

Redis2 GEO, redis持久化(rdb,aof), redis主从, redis哨兵
GEO
存储经纬度,计算两个点之间的距离,统计某个点周围多少距离的其他点
北京:116.28,39.55
天津:117.12,39.08
5个城市纬度
| 城市 | 经度 | 纬度 | 简称 |
|---|---|---|---|
| 北京 | 116.28 | 39.55 | beijing |
| 天津 | 117.12 | tianjin | |
| 石家庄 | 114.29 | 38.02 | shijiazhuang |
| 唐山 | 118.01 | 39.38 | tangshan |
| 保定 | 115.29 | 38.51 | baoding |
geoadd key longitude latitude member 举例: geoadd cities:locations 116.28 39.55 beijing --你实际的项目,地理位置信息从哪里来的?前端传过来的 -app,移动端,申请权限,用户允许了,直接调用手机提供的接口,得到经纬度---》调后台接口传给你--》拿到经纬度,放到redis中即可
(网页也是,问是否允许访问你的位置,选是返回后端) # 我现在是张三,我跟李四是朋友---》李四所在的位置,李四距离我多远,我方圆5公里内,我的好友有谁 取出某个位置的坐标 (把经纬度通过接口给前端, 前端自己处理。或者用post模块调网上现成接口[很多]显示是哪里,再给前端) geopos cities:locations beijing 计算两个人之间的距离(算的是直线距离) geodist cities:locations beijing tianjin km 计算方圆多少公里内有谁(可以算房源,商铺,好友) georadiusbymember cities:locations beijing 150 km type cities:locations # 查看geo是什么类型,返回zset,是有序集合类型
相关命令
geoadd key longitude latitude member #增加地理位置信息 geoadd cities:locations 116.28 39.55 beijing #把北京地理信息天津到cities:locations中 geoadd cities:locations 117.12 39.08 tianjin geoadd cities:locations 114.29 38.02 shijiazhuang geoadd cities:locations 118.01 39.38 tangshan geoadd cities:locations 115.29 38.51 baoding geopos key member #获取地理位置信息 geopos cities:locations beijing #获取北京地理信息 geodist key member1 member2 [unit]#获取两个地理位置的距离 unit:m(米) km(千米) mi(英里) ft(尺) geodist cities:locations beijing tianjin km #北京到天津的距离,89公里 georadius key logitude latitude radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key][storedist key] georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist] [withhash] [COUNT count] [asc|desc] [store key][storedist key] #获取指定位置范围内的地理位置信息集合 ''' withcoord:返回结果中包含经纬度 withdist:返回结果中包含距离中心节点位置 withhash:返回解雇中包含geohash COUNT count:指定返回结果的数量 asc|desc:返回结果按照距离中心店的距离做升序/降序排列 store key:将返回结果的地理位置信息保存到指定键 storedist key:将返回结果距离中心点的距离保存到指定键 ''' georadiusbymember cities:locations beijing 150 km ''' 1) "beijing" 2) "tianjin" 3) "tangshan" 4) "baoding" '''
3.2以后版本才有
geo本质时zset类型
可以使用zset的删除,删除指定member:zrem cities:locations beijing
redis持久化
#1 持久化:把内存中的数据,保存到硬盘上 #2 两种方案: -快照:rdb (类似mysql中的Dump,把内存中所有数据存到硬盘中) -日志:aof (每加,修改一条记录,记一条日志。用来恢复数据,从头走一遍即可恢复)
RDB

# 3 rdb持久化:三种方式,两种手动,一种配置文件(配置文件) # 第一种:在redis-cli客户端敲save---》通过rdb方案持久化到硬盘上,同步操作,会造成redis的阻塞 # (文件策略:如果老的RDB存在,会替换老的) # 第二种:在redis-cli客户端敲bgsave---》通过rdb方案持久化到硬盘上,异步操作 # (文件策略:跟save相同,如果老的RDB存在,会替换老的) # 第三种:配置文件 save 900 1 save 300 10 save 60 10000 解释: 如果60s中改变了1w条数据,自动生成rdb,自动调用一下bgsave 如果300s中改变了10条数据,自动生成rdb,自动调用一下bgsave 如果900s中改变了1条数据,自动生成rdb,自动调用一下bgsave # 配置文件中加入: save 900 1 #配置一条 save 300 10 #配置一条 save 60 10000 #配置一条 dbfilename dump.rdb # 设置启动载入的rdb文件名字,这句不写默认为dump.rdb dir ./ #rdb文件存在当前目录 # 4 rdb方案有缺陷,可能会丢失数据(只是用缓存)
 删除对应文件,对应aof,rdb方式无法恢复
删除对应文件,对应aof,rdb方式无法恢复
AOF
# 5 aof持久化方案 ## AOF介绍:客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复 ## aof的三种策略 日志不是直接写到硬盘上,而是先放在缓冲区,缓冲区根据一些策略,写到硬盘上 always:redis--》写命令刷新的缓冲区---》每条命令fsync到硬盘---》AOF文件 #耗费资源,每一条命令,调flash everysec(默认值):redis——》写命令刷新的缓冲区---》每秒把缓冲区fsync到硬盘--》AOF文件 #每秒刷一次(一般用这个) no:redis——》写命令刷新的缓冲区---》操作系统决定,缓冲区fsync到硬盘--》AOF文件 #类似python读写文件,没调flash,由系统决定 # 6 aof重写 随着命令的逐步写入,并发量的变大, AOF文件会越来越大,通过AOF重写来解决该问题 本质就是把过期的,无用的,重复的,可以优化的命令,来优化 这样可以减少磁盘占用量,加速恢复速度 # 7 启用aof就是修改一下配置文件(重启即可) appendonly yes #将该选项设置为yes,打开 # appendfilename "appendonly-${port}.aof" #文件保存的名字(指定aof文件名字) appendfilename "appendonly.aof" #文件保存的名字(指定aof文件名字) appendfsync everysec #采用第二种策略 dir /bigdiskpath #存放的路径 no-appendfsync-on-rewrite yes #在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失(重写策略,是否开启) ## 公司里可以aof rdb同时使用,就是耗费性能 自动化运维系统,自动安装redis,修改配置文件, 给redis使用aof的持久化方案 点按钮,切换成aof----》打开配置文件---》把那几行写入---》重启redis服务 点个按钮即可
redis主从
# 1 为了提高性能,扩展机器(读写分离,数据副本。一主一从,一主多从) # 2 数据流向是单向的,从master到slave # 3 两种方式:(需要两台机器)(启动两个redis进程,分别监听两个端口) -第一种:在客户端cli里执行命令 -在本地起两个redis服务(进程)6380是从,6379是主 # 6380从库基础配置修改如下 ## port 6380 # 修改端口 ## dir "/opt/soft/redis/data1" # 修改数据存放目录 ## logfile 6380.log # 修改log文件名 # 监测两个redis进程起来没 ps aux|grep redis-server ## grep --color=auto redis-server 这是监测的进程 -登陆到从库(6380库, redis-cli -p 6380),执行 -slaveof 127.0.0.1 6379 # 主库增删该数据,从库跟着改(在从库写入数据会报错) -取消复制:slaveof no one -第二种:配置文件 -在从节点(从数据库)配置(重启即可) slaveof ip port #配置从节点ip和端口 slave-read-only yes #从节点只读,因为可读可写,数据会乱 slaveof 127.0.0.1 6379 slave-read-only yes # 4 一主多从呢?(从库只能读) 只需要在多个从库上配置即可
redis哨兵
架构说明
可以做故障判断,故障转移,通知客户端(其实是一个进程),客户端直接连接sentinel的地址
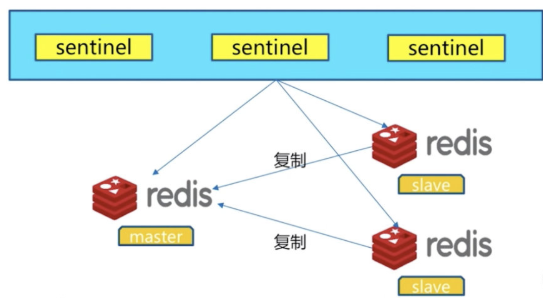
1 多个sentinel发现并确认master有问题
2 选举触一个sentinel作为领导
3 选取一个slave作为新的master
4 通知其余slave成为新的master的slave
5 通知客户端主从变化
6 等待老的master复活成为新master的slave
# 1 哨兵是为了保证redis'服务的高可用,一个master挂掉,服务依然可以用 # 2 哨兵搭建步骤 -1 先做一主两从 6379是主mastre 6380是从slave 6381是从slave -2 启用哨兵(哨兵是一个redis进程,哨兵sentinel进程可以分别放在不同的机器上) ## 配置解释: sentinel monitor <master-name> <ip> <redis-port> <quorum> 告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效 sentinel auth-pass <master-name> <password> 设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。 sentinel down-after-milliseconds <master-name> <milliseconds> 这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒 sentinel parallel-syncs <master-name> <numslaves> 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 sentinel failover-timeout <master-name> <milliseconds> failover-timeout 可以用在以下这些方面: 1. 同一个sentinel对同一个master两次failover之间的间隔时间。 2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 3.当想要取消一个正在进行的failover所需要的时间。 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。 # vim sentinel_26379.conf #创建一个sentinel的配置文件 #26379端口--一个哨兵 配置文件: port 26379 daemonize yes# 是否以守护进程的形式来跑 dir data# 数据存放目录 protected-mode no#保护模式,写不写都行,现在不需要远程连它 bind 0.0.0.0#绑定 logfile "redis_sentinel.log"#日志存放路径,在数据存放路径下面 sentinel monitor mymaster 127.0.0.1 6379 2#mymaster名字随便命 主master地址端口号 2代表要有两个sntinel觉得你挂了,你才是挂了 sentinel down-after-milliseconds mymaster 30000#指定需要多少时间,master被这个sentinel主管地认为不可用.单位是毫秒,默认为30秒 sentinel parallel-syncs mymaster 1#设置failover主备切换时,多少slave同事对新master进行同步,数字越小,切换时间越长.注:在备份的slave不可用,设为1保证每次只有一个slave处于不能处理命令请求状态.默认为1 sentinel failover-timeout mymaster 180000#同一个sentinel对同一个master两次failover失败之间的事件间隔,单位毫秒,用默认即可 #26380端口--一个哨兵 port 26380 daemonize yes dir data1 protected-mode no bind 0.0.0.0 logfile "redis_sentinel.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 #26381端口--一个哨兵 port 26381 daemonize yes dir data2 protected-mode no bind 0.0.0.0 logfile "redis_sentinel.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 -redis-sentinel 配置文件来启动哨兵 -启动哨兵: redis-sentinel 配置文件 # ./src/redis-sentinel sentinel_26379.conf # 命令在src路径下 redis-sentinel sentinel_26379.conf redis-sentinel sentinel_26380.conf redis-sentinel sentinel_26381.conf # ps aux |grep redis # 查看当前redis-sentinel进程 -从客户端登录到一个哨兵上 redis-cli -p 26379 # 哨兵不能写数据 -输入info 最后一行看到 master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3 # 显示主数据库地址端口,从数据库数量,几个哨兵 -把主库手动停掉 shutdown -连到哨兵上,输入info(主master自动变成了6381) master0:name=mymaster,status=ok,address=101.133.225.166:6381,slaves=4,sentinels=3#这是视频结果,有问题 master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=3#这是我的正常结果,6381变为主。从库还是有2,实际有一个已经被关闭了 -原来的主库如果启动,主库会变为从库,继续运行redis服务(哨兵不能重启redis服务,只能监控)(视频碰到了问题:数据脏了) # python客户端连接(直接连了主库,主库挂掉,不能改代码吧) import redis from redis.sentinel import Sentinel # 连接哨兵服务器(主机名也可以用域名) # 10.0.0.101:26379 sentinel = Sentinel([('10.0.0.101', 26379), ('10.0.0.101', 26378), ('10.0.0.101', 26377) ],socket_timeout=5) print(sentinel) # 获取主服务器地址 master = sentinel.discover_master('mymaster') print(master) # 获取从服务器地址 slave = sentinel.discover_slaves('mymaster') print(slave) # 获取主服务器进行写入 # master = sentinel.master_for('mymaster', socket_timeout=0.5) # w_ret = master.set('foo', 'bar') # # # slave = sentinel.slave_for('mymaster', socket_timeout=0.5) # r_ret = slave.get('foo') # print(r_ret)
