
美团本地生活场景的短视频分析

分享嘉宾:马彬 博士 美团 技术专家
编辑整理:刘小辉
出品平台:DataFunTalk、AI启蒙者
导读:在硬件、软件技术发展的助推下,我们正进入一个视频爆发的时代,无论从用户还是内容维度,视频数据都蕴含着非常大的信息量,在视频数据的分析中AI算法大有可为,无论是视频的创作、审核、编辑还是分发等环节都能看到AI技术的应用。在各种各样业务场景的驱动下,美团开展了很多视频分析相关的AI技术实践。本次分享的题目是本地生活场景的短视频分析,主要围绕下面三点展开:
-
短视频分析背景介绍
-
短视频分析技术在美团的技术实践
-
总结与展望
01短视频分析背景介绍
1. 视频行业发展趋势
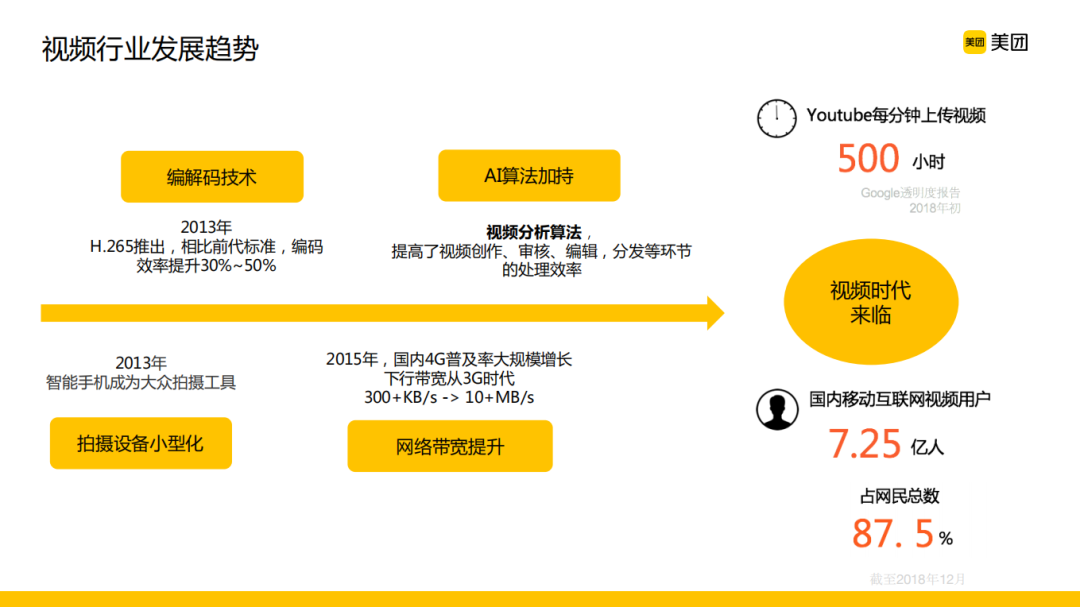
近年来,不管是从技术还是从日常生活,都能感受到我们正在进入到一个视频爆发的年代,当然这背后的一些软件和硬件的技术成为了这件事情的一个助推。从这些统计数据可以看到,无论是内容还是用户维度,视频数据都包含了非常大的信息量。在视频数据的分析过程中,不管是视频的创作、审核、编辑还是分发,AI算法都大有可为。这是视频行业整体现状的一个背景。
2. 美团AI ——"场景驱动技术"

美团的AI相关技术非常有特色,一个特点或者优势是“场景驱动技术”。除了大家比较熟悉的外卖,美团在吃、住、行、购、玩以及生活事务等方面有各种各样的业务应用场景,每个场景都会有一些特殊的视觉相关需求,在不同的场景下又会有不同特色数据内容的沉淀,这些场景和数据特点驱动着我们去做一些底层AI技术相关的沉淀,同时AI技术在打好一些基础之后,又会反过来赋能业务场景的一些应用。计算机视觉技术显然是AI平台层一个不可或缺的部分,这也是今天我们将展开去呈现的一部分。

在美团的业务场景下,为什么要对视频数据进行利用和分析?以常见的用户点评为例,传统的文本加图像在呈现信息的时候会有一些不足,相比之下,如果以视频点评的形式去呈现一个非常有创意的内容,不仅对商家来说是一个比较好的信息的宣传,对于用户来说,也是一个更加生动的信息获取的维度。在这种情况下,相信大家可以感受到美团在短视频上其实是大有可为的。
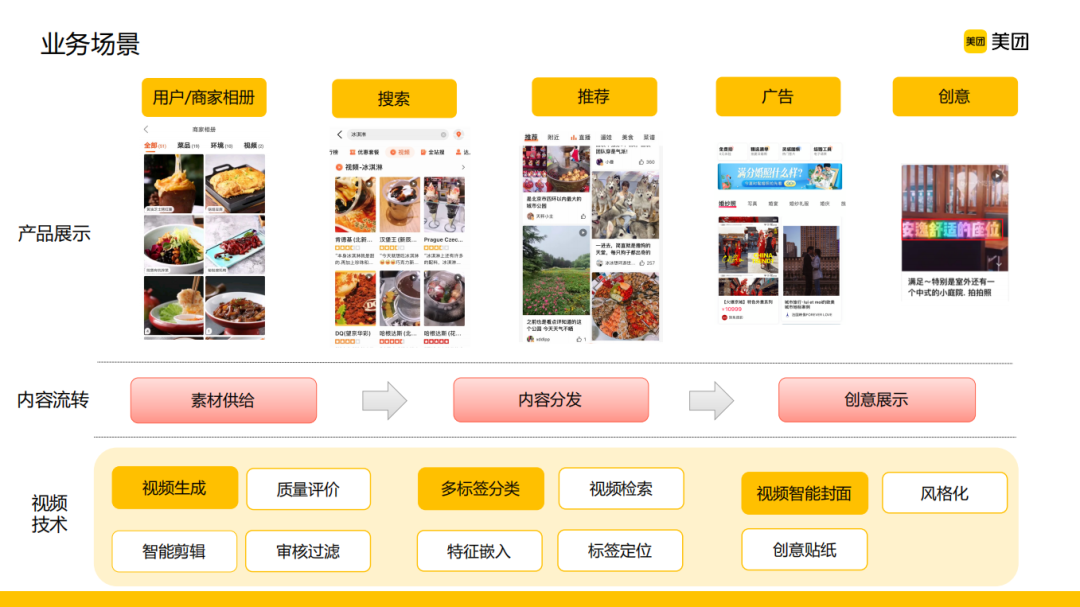
按照视频行业的大致划分,美团的视频绝大多数属于本地生活场景的碎片消费,这其实也是符合大家的认知的。美团的业务场景非常多,不管是在B端还是C端,丰富的供给源和展位都有非常多短视频内容的呈现。在这样的背景下,可以看到美团不仅有丰富的应用场景,同时又有丰富的视频内容和展位。对应到线上的这些应用,往下技术层要做的事情也就逐渐浮出水面,它是一个从视频内容的素材供给到内容分发以及创意展示全链条的一个AI赋能的情况,同时也可以看到在每一个内容流转的环节都有很多计算机视觉技术可以去发挥作用。
02短视频分析技术在美团的技术实践
1. 视频多标签分类
背景:

对于原始视频数据,仅仅利用元数据、文本或者用户点击行为开展业务应用,由于缺乏对视频内容的把控,存在很多局限性。视频打标通过对视觉内容进行一些理解能够更好服务于内容运营、用户画像、搜索、推荐、广告等业务应用,这其中的一些场景要求必须对内容有一些显式标签的把控。比如在内容运营的场景下,有时需要进行数据资产的盘点,希望知道美食的视频有多少,酒店住宿的视频有多少,然后对于缺失的部分有针对性进行补充运营,这种情况下对视频内容的理解如果只是依靠嵌入特征的隐式表征是不太能满足业务上的定制化需求的。在这样的大背景下,我们需要对视频内容进行一个标签化的理解,即对视频进行多标签分类。
挑战:

视频多标签分类有什么难点呢?在美团的场景下,数据非常丰富多样,如何有效构建模型以及我们的标签体系成为分类模型启动阶段需要克服的第一个困难。其次,初始模型构建之后,前期要对标签保证一个准确率,但是标签覆盖率可能会有一定问题,很多业务数据是打不上标签的,如何进行标签体系的扩展是第二步。最后,因为内容的更新和迭代是一个持续的过程,所以技术打标的能力也是需要有一套能够增量学习的机制,从而进行高效的样本迭代,这是第三个非常关键问题。下面分别就这三步介绍我们在这方面的一些技术实践。
初始模型构建:

为了快速在业务场景下构建初始的打标能力,最直接的想法就是通过外源数据,利用一些公开的数据集进行知识和标签的迁移。公开数据集中Google的YouTube-8M数据集与多标签分类这个场景最为契合,这个数据集具有非常丰富的实体、场景、动作等各类标签,而且相对通用,具有一定的迁移性,可以应用到我们的业务场景中。模型结构是相对容易处理的一件事情,往年的竞赛中有很多可供参考的模型结构,比如常用的Aggregation、Sequential相关模型。其中,前者逐帧提取特征,然后利用Pooling形成整个视频的表征,后者通过RNN序列建模进行视频特征的抽取。此外,假设提供原始视频的情况下,还有3D Conv、Two-stream这样两类主流的视频分类模型,这些基本涵盖了视频分类中主流的一些方法。结合我们的业务场景,由于我们的视频大多是分钟级或者几十秒甚至十几秒的小视频,时序的长时上下文重要性不那么强。同时我们的业务场景以实体和场景标签为主,运动特征虽然能够提供增量信息,但在前期从零到一构建标签模型的阶段并不是刚需。结合这两点,我们选择了第一类Aggregation模型。

由于YouTube-8M数据集的内容和本地生活场景还是有比较大的差别,数据内容和标签的差异是接下来我们要处理的一个更为困难和实际的问题,这也是当前任何一套数据驱动的Deep learning model需要克服的问题。在Facebook以及Google的一些工作的启发下,我们提出了一套半监督的、知识迁移的学习范式,首先利用公开数据集训练的Teacher Model在业务场景下的无标注数据上进行打标,在这个过程中利用置信度卡控、相似性距离度量或者Label Propagation这类半监督学习常用的方法进行一些伪标签的清洗,从而获得业务场景下的一些标注数据,然后利用这些标注数据进行Student model的微调。这个过程可以进行若干轮的迭代,Student model学习到一些信息之后,可以又变成Teacher model进行下一轮的迭代。通过这样一番初始模型的构建,我们在业务场景的数据下,看到一个明显的效果提升,不同的品类下的一些视频标签的准确率有了非常大的提升。
标签体系扩展:

第二步紧接着面临的问题是初始的标签体系难以保证对业务场景内容有一个很好的覆盖,这里我们从横向扩展与纵向细化两方面进行了标签体系的扩展。
① 横向扩展
我们尽量在少标注的情况下通过两方面的优化完成这件事。一方面对于这类打不上标签的视频,通过中间层的feature embedding进行视觉特征的聚类,然后人工对聚类的结果进行抽象分析,选择比较契合业务场景的标签对一个或者一批视频进行打标,快速进行横向标签的扩展。另一方面主动扩充内容理解的维度,在利用通用多标签分类数据集迁移知识的同时,从场景分类、人脸检测、人体分析等相关数据集去迁移知识。
② 纵向细化
标签力度过粗是公开数据集标签体系存在的另一个问题,为此我们结合业务场景下图像理解积累的一些美食的场景分类以及菜品的细粒度识别相关的能力和模型,对视频打标的结果进行了纵向的优化和扩展,完成一些细粒度标签的菜品标注,从而为业务上的应用提供了非常好的帮助。
数据高效持续迭代:
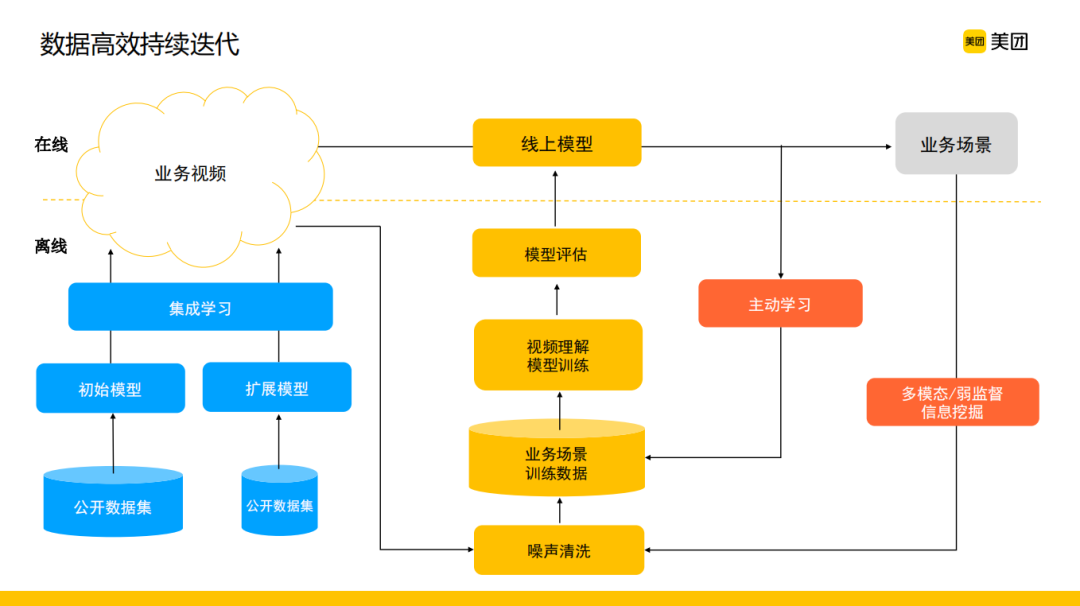
第三步面临的问题是如何实现数据高效持续的迭代,因为考虑到标签体系的扩展过程以及样本随时间的迁移,要求我们有一个持续学习的过程。图中蓝色部分基本代表了模型的冷启动与标签维度扩展,更重要的是要有一套从线上回流的机制,对应红色部分。一方面在没有业务场景标签交互的情况下,通过主动学习的方式查询一些最值得人工标注的样本,例如基于置信度或者多模型投票都可以很有效的找出模型理解不到位的线上真实样本,然后通过人工标注的方式扩充样本。另一方面业务场景中有很多弱监督的数据,利用这部分数据能够很好的帮助我们持续去迭代模型的性能。
2. 视频智能封面
背景:

在信息流场景下,最先呈现给用户的信息通常都是需要经过精挑细选的。比如按搜出图场景下,呈现给用户的内容与用户查询的相关性需要非常强的个性化,而在头图优选或者推荐这些个性化要求相对弱的场景,即使不太知道用户明确的意图是什么,我们也应该选择相对质量较好的图来进行一个呈现。这是以往信息流场景下图像相关的应用,视频智能封面的逻辑与这个其实是非常类似的,因为封面对于视频来说就像是相册的头图一样。在前置的展位上,我们不能把整个视频全部播放出去,需要选择最精彩或者与用户意图最相关的一段作为封面进行呈现,这对于给用户提供比较好的信息服务是非常重要的。
算法整体流程:

对于一个输入视频,首先需要进行一些候选片段的抽取,然后比较关键的一个过程是对这些片段进行筛选和排序,排序的质量直接决定了最终优选封面的好坏。在用户没有特别明确的意图或者偏好的场景下,我们可以从质量或者其他角度推荐最为稳妥的一套通用智能封面,而在搜索或者其他用户意图比较明确的场景,我们需要根据语义进行个性化的理解,然后推荐出语义相关的智能封面。下面分别介绍通用智能封面和语义智能封面相关算法流程。
通用智能封面:
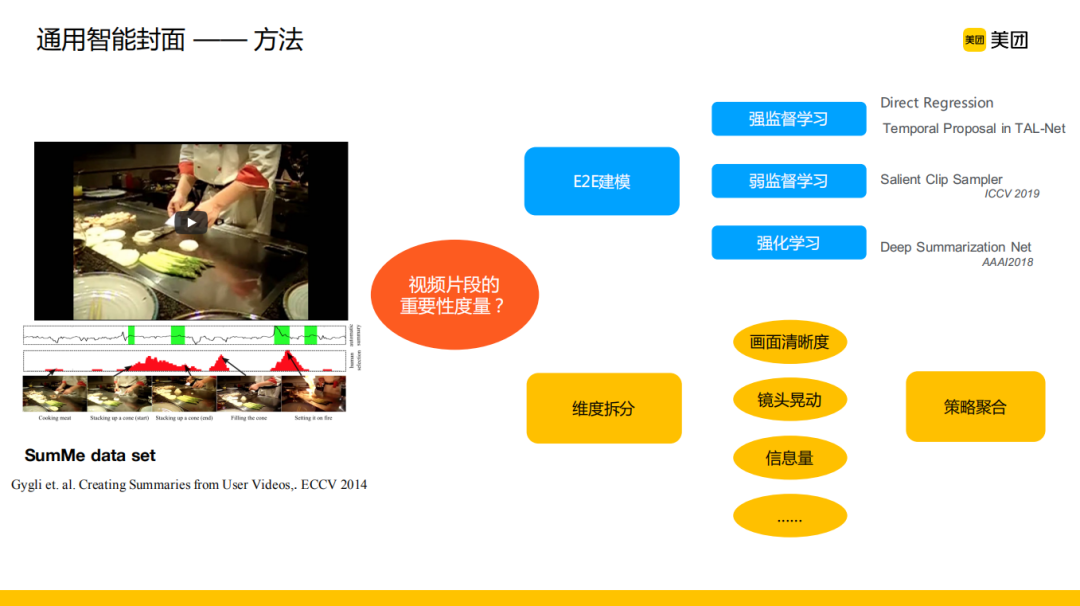
通用智能封面最核心的部分是视频片段的重要性度量,我们需要从视频的重要性波形图中抽出重要性最高的片段往前排作为封面。现有的方法主要分为两类,第一类是端到端模型,利用强监督学习、弱监督学习或者强化学习的方式进行建模,比如利用强监督学习直接去回归人工标注的显著性分数或者精彩度评分值。另一类在冷启动阶段更好处理,可解释性也更强,做法是利用重要性度量进行维度的拆分,人工去定义封面的通用质量评价标准,比如画面清晰度、镜头晃动、信息量等维度,然后每一个维度通过底层特征或者传统的图像质量评价(IQA)方法计算评分,最终通过策略或者模型进行各维度评价结果的聚合。如果在业务场景中能够获取到相关监督信号,第一类方法是非常好并且值得尝试的。在前期能力积累中以及考虑模型的可解释性,我们主要采用第二类方法,在迭代一段时间之后,随着样本的积累可以相应转化到第一类方法。
语义智能封面:
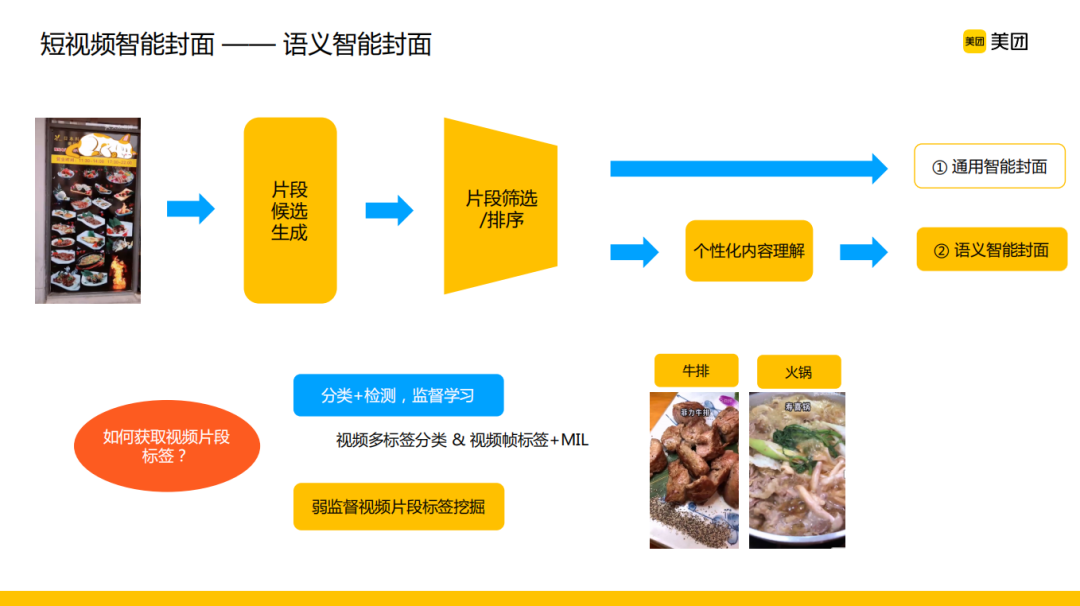
语义智能封面是与用户意图强相关的,不仅需要筛选出一些精彩片段,同时还需要对片段内容的语义有一定的把控,其中关键的技术难点就是如何获取视频片段的标签。最常规的做法是通过图像分类检测或者视频片段的监督学习进行分类打标,这种做法不过多展开介绍,重点介绍下面这种有业务场景特色的处理方式,即基于弱监督学习的视频片段语义标签挖掘。
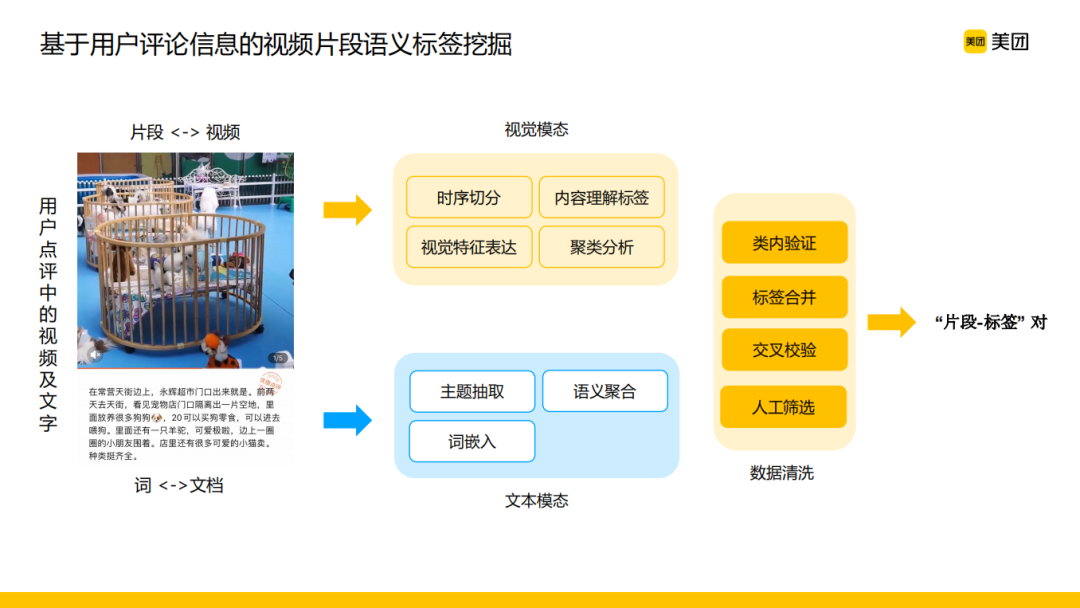
在美团的场景下,我们可以看到用户在拍摄一段点评视频的同时,还会配有相应的一段描述文字,这个时候两个模态之间是有很多相关性或者说共识存在的,而且视觉维度一个视频片段和整段视频的关系与文本维度一个词与整段文本之间的关系是有可类比性的。在这种情况下,我们分别对视觉模态和文本模态进行一些处理,然后将两方面相关的理解结果进行标签合并、交叉校验等数据清洗操作,进而挖掘出一大批“片段-标签”对。
业务应用:

在实际生产环境中,我们通过这样的方式从用户评论的内容中挖掘出的买手机游戏平台地图标签与视频片段的相关性是非常高的,挖掘出的标签可以直接用到相关的线上应用,比如最典型的用户搜索场景下,搜索引擎能够根据用户的查询内容推出语义相关的封面呈现给用户,通过这种方式视频封面与用户搜索内容的相关性有了比较明显的提升。
3. 视频生成
背景:

视频生产在整个产品的链条中扮演的主要是扩充供给的作用,比如支撑商家相册内容的丰富。
视频生成技术:

在美团的场景下,视频生产技术的一个分层抽象会经历一个从下到上的处理流程,每一块都会有一些相应的技术点。对于素材筛选,因为输入的素材丰富多样,涉及图像、视频、音频、文本,所以每一块都需要进行一些针对性的技术的处理,然后再向上通过合成渲染、统一的风格化处理,最后输出内容到业务上进行分发和应用。下面主要以图像素材的筛选以及处理为例,展示两个业务场景下真实的技术应用实例。
应用场景:
① 餐饮场景

在餐饮场景下,我们需要为商家生成一些宣传的小视频或者动图,这对于商家或者运营侧来说是一个端到端的黑盒,只要输入商家的店铺ID就能自动化生成最终的一个呈现结果。这里我们技术上图像会进行很多素材的AI理解和处理:首先基于识别质量卡控、内容去重对商家的相册进行一个整体的结构化以及质量的排序;然后通过理解内容找出来一些需要的图像并基于图像美学质量评价进行素材的精排;最后进行智能裁切、局部优选、动效渲染来整合素材生成最终的展示视频。在这个自动化的处理流程中,AI技术扮演了重要的角色,比如在素材理解上对菜品的识别和理解能力是比较核心也是很有美团特色的,同时还有素材的智能裁切,这其实都依赖于我们在信息流场景下一些长期的实践积累。
② 酒店场景
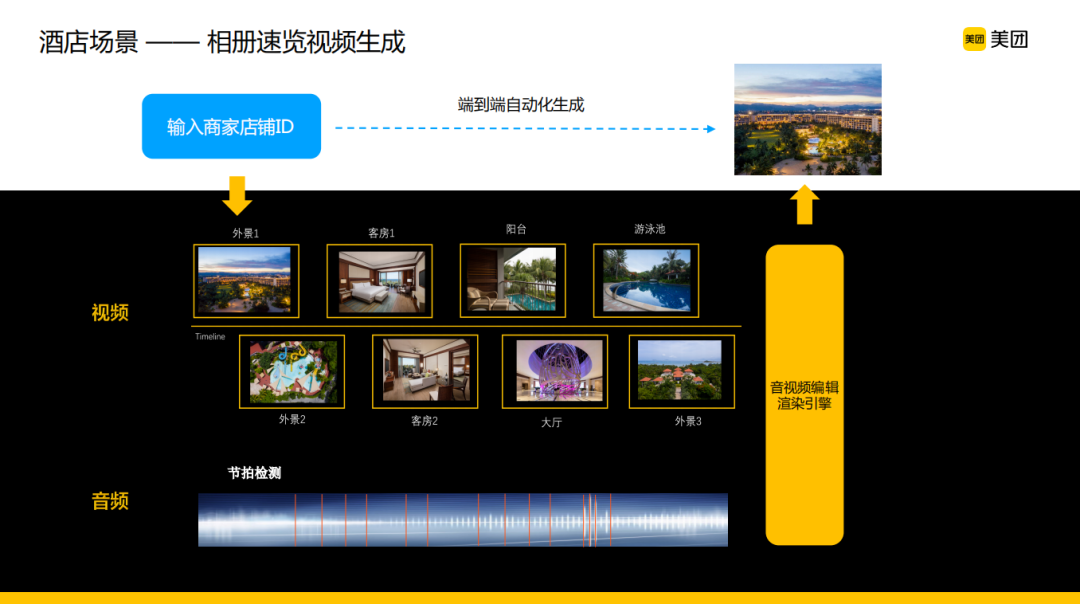
相比于餐饮场景,酒店场景多了一些酒店住宿行业的特色,业务上对于信息内容的呈现有类似于行业脚本这种比较好的呈现顺序,同时这个场景下对于视频和音频相关的配合也有比较高的要求,AI会增量做一些音频节拍的检测辅助人工进行一个卡点,最终呈现出一个观感和体验更加好的相册速览的效果,用户也能很方便地获取各个维度的信息。
03总结与展望
随着AI技术的发展以及5G等通讯行业技术的提升,视频在人们本地生活场景下将会扮演愈发重要的角色,视频分析技术将在本地场景中发挥更大价值。通过无监督、自监督以及多模态相关的内容理解技术,挖掘利用业务场景下海量数据中的有效信息将是比较重要的一个技术发展方向。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
嘉宾介绍:

马彬 博士
美团 | 技术专家
马彬,美团技术专家。2014年博士毕业于北航计算机学院,2017年加入美团,目前主要负责线上视频理解与生成方向的技术研发工作。此前曾就职于佳能研究院,研究方向为图像视频中的场景文字识别。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步