微服务01 ZooKeeper, Kafka
1.4.6 Spring Cloud
JAVA 微服务技术
Dubbo是2014年之前阿里退出的分布式系统的技术(不属于微服务)。现在主流是 Spring Cloud
官网地址: https://spring.io/projects/spring-cloud
官网上实现方法有很多种,目前主流是阿里巴巴实现的方法
Spring Boot用于单体开发; Spring cloud基于Spring Boot开发,关注多个小服务开发
1.5 服务网格 Mesh
k8s里每个pod里放一个公用容器, 用于连数据库, 服务配置, 限流等功能, 叫边车。开发无需关注这些功能
1.6 无服务架构 Serverless
用于云端,用户只要写业务代码。其他买云服务,交给云厂商
1.7 微服务还是单体
单体在绝大部分时候是更好的选择,即单体优先
2 ZooKeeper
2.2 ZooKeeper 工作原理
2.2.1 ZooKeeper 功能
2.2.1.1 命名服务 #实现服务发现, 服务注册
2.2.1.2 状态同步
2.2.1.3 配置中心
2.2.1.4 集群管理
zookeeper自身也有集群功能, 保证自身高可用
2.2.2 ZooKeeper 服务流程
ZooKeeper没monitor功能, 没提供图形web界面,无法监控程序之间调用关系,nacos解决了这一问题
2.3 ZooKeeper 安装
zookeeper基于java开发
2.3.1 ZooKeeper 单机部署
2.3.1.2 部署 ZooKeeper
2.3.1.2.1 包安装
范例:包安装
#不要求版本,直接安装 [root@ubuntu2204 ~]#apt list zookeeper zookeeper/jammy 3.4.13-6ubuntu4 all [root@ubuntu2204 ~]#apt -y install zookeeper #如果没java会把java安装了 #启动 [root@ubuntu2204 ~]#/usr/share/zookeeper/bin/zkServer.sh start #查看状态 [root@ubuntu2204 ~]#/usr/share/zookeeper/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /etc/zookeeper/conf/zoo.cfg Mode: standalone #单机模式 [root@ubuntu ~]#ss -lntp #打开2181端口 LISTEN 0 50 *:2181 *:* users:(("java",pid=3810,fd=27))
2.3.1.2.2 二进制安装
#可以从apache基金会官网进入 https://zookeeper.apache.org/ #版本: stable 和 current ,生产建议使用stable版本 #有source release是源码要编译,没有表示编译好了 #历史版本下载 https://archive.apache.org/dist/zookeeper/ #下载带bin表示二进制版,如apache-zookeeper-3.9.2-bin.tar.gz [root@ubuntu ~]#wget https://archive.apache.org/dist/zookeeper/current/apache-zookeeper-3.9.2-bin.tar.gz #先装java环境,否则zookeeper起不来 [root@ubuntu ~]#apt update && apt -y install openjdk-11-jdk #检查下版本 [root@ubuntu ~]#java -version #解压zookeeper安装包 [root@ubuntu ~]#tar xf apache-zookeeper-3.9.2-bin.tar.gz -C /usr/local/ [root@ubuntu local]#cd apache-zookeeper-3.9.2-bin/ [root@ubuntu local]#ln -s apache-zookeeper-3.9.2-bin/ zookeeper #准备配置文件 [root@ubuntu local]#cd zookeeper/conf/ [root@ubuntu conf]#cp zoo_sample.cfg zoo.cfg #默认配置可不做修改 [root@ubuntu1804 ~]#vim /usr/local/zookeeper/conf/zoo.cfg tickTime=2000 #"滴答时间",用于配置Zookeeper中最小的时间单元长度,单位毫秒,是其它时间配置的基础 initLimit=10 #初始化时间,包含启动和数据同步,其值是tickTime的倍数 syncLimit=5 #正常工作,心跳监测的时间间隔,其值是tickTime的倍数 dataDir=/usr/local/zookeeper/data/ #配置Zookeeper服务存储数据快照的目录(把目录创建出来),基于安全 (默认tmp目录ubuntu一重启会清空) dataLogDir=/usr/local/zookeeper/logs #指定日志路径,默认与 dataDir 一致,事务日志对性能影响非常大,强烈建议事务日志目录和数据目录分开,如果后续修改路径,需要先删除中dataDir中旧的事务日志,否则可能无法启动 clientPort=2181 #配置当前Zookeeper服务对外暴露的端口,用户客户端和服务端建立连接会话 autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3 autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能 #修改PATH变量 [root@ubuntu ~]#echo 'PATH=/usr/local/zookeeper/bin:$PATH' > /etc/profile [root@ubuntu ~]#. /etc/profile #启动(默认会读取配置文件zoo.cfg) [root@ubuntu ~]#zkServer.sh start #查看状态 [root@ubuntu ~]#zkServer.sh status #查版本 [root@ubuntu ~]#zkServer.sh version #停止 [root@ubuntu ~]#zkServer.sh stop
2.3.1.5 service 文件
[root@ubuntu2204 ~]#cat > /lib/systemd/system/zookeeper.service <<EOF [Unit] Description=zookeeper.service After=network.target [Service] Type=forking ExecStart=/usr/local/zookeeper/bin/zkServer.sh start ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart [Install] WantedBy=multi-user.target EOF [root@ubuntu2204 ~]#systemctl daemon-reload [root@ubuntu2204 ~]#systemctl enable --now zookeeper.service
2.4.1 命令行客户端访问 ZooKeeper (了解)
#访问zookeeper [root@ubuntu ~]#zkCli.sh #默认连到本机2181端口 #按tab键查看命令列表 #查看文件 [zk: localhost:2181(CONNECTED) 0] ls / [zookeeper] [zk: localhost:2181(CONNECTED) 1] ls /zookeeper [config, quota] #zookeeper和文件系统区别:zookeeper的文件夹自身也可以存放文件,即文件夹也可同时作为文件 #获取zookeeper文件夹自己的数据 [zk: localhost:2181(CONNECTED) 2] get /zookeeper #创建文件夹 [zk: localhost:2181(CONNECTED) 3] create /app1 [zk: localhost:2181(CONNECTED) 5] ls / [app1, zookeeper] [zk: localhost:2181(CONNECTED) 7] create /app1/name #对app1文件夹存放数据 [zk: localhost:2181(CONNECTED) 8] set /app1 myapp #获取数据 [zk: localhost:2181(CONNECTED) 11] get /app1 myapp #app1路径下的内容保持不变 [zk: localhost:2181(CONNECTED) 12] ls /app1 [name] #查看已知节点元数据 [zk: 10.0.0.103:2181(CONNECTED) 9] stat /zookeeper #删除 [zk: 10.0.0.103:2181(CONNECTED) 7] delete /app1 #退出 quit
2.4.3 图形化客户端 ZooInspector
https://github.com/zzhang5/zooinspector
https://gitee.com/lbtooth/zooinspector.git
#注意:只支持JDK8,不支持JDK11 [root@ubuntu ~]#apt update && apt install -y openjdk-8-jdk [root@ubuntu ~]#apt install maven -y #如果没有java,会装jdk11 #镜像加速 [root@ubuntu ~]#vim /etc/maven/settings.xml <mirrors> <!--阿里云镜像--> <mirror> <id>nexus-aliyun</id> <mirrorOf>*</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror> </mirrors> #国内镜像 [root@zookeeper-node1 ~]#git clone https://gitee.com/lbtooth/zooinspector.git #编译,此步骤需要较长时间下载,可能数分钟 [root@ubuntu ~]#cd zooinspector/ [root@ubuntu zooinspector]#mvn clean package -Dmaven.test.skip=true #把target下大的jar包拷贝走,需要里面的脚本 [root@ubuntu zooinspector]#cp target/zooinspector-1.0-SNAPSHOT-pkg.tar /opt [root@ubuntu zooinspector]#cd /opt/ [root@ubuntu opt]#tar xf zooinspector-1.0-SNAPSHOT-pkg.tar #里面两个脚本,linux下用和windows下用 [root@ubuntu opt]#ls zooinspector-1.0-SNAPSHOT/bin/ zooinspector.bat zooinspector.sh [root@ubuntu zooinspector-1.0-SNAPSHOT]#bin/zooinspector.sh #把zooinspector-1.0-SNAPSHOT-pkg.tar传到windows上,解压 [root@ubuntu opt]#sz zooinspector-1.0-SNAPSHOT-pkg.tar #运行zooinspector.bat即可 #这个工具以后一直能用
[root@zookeeper-node1 ~]#apt update && apt -y install python3 python3-kazoo [root@zookeeper-node1 ~]#cat zookeepe_test.py #!/usr/bin/python3 from kazoo.client import KazooClient zk = KazooClient(hosts='10.0.0.101:2181') zk.start() # 创建节点(并写数据):makepath设置为True,父节点不存在则创建,其他参数不填均为默认 zk.create('/zkapp/test',b'this is a test',makepath=True) # 操作完后关闭zk连接 data=zk.get('/zkapp/test') print(data) zk.stop() [root@zookeeper-node1 ~]#chmod +x ./zookeepe_test.py [root@zookeeper-node1 ~]#./zookeepe_test.py
[root@ubuntu ~]#telnet 10.0.0.151 2181 #常见命令列表 conf #输出相关服务配置的详细信息 cons #列出所有连接到服务器的客户端的完全的连接/会话的详细信息 envi #输出关于服务环境的详细信息 dump #列出未经处理的会话和临时节点 stat #查看哪个节点被选择作为Follower或者Leader ruok #测试是否启动了该Server,若回复imok表示已经启动 mntr #输出一些运行时信息 reqs #列出未经处理的请求 wchs #列出服务器watch的简要信息 wchc #通过session列出服务器watch的详细信息 wchp #通过路径列出服务器watch的详细信息 srvr #输出服务的所有信息 srst #重置服务器统计信息 kill #关掉Server,当前版本无法关闭 isro #查看该服务的节点权限信息 #可以管道直接传输 [root@ubuntu ~]#echo conf | nc 10.0.0.200 2181
#默认情况下,这些4字命令有可能会被拒绝,提示如下报错 xxxx is not executed because it is not in the whitelist. #解决办法:在 zoo.cfg文件中添加如下配置,如果是集群需要在所有节点上添加下面配置 # vim conf/zoo.cfg 4lw.commands.whitelist=* #允许所有4字命令 #在服务状态查看命令中有很多存在隐患的命令,为了避免生产中的安全隐患,要对这些"危险"命令进行一些安全限制,只需要编辑服务的zoo.cfg文件即可 # vim conf/zoo.cfg 4lw.commands.whitelist=conf,stat,ruok,isro [root@ubuntu ~]#systemctl restart zookeeper.service
2.3.2 ZooKeeper 集群部署
2.3.2.1 ZooKeeper 集群介绍
zookeeper不需要设定谁是主谁是从,会自动选举主节点,从节点
2.3.2.1.1 集群结构
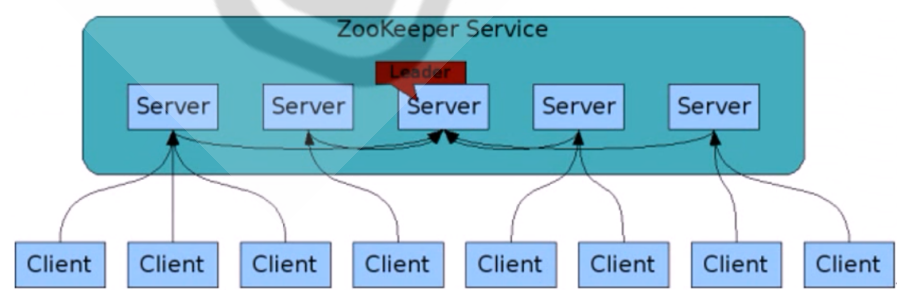
对于n台server,每个server都知道彼此的存在。只要有>n/2台server节点可用,整个zookeeper系统保持可用。因此zookeeper集群通常由 奇数台Server节点组成
集群中节点数越多,写性能越差,读性能越好。节点越少写性能越好,读性能越差
2.3.2.1.2 集群角色
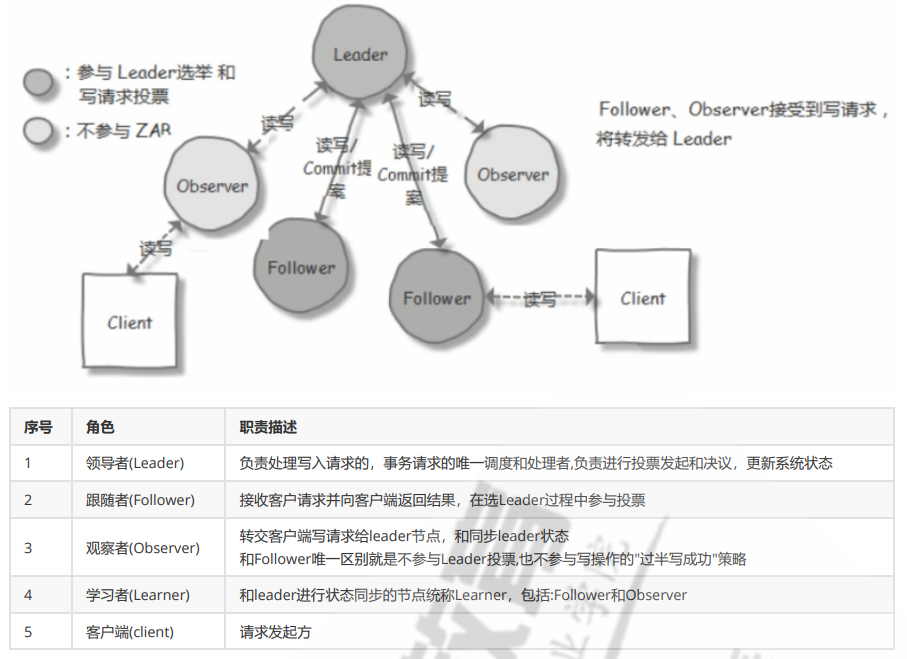
节点角色状态:
LOOKING:寻找 Leader 状态,处于该状态需要进入选举流程
LEADING:领导者状态,处于该状态的节点说明是角色已经是Leader
FOLLOWING:跟随者状态,表示 Leader已经选举出来,当前节点角色是follower
OBSERVER:观察者状态,表明当前节点角色是 observer
1.ZXID(zookeeper transaction id):每个改变 Zookeeper状态的操作都会自动生成一个对应的zxid。ZXID最大的节点优先选为Leader
2.myid:服务器的唯一标识(SID),通过配置 myid 文件指定,集群中唯一,当ZXID一样时,myid大的节点优先选为Leader
2.3.2.2.1 环境准备
#三台ubuntu18.04,20.04,22.04 zookeeper-node1.wang.org 10.0.0.151 zookeeper-node2.wang.org 10.0.0.152 zookeeper-node3.wang.org 10.0.0.153 #在三个节点都安装JDK8或JDK11 #在三个节点都安装zookeeper [root@ubuntu ~]#bash install_zookeeper_single_node.sh #装完是单机版,要改配置为集群版
2.3.2.2.3 准备配置文件
#3台机器修改配置文件 (追加下面3行) [root@ubuntu ~]#vim /usr/local/zookeeper/conf/zoo.cfg tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒 initLimit=10 #集群中leader 服务器与follower服务器初始连接心跳次数,即多少个 2000 毫秒 syncLimit=5 #leader 与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower将被视为不可用。 dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录 dataLogDir=/usr/local/zookeeper/logs clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求 maxClientCnxns=128 #单个客户端IP 可以和zookeeper保持的连接数 autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,最小值为3 autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能 #格式: server.MyID服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打开):Leader和Follower选举端口(L和F都有) server.1=10.0.0.151:2888:3888 server.2=10.0.0.152:2888:3888 server.3=10.0.0.153:2888:3888 #如果添加节点,只需要在所有节点上添加新节点的上面形式的配置行,在新节点创建myid文件,并重启所有节点服务即可 #创建dataDir文件 [root@ubuntu ~]#mkdir -p /usr/local/zookeeper/data
2.3.2.2.4 在各个节点生成ID文件
#10.0.0.151 [root@zookeeper-node1 ~]#echo 1 > /usr/local/zookeeper/data/myid #10.0.0.152 [root@zookeeper-node2 ~]#echo 2 > /usr/local/zookeeper/data/myid #10.0.0.153 [root@zookeeper-node3 ~]#echo 3 > /usr/local/zookeeper/data/myid
2.3.2.2.5 各服务器启动 Zookeeper
#3台机器都停止 [root@ubuntu ~]#systemctl stop zookeeper.service #3台机器都启动 [root@ubuntu ~]#systemctl start zookeeper.service #查看集群角色 [root@ubuntu ~]#zkServer.sh status #测试,reboot其中一台,查看两外两台,其中一台变为主节点
范例: 单实例
docker run --name some-zookeeper -p 2181:2181 --restart always -d zookeeper
范例: 集群部署
#基于docker-compose部署集群(部署在同一台机器,坏了就崩了,这样部署也就玩一玩) version: '3.1' services: zoo1: image: zookeeper restart: always hostname: zoo1 ports: - 2181:2181 environment: ZOO_MY_ID: 1 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181 zoo2: image: zookeeper restart: always hostname: zoo2 ports: - 2182:2181 environment: ZOO_MY_ID: 2 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181 zoo3: image: zookeeper restart: always hostname: zoo3 ports: - 2183:2181 environment: ZOO_MY_ID: 3 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
Zookeeper作为配置中心,也可以作为注册中心。具体怎么用,那就是java程序写代码了
3.2 Kafka 介绍
java写的
3.3 常用消息队列对比
kafka动态扩容依赖zookeeper,但是最新版不依赖它了
3.5 Kafka 角色和流程
3.5.1 Kafka 概念
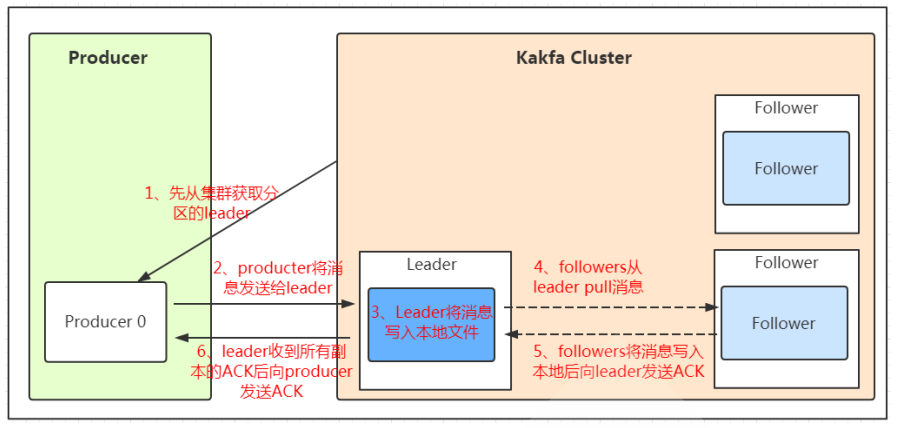
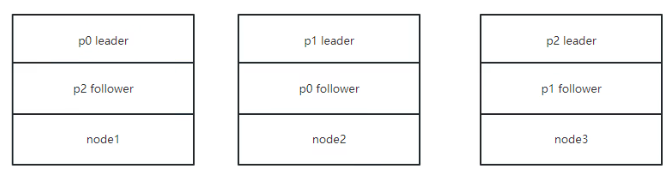
Producer:Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker。 Consumer:消费者,用于消费消息,即处理消息 Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,
如: broker-0、broker-1等…… Controller:是整个 Kafka 集群的管理者角色,任何集群范围内的状态变更都需要通过 Controller 进行,在整个集群中是个单点的服务,可以通过选举协议进行故障转移,
负责集群范围内的一些关键操作:主题的新建和删除,主题分区的新建、重新分配,Broker的加入、退出,触发分区 Leader 选举等,每个Broker里都有一个Controller实例,
多个Broker的集群同时最多只有一个Controller可以对外提供集群管理服务,Controller可以在Broker之间进行故障转移,Kafka 集群管理的工作主要是由Controller来完成的,
而 Controller 又通过监听Zookeeper 节点的变动来进行监听集群变化事件,Controller 进行集群管理需要保存集群元数据,监听集群状态变化情况并进行处理,
以及处理集群中修改集群元数据的请求,这些主要都是利用 Zookeeper 来实现 Topic :消息的主题,可以理解为消息的分类,一个Topic相当于数据库中的一张表,一条消息相当于关系数据库的一条记录,或者一个Topic相当于Redis中列表数据类型的一个Key,
一条消息即为列表中的一个元素。kafka的数据就保存在topic。在每个broker上都可以创建多个topic。 虽然一个 topic的消息保存于一个或多个broker 上同一个目录内, 物理上不同 topic 的消息分开存储在不同的文件夹,但用户只需指定消息的topic即可生产或消费数据而不必
关心数据存于何处,topic 在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应的topic 才能消费topic中的消息。 Consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group name,若不指定 group name 则属于默认的group),
同一topic的一条消息只能被同一个consumer group 内的一个consumer 消费,类似于一对一的单播机制,但多个consumer group 可同时消费这一消息,
类似于一对多的多播机制
Partition :是物理上的概念,每个 topic 分割为一个或多个partition,即一个topic切分为多份, 当创建 topic 时可指定 partition 数量,
partition的表现形式就是一个一个的文件夹,该文件夹下存储该partition的数据和索引文件,分区的作用还可以实现负载均衡,提高kafka的吞吐量。
同一个topic在不同的分区的数据是不重复的,一般Partition数不要超过节点数,注意同一个partition数据是有顺序的,但不同的partition则是无序的。 Replication: 同样数据的副本,包括leader和follower的副本数,基本于数据安全,建议至少2个,是Kafka的高可靠性的保障,和ES的副本有所不同,
Kafka中的副(leader+follower)数包括主分片数,而ES中的副本数(follower)不包括主分片数 #副本放的位置kafka自己实现
3.5.2 Kafka 工作机制
注意:Kafka 2.8.0版本开始,增加了KRaft(KRaft是Kafka Raft协议模式的简称)模式,这个模式下Kafka不再需要ZooKeeper,而是使用内 置的Raft协议来进行元数据的管理和领导者选举。Raft协议是一种为分布式系统提供一致性的算法,它更易于理解和实施,同时也保证了系 统的可用性和数据的一致性。