Prometheus02 Prometheus标签管理和告警, 定制Exporter
3.4 定制 Exporter
3.4.1 定制 Exporter 说明
开发应用服务的时候,就需要根据metric的数据格式,定制标准的/metric接口。 #各种语言帮助手册: https://github.com/prometheus/client_golang https://github.com/prometheus/client_python https://github.com/prometheus/client_java https://github.com/prometheus/client_rust
以python项目,可以借助于prometheus_client模块在python类型的web项目中定制metric接口。
#官方提供案例: https://prometheus.github.io/client_python/instrumenting/exemplars/ Three Step Demo One: Install the client: pip install prometheus-client Two: Paste the following into a Python interpreter: from prometheus_client import start_http_server, Summary import random import time # Create a metric to track time spent and requests made. REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request') # Decorate function with metric. @REQUEST_TIME.time() def process_request(t): """A dummy function that takes some time.""" time.sleep(t) if __name__ == '__main__': # Start up the server to expose the metrics. start_http_server(8000) # Generate some requests. while True: process_request(random.random()) Three: Visit http://localhost:8000/ to view the metrics.
3.4.2 定制 Exporter 案例: Python 实现
3.4.2.1 准备 Python 开发 Web 环境
#apt安装python3 ~# apt update && apt install -y python3 #安装Python包管理器,默认没有安装 ~# apt update && apt install -y python3-pip #############################如何不安装虚拟环境下面不需要执行################################# #安装虚拟环境软件 ~# pip3 install pbr virtualenv ~# pip3 install --no-deps stevedore virtualenvwrapper #创建用户 ~# useradd -m -s /bin/bash python #准备目录 ~# mkdir -p /data/venv ~# chown python.python /data/venv #修改配置文件(可选) ~# su - python ~# vim .bashrc force_color_prompt=yes #取消此行注释,清加颜色显示 #配置加速 ~# mkdir ~/.pip ~# vim .pip/pip.conf [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host=pypi.douban.com #配置虚拟软件 echo 'export WORKON_HOME=/data/venv' >> .bashrc echo 'export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3' >> .bashrc echo 'export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/bin/virtualenv' >> .bashrc echo 'source /usr/local/bin/virtualenvwrapper.sh' >> .bashrc source .bashrc #注意:virtualenv 和 virtualenvwrapper.sh 的路径位置 #创建新的虚拟环境并自动进入 ~# mkvirtualenv -p python3 flask_env #进入已创建的虚拟环境 ~# su - python ~# workon flask_env #虚拟环境中安装相关模块库 ~# pip install flask prometheus_client ~# pip list #################################如何不安装虚拟环境上面不需要执行########################## #实际环境中安装相关模块库 ~# pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple ~# cat /root/.config/pip/pip.conf [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple ~# pip3 install flask prometheus_client ~# pip3 list #创建代码目录 ~# mkdir -p /data/code
代码说明
from prometheus_client import Counter, Gauge, Summary from prometheus_client.core import CollectorRegistry class Monitor: def __init__(self): # 注册收集器 self.collector_registry = CollectorRegistry(auto_describe=False) # summary类型监控项设计 self.summary_metric_name = Summary(name="summary_metric_name", documentation="summary_metric_desc", labelnames=("label1", "label2", "label3"), registry=self.collector_registry) # gauge类型监控项设计 self.gauge_metric_name = Gauge(name="gauge_metric_name", documentation="summary_gauge_desc", labelnames=("method", "code", "uri"), registry=self.collector_registry) # counter类型监控项设计 self.counter_metric_name = Counter(name="counter_metric_name", documentation="summary_counter_desc", labelnames=("method", "code", "uri"), registry=self.collector_registry) #属性解析:上面是几个常用的标准metric数据格式设计,
范例: 定制 flask web 项目
]# su - python ]# workon flask_env ]# cat ~/code/flask_metric.py #!/usr/bin/python3 from prometheus_client import start_http_server,Counter, Summary from flask import Flask, jsonify from wsgiref.simple_server import make_server import time app = Flask(__name__) # Create a metric to track time spent and requests made REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request') COUNTER_TIME = Counter("request_count", "Total request count of the host") @app.route("/metrics") @REQUEST_TIME.time() def requests_count(): COUNTER_TIME.inc() return jsonify({"return": "success OK!"}) if __name__ == "__main__": start_http_server(8000) httpd = make_server( '0.0.0.0', 8001, app ) httpd.serve_forever() #代码解析: .inc() 表示递增值为 1 start_http_server(8000) #用于提供数据收集的端口 Prometheus可以通过此端口8000的/metrics 收集指标 make_server( '0.0.0.0', 8001, app ) #表示另开启一个web服务的/metrics 链接专门用于接收访问请求并生成对应的指标数据 #启动项目: ]# python flask_meric.py #浏览器访问 10.0.0.151:8000/metrics 可以看到大量的监控项,下面的几项就是自己定制的 ... # HELP request_processing_seconds Time spent processing request # TYPE request_processing_seconds summary request_processing_seconds_count 0.0 request_processing_seconds_sum 0.0 # TYPE request_processing_seconds_created gauge request_processing_seconds_created 1.5851566329768722e+09 # HELP request_count_total Total request count of the host # TYPE request_count_total counter request_count_total 0.0 #指标名因Counter类型自动加上total了 # TYPE request_count_created gauge request_count_created 1.5851566329769313e+09
#如果希望持续性的进行接口访问的话,我们可以编写一个脚本来实现: # cat curl_metrics.sh #!/bin/bash # 获取随机数 while true;do sleep_num=$(($RANDOM%3+1)) curl_num=$(($RANDOM%50+1)) for c_num in `seq $curl_num` do curl -s http://10.0.0.101:8001/metrics >>/dev/null 2>&1 done sleep $sleep_num done
修改prometheus配置, 增加job任务
]# vim /usr/local/prometheus/conf/prometheus.yml ... - job_name: 'my_metric' static_configs: - targets: ["127.0.0.1:8000"] [root@prometheus ~]#systemctl reload prometheus.service
基于Golang实现
#先安装go环境 go version go1.18.1 linux/amd64 [root@ubuntu2204 ~]#apt update && apt -y install golang [root@ubuntu2204 ~]#go version #准备代码,利用SDK实现 [root@ubuntu2204 ~]#cat code/main.go package main import ( "net/http" "github.com/prometheus/client_golang/prometheus/promhttp" ) func main() { // Serve the default Prometheus metrics registry over HTTP on /metrics. http.Handle("/metrics", promhttp.Handler()) http.ListenAndServe(":9527", nil) } #设置环境变量,Windows使用SET命令设置 [root@prometheus code]#export CGO_ENABLED=0 [root@prometheus code]#export GOARCH=amd64 [root@prometheus code]#export GOOS=linux [root@prometheus code]#go mod init my_metric go: creating new go.mod: module my_metric go: to add module requirements and sums: go mod tidy [root@prometheus code]#ls go.mod main.go [root@prometheus code]#cat go.mod module my_metric go 1.18 #加速 [root@prometheus code]#go env -w GOPROXY=https://goproxy.cn,direct #安装依赖 [root@prometheus code]#go get github.com/prometheus/client_golang/prometheus/promhttp #编译 [root@prometheus code]#go build -o exporter_demo [root@prometheus code]#ldd exporter_go_demo 不是动态可执行文件 #运行 [root@prometheus code]#./exporter_demo [root@ubuntu2204 ~]##curl http://127.0.0.1:9527/metrics # HELP go_gc_cycles_automatic_gc_cycles_total Count of completed GC cycles generated by the Go runtime. # TYPE go_gc_cycles_automatic_gc_cycles_total counter go_gc_cycles_automatic_gc_cycles_total 0 # HELP go_gc_cycles_forced_gc_cycles_total Count of completed GC cycles forced by the application. # TYPE go_gc_cycles_forced_gc_cycles_total counter go_gc_cycles_forced_gc_cycles_total 0 # HELP go_gc_cycles_total_gc_cycles_total Count of all completed GC cycles. # TYPE go_gc_cycles_total_gc_cycles_total counter go_gc_cycles_total_gc_cycles_total 0 # HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
左侧dashboards下new创建新的dashboard,点击Add visualization,选择Prometheus作为数据源
metric输入request_count_total,点击旁边Run queries出现图形,右上角可以更换图形
4.2 指标的生命周期
标签主要有两种表现形式: 1.私有标签 私有标签以"__*"样式存在,用于获取监控目标的默认元数据属性,比如__address__用于获取目标的 地址,__scheme__用户获取目标的请求协议方法,__metrics_path__获取请求的url地址等 2.普通标签 对个监控主机节点上的监控指标进行各种灵活的管理操作,常见的操作有,删除不必要|敏感指标,添 加、编辑或者修改指标的标签值或者标签格式。
Prometheus对数据的处理流程:

4.3 relabel_configs 和 metric_relabel_configs
4.4 标签管理
relabel_config、metric_relabel_configs 的使用格式基本上一致
[root@prometheus ~]#vim /usr/local/prometheus/conf/prometheus.yml #配置示例如下: scrape_configs: - job_name: 'prometheus' #针对job修改标签 relabel_configs|metric_relabel_configs: #2选1 - source_labels: [<labelname> [, ...]] separater: '<string> | default = ;' regex: '<regex> | default = (.*)' replacement: '<string> | default = $1' target_label: '<labelname>' action: '<relabel_action> | default = replace' #属性解析: action #对标签或指标进行管理,常见的动作有replace|keep|drop|labelmap|labeldrop等,默认为replace source_labels #指定正则表达式匹配成功的Label进行标签管理,此为列表 target_label #在进行标签替换的时候,可以将原来的source_labels替换为指定修改后的label separator #指定用于联接多个source_labels为一个字符串的分隔符,默认为分号 regex #表示source_labels对应Label的名称或者值(和action有关)进行匹配此处指定的正则表达式 replacement #替换标签时,将 target_label对应的值进行修改成此处的值 #action说明: #1)替换标签的值: replace #此为默认值,首先将source labels中指定的各标签的值使用separator指定的字符进行串连,如果串连后的值和regex匹配,
则使用replacement指定正则表达式模式或值对target_label字段进行赋值,如果target_label不存在,也可以用于创建新的标签名为target_label hashmod #将target_label的值设置为一个hash值,该hash是由modules字段指定的hash模块算法对source_labels上各标签的串连值进行hash计算生成 #2)保留或删除指标: 该处的每个指标名称对应一个target或metric keep #如果获取指标的source_labels的各标签的值串连后的值与regex匹配时,则保留该指标,反之则删除该指标 drop #如果获取指标的source_labels的各标签的值串连后的值与regex匹配时,则删除该指标,反之则保留该指标,即与keep相反 #3)创建或删除标签 labeldrop #如果source labels中指定的标签名称和regex相匹配,则删除此标签,相当于标签黑名单 labelkeep #如果source labels中指定的标签名称和regex相匹配,则保留,不匹配则删除此标签,相当于标签白名单 labelmap #一般用于生成新标签,将regex对source labels中指定的标签名称进行匹配,而后将匹配到的标签的值赋值给replacement字段指定的标签;
通常用于取出匹配的标签名的一部分生成新标签,旧的标签仍会存在 #4)大小写转换 lowercase #将串联的 source_labels 映射为其对应的小写字母 uppercase #将串联的 source_labels 映射到其对应的大写字母 #范例: #删除示例 metric_relabel_configs: - source_labels: [__name__] #指标名本身 regex: 'node_network_receive.*' action: drop #替换示例 metric_relabel_configs: - source_labels: [id] #原标签名为id regex: '/.*' #如果标签值符合正则表达式 /.*(以/开头) replacement: '123456' #那么值改为 123456 target_label: replace_id #那么把标签名改为replace_id
范例: 基于Target上已存在的标签名称进行匹配生成新标签,然后进行删除旧标签
[root@prometheus ~]#vim /usr/local/prometheus/conf/prometheus.yml #后面追加 - job_name: 'k8s-node' static_configs: - targets: ['10.0.0.151:9100','10.0.0.152:9100','10.0.0.153:9100'] labels: {app: 'k8s-node'} #添加新的label relabel_configs: - source_labels: - __scheme__ - __address__ - __metrics_path__ regex: "(http|https)(.*)" #进行分组,$1,$2 separator: "" target_label: "endpoint" #新标签 replacement: "${1}://${2}" #新标签的值 action: replace #replace把源列表通过separator连接成字符串,正则匹配的值进行替换 - regex: "(job|app)" #加下面三行,没写source就是所有名称为job或app的标签修改其标签名称加后缀_name,但旧的标签还存在 replacement: ${1}_name action: labelmap - regex: "(job|app)" #加下面两行,则删除所有名称为job或app的旧标签,注意上面修改和此删除的前后顺序 action: labeldrop - source_labels: [endpoint] #把endpoint标签换成myendpoint target_label: myendpoint [root@prometheus ~]#systemctl reload prometheus.service
范例: 用于在相应的job上,删除发现的各target之上面以"go"为前名称前缀的指标 (修改指标标签)
[root@prometheus ~]#vim /usr/local/prometheus/conf/prometheus.yml - job_name: 'k8s-node' ... #和上面内容相同 #后面追加 metric_relabel_configs: #修改/metrics下的指标标签 - source_labels: - __name__ regex: 'go.*' #删除go开头的指标 action: drop [root@prometheus ~]#systemctl reload prometheus.service
范例:kubernetes 发现 endpoint 重新打签
#https://github.com/prometheus/prometheus/blob/main/documentation/examples/prometheus-kubernetes.yml # Scrape config for service endpoints. # # The relabeling allows the actual service scrape endpoint to be configured # via the following annotations: # # * `prometheus.io/scrape`: Only scrape services that have a value of `true` # * `prometheus.io/scheme`: If the metrics endpoint is secured then you will need # to set this to `https` & most likely set the `tls_config` of the scrape config. # * `prometheus.io/path`: If the metrics path is not `/metrics` override this. # * `prometheus.io/port`: If the metrics are exposed on a different port to the # service then set this appropriately. - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) #replacement 默认值为$1 - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
prometheus支持两种类型的规则: 记录规则, 警报规则
5.1 记录规则
5.1.1 规则简介
记录规则就相当于是PromQL的一种别名
5.1.2 记录规则说明
除了别名,还会把之前算的结果保存下来,下次直接使用
5.1.3 记录规则案例
5.1.3 2 记录规则实现
#范例:#创建规则记录文件 # mkdir /usr/local/prometheus/rules #文件夹建不建无所谓 # vim /usr/local/prometheus/rules/prometheus_record_rules.yml #存放多个记录规则 groups: - name: myrules #记录规则名 rules: #记录规则 - record: "request_process_per_time" #表达式的别名 expr: request_processing_seconds_sum{job="my_metric"} / request_processing_seconds_count{job="my_metric"} #原始表达式 labels: app: "flask" role: "web" - record: "request_count_per_minute" #另一个规则 expr: increase(request_count_total{job="my_metric"}[1m]) #最后一个减去第一个算出的差值 labels: app: "flask" role: "web" #编辑prometheus配置文件(Prometheus需要加载记录规则文件,才能知道) ]# vim /usr/local/prometheus/conf/prometheus.yml ... rule_files: - "../rules/*.yml" #加此一行,如果是相对路径,是相对于prometheus.yml的路径 # - "first_rules.yml" ... #检查规则文件有效性 ]# promtool check config /usr/local/prometheus/conf/prometheus.yml #直接检查规则文件 ]# promtool check rules /usr/local/prometheus/rules/prometheus_record_rules.yml #重启服务,加载prometheus配置 ]#systemctl reload prometheus.servicebash #prometheus网页可以直接通过别名查结果了 #grafana也可以查该监控项,在监控项中metric输入request_process_per_time即可监控
#范例:系统相关指标的记录规则 vim /usr/local/prometheus/rules/prometheus_record_rules.yml groups: - name: custom_rules interval: 5s rules: - record: instance:node_cpu:avg_rate5m expr: 100 - avg(irate(node_cpu_seconds_total{job="node", mode="idle"}[5m])) by (instance) * 100 - record: instace:node_memory_MemFree_percent expr: 100 - (100 * node_memory_MemFree_bytes / node_memory_MemTotal_bytes) - record: instance:root:node_filesystem_free_percent expr: 100 * node_filesystem_free_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} vim /usr/local/prometheus/conf/prometheus.yml ... rule_files: - "../rules/*.yml" #加此一行,如果是相对路径,是相对于prometheus.yml的路径
5.2.1 告警介绍
官方提供配套Alertmanager实现告警,也可以选其他告警软件
5.2.2 告警组件
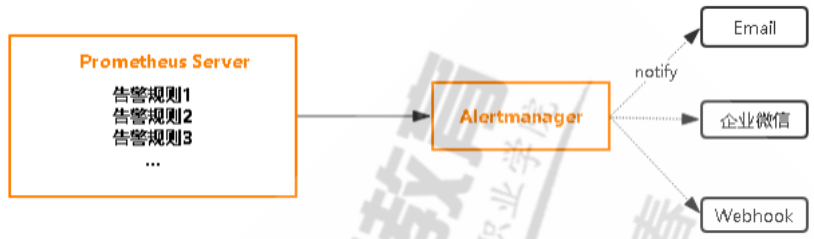
1.去重 将多个相同的告警,去掉重复的告警,只保留不同的告警 2.分组 Grouping 分组机制可以将相似的告警信息合并成一个通知。 3.抑制 Inhibition 系统中某个组件或服务故障,那些依赖于该组件或服务的其它组件或服务可能也会因此而触发告 警,抑制便是避免类似的级联告警的一种特性 4.静默 Silent 静默提供了一个简单的机制可以快速根据标签在一定的时间对告警进行静默处理。 5.路由 Route 将不同的告警定制策略路由发送至不同的目标,比如:不同的接收人或接收媒介
小公司和Prometheus装一台机器上,也可以分开装
5.2.4.1 二进制部署
#Alertmanager 下载链接 https://github.com/prometheus/alertmanager/releases #获取软件 ]# wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz #解压软件 ]# tar xf alertmanager-0.23.0.linux-amd64.tar.gz -C /usr/local/ ]# ln -s /usr/local/alertmanager-0.23.0.linux-amd64 /usr/local/alertmanager #准备工作 ]# cd /usr/local/alertmanager ]# mkdir {bin,conf,data} ]# mv alertmanager amtool bin/ ]# cp alertmanager.yml conf/ ]# useradd -r -s /sbin/nologin prometheus ]# chown -R prometheus.prometheus /usr/local/alertmanager/ #服务文件 ]# cat /usr/lib/systemd/system/alertmanager.service [Unit] Description=alertmanager project After=network.target [Service] Type=simple ExecStart=/usr/local/alertmanager/bin/alertmanager -- config.file=/usr/local/alertmanager/conf/alertmanager.yml -- storage.path=/usr/local/alertmanager/data --web.listen-address=0.0.0.0:9093 ExecReload=/bin/kill -HUP $MAINPID Restart=on-failure User=prometheus Group=prometheus [Install] WantedBy=multi-user.target #属性解析:最好配置 --web.listen-address ,因为默认的配置是:9093,有可能在启动时候报错 #启动服务 ]# systemctl daemon-reload ]# systemctl enable --now alertmanager.service ]# systemctl status alertmanager.service #查看AlertManager也会暴露指标 ]# curl http://10.0.0.151:9093/metrics/ #可以通过访问 http://10.0.0.151:9093/ 来看 alertmanager 提供的 Web 界面
#加入prometheus的监控 ]# vim /usr/local/prometheus/conf/prometheus.yml - job_name: 'alertmanager' static_configs: - targets: ['10.0.0.151:9093'] ]#systemctl reload prometheus.service
5.2.6 Alertmanager 配置文件
Alertmanager只负责告警,什么时候告警是Prometheus定的
#配置文件总共定义了五个模块,global、templates、route,receivers,inhibit_rules #templates:发通知信息的格式 #route:多个不同的收件人的信息 #receivers:接收者 #inhibit_rules:抑制规则,一个告警引发的其他告警就不发了
alertmanager配置文件语法检查命令
amtool check-config /usr/local/alertmanager/conf/alertmanager.yml
5.2.6.2.1 启用邮箱
邮箱服务器开启smtp的授权码,每个邮箱开启授权码操作不同
5.2.6.2.2 Alertmanager 实现邮件告警
范例: 实现邮件告警的配置文件
]# vim /usr/local/alertmanager/conf/alertmanager.yml # 全局配置 global: #基于全局块指定发件人信息 resolve_timeout: 5m #定义持续多长时间未接收到告警标记后,就将告警状态标记为resolved smtp_smarthost: 'smtp.qq.com:465' #指定SMTP服务器地址和端口 smtp_from: '29308620@qq.com' #定义了邮件发件的的地址 smtp_auth_username: '29308620@qq.com' smtp_auth_password: 'ongjeydfbfjjbfbe' smtp_hello: 'qq.com' smtp_require_tls: false #启用tls安全,默认true # 路由配置 route: group_by: ['alertname', 'cluster'] #用于定义分组 group_wait: 10s #同一组等待看还有没有其他告警,一起发 group_interval: 10s #一段时间内把相同通告警规则的实例合并到一个告警组,一起发 repeat_interval: 10s #多长时间发一次,不要过低,否则短期内会收到大量告警通知 receiver: 'email' #指定接收者名称(引用下面收件人信息) # 收信人员 receivers: - name: 'email' email_configs: - to: 'root@wangxiaochun.com' send_resolved: true #问题解决后也会发送恢复通知 #from: '29308620@qq.com' #除了前面的基于全局块实现发件人信息,也支持在此处配置发件人信息 #smarthost: 'smtp.qq.com:25或465' #auth_username: '29308620@qq.com' #auth_password: 'xxxxxxxxxxxxx' #require_tls: false #启用tls安全,默认true #headers: #定制邮件格式,可选 # subject: "{{ .Status | toUpper }} {{ .CommonLabels.env }}:{{ .CommonLabels.cluster }} {{ .CommonLabels.alertname }}" #html: '{{ template "email.default.html" . }}' #语法检查 ]#amtool check-config /usr/local/alertmanager/conf/alertmanager.yml ]#systemctl reload alertmanager.service
5.3.1 告警规则说明
PromQL语句,并且返回是bool值
告警规则和记录规则格式的区别, 告警规则是alert, 记录规则是record, 其他一样
#告警规则文件示例 groups: - name: example rules: - alert: HighRequestLatency #expr: up == 0 expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: warning project: myproject annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes." #属性解析: alert #定制告警的动作名称 expr #是一个布尔型的条件表达式,一般表示满足此条件时即为需要告警的异常状态 for #条件表达式被触发后,一直持续满足该条件长达此处时长后才会告警,即发现满足expr表达式后,在告警前的等待时长,
默认为0,此时间前为pending状态,之后为firing,此值应该大于抓取间隔时长,避免偶然性的故障 labels #指定告警规则的标签,若已添加,则每次告警都会覆盖前一次的标签值 labels.severity #自定义的告警级别的标签 annotations #自定义注释信息,注释信息中的变量需要从模板中或者系统中读取,最终体现在告警通知的信息中
范例: Node Exporter的告警规则
groups: - name: node-exporter rules: # Host out of memory - alert: HostOutOfMemory expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10 for: 2m labels: severity: warning annotations: summary: Host out of memory (instance {{ $labels.instance }}) description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host unusual network throughput in - alert: HostUnusualNetworkThroughputIn expr: sum by (instance) (rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: Host unusual network throughput in (instance {{ $labels.instance }}) description: "Host network interfaces are probably receiving too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host unusual network throughput out - alert: HostUnusualNetworkThroughputOut expr: sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: Host unusual network throughput out (instance {{ $labels.instance }}) description: "Host network interfaces are probably sending too much data (> 100 MB/s)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host out of disk space # Please add ignored mountpoints in node_exporter parameters like # "--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|run)($|/)". # Same rule using "node_filesystem_free_bytes" will fire when disk fills for non-root users. - alert: HostOutOfDiskSpace expr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0 for: 2m labels: severity: warning annotations: summary: Host out of disk space (instance {{ $labels.instance }}) description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host high CPU load - alert: HostHighCpuLoad expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80 for: 0m labels: severity: warning annotations: summary: Host high CPU load (instance {{ $labels.instance }}) description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host CPU high iowait - alert: HostCpuHighIowait expr: avg by (instance) (rate(node_cpu_seconds_total{mode="iowait"}[5m])) * 100 > 5 for: 0m labels: severity: warning annotations: summary: Host CPU high iowait (instance {{ $labels.instance }}) description: "CPU iowait > 5%. A high iowait means that you are disk or network bound.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host Network Interface Saturated - alert: HostNetworkInterfaceSaturated expr: (rate(node_network_receive_bytes_total{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"}[1m]) + rate(node_network_transmit_bytes_total{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"}[1m])) / node_network_speed_bytes{device!~"^tap.*|^vnet.*|^veth.*|^tun.*"} > 0.8 < 10000 for: 1m labels: severity: warning annotations: summary: Host Network Interface Saturated (instance {{ $labels.instance }}) description: "The network interface \"{{ $labels.device }}\" on \"{{ $labels.instance }}\" is getting overloaded.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}" # Host conntrack limit - alert: HostConntrackLimit expr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8 for: 5m labels: severity: warning annotations: summary: Host conntrack limit (instance {{ $labels.instance }}) description: "The number of conntrack is approaching limit\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
#准备告警rule文件 vim /usr/local/prometheus/rules/prometheus_alert_rules.yml groups: - name: flask_web rules: - alert: InstanceDown expr: up{job="my_metric"} == 0 #expr: up == 0 #所有targets for: 1m #持续1分钟是0就告警 labels: severity: 1 annotations: #告警信息说明 #title: Instance Down summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1m以上" #语法检查 ]#promtool check rules /usr/local/prometheus/rules/prometheus_alert_rules.yml #Prometheus载入该rule配置,配置alertmanager服务位置 [root@prometheus ~]#vim /usr/local/prometheus/conf/prometheus.yml global: scrape_interval: 15s. evaluation_interval: 15s #每15秒评估一次rule规则是否满足 #下面为配置内容 alerting: alertmanagers: - static_configs: - targets: - 10.0.0.151:9093 rule_files: - ../rules/*.yml #相对于prometheus.yml的路径 #对Prometheus做整体检查 ]#promtool check config /usr/local/prometheus/conf/prometheus.yml #生效 ]#systemctl reload prometheus.service #在Prometheus网页 http://10.0.0.151:9090下 status下的rules可以看到规则 #关闭python3运行的flask_metric.py服务,触发告警条件 #在alertmanager网页 http://10.0.0.151:9093/, alerts下能看到出发的告警 #在Prometheus网页,alerts栏下也能看到告警,firing已经发出去了 #收到邮件,内容为 [1] Firing Labels alertname = InstanceDown instance = 127.0.0.1:8000 job = my_metric severity = 1 Annotations description = 127.0.0.1:8000 job my_metric 已经停止1m以上 summary = Instance 127.0.0.1:8000 停止工作 #恢复服务后,网页上告警信息消失,收到恢复resolved的邮件
上面发的邮件消息不够好看,可以通过告警模板定制信息模板
5.4.1 告警模板说明
5.4.2.1 定制模板
#模板文件使用标准的Go语法,并暴露一些包含时间标签和值的变量 标签引用: {{ $labels.<label_name> }} 指标样本值引用: {{ $value }} #示例:若要在description注解中引用触发告警的时间序列上的instance和iob标签的值,可分别使用 {{$label.instance}}和{{$label.job}}
范例: 邮件告警通知模板
#建立邮件模板文件 mkdir /usr/local/alertmanager/tmpl #基于jin2的模板内容 vim /usr/local/alertmanager/tmpl/email.tmpl {{ define "test.html" }} <table border="1"> <tr> <th>报警项</th> <th>实例</th> <th>报警阀值</th> <th>开始时间</th> </tr> {{ range $i, $alert := .Alerts }} #循环 <tr> <td>{{ index $alert.Labels "alertname" }}</td> <td>{{ index $alert.Labels "instance" }}</td> <td>{{ index $alert.Annotations "value" }}</td> <td>{{ $alert.StartsAt }}</td> </tr> {{ end }} </table> {{ end }} #属性解析 {{ define "test.html" }} 表示定义了一个 test.html 模板文件,通过该名称在配置文件中应用 上边模板文件就是使用了大量的jinja2模板语言。 $alert.xxx 其实是从默认的告警信息中提取出来的重要信息
范例:邮件模板2
vim /usr/local/alertmanager/tmpl/email_template.tmpl {{ define "email.html" }} {{- if gt (len .Alerts.Firing) 0 -}} {{ range .Alerts }} =========start==========<br> 告警程序: prometheus_alert <br> 告警级别: {{ .Labels.severity }} <br> 告警类型: {{ .Labels.alertname }} <br> 告警主机: {{ .Labels.instance }} <br> 告警主题: {{ .Annotations.summary }} <br> 告警详情: {{ .Annotations.description }} <br> 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br> =========end==========<br> {{ end }}{{ end -}} {{- if gt (len .Alerts.Resolved) 0 -}} {{ range .Alerts }} =========start==========<br> 告警程序: prometheus_alert <br> 告警级别: {{ .Labels.severity }} <br> 告警类型: {{ .Labels.alertname }} <br> 告警主机: {{ .Labels.instance }} <br> 告警主题: {{ .Annotations.summary }} <br> 告警详情: {{ .Annotations.description }} <br> 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br> 恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br> =========end==========<br> {{ end }}{{ end -}} {{- end }} #说明 "2006-01-02 15:04:05"是一个特殊的日期时间格式化模式,在Golang中,日期和时间的格式化是通过指 定特定的模式来实现的。它用于表示日期和时间的具体格式
5.4.2.2 应用模板
#更改配置文件 ]# vim /usr/local/alertmanager/conf/alertmanager.yml global: ... templates: #加下面两行加载模板文件 - '../tmpl/*.tmpl' #相对路径是相对于altermanager.yml文件的路径 route: ... # 收信人员 receivers: - name: 'email' email_configs: - to: 'root@wangxiaochun.com' send_resolved: true headers: { Subject: "[WARN] 报警邮件"} #添加此行,定制邮件标题 html: '{{ template "test.html" . }}' #添加此行,调用模板名显示邮件正文 #html: '{{ template "email.html" . }}' #添加此行,调用模板显示邮件正文 #检查语法 [root@prometheus ~]#amtool check-config /usr/local/alertmanager/conf/alertmanager.yml [root@prometheus ~]#systemctl reload alertmanager.service
5.5.1 告警路由说明

注意: 新版中使用指令matchers替换了match和match_re指令
范例: 路由示例
route: group_by: ['alertname', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 10s receiver: 'email'
Alertmanager 的相关配置参数
#新版使用指令matchers替换match和match_re matchers: #下面是或的关系,两者满足其一即可 - alertname = Watchdog - severity =~ "warning|critical" #老版本 match: [ <labelname>: <labelvalue>, ... ] # 基于正则表达式验证,判断当前告警标签的值是否满足正则表达式的内容,满足则进行内部的后续处理 match_re: [ <labelname>: <regex>, ... ] routes: [ - <route> ... ]
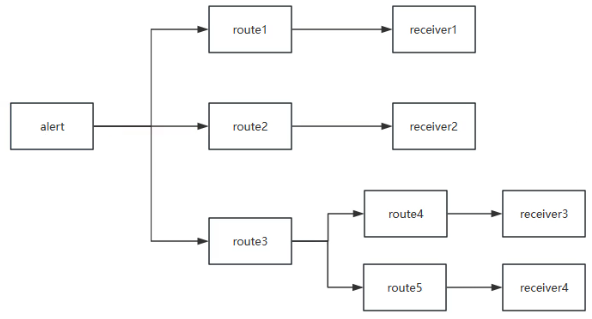
子路由如图
配置示例
#在alertmanager 定制路由 global: ... templates: ... route: group_by: ['instance'] ... receiver: email-receiver routes: - match: severity: critical receiver: leader-team - match_re: severity: ^(warning)$ #project: myproject receiver: ops-team receivers: - name: 'leader-team' email_configs: - to: '29308620@qq.com', 'admin@qq.com' - name: 'ops-team' email_configs: - to: 'root@wangxiaochun.com', 'wang@163.com'
定制的 metric 要求如下 1.如果是每分钟的QPS超过 500 的时候,将告警发给运维团队 2.如果是服务终止的话,发给管理团队 #定制告警规则 #配置告警规则 vim /usr/local/prometheus/rules/prometheus_alert_route.yml groups: - name: flask_web rules: - alert: InstanceDown expr: up{job="my_metric"} == 0 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1分钟以上" value: "{{$value}}" - name: flask_QPS rules: - alert: InstanceQPSIsHight expr: increase(request_count_total{job="my_metric"}[1m]) > 500 #增长值 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} QPS 持续过高" description: "{{ $labels.instance }} job {{ $labels.job }} QPS 持续过高" value: "{{$value}}" #根据标签的值将来可以做路由判断 #指定flask_web规则的labels为 severity: critical #指定flask_QPS规则的labels为 severity: warning #清理下/usr/local/prometheus/rules/下的yml文件,以防之前的干扰 #重启prometheus服务(不会加载新的yml,要重新加载下) systemctl reload prometheus.service
5.5.2.2 定制路由分组
#指定路由分组 vim /usr/local/alertmanager/conf/alertmanager.yml ... # 路由配置 #新版使用指令matchers替换match和match_re,如下示例 route: group_by: ['instance', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 10s receiver: 'email' routes: - receiver: 'leader-team' matchers: - severity = "critical" - receiver: 'ops-team' matchers: - severity =~ "^(warning)$" #子路由 #- matchers # - severity = "critical" # - job =~ "mysql|java" # receiver: 'leader-team' # routes: #支持routes嵌套和分级 # - matchers: # - job =~ "mysql" # receiver: 'dba-team' #- matchers # - severity =~ "warning" # - job = "node_exporter" # receiver: 'ops-team' #旧版:使用match和match_re #route: # group_by: ['instance', 'cluster'] # group_wait: 10s # group_interval: 10s # repeat_interval: 10s # receiver: 'email' # routes: # - match: # severity: critical # receiver: 'leader-team' # - match_re: # severity: ^(warning)$ # receiver: 'ops-team' # 收信人员 receivers: - name: 'email' email_configs: - to: 'root@wangxiaochun.com' send_resolved: true html: '{{ template "test.html" . }}' headers: { Subject: "[WARN] 报警邮件"} - name: 'leader-team' email_configs: - to: 'root@wangxiaochun.com' html: '{{ template "email.html" . }}' headers: { Subject: "[CRITICAL] 应用服务报警邮件"} send_resolved: true # - name: 'ops-team' email_configs: - to: 'root@wangxiaochun.com' html: '{{ template "test.html" . }}' headers: { Subject: "[WARNNING] QPS负载报警邮件"} send_resolved: true #检查语法 amtool check-config /usr/local/alertmanager/conf/alertmanager.yml #服务生效 systemctl reload alertmanager.service
5.6 告警抑制
5.6.1 告警抑制说明
对于一种业务场景,有相互依赖的两种服务:A服务和B服务,一旦A服务异常,依赖A服务的B服务也会 异常,从而导致本来没有问题的B服务也不断的发出告警。 告警抑制,B服务就不进行告警了
配置解析
#源告警信息匹配 -- 报警的来源 source_match: [ <labelname>: <labelvalue>, ... ] source_match_re: [ <labelname>: <regex>, ... ] #目标告警信息匹配 - 触发的其他告警 target_match: [ <labelname>: <labelvalue>, ... ] target_match_re: [ <labelname>: <regex>, ... ] #目标告警是否是被触发的 - 要保证业务是同一处来源 [ equal: '[' <labelname>, ... ']' ] #同时告警目标上的标签与之前的告警标签一样,那么就不再告警 #配置示例 #例如: 集群中的A主机节点异常导致NodeDown告警被触发,该告警会触发一个severity=critical的告警级别。 由于A主机异常导致该主机上相关的服务,会因为不可用而触发关联告警。 根据抑制规则的定义: 如果有新的告警级别为severity=critical,且告警中标签的node值与NodeDown告警的相同 则说明新的告警是由NodeDown导致的,则启动抑制机制,从而停止向接收器发送通知。 inhibit_rules: # 抑制规则 - source_match: # 源标签警报触发时会抑制含有目标标签的警报 alertname: NodeDown # 可以针对某一个特定的告警动作规则 severity: critical # 限定源告警规则的等级 target_match: # 定制要被抑制的告警规则的所处位置 severity: normal # 触发告警目标标签值的正则匹配规则,可以是正则表达式如: ".*MySQL.*" equal: # 因为源告警和触发告警必须处于同一业务环境下,确保他们在同一个业务中 - instance # 源告警和触发告警存在于相同的 instance 时,触发告警才会被抑制。 # 格式二 equal: ['alertname','operations', 'instance'] #表达式 up{node="node01.wang.org",...} == 0 severity: critical #触发告警 ALERT{node="node01.wang.org",...,severity=critical}
案例说明 对于当前的flask应用的监控来说,上面做了两个监控指标: 1.告警级别为 critical 的 服务异常终止 2.告警级别为 warning 的 QPS访问量突然降低为0,这里以服务状态来模拟 当python服务异常终止的时候,不要触发同节点上的 QPS 过低告警动作。 #准备告警规则 vim /usr/local/prometheus/rules/prometheus_alert_inhibit.yml groups: - name: flask_web rules: - alert: InstanceDown expr: up{job="my_metric"} == 0 for: 1m labels: severity: critical annotations: summary: "Instance {{ $labels.instance }} 停止工作" description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止1分钟以上" value: "{{$value}}" - name: flask_QPS rules: - alert: InstanceQPSIsHight expr: increase(request_count_total{job="my_metric"}[1m]) > 500 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} QPS 持续过高" description: "{{ $labels.instance }} job {{ $labels.job }} QPS 持续过高" value: "{{$value}}" - alert: InstanceQPSIsLow #判断是否QPS访问为0 expr: up{job="my_metric"} == 0 for: 1m labels: severity: warning annotations: summary: "Instance {{ $labels.instance }} QPS 异常为零" description: "{{ $labels.instance }} job {{ $labels.job }} QPS 异常为0" value: "{{$value}}" #告警路由同上,不做修改 vim /usr/local/alertmanager/conf/alertmanager.yml ... ]#systemctl reload prometheus.service
5.6.2.3 启动抑制机制
#定制抑制 vim /usr/local/alertmanager/conf/alertmanager.yml ...(同上) # 抑制措施 #上面不变,添加下面告警抑制配置 inhibit_rules: #critical一旦发生,不再告警warning - source_match: severity: critical target_match: severity: warning equal: #要求发生在同一个主机时 - instance #alertmanager服务重新加载配置 systemctl reload alertmanager.service #把python的flask应用关闭,只会收到critical的邮件,warning的没有收到
5.7.2.1 企业微信配置
5.7.2.1.1 注册企业微信
#浏览器访问下面链接,注册企业微信 https://work.weixin.qq.com/ #点击我的企业,可查看企业ID #应用管理创建Prometheus告警应用,需要独立ip,记录agentId和Secret
5.7.2.2.1 获取 Token
token相当于登录凭证,下次带token来发送消息
#获取通信token格式: curl -H "Content-Type: application/json" -d '{"corpid":"企业id", "corpsecret": "应用secret"}' https://qyapi.weixin.qq.com/cgi-bin/gettoken #范例: 获取 Token #示例: [root@prometheus ~]#curl -H "Content-Type: application/json" -d '{"corpid":"ww644a0d95807e476b", "corpsecret": "ycCDLnp0XfVq-3A6ZwS55mUiskTz5sYqiEScR_Z_Frw"}' https://qyapi.weixin.qq.com/cgi-bin/gettoken #返回token {"errcode":0,"errmsg":"ok","access_token":"NMaWPA8xfYmcN5v8so7TdqsBwym78Vs53X5Os Oy69-Q6Kv3GGXGU_V-8keGaArYkurIXrKMJGrdFbhYy-QqmKsr5x61-wv6yXZy0kiooXE-QfbDoNRumBSjiJg0AqkEOeBqaT1dc8_DryE-RGVD39J4Iu61TU3HWsyZVkGuRTU6ejM-qauflSOuy5cbDSONNXi9zUPwUmlg4XkAobrLgOw","expires_in":7200
5.7.2.2.2 命令发送测试信息
带上返回的token发送消息
#发送信息信息要求Json格式如下: Data = { "toparty": 部门id, "msgtype": "text", "agentid": Agentid, "text": {"content": "消息内容主题"}, "safe": "0" } #格式: curl -H "Content-Type: application/json" -d '{"toparty": "部门id", "msgtype":"text","agentid": "agentid", "text":{"content":"告警内容"}, "safe": "安全级别"}' https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token="企业微信token" #范例: #利用上面的token发送信息,注意:token有时间期限 [root@prometheus ~]#curl -H "Content-Type: application/json" -d '{"toparty": "2", "msgtype":"text","agentid": "1000004", "text":{"content":"PromAlert - prometheus 告警测试"}, "safe": "0"}' https://qyapi.weixin.qq.com/cgi-bin/message/sendaccess_token="NMaWPA8xfYmcN5v8so7TdqsBwym78Vs53X5OsOy69-Q6Kv3GGXGU_V-8keGaArYkurIXrKMJGrdFbhYy-QqmKsr5x61-wv6yXZy0kiooXE-QfbDoNRumBSjiJg0AqkEOeBqaT1dc8_DryE-RGVD39J4Iu61TU3HWsyZVkGuRTU6ejM-qauflSOuy5cbDSONNXi9zUPwUmlg4XkAobrLgOw" #返回成功提示 {"errcode":0,"errmsg":"ok","msgid":"WpLDpQFMGSE843kRbNhgXZcjYGgCPvKRM-uwZsq6dxIpvGVtDq3CVY9BHuCX6fJZxQe0cQ_XbSpKMYUyJtLCgg"} #此时企业微信里创建的Prometheus告警应用会发出该消息
5.7.2.3.1 定制告警的配置信息
[root@prometheus ~]#vim /usr/local/alertmanager/conf/alertmanager.yml # 全局配置 global: .. #必须项 wechat_api_corp_id: 'ww644a0d95807e476b' #公司id #此处的微信信息可省略,下面wechat_configs 也提供了相关信息 wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' #微信地址 wechat_api_secret: 'qYgLlipdHtZidsd8qAZaTKKkGkzIyWxuQSeQOk9Si0M' #secret # 模板配置 templates: - '../tmpl/*.tmpl' # 路由配置 route: group_by: ['instance', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 10s receiver: 'wechat' # 收信人员 receivers: ... #原来邮件联系人不动 #在下面添加微信配置文件 - name: 'wechat' wechat_configs: - to_party: '2' to_user: '@all' #支持给企业内所有人发送 agent_id: '1000004' #应用id #api_secret: 'qYgLlipdHtZidsd8qAZaTKKkGkzIyWxuQSeQOk9Si0M' #全局写过了 send_resolved: true message: '{{ template "wechat.default.message" . }}' #下面有模板 #重载alertmanager服务 systemctl reload alertmanager
5.7.2.3.2 定制告警的模板配置信息
# vim /usr/local/alertmanager/tmpl/wechat.tmpl {{ define "wechat.default.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} ========= 监控报警 ========= 告警状态:{{ .Status }} 告警级别:{{ .Labels.severity }} 告警类型:{{ $alert.Labels.alertname }} 故障主机: {{ $alert.Labels.instance }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 触发阀值:{{ .Annotations.value }} 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} #注意: 此为golang的时间Format,表示123456 ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} ========= 异常恢复 ========= 告警类型:{{ .Labels.alertname }} 告警状态:{{ .Status }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} 恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} {{- if gt (len $alert.Labels.instance) 0 }} 实例信息: {{ $alert.Labels.instance }} {{- end }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- end }} #重载alertmanager服务 systemctl reload alertmanager
Prometheus 不直接支持钉钉告警, 但对于prometheus来说,它所支持的告警机制非常多,尤其还支持 通过webhook,从而可以实现市面上大部分的实时动态的告警平台。 Alertmanager 的 webhook 集成了钉钉报警,钉钉机器人对文件格式有严格要求,所以必须通过特定的 格式转换,才能发送给钉钉的机器人。 在这里使用开源工具 prometheus-webhook-dingtalk 来进行prometheus和dingtalk的环境集成。 Github链接 https://github.com/timonwong/prometheus-webhook-dingtalk

工作原理 群机器人是钉钉群的高级扩展功能,通过选择机器人,并对通知群进行设置,就可以自动将机器人消息 自动推送到钉钉群中,特别的高级智能化,由于机器人是将消息推送到群,需要预先建立好一个群实现 为了完成钉钉的告警实践,遵循以下的步骤 1.配置 PC 端钉钉机器人 2.测试钉钉环境
5.8.1.1 安装钉钉和创建企业
因为手机端无法进行添加机器人的相关操作,所以需要提前在电脑上下载安装钉钉的 PC 版本
5.8.1.2 创建钉钉的告警群
点击右上角的"+", 选择"发起群聊"
创建项目群或者管理群等类型中的一种,我们这里选择创建项目群
5.8.1.3 告警群中添加和配置机器人
群设置 --- 智能群助手 --- 添加机器人 --- 自定义通过webhook接入自定义服务 创建机器人后,定制特有的关键字信息,便于后续接收信息 指定机器人名字并设置安全设置 #带关键字才能发消息,带加签(密码才能发消息),当然可以设置只需要其中任意一个,也可以都不要,只是安全考虑 #注意:一定要记住分配的webhook地址: https://oapi.dingtalk.com/robot/send?access_token=60bc0c10b1cd38319cee7dab03a4e986781b1e9e1e10c847ef7d633a9d567a33 记住告警的错误关键字:PromAlert
5.8.2.1 prometheus-webhook-dingtalk 软件部署
范例:二进制安装
#下载软件 wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.0.0/prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz #解压文件 tar xf prometheus-webhook-dingtalk-2.0.0.linux-amd64.tar.gz -C /usr/local/ ln -s /usr/local/prometheus-webhook-dingtalk-2.0.0.linux-amd64/ /usr/local/dingtalk #准备文件和目录 cd /usr/local/dingtalk mkdir bin conf mv prometheus-webhook-dingtalk bin/ cp config.example.yml conf/config.yml #编辑 config.yml 相关信息 vim /usr/local/dingtalk/conf/config.yml targets: webhook1: url: https://oapi.dingtalk.com/robot/send?access_token=60bc0c10b1cd38319cee7dab03a4e986781b1e9e1e10c847ef7d633a9d567a33 # secret for signature 加签 secret: SEC2233b6ab300289ea5ede5b1a859d01bc7ea8a0ee3eaa1145b15b38b12dbd5558 #查看命令帮助 /usr/local/dingtalk/bin/prometheus-webhook-dingtalk --help #尝试命令启动后,测试效果(未来写成service文件) /usr/local/dingtalk/bin/prometheus-webhook-dingtalk --config.file=/usr/local/dingtalk/conf/config.yml --web.listen-address=0.0.0.0:8060
5.8.2.2 Alertmanager 配置
# vim /usr/local/alertmanager/conf/alertmanager.yml global: ... # 模板配置 templates: - '../tmpl/*.tmpl' # 路由配置,添加下面内容 route: group_by: ['alertname', 'cluster'] group_wait: 10s group_interval: 10s repeat_interval: 10s receiver: 'dingtalk' # 收信人员 receivers: - name: 'dingtalk' webhook_configs: - url: 'http://10.0.0.100:8060/dingtalk/webhook1/send' send_resolved: true [root@prometheus ~]#systemctl reload alertmanager.service #如果设置了关键字,可以在prometheus的告警规则 /usr/local/prometheus/rules/下的yml里 #rules下annotations下的summary里加入关键字 (只要里面包含该关键字就行)
5.8.2.3.3 配置告警模板
#创建告警模板 vim /usr/local/dingtalk/contrib/templates/dingtalk.tmpl {{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " "}} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }} {{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }} {{ define "__text_alert_list" }}{{ range . }} **Labels** {{ range .Labels.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **Annotations** {{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }} **Source:** [{{ .GeneratorURL }}]({{ .GeneratorURL }}) {{ end }}{{ end }} {{ define "___text_alert_list" }}{{ range . }} --- **告警主题:** {{ .Labels.alertname | upper }} **告警级别:** {{ .Labels.severity | upper }} **触发时间:** {{ dateInZone "2006-01-02 15:04:05" (.StartsAt) "Asia/Shanghai" }} **事件信息:** {{ range .Annotations.SortedPairs }} {{ .Value | markdown | html }} {{ end }} **事件标签:** {{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }}{{ end }} {{ end }} {{ end }} {{ define "___text_alertresovle_list" }}{{ range . }} --- **告警主题:** {{ .Labels.alertname | upper }} **告警级别:** {{ .Labels.severity | upper }} **触发时间:** {{ dateInZone "2006-01-02 15:04:05" (.StartsAt) "Asia/Shanghai" }} **结束时间:** {{ dateInZone "2006-01-02 15:04:05" (.EndsAt) "Asia/Shanghai" }} **事件信息:** {{ range .Annotations.SortedPairs }} {{ .Value | markdown | html }} {{ end }} **事件标签:** {{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }} {{ end }}{{ end }} {{ end }} {{ end }} {{/* Default */}} {{ define "_default.title" }}{{ template "__subject" . }}{{ end }} {{ define "_default.content" }} [{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})** {{ if gt (len .Alerts.Firing) 0 -}}  **========PromAlert 告警触发========** {{ template "___text_alert_list" .Alerts.Firing }} {{- end }} {{ if gt (len .Alerts.Resolved) 0 -}}  **========PromAlert 告警恢复========** {{ template "___text_alertresovle_list" .Alerts.Resolved }} {{- end }} {{- end }} {{/* Legacy */}} {{ define "legacy.title" }}{{ template "__subject" . }}{{ end }} {{ define "legacy.content" }} [{{ .Status | toUpper }}{{ if eq .Status "firing"}}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}] ({{ template "__alertmanagerURL" . }})** {{ template "__text_alert_list" .Alerts.Firing }} {{- end }} {{/* Following names for compatibility */}} {{ define "_ding.link.title" }}{{ template "_default.title" . }}{{ end }} {{ define "_ding.link.content" }}{{ template "_default.content" . }}{{ end }} #模板语言解析 添加图标格式:  该图片地址必须是全网都能够访问的一个地址 日期时间不要乱改,这是golang语言的时间格式
5.8.2.4 应用告警模板
vim /usr/local/dingtalk/conf/config.yml ...... #添加下面五行 templates: - '/usr/local/dingtalk/contrib/templates/dingtalk.tmpl' default_message: title: '{{ template "_ding.link.title" . }}' text: '{{ template "_ding.link.content" . }}' ... #重启dingtalk服务 /usr/local/dingtalk/bin/prometheus-webhook-dingtalk --config.file=/usr/local/dingtalk/conf/config.yml --web.listen-address=0.0.0.0:8060
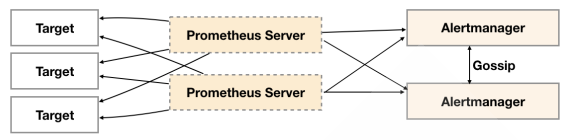
实际上可以通过keepalived把vip漂移到两个Alertmanager上实现。Alertmanager本身也提供了高可用方案。
5.9.2 Gossip 协议实现
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
范例:在同一个主机用Alertmanager多实例实现
#定义Alertmanager实例A1,其中Alertmanager的服务运行在9093端口,集群服务地址运行在8001端口(流言协议端口)。 alertmanager --web.listen-address=":9093" --cluster.listen-address="127.0.0.1:8001" --config.file=/etc/prometheus/alertmanager.yml --storage.path=/data/alertmanager/ #定义Alertmanager实例A2,其中Alertmanager的服务运行在9094端口,集群服务运行在8002端口。为了将A1,A2组成集群。 A2启动时需要定义--cluster.peer参数并且指向A1实例的集群服务地址:8001(如还有,也都要指定第一个服务地址) alertmanager --web.listen-address=":9094" --cluster.listen-address="127.0.0.1:8002" --cluster.peer=127.0.0.1:8001 --config.file=/etc/prometheus/alertmanager.yml --storage.path=/data/alertmanager2/ #创建Promthues集群配置文件/etc/prometheus/prometheus-ha.yml,完整内容如下: global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 15s rule_files: - /etc/prometheus/rules/*.rules alerting: alertmanagers: - static_configs: - targets: - 127.0.0.1:9093 - 127.0.0.1:9094 scrape_configs: - job_name: prometheus static_configs: - targets: - localhost:9090 - job_name: 'node' static_configs: - targets: ['localhost:9100']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号