

k8s阶段08 k8s扩展(kubectl插件), 调度器(亲和调度, 污点和容忍度调度), 集群日常管理, 高可用集群部署, 集群版本升级
Kubernetes 扩展机制
扩展Kubernetes
1.kubectl插件 2.API Server扩展身份认证、鉴权和动态准入控制相关插件 3.API扩展,以支持更多的资源类型 4.调度器扩展以支持更多调度算法 5.控制器扩展以支持更多的Controller或Operator 6.网络插件,扩展Kubelet以配置Pod网络 7.设备插件,扩展Kubelet以支持更多的硬件,例如GPU 8.存储插件,扩展Kubelet以支持更多的存储卷类型
kubectl插件

kubectl插件: 1.kubectl会自动加载环境变量$PATH所指定的路径下以 "kubectl-" 为前缀的可执行程序, 并以之为插件 #例:执行只要输入kubectl xyz, 它会自己去找kubectl-xyz程序(注意,如果命令重了,内置的插件高于一切插件) #这里开发一个kubectl程序,甚至写一个shell脚本命名为kubectl-开头,放到$PATH下也可以 2.安装插件时,将此类的程序文件放置于环境变量$PATH所指定的任意一个路径下即可 常用插件列表: https://github.com/ishantanu/awesome-kubectl-plugins #示例: 安装kubectl-cilium(可以不用进入容器,查看cilium的状态) #从上面常用插件网下载 kubectl-cilium_v0.1.2_linux_amd64.tar.gz 版本 [root@master01 ~]#tar xf kubectl-cilium_v0.1.2_linux_amd64.tar.gz [root@master01 ~]#mv kubectl-cilium /usr/local/bin/ #放到第三方程序安装路径下 #可以使用kubectl cilium 命令了 #查看节点02上对应的cilium信息 [root@master01 ~]#kubectl cilium exec node02 cilium status #显示更详细信息--verbose,为了不让命令被kubectl识别,前面命令当中再加上 -- [root@master01 ~]#kubectl cilium exec node02 -- cilium status --verbose #就像插件在内部使用对应命令是一样的了 3."kubectl plugin list" 命令可列出所有已经安装的插件 #示例: [root@master01 ~]#kubectl plugin list The following compatible plugins are available: /usr/local/bin/kubectl-cilium 4.插件程序文件名称不能与kubectl的现有命令相同, kubectl不会加载这类插件 使用Krew管理kubectl插件 1.Krew是由Kubernetes SIG CLI社区维护的插件管理器,常用于发现和安装kubectl插件 2.Krew自身也是kubectl的插件之一 https://github.com/kubernetes-sigs/krew/releases 3.常用命令 update: 更新索引 search: 搜索插件 install: 安装插件 info: 打印插件相关的信息 upgrade: 升级安装的插件 uninstall: 卸载插件 #示例: #安装krew,从上面官网下载amd64版本 krew-linux_amd64.tar.gz [root@master01 ~]#tar xf krew-linux_amd64.tar.gz #解压出krew-linux_amd64,移动到$PATH下,要么直接作为执行命令,要么作为kubectl插件运行(改名kubectl-krew) #这里作为kubectl插件 [root@master01 ~]#mv krew-linux_amd64 /usr/local/bin/kubectl-krew #更新索引,把索引信息更新到本地 root@master01 ~]#kubectl krew update #查找cilium插件 [root@master01 ~]#kubectl krew search cilium #查看所有插件 [root@master01 ~]#kubectl krew search all #搜索/安装tree插件(需要开代理) [root@master01 ~]#kubectl krew search tree [root@master01 ~]#kubectl krew install tree #查看deployment demoapp下有哪些资源 root@master01 ~]#kubectl tree deployment demoapp
API扩展
API端点 群组: CORE https://HOST:PORT/api/v1/KIND/OBJECT 非核心群组 #资源客制化属于非核心群组 https://HOST:PORT/apis/GROUP/VERSION/KIND/OBJECT 资源客制化 (Custom Resource) 1.资源是Kubernetes API中的端点,自定义资源便是对这类端点的扩展 2.自定义资源以动态注册的方式添加至API Server 3.资源本身仅能用来存取结构化数据,其声明式API的特性,依赖于专用的自定义控制器(Custom Controller) 自定义控制器可以用于任何类别的资源,但它们同自定义资源协同使用时更为般配 Operator模式,即是设计用来帮助用户创建自定义资源及控制器的扩展(Extensions)开发机制和框架 添加自定义资源的途径 1.API Server源代码二次开发 #不推荐 版本更新较难 有编程语言限制(golang) 2.CRD (CustomResourceDefinitions) CRD自身是API Server内置的资源类型 以创建资源对象的方式进行定义CRD对象,无须运行额外的服务器程序 3.API Aggregation 开发独立的API Server,在其中添加自定义资源 独立运行,并由API Server中的API Aggreator代理和继承 较之CRD,在处理性能、策略、认证、鉴权等方面提供了更多的可能性 #示例: ProjectCalico #CRD方式 Metrics Server #API Aggregation方式, 为独立的API Server
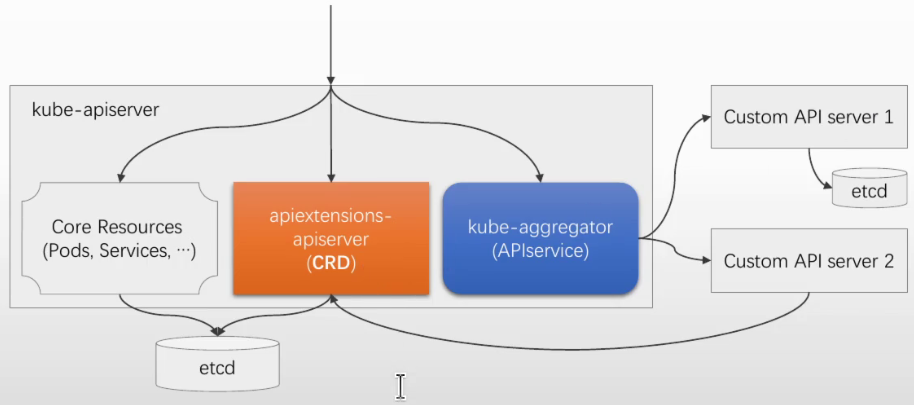
创建和使用CRD
CRD CRD APIA用于让用户自定义资源类型 用户通过创建CRD资源对象, 来定义新的资源类型 用户再通过定义新的资源类型下的对象,创建CR 这些通过声明式API定义的CR,其实际意义依赖于自定义的Controller或Operator Kubernetes API Server负责处理自定义资源对象的存储 列出现有的CRD kubectl get crds 定义CRD的关键字段 group <string>: 资源所属的组 versions <CustomResourceDefinitionVersion>:版本定义 name: 版本号 schema: 各字段的定义 scope <string>: 作用域,集群级别或名称空间界别 names <CustomResourceDefinitionNames>: 资源名称定义
1调度器和调度流程介绍
Kubernetes调度相关的概念
Pod调度: 新创建的Pod,或者未被绑定到任何一个节点上的Pod,由kube-scheduler帮其从众多节点中挑选一个最佳适配 default-scheduler #默认调度器 关于调度 ◼ 在Kubernetes中,调度是指为新创建的Pod挑选一个最佳运行节点 ◼ 控制平面组件kube-scheduler是Kubernetes集群的默认调度器 ◆基于watch机制,注册监视API Server上新创建且尚未被调度到任何节点上的Pod ◆影响调度决策的因素包括资源需求、硬件/软件/策略限制、亲和以及反亲和要求、数据局部性等 ◆若没有任何一个节点能满足Pod的资源需求,则该Pod将被置于Pending状态,直至出现合适的节点 调度逻辑

kube-scheduler 为Pod执行调度决策时包含两个关键步骤 ◼ 过滤(Predicates 预选策略) ◆选出可满足Pod运行条件需求的可调度节点 ◼ 打分(Priorities 优选策略) ◆为选出的各个可调度节点计算得分,并进行排序 #过滤: ✓ 首先要满足Pod的资源需求 ✓ 而后要满足同其它Pod间的特殊关系限制 #节点冲突不能放同一节点,2pod频繁访问就放同一节点 ✓ 再次要满足同Node之间的限制条件 ✓ 最后确保整个集群资源得到合理利用 #优先打散或者优先堆叠
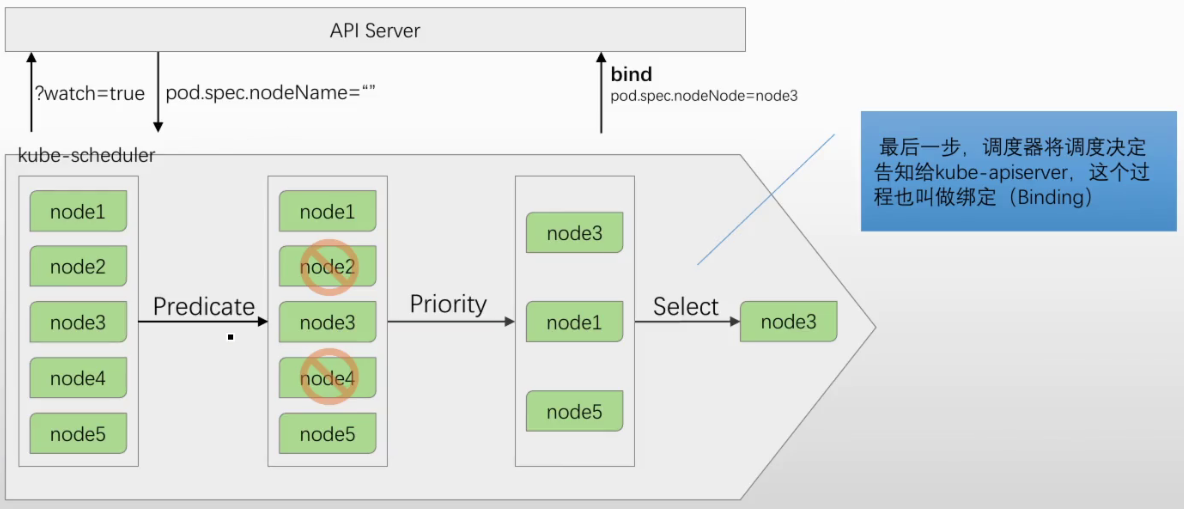
Predicates的功用,大体相当于节点过滤器(Filter) ◼ 它基于调度策略,从集群的所有节点中,过滤出符合条件的节点 ◼ 执行具体过滤操作的是一组预选插件(plugin) 经典调度器的预选算法分类 ◼ 存储约束条件 ◆名称中带有Disk或Volume的算法 ◼ Pod间的特殊关系限制 ◆MatchInterPodAffinity #匹配pod中的亲和性(pod和pod更愿意运行在同一个位置) ◼ Pod同Node的限制约束 ◆名称中带有Node的算法 ◆General Predicates ◼ Pod的散置性要求 ◆CheckServiceAffinity ◆EvenPodsSpread #如下图,绿色为默认启用,蓝色为默认没启用,选择循序从上到下,一旦不符合就排除不会往下继续判断 CheckNodeUnschedulable #是否不可被调度(手动表示,资源耗尽,节点异常) 可通过kubectl cordon设定 MaxEBSVolumeCount #EBS卷数量不能超过上限 CheckVolumeBinding #检查卷是否可以绑定 NoVolumeZoneConflict #没有卷区域冲突
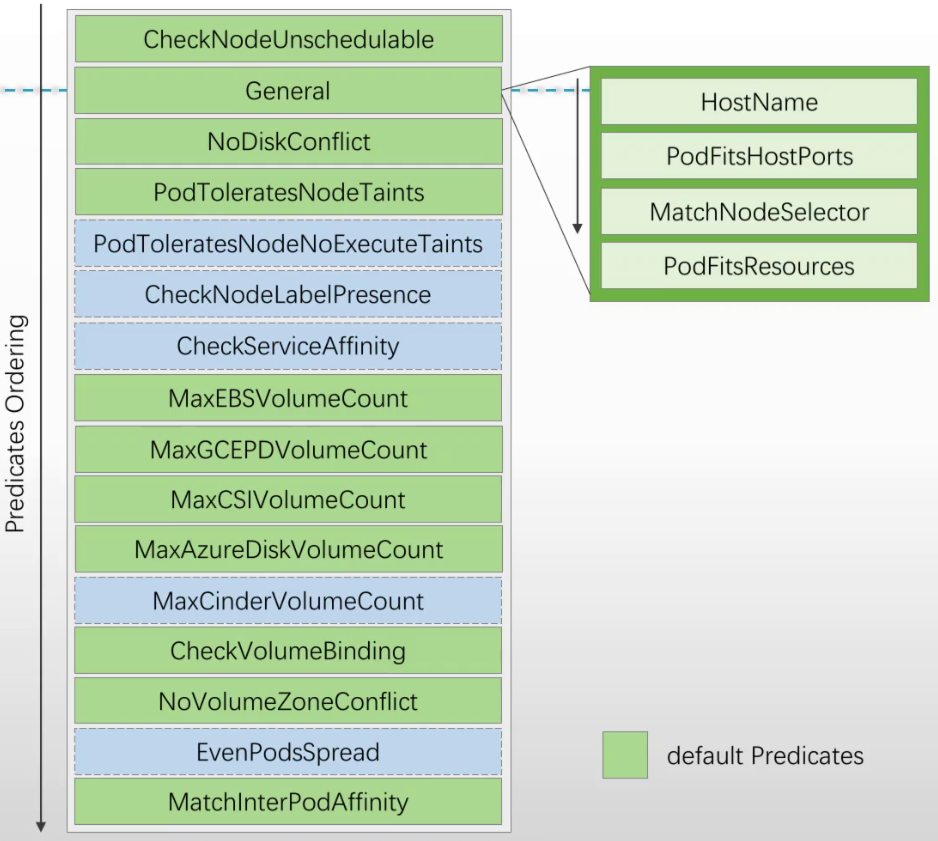
几个重要的Predicates说明 ◼ PodFitsHostPorts ◆检查Pod的各Containers中声明的Ports是否已经被节点上现有的Pod所占用 ◼ MatchNodeSelector ◆检查Pod的spec.affinity.nodeAffinity和spec.nodeSelector的定义是否同节点的标签相匹配 ◼ PodFitsResources ◆检查Pod的资源需求是否能被节点上的可用资源量所满足 ◼ PodToleratesNodeTaints ◆检查Pod是否能够容忍节点上的污点 ◼ MaxCSIVolumeCount ◆检查Pod依赖的由某CSI插件提供的PVC,是否超出了节点的单机上限 ◼ MatchInterPodAffinity ◆检查Pod间的亲和和反亲和定义是否得到满足 ◼ EvenPodsSpread #pod均衡调度 ◆为一组Pod设定在指定TopologyKey上的散置要求,即打散一组Pod至不同的拓扑位置
Priorities的功用,大体相当于计分器 ◼ 执行具体打分操作的是一组优选算法 ◼ 每个节点的总得分,则由各算法为其评分的各项分值之和 经典优选算法的分类 ◼ 节点资源分配倾向 ◆BalancedResourceAllocation #节点上各种资源使用率均衡的,分数越高,比如cpu,内存都使用50% ◆LeastRequestedPriority/MostRequestedPriority #打散/堆叠 ◆ResourceLimitsPriority #资源限制,默认未启用 ◆RequestedToCapacityRatioPriority ◼ Pod散置 ◆SelectorSpreadPriority、EvenPodsSpreadPriority、ServiceSpreadingPriority ◼ Node亲和与反亲和 ◆NodeAffinityPriority#硬亲和、NodePreferAvoidPodsPriority#软亲和(没亲和的也会选一个,不吊死) ◆TaintTolerationPriority #污点容忍程度打分 ◆ImageLocalityPriority ◼ Pod间的亲和与反亲和 ◆InterPodAffinityPriority

几个重要的Priorities说明 ◼ LeastRequestedPriority ◆优先散置Pod至不同的节点上,适合无须动态收缩集群规模的环境 ◼ MostRequestedPriority ◆优先堆叠Pod至部分节点上,适合云端按量计费、动态伸缩的集群环境 ◼ BalancedResourceAllocation ◆碎片率,即节点上各种资源(CPU/Memory/Disk)间在使用率上的差值,碎片率越大,得分越低 ◼ SelectorSpreadPriority ◆将同一Selector(通常是指由控制器资源配置的)下的所有Pod尽可能地散置到不同节点上 ◼ ServiceSpreadingPriority ◆将同一Service的后端Pod尽可能地散置到不同节点上 ◼ ImageLocalityPriority ◆优先将Pod调度至拥有其Container用到的Image的节点上 ◼ NodeAffinityPriority ◆优先将Pod调度至更能符合其对Node的亲和或反亲和条件的节点上 ◼ InterPodAffinityPriority ◆优先将Pod调度至更能符合其同其它Pod的亲和或反亲和条件的节点上
插件式调度框架
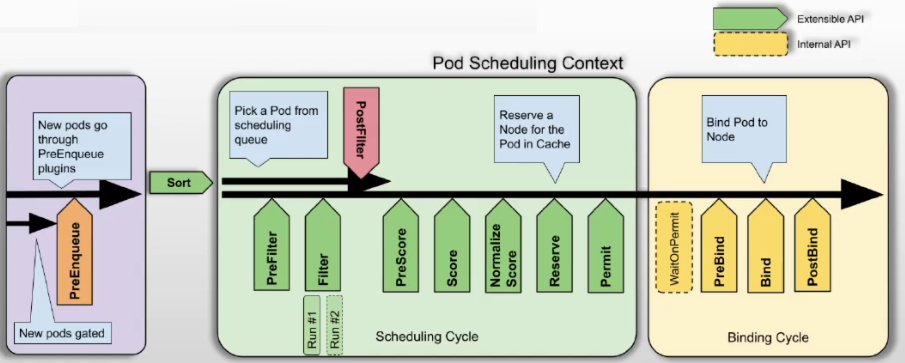
◼ Kubernetes自v1.19版提供的调度框架提供了插件架构, 为现有的调度器添加了一组新的“插件” API
◼ 插件API中,大多数调度功能都以插件形式实现
框架工作流程
◼ 调度框架上定义了一些扩展点,调度器插件完成注册后可以一个或多个扩展点上被调用
◼ 每次调度一个Pod的尝试都可划分为两个阶段:调度周期和绑定周期
◆调度周期完成为Pod挑选一个最佳匹配的节点,这类似于经典调度框架中的Predicate和Priority两阶段
◆绑定周期则是将调度决策应用于集群上的过程
资源需求(requests)和限制(limits)
资源需求和资源限制 ◼ 资源需求(requests) ◆定义需要系统预留给该容器使用的资源最小可用值 ◆容器运行时可能用不到这些额度的资源,但用到时必须确保有相应数量的资源可用 ◆资源需求的定义会影响调度器的决策 ◼ 资源限制(limits) ◆定义该容器可以申请使用的资源最大可用值,超出该额度的资源使用请求将被拒绝 ◆该限制需要大于等于requests的值,但系统在其某项资源紧张时,会从容器那里回收其使用的超出其requests值的那部分 requests和limits定义在容器级别,主要围绕cpu、memory、hugepages和ephemeral-storage四种资源 ◼ spec.containers[].resources.limits. ◆cpu、memory、hugepages-<size> 和 ephemeral-storage ◼ spec.containers[].resources.requests. ◆cpu、memory、hugepages-<size> 和 ephemeral-storage Extended resources ◼ 所有那些不属于kubernetes.io域的资源,即为扩展资源,例如“nvidia.com/gpu” ◼ 又存在节点级别和集群级别两个不同级别的扩展资源
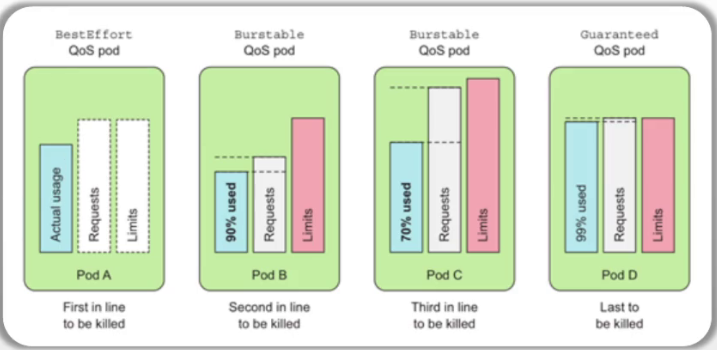
Pod QoS的类别 #Pod 服务质量的类别 ◼ Guaranteed #最高服务质量 ◆CPU和Memory都要满足条件:requests ==limits #cpu需求和cpu限制要一样,内存需求要等于内存限制 ◆其它资源类型不作限制 ◼ Burstable ◆CPU和Memory其一满足条件:requests != limits #cpu或内存有一个定义了,但是需求和限制不一样,就属于 ◆该类别的适用条件最为宽泛 ◼ BestEffort #如果资源紧缺,优先被干掉 ◆所有资源上都没有设定requests和limits 调度器考虑的要素 ◼ 仅会根据requests的值进行调度 ◼ 预选算法 ◆PodFitsResources ◼ 优选算法 ◆LeastRequestedPriority/MostRequestedPriority ◆BalancedResourceAlloca
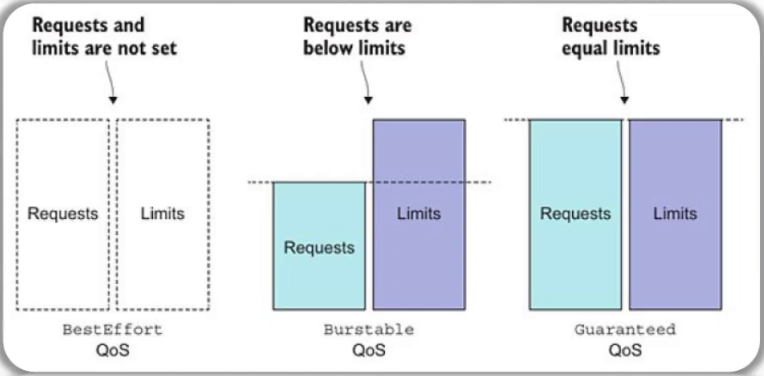
谁在需求的比例中使用越高, 谁将优先被kill
亲和性调度(亲缘性调度) 基于关系的调度: Pod同Node的关系 有节点自身的特性决定 pod.spec.nodeName #明确指定节点 pod.spec.nodeSelector #节点标签选择 #上面选择器如果不满足就 pending pod.spec.affinity.nodeAffinity requiredDuringSchedulingIgnoredDuringExecution #硬亲和(调度时受影响,调度结束不受影响) 必须满足的条件 #调度时受影响,调度结束不受影响 preferredDuringSchedulingIgnoredDuringExecution#软亲和(没有节点完全满足,选权重高的) 尽力满足的条件 Pod同其它Pod关系 由节点之上运行的Pod来决定 pods.spec.affinity podAffinity #亲和性 #例: Wordpress + MySQL podAntiAffinity #反亲和性 #例: MariaDB, MySQL 不适合放一个节点上
Pod Affinity和Anti Affinity
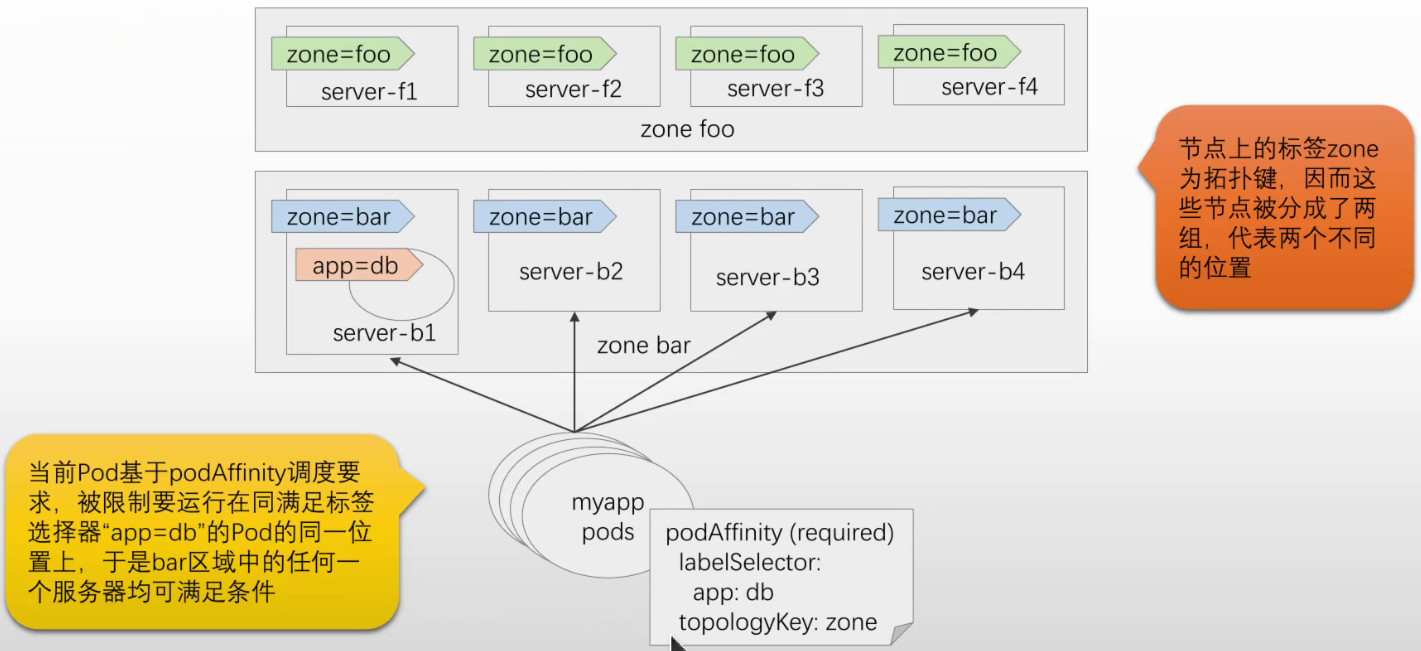
#Node Affinity语法规范 spec: ... affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution <[]WeightedPodAffinityTerm> PodAffinityTerm <PodAffinityTerm> #Pod亲和约束条件 labelSelector <LabelSelector> #标签选择器,挑选评估同其亲和性的目标Pod namespaceSelector <LabelSelector> #名称空间选择器,用于限制目标Pod namespaces <[]string> #名称空间列表,用于限制目标Pod topologyKey <string> #拓扑建,用于分组节点,同组即为统一位置 weight <integer> #权重 requiredDuringSchedulingIgnoredDuringExecution <[]PodAffinityTerm>
Pod Affinity示例
#如下图 如果topologyKey为hostname,那么只有主机名相同才为一组,待调度的Pod只能运行在b1上
Pod拓扑分散约束
定义跨拓扑域分配工作负载的策略
常用于在不显著增加成本的情况下增强抵御系统故障的能力
可基本策略保证在可用区出现故障时,其它可用区中仍存在可用Pod
拓扑域
在Kubernetes中,拓扑域是指按节点标签定义和分组的节点集合
列如,区域、可用区、机架、主机名都可以作为将节点划分成不同拓扑域的依据
Kubernetes使用Topology Key(拓扑建)来定义将节点划分至不同拓扑域的标准
散置偏差(Skew)
Pod打散调度至多个拓扑域后,拥有Pod数量最多的拓扑域,与拥有Pod数量最少的拓扑域之间的差值
Pod分散约束中允许的最大偏差及妥协策略
Pod分散约束策略基于允许的最大偏差(maxSkew)来定义Pod在拓扑域中的分散逻辑
无法满足最大偏差约束时,whenUnsatisfiable则用于定义妥协策略
DoNotSchedule(默认): 不予调度,Pod将处于Pending装填,实现的是硬限制
ScheduleAnyway: 根据每个节点的skew值打分排序后进行调度,因而实现的是软限制
Node Taints和Pod Tolerations调度
基于Pod和Node关系的调度策略 Node Affinity,用于定义Pod对Node的倾向性,即基于Node的特定属性(标签或字段)来吸引特定的Pod 而Node Taints(污点)则产生的是反作用力,它用来让Node来排斥特定的Pod,仅那些能够容忍Node Taints的Pod才能运行于该节点上 Pod上定义的用于容忍Node Taints的属性,成为Pod容忍度(Toleration) Taint和Toleration相互配合,可以用来阻止调度器将Pod分配到不适用的节点上 Node Taints 节点属性,定义在spec.taints字段上 也可以由 "kubectl taint" 命令进行添加或移除等管理操作 #TAINT_EFFECT:污点效用 kubectl taint nodes NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options] 污点效用: 指示该污点不能得到容忍时,将如何影响调度 1.PreferNoSchedule: 不能容忍该污点的Pod,要尽量避免调度至该节点 2.NoSchedule: 不能容忍则不许调度至该节点,但仅在调度决策执行期间产生影响,不影响已经运行于该节点的Pod 3.NoExecute: 不能容忍则不许调度至该节点,且将会对已经运行于该节点的Pod产生影响: 不能容忍该污点的Pod将立即被驱逐 若Pod能容忍该污点,且Pod的容忍度上未定义tolerationSeconds,则Pod可以一直运行于该节点 若Pod能容忍该污点,且Pod的容忍度上定义了tolerationSeconds,则Pod运行指定的时长后即会被驱逐
Pod Tolerations (容忍度)
管理Pod容忍度 Pod属性,定义在"spec.tolerations"字段上,列表值 每个列表项由key、operator、value、tolerationSeconds和effect几个字段组成 key: 容忍度键,即容忍的污点键 operator: 操作符,仅支持"Equal"和"Exists"两个 #Exists键存在就行,不管值 value: 键值 effect: 容忍的污点效用, 可用值与Node Taint相同 #容忍度的污点效用要大于等于污点效用才能容忍该污点 tolerationSeconds: NoExecute效用下,当前Pod可容忍某污点时,在驱逐前容许运行的时长 如何评估容忍度是否匹配污点? 一个容忍度"匹配"到一个污点,是指二者之间具有同样的key和effect,并且满足如下两个条件之一 operator是Exists operator是Equal,且二者的value相同 特殊情形 若某个容忍度的key为空,且operator为Exists,表示其可以容忍任意污点 若effect为空,则可以匹配所有键名相同的污点 #可以容忍一切级别的效用
容忍度与污点的匹配机制
节点上可定义多个Taints,Pod上也可定义多个Tolerations,针对一个节点,调度器调度决策过程如下 遍历该节点的所有污点,并过滤掉容忍度可匹配到的污点 余下未被过滤掉的污点,则由污点的effect来判定其满足状态 1.若存在至少一个效用为NoSchedule的污点,则Pod不会被调度至该节点 2.若不存在效用为NoSchedule的污点,但至少存在一个效用为PreferNoSchedule的污点,则调度器会尝试避免将Pod调度至该节点 3.若存在至少一个效用为NoExecute的污点,则Pod不会被调度至该节点;若Pod已经运行于该节点,则Pod还将被驱逐 何时需要使用基于Taint和Toleration的调度? 存在需要保留某些节点,避免调度器执行调度Pod至这些节点,或者将Pod从某些节点驱逐 保留给某些用户,或某特定应用的专用节点,例如专用于Ingress Controller的节点 配置了特殊硬件,只期望将用到这些硬件的Pod调度至这些具有特殊硬件的节点
Taints和Tolerations示例
Master节点通常会被添加污点,以避非控制平面应用运行到这类节点上 kubeadm部署的集群会自动为Master添加如下污点 key: node-role.kubernetes.io/control-plane #只有key没有值 effect: NoSchedule #示例: #查看主节点 [root@master01 ~]#kubectl get nodes master01 -o yaml ... spec: ... taints: - effect: NoSchedule key: node-role.kubernetes.io/control-plane #查看主节点上运行的cilium的pod [root@master01 ~]#kubectl get pods cilium-qjvgs -n kube-system -o yaml ... tolerations: - operator: Exists #可以容忍任意污点,没有效用说明容忍所有效用 #下面为容忍特殊污点的容忍度,即便节点当前处于不健康状态,也要部署上去,以确保产生网络通信,尝试恢复到正常状态 - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists - effect: NoSchedule key: node.kubernetes.io/disk-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/memory-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/pid-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/unschedulable operator: Exists - effect: NoSchedule key: node.kubernetes.io/network-unavailable operator: Exists
基于污点的驱逐
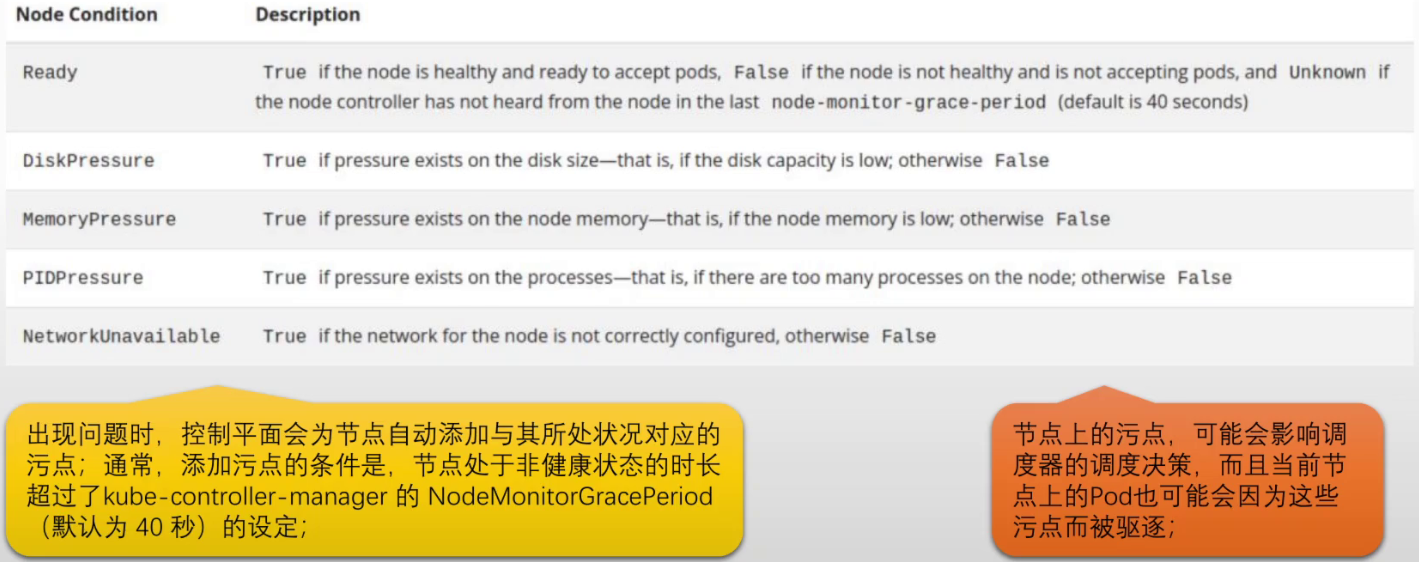
节点状态相关的某种条件(Node Conditions) 为真时,节点控制器会自动给节点添加一个污点#NoSchedule污点 node.kubernetes.io/not-ready: 节点未就绪,即节点状况Ready的值为"Fales" node.kubernetes.io/unreachable: 节点控制器访问不到节点,即节点状况Ready的值为"Unknown" node.kubernetes.io/memory-pressure: 节点内存资源紧张 node.kubernetes.io/disk-pressure: 节点磁盘空间资源紧张 node.kubernetes.io/pid-pressure: 节点PID资源紧张 node.kubernetes.io/network-unavailable: 节点网络不可用 node.kubernetes.io/unschedulable: 节点不可用于调度 node.cloudprovider.kubernetes.io/uninitialized: cloud provider尚未进行初始化 控制平面基于Node Controller自动创建与节点状况对应的、效果为NoSchedule的污点 调度器在进行调度时会检查节点上的污点, 而非检查节点状况 新建Pod时,可以通过添加相应的容忍度来忽略节点状况
Pod优先级
#当资源不足时,可以配置高优先级去抢占低优先级资源 #优先级类 [root@master01 ~]#kubectl get priorityclass #下面是系统内置的priorityclass NAME VALUE GLOBAL-DEFAULT system-cluster-critical 2000000000 false #优先级次子,集群级关键应用 system-node-critical 2000001000 false #最高优先级,节点级关键应用 Pod的优先级: pod.spec.priority pod.spec.priorityClassName #使用自定义优先级类
总结
pod --> node affinity pod --> pod affinity/anti-affinity requiredDuringSchedulingIgnoredDuringExecution #硬亲和 preferredDuringSchedulingIgnoredDuringExecution#软亲和 pod topology spread constanints maxSkew: 最大偏差 whenUnsatisfiable: 偏差不能得到满足时的调度策略 Taints/Tolerations: effect: 1.PreferNoSchedule 2.NoSchedule 3.NoExecute
K8S集群运维
Node 资源对象
Kubernetes Node API ◼ Kubernetes集群中的节点负责运行工作负载(Pod),它可以是虚拟机或者物理机,并运行有必要的服务 ◆kubelet、container runtime、kube-proxy等 ◼ 向API Server上添加Node对象的方式有两种 ◆由kubelet程序附带“--register-node=true”自动进行注册 ◆由管理员手动添加Node对象 ◼ 所有必要的服务都处于运行状态的Node,才会被API Server视作健康节点,并会尝试由该节点来运行Pod ◆Kubernetes会长期保存非健康节点的信息,并持续检测其是否转为了健康状态 ◆在节点变为健康之前,所有的集群活动都会忽略该节点 ◼ 节点名称用于惟一标识Node对象,且其名称必须是合法的DNS子域名 节点自动注册至API Server时,除“--register-node=true”外,通常还要基于多个选项提供配置#了解 ◼ --kubeconfig:认证到API Server所使用的kubeconfig文件路径 ◼ --node-ip:当前节点的IP地址列表,以逗号分隔 ◼ --node-status-update-frequency:向API Server发送自身状态信息的频率 ◼ --node-labels:注册时要添加到当前节点上的标签集 ◼ --register-with-taints:注册时要添加到当前节点上的污点列表 ◼ --cloud-provider:节点自身所在的云provider的API端点,常用于获取节点自身相关的信息
地址(addresses)
◼ HostName、ExternalIP(可从集群外部访问的IP) 和 InternalIP(仅能在集群内部路由到的IP)
状况(Condition)
容量(Capacity)与可分配(Allocatable) ◼ capacity字段用于标示节点拥有的资源总量 ◼ allocatable字段用于标识节点上可供Pod使用的资源量 #查看 capacity 和 allocatable [root@master01 ~]#kubectl get nodes node01 -o yaml #或者 [root@master01 ~]#kubectl describe nodes node01
节点状态相关的某种条件为真时,节点控制器会自动给节点添加一个污点 ◼ node.kubernetes.io/not-ready:节点未就绪,即节点状况Ready的值为 "False" ◼ node.kubernetes.io/unreachable:节点控制器访问不到节点,即节点状况Ready的值为 "Unknown" ◼ node.kubernetes.io/memory-pressure:节点内存资源紧张 ◼ node.kubernetes.io/disk-pressure:节点磁盘空间资源紧张 ◼ node.kubernetes.io/pid-pressure:节点PID资源紧张 ◼ node.kubernetes.io/network-unavailable:节点网络不可用 ◼ node.kubernetes.io/unschedulable:节点不可用于调度 ◼ node.cloudprovider.kubernetes.io/uninitialized:cloud provider尚未进行初始化 控制平面使用节点控制器自动创建 与节点状况对应的、效果为NoSchedule的污点 ◼ 调度器在进行调度时会检查节点上的污点,而非检查节点状况 ◼ 新建Pod时,可以通过添加相应的 容忍度来忽略节点状况
集群管理相关的日常维护操作1
证书管理(kubeadm部署集群时设定的证书通常在一年后到期) #正常pod可能会因为节点间通信down掉 检查证书是否过期 命令: kubeadm certs check-expiration 手动更新证书 #更新集群版本,会自动更新证书 命令: kubeadm certs renew 提示: kubeadm会在控制平面升级时自动更新所有的证书 #示例(证书管理): #监测集群中各个证书还有多少期限 [root@master01 ~]#kubeadm certs check-expiration #各个节点证书有效期限 CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Dec 11, 2025 15:03 UTC 361d ca no apiserver Dec 11, 2025 15:03 UTC 361d ca no apiserver-etcd-client Dec 11, 2025 15:03 UTC 361d etcd-ca no apiserver-kubelet-client Dec 11, 2025 15:03 UTC 361d ca no controller-manager.conf Dec 11, 2025 15:03 UTC 361d ca no etcd-healthcheck-client Dec 11, 2025 15:03 UTC 361d etcd-ca no etcd-peer Dec 11, 2025 15:03 UTC 361d etcd-ca no etcd-server Dec 11, 2025 15:03 UTC 361d etcd-ca no front-proxy-client Dec 11, 2025 15:03 UTC 361d front-proxy-ca no scheduler.conf Dec 11, 2025 15:03 UTC 361d ca no super-admin.conf Dec 11, 2025 15:03 UTC 361d ca no #4A证书有效期限 CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Dec 09, 2034 15:03 UTC 9y no etcd-ca Dec 09, 2034 15:03 UTC 9y no front-proxy-ca Dec 09, 2034 15:03 UTC 9y no #更新 #更新所有证书(也可以选择更新里面某个证书 kubeadm certs renew --help) [root@master01 ~]#kubeadm certs renew all 重置集群 #通常拆掉集群中的某个节点,一般先要排空节点(kubectl drain)也就是手动把节点上pod驱逐走(干掉) #kubectl drain命令还会把当前节点标记为不可被调度(相当于kubectl cordon) #kubectl drain可添加--ignore-daemonsets=true(忽略daemonsets),这种pod不驱逐也没事,直接down #驱逐完之后才应该执行kubeadm reset 提示: 危险操作,请务必再三确认是否必须要执行该操作,尤其是在管理生产环境时要更加注意 命令: kubeadm reset 负责尽最大努力还原通过'kubeadm init'或者'kubeadm join'命令对主机所作的更改 有些情况下需要配合 "--cri-socket" 选项使用 如果需要重置整个集群,一般要先reset各工作节点,而后再reset控制平面各节点,这与集群初始化的次序相反 最后还需要一些清理操作,包括清理iptables规则或ipvs规则、删除相关的各文件等
集群管理相关的日常维护操作2
#这里显示的是以kubeadm部署所对应的方法 令牌过期后,向集群中添加新节点 直接生成将节点将入集群的命令 kubeadm token create --print-join-command #只能添加工作节点 添加控制平面节点 先上传CA证书,并生成hash kubeadm init phase upload-certs --upload-certs 而后,生成添加控制平面节点的命令 kubeadm token create --print-join-command --certificate-key $CERT_HASH #示例: #获取添加新节点的命令(工作节点) [root@master01 ~]#kubeadm token create --print-join-command kubeadm join kubeapi.magedu.com:6443 --token 4757vj.ba1hrnzn29oghqmb --discovery-token-ca-cert-hash sha256:aee94a61a63e747fbfde7c75da91332894d59cca347d88346c8a0b7c723a59d5 #添加控制平面节点 #先上传CA证书,并生成hash [root@master01 ~]#kubeadm init phase upload-certs --upload-certs [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: 772d937c5eb08b20ae0e0d5d86761fb4975a8fc550abaaf5c298ae748f4af46b #生成添加控制平面节点的命令 [root@master01 ~]#kubeadm token create --print-join-command --certificate-key 772d937c5eb08b20ae0e0d5d86761fb4975a8fc550abaaf5c298ae748f4af46b kubeadm join kubeapi.magedu.com:6443 --token jiu139.pyrwf24shcjgyt0h --discovery-token-ca-cert-hash sha256:aee94a61a63e747fbfde7c75da91332894d59cca347d88346c8a0b7c723a59d5 --control-plane --certificate-key 772d937c5eb08b20ae0e0d5d86761fb4975a8fc550abaaf5c298ae748f4af46b
总结
Kubernetes集群运维: 日常维护: 更新证书 扩容: 添加更多的节点: 控制平面节点 工作节点 缩容: 排空节点: kubectl drain #如果数据存在在节点上,也要迁走 kubeadm reset #重置节点对象 kubeadm delete node 更新集群
高可用: 控制平面的高可用 工作节点的高可用: 提供更多的节点数量保证 业务的高可用: deployment, replicas=3 (1) Pod数量 (2) Pod中断预算 #确保不可用pod比例 控制平面组件: 1.etcd: 有状态、分布式、强一致性k/v存储 协议: #内生支持raft协议 内生支持集群架构 http协议 https协议 peer certs #使用对等证书 分区容错: #一部分节点联系不到了 quorum: #支持仲裁机制 with quorum: vote > total/2 #得票数大于一半 奇数个节点: 3,5,7 2.api server: 无状态 多实例,负载均衡 3.controller manager: 决定中心,避免"政出多门" #只能有一个工作,其他都是备 A/P A: 仅能有一个 P: 一至多个P leader election: #默认打开 分布式锁,抢占来进行选举 周期性更新锁 #锁状态没有更新,说明主down了,备重新抢 4.scheduler: A/P #也通过抢占锁选举
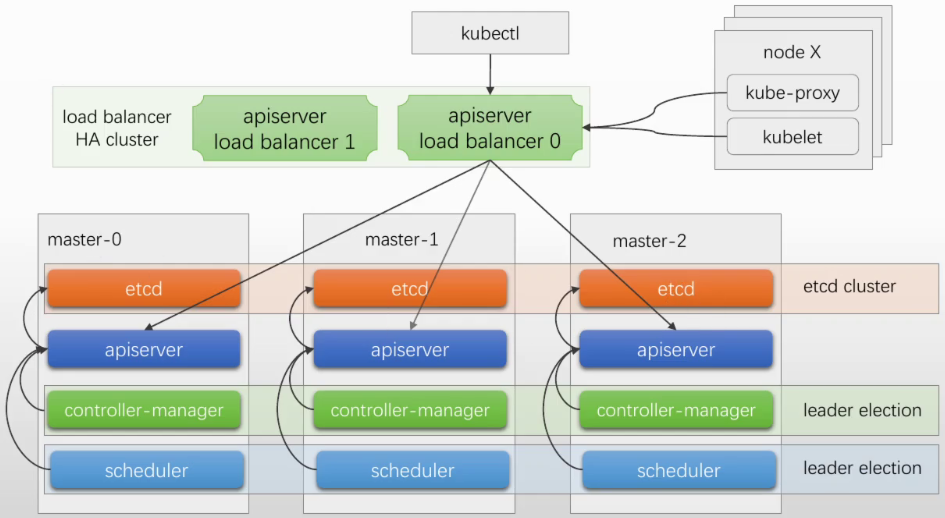
下图为堆叠式部署, 适合中小规模集群,100-200个节点。如果节点数量较大, 就把etcd独立部署在另外几个节点上
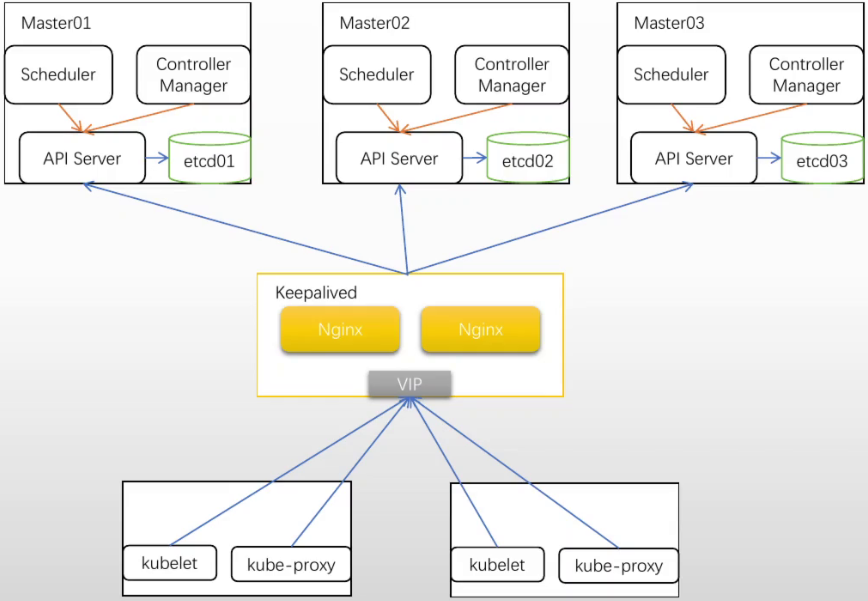
把当中的keepalive控制2个nginx节点去掉, 在每个节点上部署一个nginx, 这样能去掉2个nginx节点(如果外部kubectl客户端很多,还是用上图不要省nginx节点了)
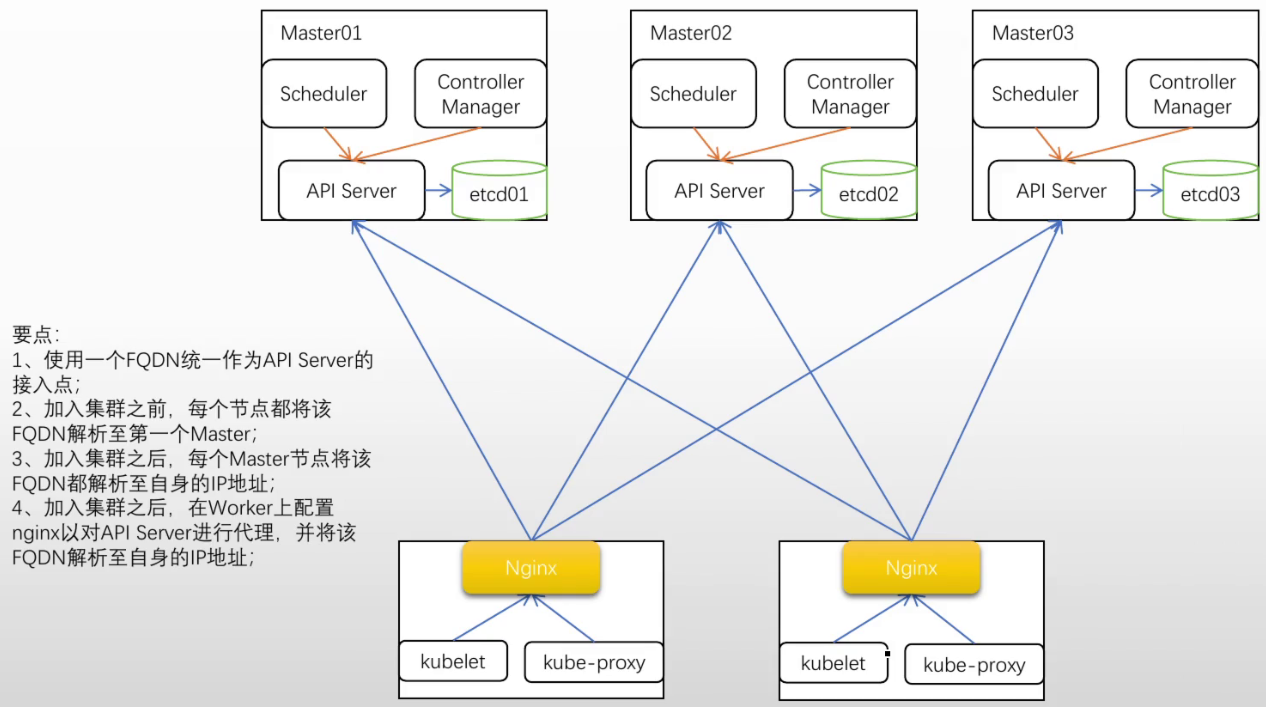
#实际操作示例 准备3个控制节点机器,3个工作节点机器 #几个节点之间做免密登录 #/etc/hosts文件配置 ip和主机名 10.0.0.151 kubeapi.magedu.com master01 10.0.0.152 node01 10.0.0.153 node02 10.0.0.154 node03 10.0.0.156 master02 10.0.0.157 master03 #拷贝到其他几个节点上 [root@master01 ansible-k8s-install]#scp /etc/hosts 10.0.0.152:/etc/hosts #每个节点执行 apt update #查看swap是否关闭 [root@master01 ~]#free -g #所有节点禁用swap [root@ubuntu ~]#swapoff -a #下载程序(里面有ansible程序,安装快一些) [root@master01 ~]#git clone https://github.com/iKubernetes/learning-k8s.git [root@master01 ~]#cd learning-k8s/ansible-k8s-install/ [root@master01 ansible-k8s-install]#vim cluster-install.sh MASTER_IP='10.0.0.151' MASTER_02_IP='10.0.0.156' MASTER_03_IP='10.0.0.157' NODE_01_IP='10.0.0.152' NODE_02_IP='10.0.0.153' NODE_03_IP='10.0.0.154' ... cat <<EOF >> /etc/ansible/hosts [master] ${MASTER_IP} node_ip=${MASTER_IP} [ha_masters] ${MASTER_02_IP} node_ip=${MASTER_02_IP} ${MASTER_03_IP} node_ip=${MASTER_03_IP} [nodes] ${NODE_01_IP} node_ip=${NODE_01_IP} ${NODE_02_IP} node_ip=${NODE_02_IP} ${NODE_03_IP} node_ip=${NODE_03_IP} #选github上1.31.2-1.1版本 [root@master01 ansible-k8s-install]#vim install-kubeadm.yaml vars: kube_version: "v1.31" kube_release: "1.31.2-1.1" # -1.1包名固定格式 [root@master01 ansible-k8s-install]#bash cluster-install.sh #到随意节点上查看 [root@node03 ~]#kubeadm version [root@node03 ~]#containerd --version #下面为主节点执行步骤 #先把镜像下载起来 [root@master01 ~]#kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers #部署Kubernetes集群(这里采用Cilium网络插件,并取代kube-proxy) 将来把kubeapi.magedu.com解析到主节点1,2,3 kubeadm init --control-plane-endpoint kubeapi.magedu.com \ --kubernetes-version=v1.31.2 \ --pod-network-cidr=10.244.0.0/16 \ --service-cidr=10.96.0.0/12 \ --upload-certs \ --image-repository=registry.aliyuncs.com/google_containers \ --skip-phases=addon/kube-proxy [root@master01 ~]#mkdir .kube [root@master01 ~]#cp /etc/kubernetes/admin.conf .kube/config #安装cilium cli [root@master01 ~]#curl -LO https://github.com/cilium/cilium-cli/releases/download/v0.16.21/cilium-linux-amd64.tar.gz [root@master01 ~]#tar xf cilium-linux-amd64.tar.gz [root@master01 ~]#mv cilium /usr/local/bin #直接可以使用cilium命令 #部署网络插件(使用vxlan协议) [root@master01 ~]#cilium install \ --set kubeProxyReplacement=strict \ #这里报错,改成true就可以了 --set ipam.mode=kubernetes \ --set routingMode=tunnel \ --set tunnelProtocol=vxlan \ --set ipam.operator.clusterPoolIPv4PodCIDRList=10.244.0.0/16 \ --set ipam.Operator.ClusterPoolIPv4MaskSize=24 #了解整个集群的cilium部署状况(等待部署完成) [root@master01 ~]#cilium status #添加两个控制节点(etcd会等待所有etcd成员加进来) (如果下载失败了,就在执行一次) [root@master02 ~]#kubeadm join kubeapi.magedu.com:6443 --token 5qah1z.zxxxjhvvffwqz0dk \ --discovery-token-ca-cert-hash sha256:5debc7dd45de0238c2bcbcf048791f25ce8dbc220957d5b7fdaec8aa3972be45 \ --control-plane --certificate-key 804408cc3a09ce11eb65c933ba25c3af8c3ab52f8195e5e0f712ff121689eb0f #把3个主节点上etcd组合起来,构建成集群(要下镜像,需要一点时间) #在master01上查看节点 [root@master01 ~]#kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready control-plane 25m v1.31.2 master02 Ready control-plane 4m33s v1.31.2 master03 Ready control-plane 4m7s v1.31.2 [root@master01 ~]#kubectl get pods -n kube-system -o wide ... etcd-master01 1/1 Running 1 (13m ago) 32m 10.0.0.151 master01 etcd-master02 1/1 Running 0 11m 10.0.0.156 master02 etcd-master03 1/1 Running 0 11m 10.0.0.157 master03 kube-apiserver-master01 1/1 Running 1 (13m ago) 32m 10.0.0.151 master01 kube-apiserver-master02 1/1 Running 0 11m 10.0.0.156 master02 kube-apiserver-master03 1/1 Running 0 11m 10.0.0.157 master03 kube-controller-manager-master01 1/1 Running 1 (13m ago) 32m 10.0.0.151 master01 kube-controller-manager-master02 1/1 Running 0 11m 10.0.0.156 master02 kube-controller-manager-master03 1/1 Running 0 11m 10.0.0.157 master03 kube-scheduler-master01 1/1 Running 1 (13m ago) 32m 10.0.0.151 master01 kube-scheduler-master02 1/1 Running 0 11m 10.0.0.156 master02 kube-scheduler-master03 1/1 Running 0 11m 10.0.0.157 master03 #master02节点上根据提示操作 (master03也按照如下操作) [root@master02 ~]#mkdir -p $HOME/.kube [root@master02 ~]#cp -i /etc/kubernetes/admin.conf $HOME/.kube/config #可以看出实际上配置指向kubeapi.magedu.com [root@master02 ~]#kubectl config view ... server: https://kubeapi.magedu.com:6443 #这里没有dns服务器,为了验证效果,手动修改master02的host的kubeapi.magedu.com指向 [root@master02 ~]#vim /etc/hosts 10.0.0.151 master01 10.0.0.152 node01 10.0.0.153 node02 10.0.0.154 node03 10.0.0.156 master02 kubeapi.magedu.com 10.0.0.157 master03 #此时使用kubectl联系到master02的api server上 [root@master02 ~]#kubectl get nodes #node01上安装nginx,kubectl通过四层代理负载均衡到3个master上(6443端口) [root@node01 ~]#apt install nginx #编辑nginx配置,追加四层代理 [root@node01 ~]#vim /etc/nginx/nginx.conf #追加(在http配置外,是四层代理) stream { upstream apiservers { server 10.0.0.151:6443 max_fails=2 fail_timeout=30s; server 10.0.0.156:6443 max_fails=2 fail_timeout=30s; server 10.0.0.157:6443 max_fails=2 fail_timeout=30s; } server { listen 6443; proxy_pass apiservers; } } [root@node01 ~]#nginx -t [root@node01 ~]#nginx -s reload [root@node01 ~]#ss -lnt State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 511 0.0.0.0:6443 0.0.0.0:* #测试 [root@node01 ~]#mkdir .kube #在任意主节点上复制认证文件到node01 [root@master01 ~]#scp /etc/kubernetes/admin.conf 10.0.0.152:/root/.kube/config #把kubeapi.magedu.com解析给本机,让请求发给自身6443端口,通过nginx负载均衡出去 [root@node01 ~]#vim /etc/hosts 10.0.0.151 master01 10.0.0.152 node01 kubeapi.magedu.com 10.0.0.153 node02 10.0.0.154 node03 10.0.0.156 master02 10.0.0.157 master03 [root@node01 ~]#kubectl get nodes #node01添加工作节点 (此时kubeapi.magedu.com其实指向的是自身) [root@node01 ~]#kubeadm join kubeapi.magedu.com:6443 --token 5qah1z.zxxxjhvvffwqz0dk \ --discovery-token-ca-cert-hash sha256:5debc7dd45de0238c2bcbcf048791f25ce8dbc220957d5b7fdaec8aa3972be45 #任意一个节点都能看到 [root@master02 ~]#kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready control-plane 89m v1.31.2 master02 Ready control-plane 68m v1.31.2 master03 Ready control-plane 67m v1.31.2 node01 NotReady <none> 21s v1.31.2 #node02,03上安装nginx,通过四层代理负载均衡到3个master上(6443端口) [root@node02 ~]#apt install nginx #编辑nginx配置,追加四层代理 [root@node01 ~]#scp /etc/nginx/nginx.conf 10.0.0.153:/etc/nginx/nginx.conf [root@node02 ~]#nginx -s reload #把kubeapi.magedu.com解析给本机,让请求发给自身6443端口,通过nginx负载均衡出去 [root@node02 ~]#vim /etc/hosts 127.0.0.1 localhost kubeapi.magedu.com 10.0.0.151 master01 10.0.0.152 node01 10.0.0.153 node02 10.0.0.154 node03 10.0.0.156 master02 10.0.0.157 master03 #node02,03添加工作节点 (此时kubeapi.magedu.com其实指向的是自身) [root@node02 ~]#kubeadm join kubeapi.magedu.com:6443 --token 5qah1z.zxxxjhvvffwqz0dk \ --discovery-token-ca-cert-hash sha256:5debc7dd45de0238c2bcbcf048791f25ce8dbc220957d5b7fdaec8aa3972be45 #任何工作节点宕机了,都不影响其他节点。任何master节点宕机,nginx配置了会监测api server健康状态,会从可用列表端点中摘除
企业配置
master: #下面例举的为etcd和主节点分开部署的情况 小型规模 #几十个node,几百个pod 3x 4C8G, etcd: 3x 4C8G(SSD/HDD) 中型规则 #node上百,pod上千 3x 8C16G /12C24G, etcd: 3x 8C24G(SSD) 大型规模 #最好用物理机 几千个容器 3x 16C32G/24C48G, etcd: 3x 16C48G(SSD/PCI-E SSD) 超大-物理机 3x 48C64G/96C128G, etcd: 3x 48C64G(PCI-E SSD/M.2)
3 集群版本升级
为何需要更新Kubernetes?
Kubernetes的发布周期 版本号遵循典型的版本控制机制 vX.Y.Z:X为主版本号,Y是次要版本号,Z是补丁版本号 2021年之前,Kubernetes每季度发布一个"次要"版本 自v1.22版本起,Kubernetes改为每年发布3个"次要"版本 发布逻辑遵循N-2模型,即当前版本及之前的两个版本遵循同样的发布策略 升级策略 多数工具和组件,通常只允许一次升级一个次要版本 #如1.22要升级1.23,然后才能升级1.24(测试环境先测试) 落后多个版本进行升级时,升级过程较为耗时,但一次一个次要版本也是确保升级成功的必要策略
版本升级前的注意事项
事前进行升级计划 根据Kubernetes团队发布的releases notes,详细了解变更的内容,尤其是API的变动 了解集群中使用的各类第三方项目同目标版本的兼容性,并整理要进行的必要变更措施#(可能需要提前更新第三方项目) 升级过程总的时长需求 如何通知集群上的各租户 如何进行测试和部署 总结前一次升级,是否有可用的经验教训等 在非生产环境中进行充分测试 创建与生产环境分离的Kubernetes集群 升级非生产集群的Kubernetes版本,记录所采取的步骤 测试并验证升级后的非生产集群中进行的工作负载是否能够按预期进行 根据上述经验教训,审查、记录和改进升级过程,以便更好地进行生产环境升级 使用滚动或蓝绿方式进行节点升级 严密监视设计过程 借助可观测工具栈, 严密监视集群的指标、日志和跟踪数据 重点关注的数据包括 获取应用程序的性能基线 验证集群应用程序的可用性 验证升级期间和升级完成后集群的整体运行状况 制定灾难恢复计划 恢复计划旨在尽可能快速、准确地回滚和恢复集群及其应用程序的状态,以减少停机时间和潜在的数据丢失 恢复计划的关键要素 备份集群的装填 记录集群的当前状态 基于可观测工具栈排查出问起的根源 记录从灾难恢复中获利的经验教训
升级kubeadm集群
升级步骤 1.升级控制平面节点 (1)升级kubeadm (2)升级控制平面第一个节点 (3)排空节点,将节点标记为不可调度并驱逐所有工作负载 (4)升级kubelet和kubebctl (5)解除节点保护 2.升级控制平面其他节点 3.升级工作节点 (1)升级kubeadm (2)执行升级 (3)排空节点 (4)升级kubelet和kubectl (5)解除节点保护 4.验证集群状态 #官方文档 https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/ #可以选择对应升级版本(右上角调成中文) 点击发行说明,可以看每个发行版本变更内容
升级实际操作示例
#更改软件包仓库,修改要升级的版本v1.31 [root@master01 ~]#vim /etc/apt/sources.list.d/kubernetes.list.list deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb/ / #确定要升级到哪个版本 [root@master01 ~]#apt update #显示可用的adm有多少版本,这里选1.31.4-1.1 版本进行更新 [root@master01 ~]#apt-cache madison kubeadm kubeadm | 1.31.4-1.1 | https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb Packages kubeadm | 1.31.3-1.1 | https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb Packages kubeadm | 1.31.2-1.1 | https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb Packages kubeadm | 1.31.1-1.1 | https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb Packages kubeadm | 1.31.0-1.1 | https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb Packages #升级控制平面节点 #对于第一个控制面节点 # 设定指定的版本号 [root@master01 ~]#apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.31.4-1.1' && \ sudo apt-mark hold kubeadm #验证下载操作正常,并且 kubeadm 版本正确 [root@master01 ~]#kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"32", GitVersion:"v1.32.0" #验证升级计划,看看有没有问题,会返回升级命令 [root@master01 ~]#kubeadm upgrade plan #升级,执行真正的更新操作 [root@master01 ~]#kubeadm upgrade apply v1.31.4 #一旦该命令结束,你应该会看到 [upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.31.x". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so. #如果网络插件需要升级,手动升级你的 CNI 驱动插件(这里已是最新版,不需要升级) #腾空节点(将节点标记为不可调度并驱逐所有负载,准备节点的维护) 调度器会把被驱逐的节点转移到其他节点上 [root@master01 ~]#kubectl drain master01 --ignore-daemonsets [root@node01 ~]#kubectl get nodes #可以看到该节点变为不可被调度 NAME STATUS ROLES AGE VERSION master01 Ready,SchedulingDisabled control-plane 4h49m v1.31.2 #升级 kubelet 和 kubectl (修改下面命令的版本号) [root@master01 ~]#sudo apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.31.4-1.1' kubectl='1.31.4-1.1' && \ sudo apt-mark hold kubelet kubectl #重启 kubelet [root@master01 ~]#systemctl daemon-reload [root@master01 ~]#systemctl restart kubelet #解除节点的保护(通过将节点标记为可调度,让其重新上线) [root@master01 ~]#kubectl uncordon master01 #查看 [root@master01 ~]#kubectl get nodes NAME STATUS ROLES AGE VERSION master01 Ready control-plane 4h52m v1.31.4 #升级其他控制节点 (master02和master03都执行下面操作) ----------------------------------------------------- #更改软件包仓库,修改要升级的版本v1.31 [root@master02 ~]#vim /etc/apt/sources.list.d/kubernetes.list.list deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb/ / [root@master02 ~]#apt update #升级控制平面节点 # 设定指定的版本号 [root@master02 ~]#apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.31.4-1.1' && \ sudo apt-mark hold kubeadm #验证下载操作正常,并且 kubeadm 版本正确 [root@master02 ~]#kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"32", GitVersion:"v1.32.0" #验证升级计划,看看有没有问题 (不执行也没事) [root@master02 ~]#kubeadm upgrade plan #升级,执行真正的更新操作(和第一个节点命令不同) 要下镜像,等一会 [root@master02 ~]#kubeadm upgrade node #腾空节点(将节点标记为不可调度并驱逐所有负载,准备节点的维护) 调度器会把被驱逐的节点转移到其他节点上 [root@master01 ~]#kubectl drain master02 --ignore-daemonsets #升级 kubelet 和 kubectl (修改下面命令的版本号) [root@master02 ~]#apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.31.4-1.1' kubectl='1.31.4-1.1' && \ sudo apt-mark hold kubelet kubectl #重启 kubelet [root@master02 ~]#systemctl daemon-reload [root@master02 ~]#systemctl restart kubelet #解除节点的保护(通过将节点标记为可调度,让其重新上线) [root@master02 ~]#kubectl uncordon master02 --------------------------------------------------#master02和master03都执行上面操作 #升级工作节点(这里就演示一个,node02,node03相同操作) #更改软件包仓库,修改要升级的版本v1.31 [root@node01 ~]#vim /etc/apt/sources.list.d/kubernetes.list.list deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/deb/ / # 升级 kubeadm [root@node01 ~]#apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.31.4-1.1' && \ sudo apt-mark hold kubeadm #执行 "kubeadm upgrade" (对于工作节点,下面的命令会升级本地的 kubelet 配置) [root@node01 ~]#kubeadm upgrade node #腾空节点(将节点标记为不可调度并驱逐所有负载,准备节点的维护) [root@master02 ~]#kubectl drain node01 --ignore-daemonsets #升级 kubelet 和 kubectl (修改下面命令的版本号) [root@node01 ~]#apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.31.4-1.1' kubectl='1.31.4-1.1' && \ sudo apt-mark hold kubelet kubectl #重启 kubelet [root@node01 ~]#systemctl daemon-reload [root@node01 ~]#systemctl restart kubelet #取消对节点的保护(通过将节点标记为可调度,让节点重新上线) [root@master02 ~]#kubectl uncordon node01 #注意:这里演示的升级,没有提前做备份,可以先基于Velero做备份


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
2020-12-16 MongoDB3 mongoengine(基本使用, 联合唯一, ReferenceField, EmbeddedDocument, 时间段查询)