

Elasticsearch5 Python操作Elasticsearch, es集成到django中, saas介绍, mysql和Elasticsearch同步数据(开源插件go-mysql-elasticsearch),haystack的使用
# 第一种使用方式 (推荐使用,简单) # 官方提供的:Elasticsearch # pip install elasticsearch # GUI:pyhon能做图形化界面编程吗? -Tkinter -pyqt # 使用(查询是重点) # pip3 install elasticsearch https://github.com/elastic/elasticsearch-py # 更高级的用法文档里搜 from elasticsearch import Elasticsearch obj = Elasticsearch(['127.0.0.1:9200','192.168.1.1:9200','192.168.1.2:9200'],) # 创建索引(Index) # body:用来干什么?mapping:{},setting:{} body不写为默认 # result = obj.indices.create(index='user',body={'userid':'1','username':'lqz'},ignore=400) result = obj.indices.create(index='user',ignore=400) #indices索引的意思,index索引名 # ignore忽略某些http错误状态码 print(result) # {'acknowledged': True, 'shards_acknowledged': True, 'index': 'user'} # 删除索引 result = obj.indices.delete(index='user', ignore=[400, 404]) print(result) # {'acknowledged': True} # 插入和查询数据(文档的增删查改),是最重要 # 插入数据 # POST news/politics/1 # {'userid': '1', 'username': 'lqz','password':'123'} data = {'userid': '1', 'username': 'lqz','password':'123'} result = obj.create(index='news', doc_type='politics', id=1, body=data) print(result) # {'_index': 'news', '_type': 'politics', '_id': '1',... # 更新数据 相当于增量式修改(数据要包在doc中,用的最多) ''' 不用doc包裹会报错 ActionRequestValidationException[Validation Failed: 1: script or doc is missing ''' data ={'doc':{'userid': '1', 'username': 'lqz','password':'123ee','test':'test'}} result = obj.update(index='news', doc_type='politics', body=data, id=1) print(result) # {'_index': 'news', '_type': 'politics', '_id': '1'... # 删除数据 索引还在,数据没了 result = obj.delete(index='news', doc_type='politics', id=1) # {'_index': 'news', '_type': 'politics', '_id': '1'... # 查询 # 查找所有文档 # query = {'query': {'match_all': {}}} # 查找名字叫做jack的所有文档 # query = {'query': {'match': {'desc': '娇憨可爱'}}} # query = {'query': {'term': {'from': 'sheng'}}} query = {'query': {'term': {'name': '娘子'}}} # term和match的区别 # term是短语查询,不会对term的东西进行分词 # match 会多match的东西进行分词,再去查询 # 查找年龄大于11的所有文档 # allDoc = obj.search(index='lqz', doc_type='doc', body=query) allDoc = obj.search(index='lqz', doc_type='doc', body=query) print(allDoc) import json print(json.dumps(allDoc)) # print(allDoc['hits']['hits'][0]['_source'])
es集成到django中
# 如何集成到django项目中:创建索引,提前创建好就行了 # 插入数据,查询数据,修改数据 query = {'query': {'term': {'name': '娘子'}}} allDoc = obj.search(index='lqz', doc_type='doc', body=query) # json格式直接返回(不管是前后端分离还是不分离,让前端自己渲染)
saas介绍
# saas :软件即服务,不是用人家服务,而是写服务给别人用----》正常的开发 # 舆情监测系统:(爬虫) # 只监控微博---》宜家:微博,百度贴吧,上市公司 # 公安:负面的,---》追踪到哪个用户发的---》找上门了 # qq群,微信群----》舆情监控(第三方做不了,腾讯出的舆情监控,第三方机构跟腾讯合作,腾讯提供接口,第三方公司做) # 平台开发出来,别人买服务---》买一年的微博关键字监控 ERP:公司财务,供应链 某个大公司,金蝶,用友,开发了软件----》你们公司自己买服务器---》软件跑在你服务器上 saas模式:公司买服务,10年服务----》账号密码---》登进去就能操作---》出了问题找用友---》服务器在别人那---》政务云,各种云---所有东西上云 ---政府花钱买的东西---》用友敢泄露吗? ---未来的云计算---》只能能上网---》计算机运算能力有限---》上云买服务---》计算1+。。。+100 ---》买了计算服务,直接拿到结果
第二种方式
# 第二种使用方式 (建议使用上面第一种方式,是官方的,简单) # https://github.com/elastic/elasticsearch-dsl-py # 更高级的用法文档里搜 # pip3 install elasticsearch-dsl from datetime import datetime from elasticsearch_dsl import Document, Date, Nested, Boolean,analyzer, InnerDoc, Completion, Keyword, Text,Integer from elasticsearch_dsl.connections import connections connections.create_connection(hosts=["localhost"]) class Article(Document): # 分词器是ik_max_word类型,'title'字段是Keyword类型 title = Text(analyzer='ik_max_word', search_analyzer="ik_max_word", fields={'title': Keyword()}) author = Text() class Index: name = 'myindex' # 索引名 def save(self, ** kwargs): # save方法 return super(Article, self).save(** kwargs) if __name__ == '__main__': Article.init() # 创建映射 创建索引
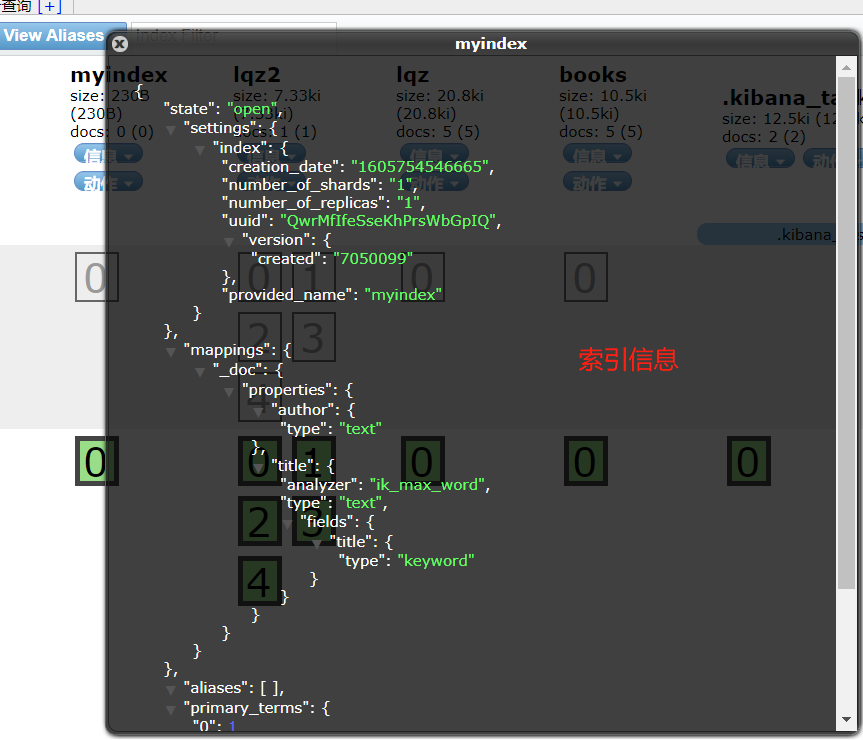
保存数据
if __name__ == '__main__': # Article.init() # 创建索引 # 保存数据 article = Article() article.title = '测试数据' article.author = 'egon' article.save() # 数据就保存好了
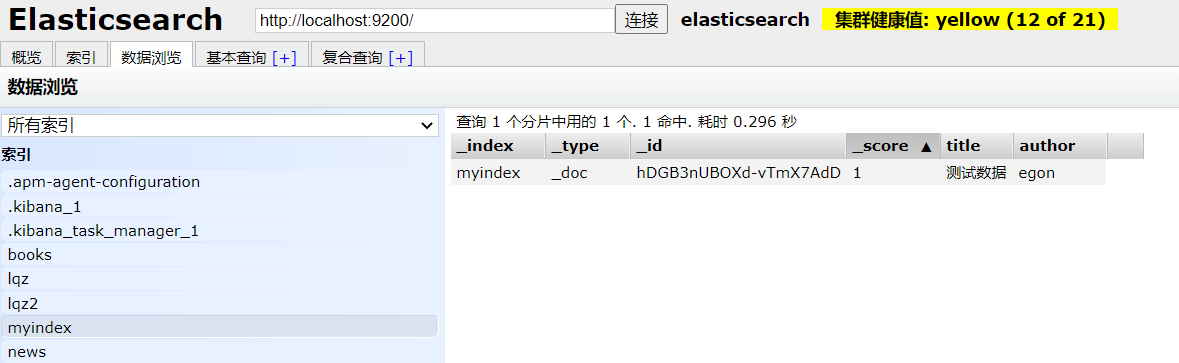
查询数据
if __name__ == '__main__': # 之前Article对象又保存了一组数据 #查询数据 s=Article.search() # s = s.filter('match',title='测试',author="egon") # 这是and查询。想要用与或非查询用q查询,查看elasticsearch_dsl文档 s = s.filter('match', title="测试") results = s.execute() # 返回对象列表,可以转为json格式返回 # # 类比queryset对象,列表中一个个对象 # # es中叫Response,当成一个列表,列表中放一个个对象 print(results) # <Response: [Article(index='myindex', id='hDGB3nUBOXd-vTmX7AdD'), Article(index='myindex', id='hTGN3nUBOXd-vTmXYQeJ')]>
修改数据,删除数据
if __name__ == '__main__': #删除数据 s = Article.search() s = s.filter('match', title="测试").delete() #修改数据 (先查后改) s = Article().search() s = s.filter('match', title="测试") results = s.execute() print(results[0]) # Article(index='myindex', id='hDGB3nUBOXd-vTmX7AdD') results[0].title="xxx" results[0].save() # 其他操作,参见文档
mysql和Elasticsearch同步数据
# 只要article表插入一条数据,就自动同步到es中 # 第一种方案: -每当aritcle表插入一条数据(视图类中,Article.objects.create(),update) -往es中插入一条 -缺陷:代码耦合度高,改好多地方 # 第二种方案: -重写create方法,重写update方法 -缺陷:同步操作---》es中插入必须返回结果才能继续往下走 # 第三种方案: -用celery,做异步 -缺陷:引入celery,还得有消息队列。。。 # 第四种方案:(用的最多) -重写create方法,重写update方法,用信号存入,异步操作 -缺陷:有代码侵入
开源插件go-mysql-elasticsearch
# 第五种方案:(项目不写代码,自动同步),第三方开源的插件 -https://github.com/siddontang/go-mysql-elasticsearch----go写 -你可以用python重写一个,放到git上给别人用(读了mysql的日志。原理:监控日志文件,如有变化存到es中) -跟平台无关,跟语言无关 -如何使用: -源码下载---》交叉编译---》可执行文件--》运行起来--》配置文件配好,就完事了
下载完,放入gopath下src路径下。可以参照github说明,在当前项目目录下敲make命令,使用已经写好的Makefile文件。也可以直接敲
go build -o bin/go-mysql-elasticsearch ./cmd/go-mysql-elasticsearch
进行编译。把文件编译到bin/go-mysql-elasticsearch中。
注意:我执行的时候,提示报错如下

代表:被墙了,直接在命令行执行走代理。
go env -w GOPROXY=https://goproxy.cn
就可以正常从外网下载组件进行编译

注意:在windows系统下,需要将go-mysql-elasticsearch加上后缀名.exe,才能在命令行中输入运行。下图提示需要配置./etc/river.toml配置文件

# 配置文件 [[source]] schema = "数据库名" tables = ["article"] #tables = ["test_river_[0-9]{4}"]可以使用正则配对,例[app01_.*?] [[rule]] schema = "数据库名" # mysql配置 table = "表名" index = "索引名" # es配置 type = "类型名"
# 缺陷: -es跟mysql同步时,不希望把表所有字段都同步,mysql的多个表对着es的一个类型 # 话术升级: -一开始同步 -用了开源插件(读取mysql日志,连接上es,进行同步) -用信号自己写的 -再高端:仿着他的逻辑,用python自己写的,----》(把这个东西开源出来)
维护不太好,官方文档好多不支持了。建议自己用信号写,如果使用haystack要学很多东西
# django上的一个第三方模块 ---》你使用过的django第三方模块有哪些? # 可以在django上实现全文检索 # 相当于orm--》对接es,solr,whoosh # 具体使用步骤参考下方网站 https://www.cnblogs.com/xiaoyuanqujing/articles/11803376.html #第四步settings配置文件中,HAYSTACK_CONNECTIONS={'default':{...'URL':}}此处如果是集群只要改为列表,里面地址即可
(HAYSTACK_SIGNAL_PROCESSOR=...本质上使用信号实现,模块封装好了) # 第七步一开始需要手动输入同步,后面因为第四步配了自动同步,不用再手动同步了 # 不支持es,6以上版本 (因为es6以上改为一个索引下只能有一个类型) # haystack+Elasticsearch实现全文检索 # es的原生操作:ELasticsearch Elasticsearch-dsl
