
Shell阶段09 shell正则,grep正则, sed使用及案例
[root@shell01 shell13]# grep -E 'root|nginx|mysql|www' passwd通配符及特殊符号 * #所有 . #当前目录 .. #当前目录的上级目录 - #当前目录的上一次所在的目录 ~ #家目录 # #注释,超级管理员的命令行提示符 $ #引用变量,普通用户的命令行提示符 ? #匹配任意一个字符,必须是一个 ! #非,取反 [] #匹配中括号中任意一个字符 {} #生成序列,整体 [^] #排除中括号中所有字符 `` #优先执行反引号里面的命令 $() #优先执行里面的命令 && #前面一个命令执行成功,才会执行后面的命令 || #签名的命令执行失败,才会执行后面的命令 | #管道,将前面的命令的输出结果交给管道后面的命令 \ #转义字符,取消一些特殊字符的含义 & #将程序放到后台运行 正则表达式 注意事项: 正则神坑 中文字符 正则符号 基础正则 扩展正则 RE BRE ERE ^ #开头 $ #结尾 ^$ #空行(有空格或tab键不算空行)
<pattern\> #匹配整个单词
#注意: 单词是由字母,数字,下划线组成
\ #转义字符 . #任意一个字符,除了换行符 [] #匹配中括号中的任意一个字符 [^] #匹配[^]之外的所有字符 [a-z] #匹配所有小写字母 [0-9] ? #匹配前面的字符出现0次或者1次 #扩展 * #匹配前面的字符出现0次或者0次以上 + #匹配前面的字符出现1次或者1次以上 #扩展 .* #所有 () #整体,后向引用,创建一个用于匹配的字符串 #扩展 {n} #n数字,前面的字符出现n次 #扩展 {n,} #前面的字符至少出现n次 #扩展 {n,m} #前面的字符出现至少n次,最多m次 n<m #扩展 {,m} #前面的字符最多出现m次 #扩展 | #或者 #扩展 特定的字符 [[:upper:]] 所有大写字母 [[:lower:]] 所有小写字母 [[:alpha:]] 所有字母 [[:space:]] 所有空白字符 [[:digit:]] 所有数字 [[:alnum:]] 所有字母和数字 [[:punct:]] 所有特殊符号 grep #三剑客老三 过滤 过滤出来的内容是有颜色 [root@shell01 shell13]# alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' 选项: -i #忽略大小写 -v #排除 -n #显示过滤出来的内容所在文件的行号 -c #将过滤出来的内容进行统计 -w #精确匹配 -o #只显示过滤出来的内容 -E #支持扩展正则 (扩展正则实际上是基本正则\转义太多,所以开发出-E一般不用\转义的) -r #递归过滤 -R #递归过滤 -A #显示过滤出来的内容及向下多少行 -B #向上 -C #向上向下各多少行 #准备文件 cp /etc/passwd ./ #过滤以什么开头的行 [root@shell01 shell13]# grep '^root' passwd root:x:0:0:root:/root:/bin/bash #过滤以什么为结尾的行 [root@shell01 shell13]# grep 't$' passwd halt:x:7:0:halt:/sbin:/sbin/halt #过滤出空行,并打印行号 -n显示行号 [root@shell01 shell13]# grep -n '^$' passwd #匹配任意一个字符,不匹配空行 [root@shell01 shell13]# grep '.' passwd #匹配所有行,包括空行 [root@shell01 shell13]# grep '.*' passwd # 取消特殊含义,匹配以.结尾行 [root@shell01 shell13]# grep '\.$' passwd
# 匹配单词
[root@ubuntu2204 ~]# echo mage | grep "\<mage\>"
#匹配中括号中的任意一个字符,a开头或者c开头 [root@shell01 shell13]# grep '^[ac]' passwd adm:x:3:4:adm:/var/adm:/sbin/nologin cdm:x:3:4:adm:/var/adm:/sbin/nologin #以ac开头,加不加括号都行 [root@shell01 shell13]# grep '^(ac)' passwd #排除中括号中的任意一个字符,排除a或者c开头 [root@shell01 shell13]# grep '^[^ac]' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin #统计出文件中所有字母出现的次数,次数从大到小进行排列 # -o只显示过滤出来的内容 uniq -c去重统计 [root@shell01 shell13]# grep -o '[a-Z]' passwd |sort |uniq -c|sort -rn 101 n 84 o 73 s #统计出文件中所有单词出现的次数,次数从大到小进行排列 #+号是扩展正则,需要用-E [root@shell01 shell13]# grep -Eo '[a-Z]+' passwd |sort |uniq -c|sort -rn 26 sbin 24 x 20 nologin 10 var #+和*的区别之处 [root@shell01 shell13]# grep 'a*' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin [root@shell01 shell13]# grep -E 'a+' passwd root:x:0:0:root:/root:/bin/bash daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin #*和?的区别 [root@shell01 shell13]# grep -Eo 'a*' passwd a aaa [root@shell01 shell13]# grep -Eo 'a?' passwd a a #过滤出passwd文件中数字为2位或者3位的数字 #这里用w精确匹配, {}是扩展正则,要用-E [root@shell01 shell13]# grep -Ew '[0-9]{2,3}' passwd mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin #匹配数字位数出现2次 [root@shell01 shell13]# grep -Ew '[0-9]{2}' passwd #匹配数字出现5次以上 [root@shell01 shell13]# grep -Ew '[0-9]{5,}' passwd #前面的数字最多匹配2次,可以匹配0次 [root@shell01 shell13]# grep -Ew '[0-9]{,2}' passwd [root@shell01 shell13]# grep -Ew '[0-9]{0,2}' passwd
#过滤文件中以r开头的行,忽略大小写 [root@shell01 shell13]# grep -i '^r' passwd root:x:0:0:root:/root:/bin/bash [root@shell01 shell13]# grep '^[rR]' passwd #()号是一个整体,当中用|才是或 [root@shell01 shell13]# grep -E '^(r|R)' passwd #过滤出文件中包含root nginx mysql www等字符串 [root@shell01 shell13]# grep -E 'root|nginx|mysql|www' passwd #过滤出文件中以root nginx mysql www开头的行 [root@shell01 shell13]# grep -E '^root|^nginx|^mysql|^www' passwd [root@shell01 shell13]# grep -E '^(root|nginx|mysql|www)' passwd #取IP地址 [root@shell01 shell13]# ifconfig |grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' -o #文件中匹配出正确的身份证号码 [root@shell01 shell13]# grep -Ew '[0-9]{17}[0-9x]{1}' id.txt
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+ 后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名 方式为: \1, \2, \3, ... \1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符 注意: \0 表示正则表达式匹配的所有字符
#ab,然后c出现3次 [root@ubuntu2204 ~]# echo abccc | grep "abc\{3\}" abccc #abc作为一个整体出现3次 [root@ubuntu2204 ~]# echo abcabcabc | grep "\(abc\)\{3\}" abcabcabc #后向引用 #\1表示引用第一个分组的内容,即 abc [root@ubuntu2204 ~]# echo "abcdefabc" | grep "\(abc\)def\1" abcdefabc #\1表示引用第一个分组的内容,即abc,\{3\}表示引用内容出现3次 [root@ubuntu2204 ~]# echo abc-def-abcabcabc | grep "^\(abc\)-\(def\)-\1\{3\}" abc-def-abcabcabc 注意: 后向引用引用前面的分组括号中的模式所匹配字符,而非模式本身
2.或者: |
a\|b #a或b C\|cat #C或cat \(C\|c\)at #Cat或cat #a或b a\|b [root@ubuntu2204 ~]# echo "cab" | grep "a\|b" cab
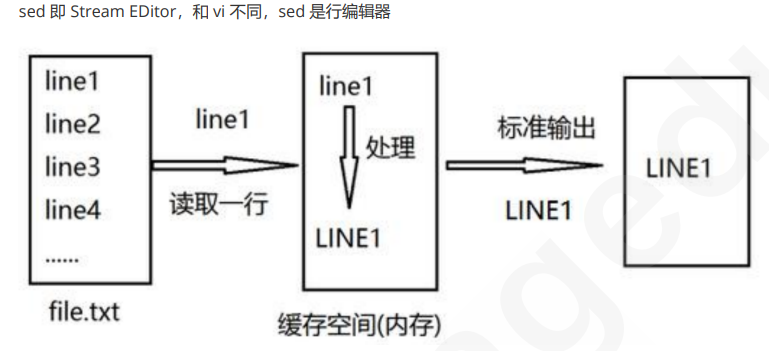
# sed工作原理
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到
最后一行。
每当处理一行时,把当前处理的行存储在临时缓冲区 模式空间(Pattern Space) 中,接着用sed命令
处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到
文件末尾。
一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。
如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性
将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速
度也很快。
三剑客的老二 擅长替换 流编辑器 非交互式的编辑器 Sed的工作原理 sed命令按照行进行处理内容。处理文件时,首先会将第一行取出放在一个缓冲区,这个缓冲区我们称之为模式空间。 sed进行处理。如果行匹配处理完成之后将之输出到屏幕,如果行不匹配,将之丢弃。接着处理下一行。同样的操作,直到文件结束。
文件的内容其实并没有改变。如果想真正的改变,需要加上-i选项。 sed是可以同时处理多个文件的。 sed的语法: sed [选项] command files sed正则使用,和grep相差不大 sed使用扩展正则时,需要使用-r选项 Sed的命令示例: 选项: 增删改查 -n #取消默认输出 -i #修改文件内容 -r #支持扩展正则 -e #多项编辑,or的关系 Sed 的内部命令 a #追加 i #插入(在上面追加) p #打印 d #删除 s #替换 g #全局 c #在当前行位置进行替换 ! #取反 = #显示行号 i #忽略大小写 了解 n #读入下一行,从下一行命令进行处理(N为上一行) h #把模式空间的内容重定向到暂存缓冲区 H #把模式空间里的内容追加到暂存缓冲区 g #取出暂存缓冲区的内容,将其复制到模式空间,覆盖原处的内容 G #取出暂存缓冲区的内容,将其复制到模式空间,追加到原处的内容的后面 地址格式
# 为空,则表示对全文进行处理
#单地址,指定行 N #具体行号
$ #最后一行
/pattern/ #能被匹配到的每一行
#范围地址
M,N #第M行到第N行
M,+N #第M行到第M+N行 3,+4 表示从第3行到第7行
/pattern1/,/pattern2/ #从第一个匹配行开始,到第二个匹配行中间的行
M,/pattern/ #行号开始,匹配结束
/pattern/,N #匹配开始,行号结束
#步长
1~2 #奇数行
2~2 #偶数行
#后向引用
\1 #第一个分组
\2 #第二个分组
\N #第N个分组
& #所有搜索内容
#输出第三行 (默认会输出所有内容,-n取消默认输出) [root@shell01 shell13]# sed -n '3p' /etc/passwd daemon:x:2:2:daemon:/sbin:/sbin/nologin #输出2-10行 [root@shell01 shell13]# sed -n '2,10p' /etc/passwd daemon:x:2:2:daemon:/sbin:/sbin/nologin #输出最后一行
[root@ubuntu2204 ~]# sed -n '$p' /etc/passwd
#正则匹配,输出以root开头的行
[root@rocky86 ~]# sed -n '/^root/p' /etc/passwd
root:x:0:0:root:/root:/bin/bash
#获取cpu信息(使用反向引用\1指代前面第一个()中的内容)
[root@ubuntu ~]#lscpu |sed -En 's/Model name: +([^ ].*)/\1/p'
Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
#取非 1|3|5|7
[root@ubuntu2204 ~]# ls | grep -Ev 'f-(1|3|5|7)\.txt'
f-2.txt f-4.txt
#行号开始,正则结束
[root@rocky86 0723]# sed -n '8,/root/p' /etc/passwd
#变量展开
[root@ubuntu2204 ~]# number=1;sed -n "${number}p" /etc/passwd
root:x:0:0:root:/root:/bin/bash
#删除2-10行 [root@shell01 shell13]# sed -n '2,10d' /etc/passwd #删除第2行到结尾 [root@shell01 shell13]# sed -n '2,$d' /etc/passwd
#删除奇数行
[root@ubuntu2204 ~]# seq 10 |sed '1~2d'
2
4
#或
[root@ubuntu2204 ~]# #sed -e '2d' -e '4d' seq.log
1
3
5
#在第三行下面追加oldboy内容 [root@shell01 shell13]# sed -i '3a oldboy' passwd #在第三行上面追加alex [root@shell01 shell13]# sed -i '3i alex' passwd
#修改前备份
[root@ubuntu2204 ~]# seq 10 > 10.txt
[root@ubuntu2204 ~]# sed -i.bak '2,7d' 10.txt
[root@ubuntu2204 ~]# ll 10*
-rw-r--r-- 1 root root 9 Jul 23 19:02 10.txt
-rw-r--r-- 1 root root 21 Jul 23 19:01 10.txt.bak
#不备份
[root@ubuntu2204 ~]# sed -i '2,7d' 10.txt
#后向引用 &引用前面的r..t
[root@rocky86 0723]# sed -n 's/r..t/&er/gp' /etc/passwd
rooter:x:0:0:rooter:/rooter:/bin/bash
operator:x:11:0:operator:/rooter:/sbin/nologin
#把第五行替换为lidao [root@shell01 shell13]# sed '5c lidao' passwd #找lp打印出来 [root@shell01 shell13]# sed -n '/lp/p' passwd #在lp行下把spool换成alex (-n取消默认输出,就要有p,否则没有输出了) [root@shell01 shell13]# sed -n '/lp/s#spool#alex#gp' passwd lp:x:4:7:lp:/var/alex/lpd:/sbin/nologin #匹配root行,删除root行的下一行(没用) (换成N就是上一行) [root@shell01 shell13]# sed '/root/{n;d}' passwd #替换匹配root行的下一行(没用) [root@shell01 shell13]# sed '/root/{n; s/bin/oldboy/}' passwd #将第一行写入暂存区,替换最后一行内容 [root@shell01 shell13]# sed '1h;$g' /etc/hosts #将第一行写入暂存区,在最后一行调用暂存区的内容 [root@shell01 shell13]# sed '1h;$G' /etc/hosts #将第一行的内容删除但保留至暂存区,在最后一行调用暂存区内容追加到尾部 [root@shell01 shell13]# sed -r '1{h;d};$G' /etc/hosts #将第一行的内容写入暂存区,从第二行开始往下全部替换 [root@shell01 shell13]# sed -r '1h;2,$g' /etc/hosts #将第一行重定向到暂存区,2-3行追加到暂存区,最后追加调用暂存区的内容 [root@shell01 shell13]# sed -r '1h; 2,3H; $g' /etc/hosts #示例: #把定时任务里的时间同步注释 [root@shell01 shell13]# sed -n '/ntpdate/s#^##gp' /var/spool/cron/root [root@shell01 shell13]# sed -n '/ntpdate/s/^/#/gp' /var/spool/cron/root #把第二行注释 [root@shell01 shell13]# sed -n '2s/^/#/gp' /var/spool/cron/root #把第二行到结尾注释 [root@shell01 shell13]# sed -n '2,$s/^/#/gp' /var/spool/cron/root #将第2行到第6行前面添加#注释符 &为追加的意思 [root@shell01 shell13]# sed -r '2,6s/.*/#&/' passwd
获取ip地址
[root@ubuntu ~]#ifconfig ens33 ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.0.151 netmask 255.255.255.0 broadcast 10.0.0.255 inet6 fe80::20c:29ff:fe0b:c907 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:0b:c9:07 txqueuelen 1000 (Ethernet) RX packets 1099 bytes 596003 (596.0 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 836 bytes 112838 (112.8 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ubuntu ~]#ifconfig ens33 | sed -nE 's/.*inet (.*) netmask.*/\1/p' 10.0.0.151
