

Redis1 介绍linux安装配置, 使用场景, redis-API的使用(通用命令, 五大数据类型), redis高级用法(慢查询优化, 管道[实现事务功能], 发布订阅, Bitmap位图, HyperLogLog)
Redis 介绍安装配置
#1 只有5种数据结构: -多种数据结构:字符串,hash,列表,集合,有序集合 #2 单线程,速度为什么这么快? -本质还是因为是内存数据库 -epoll模型(io多路复用) -单线程,没有线程,进程间的通信 # 3 linux上 安装redis#下载 (测试放在/home/ldc路径下) wget http://download.redis.io/releases/redis-5.0.7.tar.gz #解压 tar -xzf redis-5.0.7.tar.gz #建立软连接 (相当于建立快捷方式,直接cd就能进去) ln -s redis-5.0.7 redis # 当前路径下会有redis文件夹 cd redis make&&make install # 编译和安装两步并一步 # bin路径下几个命令:redis-cli,redis-server,redis-sentinel (cd到redis里的src文件夹中,能看到命令,可以敲命令使用) # 在任意位置能够执行redis-server 如何做?配置环境变量 (经测试这里redis自动加入环境变量中) #4 启动redis的三种方式 -方式一:(一般不用,没有配置文件) -redis-server -方式二:(用的也很少) # 以6380端口打开 redis-server --port 6380 -方式三:(都用这种,配置文件) # cat redis.conf查看配置文件,下面为内部重要参数 daemonize yes#是否以守护进程启动 pidfile /var/run/redis.pid#进程号的位置,删除 port 6379#端口号 dir "/opt/soft/redis/data"#工作目录(数据存放的目录) logfile 6379.log#日志位置 # vim redis.conf1 编写新的配置文件,写入上面5行重要参数 (注意命令结尾不要空格,可以写注释。经过测试,删掉注释才能识别。。。) # 启动:redis-server redis.conf1
(Can't chdir to '/opt/soft/redis/data': No such file or directory报错。创建对应的文件夹路径,然后回到redis.conf1路径下) #5 客户端连接 redis-cli -h 127.0.0.1 -p 6379 # 查看进程是否存在 ps -ef |grep redis-server |grep 6379 # 参看日志 cat 6379.log
使用场景
计数器:网站访问量,转发量,评论数(文章转发,商品销量,单线程模型【一个个执行,不会出现并发问题】)
消息队列:发布订阅,阻塞队列实现(简单的分布式,blpop:阻塞队列,生产者消费者)
排行榜:有序集合(阅读排行,点赞排行,推荐(销量高的,推荐))
社交网络:很多特效跟社交网络匹配,粉丝数,关注数
实时系统:垃圾邮件处理系统,布隆过滤器
redis-API的使用
# 介绍,安装,启动,应用场景 在配置文件中添加:允许远程登陆(windows连接测试,redis没设密码,不用添加下面参数也能连) bind 0.0.0.0 protected-mode no requirepass 123456 # 可加可不加 #1 通用命令 ####1-keys #打印出所有key keys * (少用,慢查询。数据多,会特别慢) #keys命令一般不在生产环境中使用,生产环境key很多,时间复杂度为o(n),用scan命令 ####2-dbsize 计算key的总数 dbsize #redis内置了计数器,插入删除值该计数器会更改,所以可以在生产环境使用,时间复杂度是o(1) ###3-exists key 时间复杂度o(1) exists key # 查看key是否存在 #设置a set a b #查看a是否存在 exists a (integer) 1 # 返回结果 #存在返回1 不存在返回0 ###4-del key 时间复杂度o(1) 删除成功返回1,key不存在返回0 ###5-expire key seconds 时间复杂度o(1) expire name 时间 # 给name这个key设置一个超时时间 expire name 3 #3s 过期 ttl name # 还剩多长时间过期 persist name # 去掉超时时间,没有过期时间。如果过期了,就不存在了,返回(integer) 0 ###6-type key 时间复杂度o(1) type name # 查看key 对应数据的类型 # 2 数据结构:5大数据类型(字符串,列表,hash,集合,有序集合 他们底层有更丰富的类型存储) # 3 单线程架构,同一时刻,只有一个命令(不会出现并发问题) -其实并不是真正的单线程,执行命令是单线程,可能会持久化数据
字符串类型
# 4 字符串类型 ##常用命令 ###1---基本使用get,set,del get name #时间复杂度 o(1) set name lqz #时间复杂度 o(1) del name #时间复杂度 o(1) ###2---其他使用incr,decr,incrby,decrby incr age #对age这个key的value值自增1 decr age #对age这个key的value值自减1 incrby age 10 #对age这个key的value值增加10 decrby age 10 #对age这个key的value值减10 #统计网站访问量(单线程无竞争,天然适合做计数器) #缓存mysql的信息(json格式) #分布式id生成(多个机器同时并发着生成,不会重复) ###3---set,setnx,setxx set name lqz #不管key是否存在,都设置 setnx name lqz #key不存在时才设置(新增操作) set name lqz nx #同上 set name lqz xx #key存在,才设置(更新操作) ###4---mget mset mget key1 key2 key3 #批量获取key1,key2.。。时间复杂度o(n) mset key1 value1 key2 value2 key3 value3 #批量设置时间复杂度o(n) #n次get和mget的区别 #n次get时间=n次命令时间+n次网络时间 #mget时间=1次网络时间+n次命令时间 ###5---其他:getset,append,strlen getset name lqznb #设置新值并返回旧值 时间复杂度o(1) append name 666 #将value追加到旧的value 时间复杂度o(1) strlen name #计算字符串长度(注意中文) 时间复杂度o(1) ###6---其他:incrybyfloat,getrange,setrange increbyfloat age 3.5 #为age自增3.5,传负值表示自减 时间复杂度o(1) getrange key start end #获取字符串制定下标所有的值 时间复杂度o(1) #例 getrange name 1 3 取第1到第3位(从0开始),前闭后闭区间 setrange key index value #从指定index开始设置value值 时间复杂度o(1) #例 setrange name 1 ppp 从第1位开始替换为ppp 例如返回"lpppb666" -incrby 分布式id的生成 -mget mset 批量设置值,取值 (生产环境中尽量少用)
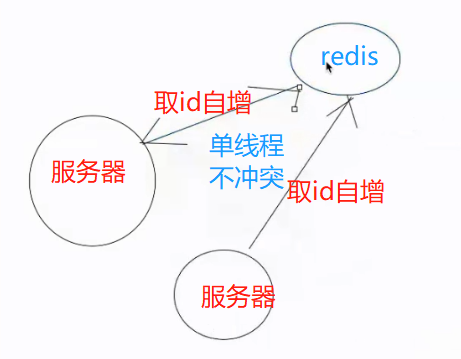 分布式id的生成
分布式id的生成
哈希类型
哈希值结构
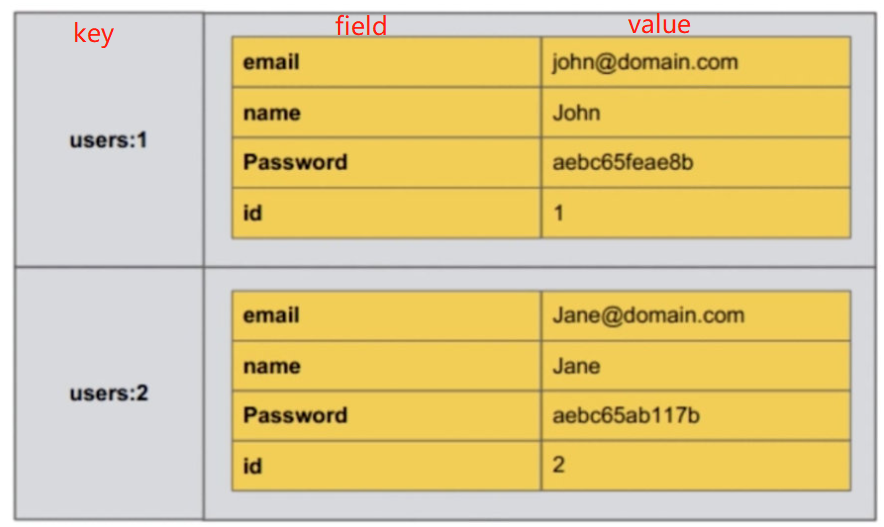
# 5 hash类型
##常用命令 ###1---hget,hset,hdel hget key field #获取hash key对应的field的value 时间复杂度为 o(1) hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1) hdel key field #删除hash key对应的field的值 时间复杂度为 o(1) #测试 hset user:1:info age 23 #使用:分层方便层级查看 hget user:1:info age hset user:1:info name lqz hgetall user:1:info hdel user:1:info age ###2---hexists,hlen hexists key field #判断hash key 是否存在field 时间复杂度为 o(1) hlen key #获取hash key field的数量 时间复杂度为 o(1) hexists user:1:info name hlen user:1:info #返回数量 ###3---hmget,hmset hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n) hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n) ###4--hgetall,hvals,hkeys hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n) hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n) hkeys key #返回hash key对应的所有field 时间复杂度是o(n) ###小心使用hgetall ##1 计算网站每个用户主页的访问量 hincrby user:1:info pageview count #例hincrby user:1:info age 3 #这个key中user代表用户,1代表用户id,info代表用户信息。使用:分层方便软件查看 #另外一般使用这种方法,好处是同一个key下。如果使用incrby key来自增,会导致key很多不方便,并影响效率 ##2 缓存mysql的信息,直接设置hash格式(对比存string类型,key会少一些) hset hget hdel hexists --下方5个都是长慢命令 hmget hmset hgetall 获取所有 #长慢命令,出现卡顿情况。用hscan一点一点取,做生成器。hscan底层生成器实现 hvals 获取所有value值 hkeys 获取所有key值 hincrby user:group { #此处伪代码,hincrby使用情况。 userid1:88 userid2:100 userid3:22 } ####注意:哈希类型只支持一层,里面不能套字典,列表 ##其他操作 hsetnx,hincrby,hincrbyfloat hestnx key field value #设置hash key对应field的value(如果field已存在,则失败),时间复杂度o(1) hincrby key field intCounter #hash key 对英的field的value自增intCounter 时间复杂度o(1) hincrbyfloat key field floatCounter #hincrby 浮点数 时间复杂度o(1)
# 面试官:你在使用redis的时候,有没有要注意的点?-----》拒绝长慢命令
# 在用redis的过程中遇到什么问题?-----》同事写的命令,慢,我去排查,修改hgeall---一次性获取出来 用hscan代替,一点点取,做成生成器
列表类型
# 6 列表类型 -有序队列:从左侧添加,右侧添加,左侧弹出,右侧弹出,可以重复 -实现队列和栈(爬虫深度优先和广度优先[先进先出还是后进后出]) ##插入操作 #rpush 从右侧插入 rpush key value1 value2 ...valueN #时间复杂度为o(1~n) 例rpush ll 1 2 3 #lpush 从左侧插入 #linsert linsert key before|after value newValue #从元素value的前或后插入newValue 时间复杂度o(n) ,需要便利列表 例linsert ll before 2 888 linsert listkey before b java linsert listkey after b php ##删除操作 lpop key #从列表左侧弹出一个item 时间复杂度o(1) rpop key #从列表右侧弹出一个item 时间复杂度o(1) lrem #从指定位置删除 lrem key count value #根据count值,从列表中删除所有value相同的项 时间复杂度o(n) 1 count>0 从左到右,删除最多count个value相等的项 2 count<0 从右向左,删除最多 Math.abs(count)个value相等的项 3 count=0 删除所有value相等的项 lrem listkey 0 a #删除列表中所有值a lrem listkey -1 c #从右侧删除1个c ltrim key start end #按照索引范围修剪列表 o(n) 前后都为闭区间 ltrim ll 1 4 #修剪,只保留下表1-4的元素 ##查询操作 lrange key start end #包含end获取列表指定索引范围所有item o(n) end如果超出范围不报错 lrange listkey 0 2 lrange listkey 1 -1 #获取第一个位置到倒数第一个位置的元素 lindex key index #获取列表指定索引的item o(n) lindex listkey 0 lindex listkey -1 # 获取最后一个 llen key #获取列表长度 ##修改操作 lset key index newValue #设置列表指定索引值为newValue o(n) lset listkey 2 ppp #把第二个位置设为ppp lset ll 1 99 #使用场景 --时间轴:微信朋友圈状态,列表有顺序 -关注的人 列表的key 你的id号[每次关注一个插入一条] ##其他操作 blpop key timeout #lpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1) brpop key timeout #rpop的阻塞版,timeout是阻塞超时时间,timeout=0为拥有不阻塞 o(1) #要实现栈的功能 lpush+lpop # 后进先出 #实现队列功能 lpush+rpop # 先进先出 #固定大小的列表 lpush+ltrim # 插进去修剪下 #消息队列 lpush+brpop # 插入,右侧取的时候是阻塞状态 达到类似celery的效果 # 队列用来干啥? -流量削峰 # 处理能力有限,一点点处理 -解耦 # 本来一个程序,变为go项目给数据到python处理 -异步
集合类型
# 6 集合类型 -无序,不重复(去重),社交相关(交叉并补),同时关注刘亦菲的,你们公共关注的好友 -你关注的人张三 喜欢了linux,python, -你喜欢了linux---》给你推荐python -推荐系统---》通过大数据分析的出来的---》 -上海有个张三,年龄,性别,身高,职业。。。 -跟北京的王五,,年龄,性别,身高,职业。。。都类似 -忽然有一天张三在你们平台上买了绿色短裤(linux的课程) -可以推断出王五也可能喜欢绿色短裤,给王五推 # 基本操作 sadd key element #向集合key添加element(如果element存在,添加失败) o(1) srem key element #从集合中的element移除掉 o(1) scard key #计算集合大小 sismember key element #判断element是否在集合中 srandmember key count #从集合中随机取出count个元素,不会破坏集合中的元素 srandmember key count 从集合中随机取出几个元素(抽奖), -汽车商场(抽奖功能),连续登陆14天---》获得抽奖资格---》7天后开奖---》送个头盔 spop key #从集合中随机弹出一个元素 smembers key 获取集合中所有元素,无序 o(n) # 要小心,可能会阻塞 sdiff user:1:follow user:2:follow #计算user:1:follow和user:2:follow的差集 sinter user:1:follow user:2:follow #计算user:1:follow和user:2:follow的交集 sunion user:1:follow user:2:follow #计算user:1:follow和user:2:follow的并集 sdiff|sinter|suion + store destkey... #将差集,交集,并集结果保存在destkey集合中 # sdiffstore newkey key1 key2 ... # 把key1于key2的差集存入newkey中 # 实战 抽奖系统 :通过spop来弹出用户的id,活动取消,直接删除 点赞,点踩,喜欢等,用户如果点了赞,就把用户id放到该条记录的集合中 # 不会出现重复点的情况 标签:给用户/文章等添加标签,sadd user:1:tags 标签1 标签2 标签3 # 如果交集匹配超过30%就推荐 给标签添加用户,关注该标签的人有哪些 共同好友:集合间的操作
有序集合
# 7 有序集合 ## 特点 #有一个分值字段,来保证顺序 key score value user:ranking 1 lqz user:ranking 99 lqz2 user:ranking 88 lqz3 #集合有序集合 集合:无重复元素,无序,element 有序集合:无重复元素,有序,element+score #列表和有序集合 列表:可以重复,有序,element 有序集合:无重复元素,有序,element+score ### 基本操作 zadd key score element #score(必须有)可以重复,可以多个同时添加,element不能重复 o(logN) # zadd key grade1 member1 grade2 member2 ... zrem key element #删除元素,可以多个同时删除 o(1) zscore key element #获取元素的分数 o(1) zincrby key increScore element #增加或减少元素的分数increScore o(1) zcard key #返回元素总个数 o(1) zrank key element #返回element元素所在的排名(从小到大排) zrange key 0 -1 #返回排名,不带分数 o(log(n)+m) n是元素个数,m是要获取的值 #zrange zset1 0 1获取排名倒数第一与倒数第二 #zrange zset1 -2 -1 获取排名第二与第一 #zrange key start end # 从低到高 #zrevrange key start end # 从高到底 zrange player:rank 0 -1 withscores #返回排名,带分数 zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素 o(log(n)+m) zrangebyscore user:1:ranking 90 210 withscores #获取90分到210分的元素 zcount key minScore maxScore #返回有序集合内在指定分数范围内的个数 o(log(n)+m) zremrangebyrank key start end #删除指定排名内的升序元素 o(log(n)+m) zremrangebyrank user:1:rangking 1 2 #删除升序排名中1到2的元素 zremrangebyscore key minScore maxScore #删除指定分数内的升序元素 o(log(n)+m) zremrangebyscore user:1:ranking 90 210 #删除分数90到210之间的元素 文章阅读数 zincrby key increScore element zcard key 返回排名:过了一天了,管理员登陆到后台,统计一下上新的产品,浏览量(收藏量)排名 zrank key element 管理员统计浏览量在2w到3w之间的商品 zrangebyscore key minScore maxScore -实战:排行榜相关的操作 排行榜:音乐排行榜,销售榜,关注榜,游戏排行榜 ### 其他操作 zrevrank #从高到低排序 zrevrange #从高到低排序取一定范围 zrevrangebyscore #返回指定分数范围内的降序元素 zinterstore #对两个有序集合交集 zunionstore #对两个有序集合求并集 # 面试官:你在使用redis的时候,有没有要注意的点?-----》拒绝长慢命令 # 在用redis的过程中遇到什么问题?-----》同事写的命令,慢,我去排查,修改hgeall---一次性获取出来 用hscan代替,一点点取,做成生成器
| 操作类型 | 命令 |
|---|---|
| 基本操作 | zadd/ zrem/ zcard/ zincrby/ zscore |
| 范围操作 | zrange/ zrangebyscore/ zcount/ zremrangebyrank |
| 集合操作 | zunionstore/ zinterstore |
redis高级用法
慢查询
我们配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询.
慢查询发生在第三阶段
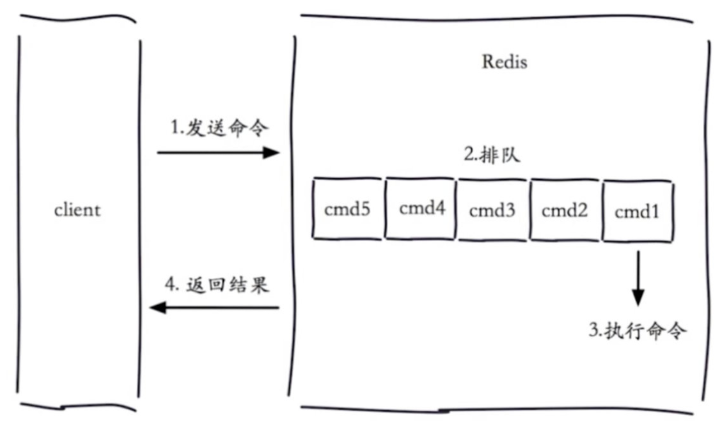
# 1 慢查询优化 一:修改配置问题 slowlog-max-len # 固定长度 # 后面慢的命令会被丢弃 二:通过记录日志,后期分析日志,或者通过命令,定位出哪些命令慢,改掉它 # 慢查询阈值(单位:微秒) (1秒等于1000 000微秒) slowlog-log-slower-than=0 # 超过设定微秒数的命令会被记录下来,如果=0记录所有命令 slowlog-log-slower-than <0,不记录任何命令 面试官问:在使用redis时有没有碰到什么问题? 执行慢了---》通过分析日志,解决掉 celery使用碰到过什么问?redis大家都用---》有的同事写了一些慢命令导致redis阻塞了,导致我的celery项目 执行慢---》清空慢查询的队列
配置方法
1 默认配置
config get slowlog-max-len=128
Config get slowly-log-slower-than=10000
2 修改配置文件重启
3 动态配置
客户端的方式写入,一重启就失效了
# 设置记录所有命令 config set slowlog-log-slower-than 0 # 最多记录100条 config set slowlog-max-len 100 # 持久化到本地配置文件 config rewrite ''' config set slowlog-max-len 1000 config set slowlog-log-slower-than 1000 '''
slowlog get [n] #获取慢查询队列 ''' 日志由4个属性组成: 1)日志的标识id 2)发生的时间戳 3)命令耗时 4)执行的命令和参数 ''' slowlog len #获取慢查询队列长度 slowlog reset #清空慢查询队列,速度就变快了
1 slowlog-max-len 不要设置过大,默认10ms,通常设置1ms 2 slowlog-log-slower-than不要设置过小,通常设置1000左右 3 理解命令生命周期 4 定期持久化慢查询(也就是清理慢查询)
管道
-redis是不支持事务的(网上会说,redis支持事务) -要么都成功要么都失败(断电后面就不执行了)---》mysql通过回滚实现的 -客户端的命令先放到管道中,---》一次性发送到服务端执行---》保证了要么都成功,要么都失败 ### 客户端实现 import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) #创建pipeline pipe = r.pipeline(transaction=True) #开启事务 pipe.multi() pipe.set('name', 'lqz') #其他代码,可能出异常 pipe.set('role', 'nb') pipe.execute() # 把上面的命令一起执行 ### 与原生操作对比 通过pipeline提交的多次命令,在服务端执行的时候,可能会被拆成多次执行,而mget等操作,是一次性执行的,所以,pipeline执行的命令并非原子性的。 但是因为执行速度很快,基本一瞬间完成,除非极端情况(断电等),可能出现有操作未完成 ### 使用建议 1 注意每次pipeline携带的数据量 2 pipeline每次只能作用在一个Redis的节点上 3 M(mset,mget....)操作和pipeline的区别
# 使用场景 转账的人特别多。先把转账的人数据拿到redis中,张三减,李四加。然后做定时任务,把数据再同步到mysql中去
发布订阅
发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息)
模型

publish souhu:tv "hello world" # 发布命令 subscribe souhu:tv # 订阅频道 订阅之后,再在这个频道上发布消息,只要订阅了,都能收到
 发布者
发布者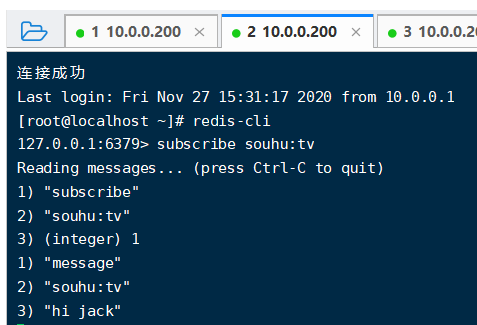 订阅者
订阅者
publish channel message #发布命令 publish souhu:tv "hello world" #在souhu:tv频道发布一条hello world 返回订阅者个数 subscribe [channel] #订阅命令,可以订阅一个或多个 subscribe souhu:tv #订阅sohu:tv频道 unsubscribe [channel] #取消订阅一个或多个频道(需要在代码中进行使用,客户端连上无法退出) unsubscribe sohu:tv #取消订阅sohu:tv频道 psubscribe [pattern...] #订阅模式匹配 订阅多个频道 psubscribe c* #订阅以c开头的频道 unpsubscribe [pattern...] #按模式退订指定频道 pubsub channels #列出至少有一个订阅者的频道,列出活跃的频道 pubsub numsub [channel...] #列出给定频道的订阅者数量 pubsub numpat #列出被订阅模式的数量
--发布订阅和消息队列的区别? 发布订阅数全收到,消息队列有个抢的过程,只有一个抢到 微信公众号订阅:公众号发了一篇文章,只要订阅了的,都可以收到更新。属于主动发送,不算这里说的发布订阅(发布订阅模式,观察者模式) -自己实现的,写了新文章,主动给所有订阅的用户推送 设计模式:单例模式,工厂模式; 观察者模式,代理模式(flask源码部分,request对象,用的是代理模式),迭代器模式
Bitmap位图(本质是字符串)

# 4 bitmap 位图(字符串) ## 相关命令 set hello big #放入key位hello 值为big的字符串 getbit hello 0 #取位图的第0个位置,返回0 getbit hello 1 #取位图的第1个位置,返回1 如上图 ##我们可以直接操纵位 setbit key offset value #给位图指定索引设置值 setbit hello 7 1 #把hello的第7个位置设为1 这样,big就变成了cig setbit test 50 1 #test不存在,在key为test的value的第50位设为1,那其他位都以0补 # getbit test 1 #返回0 # getbit test 2 #返回0 # getbit test 50 #返回1 bitcount key [start end] #获取位图指定范围(start到end,单位为字节,注意按字节一个字节8个bit为,如果不指定就是获取全部)位值为1的个数 bitop op destkey key [key...] #做多个Bitmap的and(交集)/or(并集)/not(非)/xor(异或),操作并将结果保存在destkey中 bitop and after_lqz lqz lqz2 #把lqz和lqz2按位与操作,放到after_lqz中 bitpos key targetBit start end #计算位图指定范围(start到end,单位为字节,如果不指定是获取全部)第一个偏移量对应的值等于targetBit的位置 bitpos lqz 1 #big 对应位图中第一个1的位置,在第二个位置上,由于从0开始返回1 bitpos lqz 0 #big 对应位图中第一个0的位置,在第一个位置上,由于从0开始返回0 bitpos lqz 1 1 2 #返回9:返回从第一个字节到第二个字节之间 第一个1的位置,看上图,为9
### 使用场景: 独立用户统计 1 使用set和Bitmap对比 2 1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量)
| 数据类型 | 每个userid占用空间 | 需要存储用户量 | 全部内存量 |
|---|---|---|---|
| set | 32位(假设userid是整形,占32位) | 5千万 | 32位*5千万=200MB |
| bitmap | 1位 | 1亿 | 1位*1亿=12.5MB |
### 总结 1 位图类型是string类型,最大512M (1亿才12.5MB,绝对够了) 2 使用setbit时偏移量如果过大,会有较大消耗(setbit 1,2没问题。如果是1亿,10亿会有点慢) 3 位图不是绝对好用,需要合理使用 4 和布隆过滤器比较,因为布隆过滤器是经过运算取点,会比bitmap的方法更省空间
HyperLogLog(日活统计) 几百人集合就行
基于HyperLogLog算法:极小的空间完成独立数量统计(比位图占的空间还要小)
本质还是字符串
## 三个命令 pfadd key element #向hyperloglog添加元素,可以同时添加多个 pfcount key #计算hyperloglog的独立总数 pfmerge destroy sourcekey1 sourcekey2#合并多个hyperloglog,把sourcekey1和sourcekey2合并为destroy pfadd uuids "uuid1" "uuid2" "uuid3" "uuid4" #向uuids中添加4个uuid pfcount uuids #返回4 pfadd uuids "uuid1" "uuid5"#有一个之前存在了,其实只把uuid5添加了,去重 pfcount uuids #返回5 pfadd uuids1 "uuid1" "uuid2" "uuid3" "uuid4" pfadd uuids2 "uuid3" "uuid4" "uuid5" "uuid6" pfmerge uuidsall uuids1 uuids2 #合并 pfcount uuidsall #统计个数 返回6 ## 内存消耗&总结 百万级别独立用户统计,百万条数据只占15k 错误率 0.81% 无法取出单条数据,只能统计个数 当时在做日活统计功能的时候,专门去调研了,想用HyperLogLog,发现没多少用户,直接用了集合,后期如果用户量增大,再用HyperLogLog (日活几百人,用集合就可以了) 问题:日活5000左右,但是将阿里云的带宽200m全占满了,有什么解决方案 收获:5000用户---》同时在访问你---》程序没有及时的响应回来(异步[尽量快速把请求处理完,mysql做主从],cdn) 服务降级,熔断,api网关
