random:Python随机数的生成与应用
前言
在实际的开发中,经常会用到随机数生成。而random库专用于随机数的生成,它是基于Mersenne Twister算法提供了一个快速伪随机数生成器。
本篇,将详细讲解各种场景之下随机数的生成应用。
生成随机数
对于随机数的生成,random库提供了很多函数,有的负责生成浮点数,有的负责生成整型,还有的可以生成区间内的随机数等。
| 函数名 | 参数 | 意义 |
|---|---|---|
| random | 无参数 | 随机生成[0-1]之间浮点数 |
| uniform | 2个整型参数:最小数,最大数 | 随机生成最小最大之间的浮点数 |
| randint | 2个整型参数:最小数,最大数 | 随机生成最小最大之间的整数 |
| randrange | 3个整型参数:最小数,最大数,步长 | 随机生成最小最大之间的间隔步长整数 |
下面,我们来看看这些常用的随机数生成函数的应用:
import random
# 随机生成[0-1]之间浮点数
print("%04.2f" % random.random())
# 随机生成浮点数
print("%04.2f" % random.uniform(100, 200))
# 随机生成整型
print(random.randint(1, 200))
# 随机生成整型
print(random.randrange(0, 200, 5))
运行之后,效果如下:
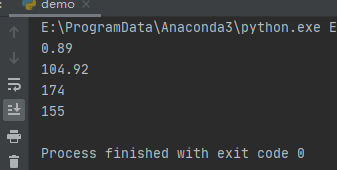
以上是最常用的,也是最普遍的随机数用法。
种子
不知道读者发现没有,通过上面这些方法虽然能生成随机数,但是随机数都是无序的。这次你运行可能开头是一个数,结尾是一个数,下次运行开头和结尾又会不一样。这对于需要固定序列的随机数需求而言,显然不合适。
所以,random库给我们提供了种子函数:random.seed()。种子会控制由公式生成的第一个值,由于公式是确定的,所以每次只要种子相同,随机数每次生成的序列值就相同。
import random
random.seed(1)
# 随机生成浮点数
print("%04.2f" % random.random())
# 随机生成浮点数
print("%04.2f" % random.uniform(100, 200))
# 随机生成整型
print(random.randint(1, 200))
# 随机生成整型
print(random.randrange(0, 200, 5))
多次运行上面这段代码,你会发现每次随机数都是一样的。
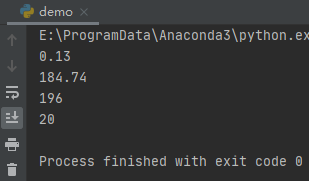
random.sample
博主经常编写刷评论的脚本,但是对于爬虫来说,有一个与众不同的随机数需求。比如,我要评论20个网页,那么将20个网页放在数组中,就会有(0,19)索引进行选择。如果用平常的区间随机数,那么可能会漏掉一些值,意味着也会漏掉一些网页没有评论。
这个时候,博主肯定期望生成一个(0,19)区间的随机数样本,且不重复。保证一个轮回评论完成之后,没有一个网页漏掉。那么这种需求用random库如何操作呢?
当然,小标题已经给出答案了,可以使用random.sample()函数:
import random
print(random.sample(range(0, 20), 20))
运行之后,效果如下:

random.sample第1个参数是一个区间数组,比如随机数在(0,19),那么第1个参数就是range(0,19);第2个是生成多少不重复的随机数,这里需要全部网页都能评论到,所以生成20个随机数。可以看到上面所有随机数都不重复,且都在区间而且唯一。(该函数还可以用于扑克牌的发放,感兴趣的读者,可以自己写写代码熟练掌握)
随机元素
在概率统计中,我们经常使用随机数进行预测概率,比如一枚硬币正面朝上的概率是多少等等。这种求概率的随机元素操作,如果通过随机数实现呢?
答案是random.choice()函数,它可以从一个序列中随机选择元素。比如这里我们来抛硬币10000次,看看各面朝上的概率是多少。具体代码如下:
import random
coin_pro = {
'heads': 0,
'tails': 0,
}
coin = ['heads', 'tails']
for i in range(10000):
coin_pro[random.choice(coin)] += 1
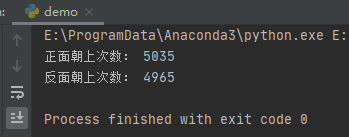
print("正面朝上次数:", coin_pro['heads'])
print("反面朝上次数:", coin_pro['tails'])
运行之后,我们会得到次数,从而也可以计算概率。
SystemRandom
random库下还有一个SystemRandom类,该类产生的系列是不可再生的,因为其随机性跟随系统,而不是来自软件自身。
我们先来看一段代码:
import random
import time
r1 = random.SystemRandom()
print(r1.random())
seed = time.time()
r1 = random.SystemRandom(seed)
print(r1.random())
运行之后,效果如下:
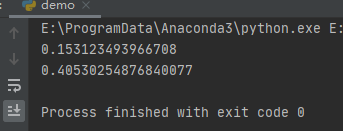
你可以简单的把SystemRandom理解为该随机数的生成因子是系统时间,根据系统时间因子生成的随机数。(只是做一个类比),也就是上面seed因子根本不起作用,它只用系统的随机种子。
非均匀分布
使用numpy库的读者,应该会经常用到该库生成一些正态分布的值。同样的,random随机数库也提供了这些分布的函数用于进行科学计算的应用。下面,我们来分别讲解这些随机数如何生成。
| 函数 | 意义 |
|---|---|
| betavariate() | 根据Beta分布返回一个介于0和1之间的随机浮点数(用于统计信息) |
| expovariate() | 根据指数分布(用于统计信息),返回一个介于0和1之间或如果介于0和-1之间的随机浮点数(如果参数为负) |
| gammavariate() | 根据Gamma分布返回一个介于0和1之间的随机浮点数(用于统计信息) |
| gauss() | 根据高斯分布(在概率论中使用)返回介于0和1之间的随机浮点数 |
| lognormvariate() | 根据对数正态分布(用于概率论),返回介于0和1之间的随机浮点数 |
| normalvariate() | 根据正态分布(在概率论中使用)返回介于0和1之间的随机浮点数 |
| vonmisesvariate() | 根据von Mises分布返回0到1之间的一个随机浮点数(用于定向统计) |
| paretovariate() | 根据帕累托分布(在概率论中使用)返回介于0和1之间的随机浮点数 |
| weibullvariate() | 根据Weibull分布返回0到1之间的随机浮点数(用于统计信息) |
正态分布
random库中提供了函数normalvariate()和gauss()生成正态分布随机数(高斯分布)。当然还有一个函数lognormvariate()也可以生成正态分布,不过它生成的正态分布适用于多个不交互随机变量的积。
import random
for i in range(2):
print(random.normalvariate(0, 1))
for i in range(2):
print(random.gauss(0, 1))
运行之后,效果如下:
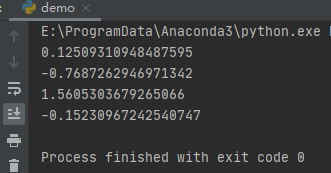
以上都有2个参数:平均值与协方差。平均值是N维空间中的一个坐标,表示样本最有可能产生的位置。这类似于一维或单变量正态分布的钟形曲线的峰值。协方差表示两个变量一起变化的水平。
近似分布
三角分布(triangular distribution),亦称辛普森分布或三角形分布。在概率论与统计学中,三角形分布是低限为a、众数为c、上限为b的连续概率分布。
triangular()方法返回两个指定数字(包括两者)之间的随机浮点数,但是您也可以指定第三个参数,即mode 参数。mode参数使您有机会权衡可能的结果,使其更接近其他两个参数值之一。mode参数默认为其他两个参数值之间的中点,它将不会权衡任何方向的可能结果。
import random
print(random.triangular(20, 60, 30))
运行之后,效果如下:
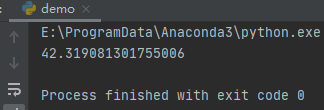
其他函数感兴趣的可以自行研究。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号