6. Calcite添加自定义函数
1. 简介
在上篇博文中介绍了如何使用calcite进行sql验证, 但是真正在实际生产环境中我们可能需要使用到
- 用户自定义函数(UDF): 通过代码实现对应的函数逻辑并注册给calcite
- sql验证: 将UDF信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: calcite通过调用UDF逻辑实现函数逻辑
- sql验证: 将UDF信息注册给calcite,
- 自定义db函数: 数据库中创建的自定义函数
- sql验证: 将自定义的db函数信息注册给calcite,
SqlValidator.validator验证阶段即可通过验证 - sql执行: 下推到db执行对应的db函数
- sql验证: 将自定义的db函数信息注册给calcite,
此时我们需要将自定义的函数注册到calcite中, 用于sql验证和执行. 例如注册一个简单的函数 如: 将数据库中的性别字段值做字典转换.
2. Maven
2. UDF
如上述所说, UDF是将用户自定义的方法注册为函数使用的, 首先看一下calcite是如何注册UDF的
SchemaPlus#add(String name, Function function);
其Function的实现类如下:
-
定义UDF实现
public class Udf { public static String dictSex(String code) { if (StringUtils.isBlank(code)) { return code; } if (StringUtils.equals(code, "1")) { return "男"; } else if (StringUtils.equals(code, "2")) { return "女"; } else { return "未知"; } } } -
把
dictSex方法注册到calcite中, 因为上述的方法输入返回的都是单一值, 所以直接注册为标量函数即可(如果是聚合函数可以使用AggregateFunction)// 指定函数名称 和 对应函数的class & method name rootSchema.add("dict_sex", ScalarFunctionImpl.create(Udf.class, "dictSex")); -
测试执行
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`"); printResultSet(resultSet); 表数据如下
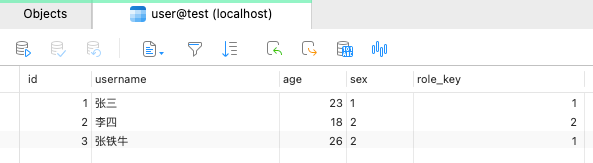
输出结果
c.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2 c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛}
3. 自定义db函数
首先 我们定义一个db 函数实现字典值的转换
验证函数功能

ok, 函数创建完成, 我们将函数注册到calcite中
calcite中sqlfunction有很多其已经实现的类, 我们这里使用SqlBasicFunction来创建我们的函数
-
定义SqlFunction
/* * SqlBasicFunction create(String name, SqlReturnTypeInference returnTypeInference, SqlOperandTypeChecker operandTypeChecker) * name: 函数名称 * returnTypeInference: 返回值类型 * operandTypeChecker: 函数入参的校验器 */ SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER)); -
注册SqlFunction
从上篇博文中我们知道, calcite的sql函数都注册到了
SqlStdOperatorTable类中, 所以我们只需要将自定义的函数注册进即可final SqlStdOperatorTable sqlStdOperatorTable = SqlStdOperatorTable.instance(); sqlStdOperatorTable.register(DICT_SEX); 对, 就这么简单. 因为
SqlStdOperatorTable类是单例模式, 所以我们可以随时随地的进行注册, 其验证逻辑就可以直接调用了当然, 看了其他博客大多数都是继承
SqlStdOperatorTable类实现自定义SqlStdOperatorTable的 如下, 最后使用自己的SqlStdOperatorTable即可public static class SqlCustomOperatorTable extends SqlStdOperatorTable { private static SqlCustomOperatorTable instance; // 只需要申明为成员变量即可, instance.init() 的时候会反射取变量进行注册 public static final SqlFunction DICT_SEX = SqlBasicFunction.create("dict_sex", ReturnTypes.VARCHAR, OperandTypes.family(SqlTypeFamily.CHARACTER)); public static synchronized SqlCustomOperatorTable instance() { if (instance == null) { instance = new SqlCustomOperatorTable(); instance.init(); } return instance; } /** * 如果想修改获取函数的过程, 可以重写此方法 */ @Override protected void lookUpOperators(String name, boolean caseSensitive, Consumer<SqlOperator> consumer) { super.lookUpOperators(name, caseSensitive, consumer); } } -
测试执行
final ResultSet resultSet = statement.executeQuery("SELECT username, dict_sex(sex) sex_name FROM `user`"); printResultSet(resultSet); 输出结果
c.l.c.CalciteFuncTest - [printResultSet,86] - Number of columns: 2 c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=男, username=张三} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=李四} c.l.c.CalciteFuncTest - [printResultSet,98] - {sex_name=女, username=张铁牛} 经测试: 如果udf 和 sqlfunction 同时存在的时候 优先使用udf
4. 完整代码
4.1 udf
4.2 db func
__EOF__

本文作者:张铁牛
本文链接:https://www.cnblogs.com/ludangxin/p/18751135.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/ludangxin/p/18751135.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!

« 上一篇: 5. 想在代码中验证sql的正确性?

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)