效
2)删除客户端cookie
3)服务端对失效token进行标记,形成黑名单,虽然有违无状态特性,但是因为token有效期短,因此标记 时间也比较短。
6、 jwt如何解决异地登录问题?
答:JWT设计为了实现无状态的登录,因此token无法修改,难以实现异地登录的判断,或者强制让登录token失效。
因此如果有类似需求, 就不应选择JWT作为登录方案,而是使用传统session登录方案。
但是,如果一定要用JWT实现类似要过,就需要在Redis中记录登录用户的JWT的token信息,这样就成了有状态的登录,还不如一开始就选择Session方案。
7、简述redis优点,Python怎样使用redis
redis:内存数据库(读写快),非关系型(操作数据方便)
支持数据持久化(数据丢失可以找回,可以将数据同步给mysql)
支持高并发
可以操作字符串,列表,字典,无序集合,有序集合.
**使用:**
直接使用(导入redis模块,配置端口和IP地址,以及数据库序号)
连接池使用(导入redis模块,连接池子,配置端口和IP地址,以及数据库序号,以及连接数)
缓存使用:
1. 额外安装django-redis
2. 将缓存存储位置配置到redis中:settings.py
3. 操作cache模块,直接操作缓存:views.py
4. 存放token,可以直接设置过期时间
5. 取出token
8、简述git工作流程
分为工作区,暂存区,版本库,服务器版本库
工作区就是开发程序代码的,暂存区是内存中用来临时存储的,版本库用来本地开发代码,服务区版本库:远程参考,服务器共有的代码.
提交:工作区创建,编写,删除文件,提交到暂存区 git add 暂存区内存中临时存储提交到版本库 git commit ,版本库提交之前需要先拉取一下 pull push
回滚:工作区 git checkout . , 暂存区 git reset HEAD . 版本库 git reset --hard 版本号
9、 Redis是单线程的,但Redis为什么这么快?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
10、 为什么Redis是单线程的?
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)。
11、 xadmin介绍
Django自带有admin后台,但是其风格并不漂亮、功能也不是让人很满意。因此一些人就重写了admin后台叫做xadmin,对admin进行了优化。
12、 xadmin简单的配置
安装:pip install https://codeload.github.com/sshwsfc/xadmin/zip/django2
在setting中注册:INSTALLED_APPS = [
'xadmin',
'crispy_forms',
'reversion',
]
数据库迁移:python manage.py makemigrations
python manage.py migrate
在url中设置主路由替换admin
import xadmin
xadmin.autodiscover()
from xadmin.plugins import xversion
xversion.register_models()
urlpatterns = [
path(r'xadmin/', xadmin.site.urls),
]
完成xadmin全局配置:新建home/adminx.py
完成xadmin全局配置:新建home/adminx.py
from . import models
xadmin.site.register(models.Banner)
13、 linux最常用的19个命令
1、cd命令
这是一个非常基本,也是大家经常需要使用的命令,它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径。
2、ls命令
这是一个非常有用的查看文件与目录的命令,list之意,它的参数非常多。
3、grep命令
该命令常用于分析一行的信息,若当中有我们所需要的信息,就将该行显示出来,该命令通常与管道命令一起使用,用于对一些命令的输出进行筛选加工等等。
4、find命令
find是一个基于查找的功能非常强大的命令,相对而言,它的使用也相对较为复杂,参数也比较多,
5、cp命令
该命令用于复制文件,copy之意,它还可以把多个文件一次性地复制到一个目录下。
6、mv命令
该命令用于移动文件、目录或更名,move之意。
7、rm命令
该命令用于删除文件或目录。
8、ps命令
该命令用于将某个时间点的进程运行情况选取下来并输出。
9、kill命令
该命令用于向某个工作(%jobnumber)或者是某个PID(数字)传送一个信号,它通常与ps和jobs命令一起使用。
10、killall命令
该命令用于向一个命令启动的进程发送一个信号.
11、file命令
该命令用于判断接在file命令后的文件的基本数据,因为在Linux下文件的类型并不是以后缀为分的,所以这个命令对我们来说就很有用了,
12、tar命令
该命令用于对文件进行打包,默认情况并不会压缩,如果指定了相应的参数,它还会调用相应的压缩程序(如gzip和bzip等)进行压缩和解压。
13、cat命令
该命令用于查看文本文件的内容,后接要查看的文件名,通常可用管道与more和less一起使用,从而可以一页页地查看数据。
14、chgrp命令
该命令用于改变文件所属用户组,它的使用非常简单,
15、chown命令
该命令用于改变文件的所有者,与chgrp命令的使用方法相同,只是修改的文件属性不同,不再详述。
16、chmod命令
该命令用于改变文件的权限。
18、vim命令
该命令主要用于文本编辑,它接一个或多个文件名作为参数,如果文件存在就打开,如果文件不存在就以该文件名创建一个文件。vim是一个非常好用的文本编辑器,它里面有很多非常好用的命令,在这里不再多说。
19、time命令
在程序或命令运行结束后,在最后输出了三个时间,它们分别是:
user:用户CPU时间.
system:系统CPU时间。
real:实际时间。
14、 Niginx 中正向代理和反向代理的区别
1. 背景
经常听到代理,比如通常我们要上国外的网站时,需要买vpn作为跳板机器进行访问。
但是在公司里面也听到了nginx支持反向代理。
那什么是正向代理,什么是反向代理?在网上看了写内容,说一下自己的理解。
2. 正向代理
正向代理,是在用户端的。比如需要访问某些国外网站,我们可能需要购买vpn。
并且vpn是在我们的用户浏览器端设置的(并不是在远端的服务器设置)。
浏览器先访问vpn地址,vpn地址转发请求,并最后将请求结果原路返回来。
3. 反向代理
有正向代理,就有反向代理。(哈哈,因为起名字的人也会考虑,为什么不叫代理,而是取名"正向"代理)。
反向代理是作用在服务器端的,是一个虚拟ip(VIP)。对于用户的一个请求,会转发到多个后端处理器中的一台来处理该具体请求。
大型网站都有DNS(域名解析服务器),load balance(负载均衡器)等。
总结,nginx作为软件能支持反向代理,也就是说nginx可以作为负载均衡器。
(负载均衡器可以提高网站性能,支持更高并发请求)
MySQL面试题
- 20、什么是递归,python递归的最大层数?
- 21、什么是python异常处理,写出几个常见的异常类型
- 22、assert是什么?有什么作用?
- 23、如何python脚本执行CMD命令并返回结果?
- Django面试题
- 中间件是介于request与response处理之间的一道处理过程,用于在全局范围内改变Django的输入和输出。
- 简单的来说中间件是帮助我们在视图函数执行之前和执行之后都可以做一些额外的操作
- 例如:
- 1.Django项目中默认启用了csrf保护,每次请求时通过CSRF中间件检查请求中是否有正确#token值
- 2.当用户在页面上发送请求时,通过自定义的认证中间件,判断用户是否已经登陆,未登陆就去登陆。
- 3.当有用户请求过来时,判断用户是否在白名单或者在黑名单里
- 1.process_request : 请求进来时,权限认证
- 2.process_view : 路由匹配之后,能够得到视图函数
- 3.process_exception : 异常时执行
- 4.process_template_responseprocess : 模板渲染时执行
- 5.process_response : 请求有响应时执行
- 参与排序的字段
- 参与搜索的字段
- 参与分类筛选的字段:所有字段都可以,但是用于分组的字段更有意义
- filter_fields = ['course_category'] # 分类字段
- filters.py
- 配置自定义分页器类,继承PageNumberPagination,LimitOffsetPagination,CursorPagination
- paginations.py
- mysql面试题
mysql面试题
事务
什么是事务?
理解什么是事务最经典的就是转账的例子,相信大家也都了解,这里就不再说一边了.
事务是一系列的操作,他们要符合ACID特性.最常见的理解就是:事务中的操作要么全部成功,要么全部失败.但是只是这样还不够的.
ACID是什么?可以详细说一下吗?
A=Atomicity
原子性,就是上面说的,要么全部成功,要么全部失败.不可能只执行一部分操作.
C=Consistency
系统(数据库)总是从一个一致性的状态转移到另一个一致性的状态,不会存在中间状态.
I=Isolation
隔离性: 通常来说:一个事务在完全提交之前,对其他事务是不可见的.注意前面的通常来说加了红色,意味着有例外情况.
D=Durability
持久性,一旦事务提交,那么就永远是这样子了,哪怕系统崩溃也不会影响到这个事务的结果.
同时有多个事务在进行会怎么样呢?
多事务的并发进行一般会造成以下几个问题:
- 脏读: A事务读取到了B事务未提交的内容,而B事务后面进行了回滚.
- 不可重复读: 当设置A事务只能读取B事务已经提交的部分,会造成在A事务内的两次查询,结果竟然不一样,因为在此期间B事务进行了提交操作.
- 幻读: A事务读取了一个范围的内容,而同时B事务在此期间插入了一条数据.造成"幻觉".
怎么解决这些问题呢?MySQL的事务隔离级别了解吗?
MySQL的四种隔离级别如下:
- 未提交读(READ UNCOMMITTED)
这就是上面所说的例外情况了,这个隔离级别下,其他事务可以看到本事务没有提交的部分修改.因此会造成脏读的问题(读取到了其他事务未提交的部分,而之后该事务进行了回滚).
这个级别的性能没有足够大的优势,但是又有很多的问题,因此很少使用.
- 已提交读(READ COMMITTED)
其他事务只能读取到本事务已经提交的部分.这个隔离级别有 不可重复读的问题,在同一个事务内的两次读取,拿到的结果竟然不一样,因为另外一个事务对数据进行了修改.
- REPEATABLE READ(可重复读)
可重复读隔离级别解决了上面不可重复读的问题(看名字也知道),但是仍然有一个新问题,就是 幻读,当你读取id> 10 的数据行时,对涉及到的所有行加上了读锁,此时例外一个事务新插入了一条id=11的数据,因为是新插入的,所以不会触发上面的锁的排斥,那么进行本事务进行下一次的查询时会发现有一条id=11的数据,而上次的查询操作并没有获取到,再进行插入就会有主键冲突的问题.
- SERIALIZABLE(可串行化)
这是最高的隔离级别,可以解决上面提到的所有问题,因为他强制将所以的操作串行执行,这会导致并发性能极速下降,因此也不是很常用.
Innodb使用的是哪种隔离级别呢?
InnoDB默认使用的是可重复读隔离级别.
对MySQL的锁了解吗?
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制.
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用.
MySQL都有哪些锁呢?像上面那样子进行锁定岂不是有点阻碍并发效率了?
从锁的类别上来讲,有共享锁和排他锁.
共享锁: 又叫做读锁. 当用户要进行数据的读取时,对数据加上共享锁.共享锁可以同时加上多个.
排他锁: 又叫做写锁. 当用户要进行数据的写入时,对数据加上排他锁.排他锁只可以加一个,他和其他的排他锁,共享锁都相斥.
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的. 一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以.
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁.
他们的加锁开销从大大小,并发能力也是从大到小.
mysql优化
SQL语句优化
- 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0 - 很多时候用 exists 代替 in 是一个好的选择
- 用Where子句替换HAVING 子句 因为HAVING 只会在检索出所有记录之后才对结果集进行过滤
索引优化
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
索引的优缺点
优点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引类型
普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHEREcolumn=)或排序条件(ORDERBYcolumn)中的数据列创建索引。只要有可能,就应该选择一个数据最整齐、最紧凑的数据列(如一个整数类型的数据列)来创建索引。
唯一索引
如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就应该用关键字UNIQUE把它定义为一个唯一索引。这么做的好处:一是简化了MySQL对这个索引的管理工作,这个索引也因此而变得更有效率;二是MySQL会在有新记录插入数据表时,自动检查新记录的这个字段的值是否已经在某个记录的这个字段里出现过了;如果是,MySQL将拒绝插入那条新记录。也就是说,唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
主索引
在前面已经反复多次强调过:必须为主键字段创建一个索引,这个索引就是所谓的"主索引"。主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是PRIMARY而不是UNIQUE。
外键索引
如果为某个外键字段定义了一个外键约束条件,MySQL就会定义一个内部索引来帮助自己以最有效率的方式去管理和使用外键约束条件。
复合索引
索引可以覆盖多个数据列,如像INDEX(columnA, columnB)索引。这种索引的特点是MySQL可以有选择地使用一个这样的索引。如果查询操作只需要用到columnA数据列上的一个索引,就可以使用复合索引INDEX(columnA, columnB)。不过,这种用法仅适用于在复合索引中排列在前的数据列组合。比如说,INDEX(A, B, C)可以当做A或(A, B)的索引来使用,但不能当做B、C或(B, C)的索引来使用。
全文索引
文本字段上的普通索引只能加快对出现在字段内容最前面的字符串(也就是字段内容开头的字符)进行检索操作。如果字段里存放的是由几个、甚至是多个单词构成的较大段文字,普通索引就没什么作用了。这种检索往往以LIKE %word%的形式出现,这对MySQL来说很复杂,如果需要处理的数据量很大,响应时间就会很长。
这类场合正是全文索引(full-text index)可以大显身手的地方。在生成这种类型的索引时,MySQL将把在文本中出现的所有单词创建为一份清单,查询操作将根据这份清单去检索有关的数据记录。全文索引即可以随数据表一同创建,也可以等日后有必要时再使用下面这条命令添加:
ALTER TABLE tablename ADD FULLTEXT(column1, column2)
有了全文索引,就可以用SELECT查询命令去检索那些包含着一个或多个给定单词的数据记录了。下面是这类查询命令的基本语法:
SELECT * FROM tablename
WHERE MATCH(column1, column2) AGAINST('word1', 'word2', 'word3')
上面这条命令将把column1和column2字段里有word1、word2和word3的数据记录全部查询出来。
注解:InnoDB数据表不支持全文索引。
数据库三大范式
第一范式(1NF)
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是非主属性非部分依赖于主关键字。
第三范式(3NF)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。(我的理解是消除冗余)
存储引擎
mysql常见引擎即大致作用:
innodb:支持事务,行级锁,外键等
mylsam:查询效率优于innodb,不支持事务等
memory:作用于内存
Blackhole(黑洞引擎):将数据丢弃,可以减轻服务器负担(只记录日志)
MySQL中myisam与innodb的区别,至少5点
问5点不同
1.InnoDB支持事物,而MyISAM不支持事物
2.InnoDB支持行级锁,而MyISAM支持表级锁
3.InnoDB支持MVCC, 而MyISAM不支持
4.InnoDB支持外键,而MyISAM不支持
5.InnoDB不支持全文索引,而MyISAM支持。
6.InnoDB不能通过直接拷贝表文件的方法拷贝表到另外一台机器, myisam 支持
7.InnoDB表支持多种行格式, myisam 不支持
8.InnoDB是索引组织表, myisam 是堆表
innodb引擎的4大特性
1.插入缓冲(insert buffer)
2.二次写(double write)
3.自适应哈希索引(ahi)
4.预读(read ahead)
各种不同 mysql 版本的Innodb的改进
MySQL5.6 下 Innodb 引擎的主要改进:
( 1) online DDL
( 2) memcached NoSQL 接口
( 3) transportable tablespace( alter table discard/import tablespace)
( 4) MySQL 正常关闭时,可以 dump 出 buffer pool 的( space, page_no),重启时 reload,加快预热速度
( 5) 索引和表的统计信息持久化到 mysql.innodb_table_stats 和mysql.innodb_index_stats,可提供稳定的执行计划
( 6) Compressed row format 支持压缩表
MySQL 5.7 innodb 引擎主要改进
( 1) 修改 varchar 字段长度有时可以使用 online DDL
( 2) Buffer pool 支持在线改变大小
( 3) Buffer pool 支持导出部分比例
( 4) 支持新建 innodb tablespace,并可以在其中创建多张表
( 5) 磁盘临时表采用 innodb 存储,并且存储在 innodb temp tablespace 里面,以前是 myisam 存储
( 6) 透明表空间压缩功能
2者select count(*)哪个更快,为什么
myisam更快,因为myisam内部维护了一个计数器,可以直接调取。
2者的索引的实现方式
都是 B+树索引, Innodb 是索引组织表, myisam 是堆表, 索引组织表和堆表的区别要熟悉
字符编码
utf8_bin和utf8_general_ci和utf8_unicode_ci的区别
ci是 case insensitive, 即 “大小写不敏感”, a 和 A 会在字符判断中会被当做成一样的;
bin 是二进制, a 和 A 会别区别对待.
utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法,一些字符还是不能支持。
SELECT * FROM user WHERE name = 'a’查询时,
使用utf8_bin排序就找不到name = 'A’的那行
使用utf8_general_ci排序就能找到name = 'A’的那行
utf8_bin区分大小写,utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性也够我们用的了
如何在mysql中使用emoji表情
因为emoji表情占了4个字符,而utf8只支持1-3个字节,所以这个时候我们需要用到utf8mb4
utf8mb4: Unicode字符集的UTF-8编码,每个字符使用1到4个字节
utf8mb3: Unicode字符集的UTF-8编码,每个字符使用一到三个字节
utf8: utf8mb3的别名
解决方法:
ALTER TABLE 你的表名 CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
utf8扩展,除了mb3,mb4,还有以下:
ucs2: Unicode字符集的UCS-2编码,每个字符使用两个字节
utf16: Unicode字符集的UTF-16编码,每个字符使用两个或四个字节。就像ucs2一样,但是有一个补充字符的扩展
utf16le: Unicode字符集的UTF-16LE编码。类似于utf16,但是是little-endian(小端)而不是big-endian(大端)。
utf32: Unicode字符集的UTF-32编码,每个字符使用四个字节。
其余
truncate与 delete区别
TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。 DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。
TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。 TRUNCATE,DELETE,DROP 放在一起比较:
TRUNCATE TABLE :删除内容、释放空间但不删除定义。
DELETE TABLE: 删除内容不删除定义,不释放空间。
DROP TABLE :删除内容和定义,释放空间。
order by与group by的区别
order by 排序查询、asc升序、desc降序 group by 分组查询、having 只能用于group by子句、作用于组内,having条件子句可以直接跟函数表达式。使用group by 子句的查询语句需要使用聚合函数。
+号的作用
在python中“+”的作用有两个:
1、运算符,两个操作数都为数值型的时候相加
2、连接符,两个都为字符串的时候,拼接字符串
在mysql中,+ 只有一个功能:运算符
①:两个操作数都为数值型,就做加法运算
②:其中一方为字符型,试图将字符型竖直转换成数值型,如果转换成功(字符串为数字内容),则继续做加法运算;如果转换失败,则将字符型数值转换成0.
③:只要其中一方为null,拿结果肯定是null
当你的一个表里的数据类型为int的字段里存在null的时候,用sum方法,这个时候结果不会是null。
这说明了sum函数会自动过滤掉内容为null的记录。
同理,avg() ,max() ,min()也一样会过滤null。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!