Java-基础-HashMap
1. 简介
Java8 HashMap结构(数组 + 列表 + 红黑树)如图:
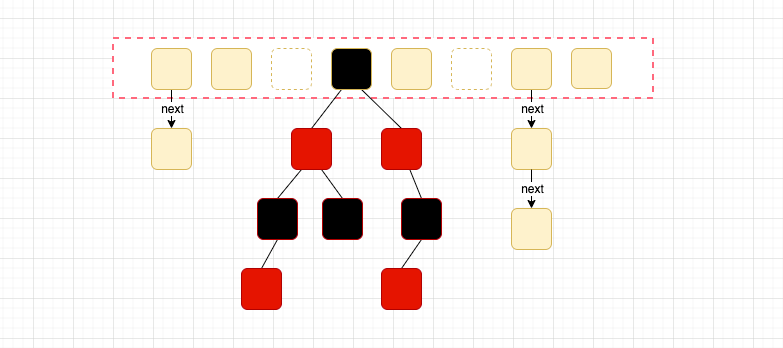
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
2. 定义
2.1 主要属性
2.2 构造方法
HashMap共有三个构造函数:
初始化一个默认容量=16,负载因子=0.75 的hashmap对象。
初始化一个指定初始容量和负载因子=0.75 的hashmap对象。
初始化一个指定初始容量和负载因子 的HashMap对象。
2.3 node
Node是HashMap的静态内部类,HashMap主干是一个Node数组,Node是HashMap的最基本组成单位。
3. 初始容量 负载因子
上文中反复提到了两个参数:初始容量,负载因子。这两个参数是影响HashMap性能的重要参数。
容量:transient Node<K,V>[] table; 即 table的长度,初始容量是创建哈希表时的容量 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 即初始容量为 16。
负载因子: final float loadFactor; 容器进行初始化的时候会将值设置为0.75 ( 也就是初始可用的容量为:16 * 0.75 = 12,当容量达到12的时候就会进行扩容操作),负载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间使用程度,负载因子越大表示散列表的装填程度越高,反之越小。
为什么说 容量 和 负载因子 会影响 HashMap的性能?
我们在考虑HashMap的时候,首先要想到HashMap只是一个数据结构,既然是数据结构最主要的就是节省时间和空间。负载因子的作用肯定是节省时间和空间。为什么节省呢?
-
假设 负载因子 = 1.0
HashMap是将key进行hash运算得到桶的位置(table的索引)的。既然是hash运算,那么Hash冲突是避免不了的。当负载因子是1.0的时候,意味着会出现大量的Hash冲突(因为要将整个table填满,并且为了将数均匀填充,jdk还使用了扰动函数,增加随机性),底层的红黑树会变的异常复杂。对查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。
-
假设 负载因子 = 0.5
负载因子是0.5的时候,也就意味着,当数组中的元素达到了一半就开始扩容,既然填充的元素好了,Hash冲突也会减少,那么底层的链表或者红黑树的高度就会降低。查询效率就会增加。但是,这时候空间利用率就会大大降低,显然也不太好。
总结:
默认容量 = 16,负载因子 = 0.75,这两个常量的值都是经过大量的计算和统计得出来的最优解。
当然 如果知道自己的hashmap容量大小,尽量在初始化的时候就指定一下,可以避免扩容带来的性能损耗。但负载因子就别随意改了,毕竟是最优解。
4. 添加元素
put方法是一个重点方法,这里有hashmap的初始化,数据的在hashmap中是如何存储的,什么情况下会转换成红黑树等。
hash方法 扰动函数
看到了熟悉的hashCode,这就解释了为什么重写equals方法的时候,一定要重写hashCode方法,因为key是基于hashCode来处理的。
为什么 获取了key的hashcode() 返回的int型的散列值还要异或(^)h >>> 16 呢? 有什么用?
实质上是把一个数的低16位与它的高16位做异或运算,混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。
那为什么要增加低16位的随机性呢?
根本目的是为了增加 散列表的装填程度,为了使数据分布的更均匀。
因为在找key的位置tab[i = (n - 1) & hash]),是通过(n - 1) & hash 计算索引位置的,而当n的长度不够大时,只和hashCode()的低16位有关。
这样做有几个好处:
- &运算速度快,至少比%取模运算快
- 能保证 索引值 肯定在 capacity 中,不会超出数组长度
- ( n -1) & hash,当n为2次幂时,会满足一个公式:
(n -1) & hash = hash % n

5. 扩容方法
扩容的三种情况:
- 使用默认构造方法初始化HashMap。从前文可以知道HashMap在一开始初始化的时候会返回一个空的table,并且thershold为0。因此第一次扩容的容量为默认值DEFAULT_INITIAL_CAPACITY也就是16。同时threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR = 12。
- 指定初始容量的构造方法初始化HashMap。那么从下面源码可以看到初始容量会等于threshold,接着threshold = 当前的容量(threshold) * DEFAULT_LOAD_FACTOR。
- HashMap不是第一次扩容。如果HashMap已经扩容过的话,那么每次table的容量以及threshold量为原有的两倍
这边也可以引申到一个问题就是HashMap是先插入数据再进行扩容的,但是如果是刚刚初始化容器的时候是先扩容再插入数据。
5.1 扩容部分
5.2 复制数据部分
__EOF__

本文链接:https://www.cnblogs.com/ludangxin/p/15526375.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?