

中间件 - redis
官网链接:https://redis.io/
首先简单理解一下
1、什么是redis
redis 是一种开源的、内存中数据结构存储,用作数据库、缓存和消息代理。
redis 数据结构包含五大数据类型:字符串、散列、列表、集合、带范围查询的排序集合
以及三大特殊数据类型:位图、超级日志、地理空间索引。
redis 内置复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久化,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。
redis 是单线程,基于内存操作,cpu不是性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线程来实现,所以就使用单线程。
redis由C语言编写,不比Mamecache差
说道单线程,这里有两个误区:
1、高性能的服务器一定是多线程的?
2、多线程(CPU上下文会切换)一定比单线程效率高?
核心:redis 是将所有的数据存放 到内存中,所以说用单线程是效率最高的,因为多线程之间CPU上下文切换,是一个耗时的操作,对于内存系统来说,没有数据上下文切换,效率就是最高的,多次读写都是在一个CPU上的,在内存情况下,单线程就是最优的方案
2、如何在项目中使用redis
第一种:原生 Jedis
1、什么是jedis?
jedis就是集成了redis的一些命令操作,封装了redis的java客户端。提供了连接池管理。一般不直接使用jedis,而是在其上在封装一层,作为业务的使用
2、导入jedis的maven依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.6.0</version> </dependency>
3、使用测试
注:需要开启本地的redis服务
ping :是否连接上redis服务
package com.cai; import redis.clients.jedis.Jedis; public class TestPing { public static void main(String[] args) { // 实例化 jedis
// 无参构造方法会自动链接本地的redis服务,也就是说如果连接的是本地的redis服务,则可以不用写地址和端口号 Jedis jedis = new Jedis("127.0.0.1",6379); // ping ,如果返回pong 就代表链接成功 System.out.println(jedis.ping()); } }
运行响应
PONG
Process finished with exit code 0
返回 PONG 说明redis服务连接上了,就可以后续的命令操作
五大基本类型
① string(字符串)
package com.redis.basicType; import redis.clients.jedis.Jedis; import java.util.Set; // 字符串类型 public class TpeString { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); // 数据库的大小 System.out.println(jedis.dbSize()); // 切换数据库 jedis.select(2); // 设置字符串 System.out.println("设置了key:ey1->value:value1:"+jedis.set("key1", "value1")); // 获取字符串 key System.out.println("get ke1:"+jedis.get("key1")); System.out.println("当前数据库中所有的key数量:"+jedis.dbSize()); // 清空所有数据库 jedis.flushAll(); // 清空当前数据库 jedis.flushDB(); System.out.println("设置了key:name->value:test:"+jedis.set("name","test")); System.out.println("设置了key:name1->value:张三:"+jedis.set("name1","张三")); System.out.println("设置了key:name2->value:李四:"+jedis.set("name2","李四")); // 获取当前数据库下所有的key Set<String> keys = jedis.keys("*"); System.out.println("获取当前数据库中所有的key:"+keys); // 判断是否存在 System.out.println("key->name 是否存在"+jedis.exists("name")); // 删除某个key System.out.println("删除了键name:"+jedis.del("name")); // 判断是否存在 System.out.println("key->name 是否存在"+jedis.exists("name")); // 设置key的过期时间,10s之后 System.out.println("设置name的过期时间为10s后:"+jedis.expire("name", 10)); // 获取key的剩余时间 System.out.println("key->name 剩余时间"+jedis.ttl("name")); // 查看key的类型 System.out.println("key->name 类型"+jedis.type("name")); // 向 value值后面追加 jedis.append("name","追加"); // 追加之后的 System.out.println("追加之后的值:"+jedis.get("name")); // 获取value的长度 Long length = jedis.strlen("name"); System.out.println("name的value长度"+length); // 追加的key如果不存在,则新增 jedis.append("name2","张三"); // 设置一个数字类型 jedis.set("number", "100"); System.out.println("起始number:"+jedis.get("name")); // 递增1 jedis.incr("number"); System.out.println("递增number:"+jedis.get("number")); // 递减1 jedis.decr("number"); System.out.println("递减number:"+jedis.get("number")); // 递增指定值 jedis.incrBy("number",10); System.out.println("递增10 number:"+jedis.get("number")); // 递减指定值 jedis.decrBy("number",5); System.out.println("递减10 number:"+jedis.get("number")); jedis.flushDB(); jedis.set("key1","三生三世十里桃花"); System.out.println("设置key1的值为:"+jedis.get("key1")); // 查看key1值 从 第几位到第几位s String rangeValue = jedis.getrange("key1", 1, 3); System.out.println("查看key1值 从 第1位到第3位:"+rangeValue); // 获取key1全部长度的值 和 get 功能一样 jedis.getrange("key1",0,-1); // 替换某个字符串 jedis.set("key2","hello world,redis"); System.out.println("key2的值:"+jedis.get("key2")); // 将某个位置的值替换成某个值 Long setRangeValue = jedis.setrange("key2", 7, "xx"); System.out.println("将key2第7位的值换成xx:"+setRangeValue); // 当key存在设置过期时间 jedis.setex("key2",30,"存在设置值,30s后过期"); System.out.println("key2的值:"+jedis.get("key2")); System.out.println("key2的过期时间:"+jedis.ttl("key2")); // 当key不存在才去设置值 jedis.setnx("noHaveKey","不存在的key设置值"); System.out.println("设置noHaveKey的值:"+jedis.get("noHaveKey")); jedis.setnx("noHaveKey","再次设置值"); System.out.println("设置noHaveKey存在时的值:"+jedis.get("noHaveKey")); jedis.flushDB(); // 批量设置key-value jedis.mset("key1","value1","key2","value2","key3","value3"); // 批量获取key的值 System.out.println("批量获取值:"+jedis.mget("key1", "key2", "key3")); // 批量设置key不存在设置值 [原子性] System.out.println(jedis.msetnx("key1", "value11", "key4", "key4")); jedis.flushDB(); // 设置对象 对象名-id-属性 jedis.mset("user:1:name","张三","user:1:age","3"); jedis.mget("user:1:name","user:1:age"); // 先获取db的值再去设置db的值 不存在的key则返回null System.out.println("getSet:"+jedis.getSet("db", "redis")); // 再去获取db的值 System.out.println(jedis.get("db")); } }
总结:
msetnx :原子性的操作,要不全部成功,要不全部失败
使用场景:
计数器(incyby)
统计多单位的数量(user:1:like -> 1)
对象缓存存储
② list(列表)
在redis中 可将list玩成 栈(先进后出) 和 队列(先进先出)
命令都是用 l 或者 r 开头
package com.cai; import redis.clients.jedis.Jedis; import redis.clients.jedis.ListPosition; public class TypeList { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushAll(); // 将一个值或者多个值插入到列表的头部 jedis.lpush("list","one","two","three"); // 获取全部的值 System.out.println("获取list第一位到最后一位的值:"+jedis.lrange("list", 0, -1)); // 获取 第一位和 第二位的值 System.out.println("获取list第一位到第二位的值:"+jedis.lrange("list", 0, 1)); // 将值插入到列表的右边 jedis.rpush("list","right"); System.out.println("list插入右边值:"+jedis.lrange("list", 0, -1)); // 移除左边的值 jedis.lpop("list"); System.out.println("list移除左边的值:"+jedis.lrange("list", 0, -1)); // 移除右边的值 jedis.rpop("list"); System.out.println("list移除右边的值:"+jedis.lrange("list", 0, -1)); // 通过下标获取list的某个值 System.out.println("通过下标1获取list的值:"+jedis.lindex("list", 1)); // 获取列表的长度 System.out.println("获取list的长度:"+jedis.llen("list")); // 插入重复值 jedis.lpush("list","one","two","three"); System.out.println("list的值:"+jedis.lrange("list", 0, -1)); // 移除list集合中指定的个数 jedis.lrem("list",1,"one"); System.out.println("移除list中1个one:"+jedis.lrange("list", 0, -1)); jedis.flushDB(); jedis.rpush("myList","hello","hello1","hello2","hello3","hello4"); System.out.println("myList:"+jedis.lrange("myList", 0, -1)); // 通过下标截取指定的长度,list被改变,截断了只剩下截取的元素 jedis.ltrim("myList",1,3); System.out.println("myList截取1 到2 :"+jedis.lrange("myList", 0, -1)); // 将一个list右边的一个元素移到另一个list的左边 jedis.rpoplpush("myList","giveList"); System.out.println("给值的myList:"+jedis.lrange("myList", 0, -1)); System.out.println("拿到值得giveList:"+jedis.lrange("giveList", 0, -1)); // 判断是否存在 System.out.println("key->list是否存在:"+jedis.exists("list")); jedis.lpush("list","item01"); System.out.println("list:"+jedis.lrange("list", 0, -1)); // 将list指定下标的值替换成一个新的值 ,当 list 索引值不存在 设置会报错【ERR no such key】 System.out.println(jedis.lset("list", 0, "item1")); System.out.println("修改之后的list:"+jedis.lrange("list", 0, -1)); // 将某个value插入到列表中某个值的前面 jedis.linsert("list", ListPosition.BEFORE,"item1","item0"); System.out.println("insert->before的list:"+jedis.lrange("list", 0, -1)); // 将某个value插入到列表中某个值的后面 jedis.linsert("list", ListPosition.AFTER,"item1","item2"); System.out.println("insert->after的list:"+jedis.lrange("list", 0, -1)); } }
总结:
list是一个链表,可以在left 和 right 进行插入
如果key不存在,创建新的链表
如果key存在,新增内容
如果移除了所有的值,空链表。,也代表不存在
在两边插入或者改变值,效率最高,中间元素,相对效率会低一点
使用场景:
消息队列:lpush -> rpop
栈:lpush->lpop
③ set(集合)
set 所有的命令都是以 s 开头
set 是无序和不可重复的
package com.cai; import redis.clients.jedis.Jedis; // set 类型:无序、不可重复 public class TypeSet { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); // sadd 添加值 jedis.sadd("key1", "test"); // 添加重复值:会添加失败,但是不会报错 System.out.println("向key1中添加重复的值test:" + jedis.sadd("key1", "test")); // sadd 可一次性设置多个值,在这里一次性添加的value 中存在重复值,但是并没有报错,说明sadd方法不是原子性 jedis.sadd("key1", "test1", "test2", "test", "hello set", "小菜", "study", "永无止境", "干巴得"); // smembers 获取指定key中的所有值 System.out.println("获取key1所有的值:" + jedis.smembers("key1")); // 判断某个值是都在某个key中存在 System.out.println("key1中是否存在hello:" + jedis.sismember("key1", "hello")); System.out.println("key1中是否存在test:" + jedis.sismember("key1", "test")); // 查看元素个数 System.out.println("key1中元素个数:" + jedis.scard("key1")); // 移除指定元素 jedis.srem("key1", "test2"); System.out.println("移除test2后key1的值:" + jedis.smembers("key1")); // 随机取值 System.out.println("随机取key1中的1个值:" + jedis.srandmember("key1")); System.out.println("随机取key1中的2个值:" + jedis.srandmember("key1", 2)); // 随机删除元素 jedis.spop("key1"); System.out.println("随机删除key1中的1个值:" + jedis.smembers("key1")); System.out.println("-----------------------------------"); jedis.sadd("key2", "张三", "李四", "王五", "赵六", "田七"); System.out.println("key1:" + jedis.smembers("key1")); System.out.println("key2:" + jedis.smembers("key2")); // 将一个key中的值移动到另一个key中 jedis.smove("key2", "key1", "张三"); System.out.println("张三转移之后的key1:" + jedis.smembers("key1")); System.out.println("张三转移之后的key2:" + jedis.smembers("key2")); System.out.println("-----------------------------------"); // 清空当前redis数据库 jedis.flushDB(); // 设置两组set jedis.sadd("key1", "1", "3", "5", "7", "9"); jedis.sadd("key2", "2", "4", "5", "8", "9"); System.out.println("key1:" + jedis.smembers("key1")); System.out.println("key2:" + jedis.smembers("key2")); // 查询一个set与另一个set的差集 System.out.println("key1对比key2的差集:"+jedis.sdiff("key1", "key2")); // 查询一个set与另一个set的交集 System.out.println("key1对比key2的交集:"+jedis.sinter("key1", "key2")); // 查询一个set与另一个set的并集 System.out.println("key1对比key2的并集:"+jedis.sunion("key1", "key2")); } }
总结:
set具有不可重复的特点,在向set中添加重复值时会插入失效,不会报错,查询多个set的并集时,也会去重
使用场景:共同好友
④ Hash(哈希)
想象成Map集合,key ->Map(key-value)。
命令就是以 h 开头
package com.cai; import redis.clients.jedis.Jedis; import java.util.HashMap; import java.util.Map; public class TypeHash { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); // hash set : key:myHash value:(key:field1 - value:张三) jedis.hset("myHash", "field1", "123"); System.out.println("myHash中field1的值:" + jedis.hget("myHash", "field1")); Map<String, String> map = new HashMap<>(); map.put("field1", "张三"); map.put("field2", "李四"); map.put("field3", "王五"); map.put("field4", "赵六"); map.put("field5", "田七"); map.put("field6", "1"); // hmset 存多个,存在的值会被覆盖 jedis.hmset("myHash", map); // hmget 获取某个key的多个字段值 System.out.println("获取myHash的filed1、filed2的值:" + jedis.hmget("myHash", "filed1", "filed2")); // hgetAll 获取某个key 的所有值 System.out.println("获取myHash所有的值:" + jedis.hgetAll("myHash")); // 删除key中指定的字段 jedis.hdel("myHash", "field1"); System.out.println("删除myHash中指定的字段field1:" + jedis.hgetAll("myHash")); // 获取某个key的长度 System.out.println("获取myHash的长度:" + jedis.hlen("myHash")); // 判断某个key中某个field是否存在 System.out.println("myHash中field1是否存在:" + jedis.hexists("myHash", "field1")); System.out.println("myHash中field2是否存在:" + jedis.hexists("myHash", "field2")); // 获取key中所有的filed System.out.println("myHash中所有的field:"+jedis.hkeys("myHash")); // 获取key中所有的value System.out.println("myHash中所有的value:"+jedis.hvals("myHash")); // 对某个key的field自增 jedis.hincrBy("myHash","field6",1); System.out.println("myHash中的field6->hincrBy自增1之后的值:"+jedis.hget("myHash", "field6")); // 对某个key的field自增 jedis.hincrBy("myHash","field6",-1); System.out.println("myHash中的field6->hincrBy自增-1之后的值:"+jedis.hget("myHash", "field6")); // 当某个key中某个field不存在的时候设置值 System.out.println("hsetnx->field6存在时设置值:"+jedis.hsetnx("myHash", "field6", "test")); System.out.println("hsetnx->field7不存在时设置值:"+jedis.hsetnx("myHash", "field7", "test")); System.out.println("获取myHash所有的值:"+jedis.hgetAll("myHash")); } }
总结:hash 可以比string 更好的存储对象类型
使用场景:对象的存储,数据经常发生变化
⑤ Zset (有序集合)
顾名思义,就是在set的基础上增加了排序功能,满足有序,不可重复
命令都是以 z 开头
package com.cai; import redis.clients.jedis.Jedis; import java.util.HashMap; import static jdk.nashorn.internal.objects.Global.Infinity; public class TypeZset { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); // 添加数据 jedis.zadd("myZset",1,"张三"); HashMap<String, Double> map = new HashMap<>(); map.put("李四",2.0); map.put("王五",2.5); map.put("赵六",3.0); // 添加多个值 jedis.zadd("myZset",map); // 通过索引获取区间值 System.out.println("根据索引获取myZset的所有值:"+jedis.zrange("myZset", 0, -1)); // 根据score正序来获取区间值 System.out.println("获取myZset的score从负无穷到正无穷的区间值正序:"+jedis.zrangeByScore("myZset", -Infinity, Infinity)); // 删除指定元素 jedis.zrem("myZset","张三"); // 根据score正序来获取区间值 System.out.println("获取myZset的score从0到2.5的区间值正序:"+jedis.zrangeByScore("myZset", 0, 2.5)); // 获取元素个数 System.out.println("获取myZset的元素个数:"+jedis.zcard("myZset")); // 根据score倒序来获取区间值 System.out.println("获取myZset的score->0到3的区间值倒序:"+jedis.zrevrange("myZset", 0, 3)); // 获取score 区间值的元素个数 System.out.println("获取score从0到2.5的元素个数:"+jedis.zcount("myZset", 0, 2.5)); } }
总结:
set:sadd key value
Zset:sadd key score value
使用场景:排名、等级
三种特殊数据类型
① geospatial(地理位置)
用于存放地点经纬度
命令都是 geo 开头
package com.cai; import redis.clients.jedis.GeoUnit; import redis.clients.jedis.Jedis; import redis.clients.jedis.params.GeoRadiusParam; // public class TypeGeospatial { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); // 添加数据 jedis.geoadd("city",116.23128,40.22077,"beijing"); jedis.geoadd("city",121.48941,31.40527,"shanghai"); jedis.geoadd("city",113.27324,23.15792,"guangzhou"); jedis.geoadd("city",113.88308,22.55329,"shenzhen"); // 获取key中指定元素的经纬度 System.out.println("获取指定地点的经纬度:"+jedis.geopos("city","beijing","shanghai","guangzhou","shenzhen")); // 查询key中两个元素之间的距离 System.out.println("北京到上海的直线距离约为:"+jedis.geodist("city", "beijing", "shanghai", GeoUnit.KM)+"/km"); System.out.println("上海到深圳的直线距离约为:"+jedis.geodist("city", "shanghai", "shenzhen", GeoUnit.M)+"/m"); // 模拟附近的人 以经纬度110,30为中心,半径为1000km附近的城市 System.out.println("经纬度110,30附近1000km的地点:"+jedis.georadius("city", 110, 30, 1000, GeoUnit.KM)); // 以元素为中心,查询指定距离的其他元素 System.out.println("北京附近1000km的地点:"+jedis.georadiusByMember("city", "beijing", 1000, GeoUnit.KM)); // 降维打击 ,hash值越像,距离越近 System.out.println("将二维的经纬度转为一维的字符串:"+jedis.geohash("city", "beijing", "shanghai")); // 可以通过Zset的命令操作 System.out.println("通过zrange获取元素:"+jedis.zrange("city", 0, -1)); System.out.println("通过zrem删除元素:"+jedis.zrem("city", "shenzhen")); System.out.println("通过zrange获取元素(删除shenzhen之后):"+jedis.zrange("city", 0, -1)); } }
总结:
地球两极无法添加
有效经度:-180 到 +180
有效纬度:-85 到 +85
geo底层的实现远离其实就是Zset,我们可以使用Zset命令来操作geo
使用场景:
计算两地的直线距离
查询附近的人
② hyperloglog (数据结构)
用于做基数(不重复的元素)统计的算法
package com.cai; import redis.clients.jedis.Jedis; public class TypeHyperloglog { public static void main(String[] args) { Jedis jedis = new Jedis(); // 添加元素 jedis.pfadd("myKey","a","a","b","b","c"); // 统计元素个数 System.out.println("myKey中基数个数:"+jedis.pfcount("myKey")); jedis.pfadd("myKey2","1","2","3","4","4"); System.out.println("myKey2中基数个数:"+jedis.pfcount("myKey2")); // 合并两个key 生成新的key jedis.pfmerge("myKey3","myKey","myKey2"); System.out.println("myKey3中基数个数:"+jedis.pfcount("myKey3")); } }
总结:
可以接受误差,占用的内存是固定的(2^64的元素,只占用12kb)
使用场景:
网站 UV(一个人访问一个网站多次,但是还是算一个人) 统计
③ bitmaps(位图)
操作二进制来进行记录,只有true(1)和false(0)两个状态,占用内存非常小,八个bit才一个字节
所以命令比较少,也比较简单
import redis.clients.jedis.Jedis; public class TypeBitmaps { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1", 6379); // 签到 : 第一天 签到了 jedis.setbit("sign",1,true); // 第二天 未签到 jedis.setbit("sign",2,false); // 第三天 签到了 jedis.setbit("sign",3,true); // 获取key中指定天数的状态 System.out.println("获取sign中第1天是否打卡:"+jedis.getbit("sign", 1)); System.out.println("获取sign中第2天是否打卡:"+jedis.getbit("sign", 2)); System.out.println("获取sign中第3天是否打卡:"+jedis.getbit("sign", 3)); // 查询key中value为true的总数 System.out.println("三天内打卡次数:"+jedis.bitcount("sign")); } }
总结:
bitmaps占用的内存很小,bit类型,只有两种状态,true和false
使用场景:
一般用于记录两种状态的数据,比如:是否签到、是否登录、是否活跃
事务
事务的ACID特性,在redis中,只保证单条命令具有原子性,事务是不保证原子性和隔离性的
redis的事务如果命令中出错是不会回滚的,造成不具有原子性。
redis的事务可以配合着监视器(watch),当监视的key的中值发生了变化时,事务中的命令则不会执行
redis的事务分为三个阶段:
1、开启事务(multi)
2、命令入队(set...)
3、执行事务(exec)
也就是说,所有的命令在事务中,并没有直接被执行,只有发起了执行事务命令,才会去执行。
package com.redis.transaction; import com.alibaba.fastjson.JSONObject; import redis.clients.jedis.Jedis; import redis.clients.jedis.Transaction; import java.util.concurrent.TimeUnit; public class Trans { public static void main(String[] args) { Jedis jedis = new Jedis(); jedis.flushDB(); // 创建一个json JSONObject jsonObject=new JSONObject(); jsonObject.put("name","lucky"); jsonObject.put("age","18"); // 开启事务 Transaction multi = jedis.multi(); String user = jsonObject.toJSONString(); try { System.out.println("事务插入user-json:"+multi.set("user", user)); System.out.println("事务插入key1-张三:"+multi.set("key1", "张三")); System.out.println("事务插入key2-李四:"+multi.mset("key2", "李四")); System.out.println("事务插入key3-王五:"+multi.lpush("key3", "王五")); System.out.println("事务插入key4-赵六:"+multi.sadd("key4", "赵六")); System.out.println("事务插入key5-田七:"+multi.zadd("key5", 6, "田七")); System.out.println("事务插入key6-周八:"+multi.hset("key6", "name", "周八")); // 执行事务 System.out.println("执行结果:"+multi.exec()); }catch (Exception e){ // 出现异常,取消事务 multi.discard(); } System.out.println("------------------------------------"); // 获取事务插入的值 System.out.println("事务中字符串set的user:"+jedis.get("user")); System.out.println("事务中字符串set的key1:"+jedis.get("key1")); System.out.println("事务中字符串mset的key2:"+jedis.mget("key2")); System.out.println("事务中列表push的key3:"+jedis.lrange("key3",0,-1)); System.out.println("事务中集合set的key4:"+jedis.srandmember("key4")); System.out.println("事务中有序集合add的key5:"+jedis.zrange("key5",0,-1)); System.out.println("事务中哈希set的key6:"+jedis.hgetAll("key6")); System.out.println("------------------------------------"); // 创建事务,测试取消事务,是否还能查询到值 Transaction multi1 = jedis.multi(); System.out.println("事务插入key7-九九:"+multi1.set("key7", "九九")); // 取消事务 System.out.println("取消事务:"+multi1.discard()); // 查询事务取消之后是否还能查询中key7 System.out.println("事务被取消添加的key7:"+jedis.get("key7")); System.out.println("-------------------------------------"); // 测试事务执行的命令中出现错误,是否保证原子性 Transaction multi2 = jedis.multi(); System.out.println("事务插入key8-字符串:"+multi2.set("key8", "字符串")); System.out.println("事务将key8的值字符串自增1:"+multi2.incr("key8")); System.out.println("执行结果:"+multi2.exec()); // 获取key8的值,发现有值,说明redis的事务不保证原子性 System.out.println("获取key8的值:"+jedis.get("key8")); System.out.println("--------------------------------------"); // 设置一个key System.out.println("设置money的值:"+jedis.set("money", "1000")); System.out.println("设置out的值:"+jedis.set("out", "0")); // 监视【watch】 相当于mysql中的乐观锁【version】 System.out.println("监视money:"+jedis.watch("money")); // 测试正常情况,事务期间,数据没有发生变动 Transaction multi3 = jedis.multi(); System.out.println("测试正常情况money自减200:"+multi3.decrBy("money", 200)); System.out.println("测试正常情况out自增200:"+multi3.incrBy("out", 200)); System.out.println("执行结果:"+multi3.exec()); System.out.println("测试正常情况money执行后的值:"+jedis.get("money")); System.out.println("测试正常情况out执行后的值:"+jedis.get("out")); System.out.println("--------------------------------------"); jedis.watch("money"); new Thread(()->{ // 插入扣除money800,money变为0 System.out.println("插队扣除money的800:"+jedis.decrBy("money", 800)); },"b").start(); new Thread(()->{ Transaction multi4 = jedis.multi(); try { System.out.println("测试money插队修改后money自减200:"+multi4.decrBy("money", 200)); System.out.println("测试money插队修改后out自增200:"+multi4.incrBy("out", 200)); }catch (Exception e){ System.out.println("异常情况:"+multi4.discard()); } try { TimeUnit.SECONDS.sleep(2); } catch (InterruptedException e) { e.printStackTrace(); } // 得出结果,监视到money的值发生了变化,事务中的命令操作并没有执行 System.out.println("执行结果:"+multi4.exec()); System.out.println("测试money插队修改后money执行后的值:"+jedis.get("money")); System.out.println("测试money插队修改后out执行后的值:"+jedis.get("out")); },"a").start(); } }
第二种:SpringBoot整合
1、导入依赖,我们可以再选择在创建springboot项目的时候勾选上redis,也可以在创建完成项目之后,再导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、了解 Redis 配置
redis既然集成springboot中,那就应该存在一个 RedisAutoConfiguration 的自动配置类,并绑定一个 properties 文件
我们在SpringBootAutoConfigure中查找关于redis的配置

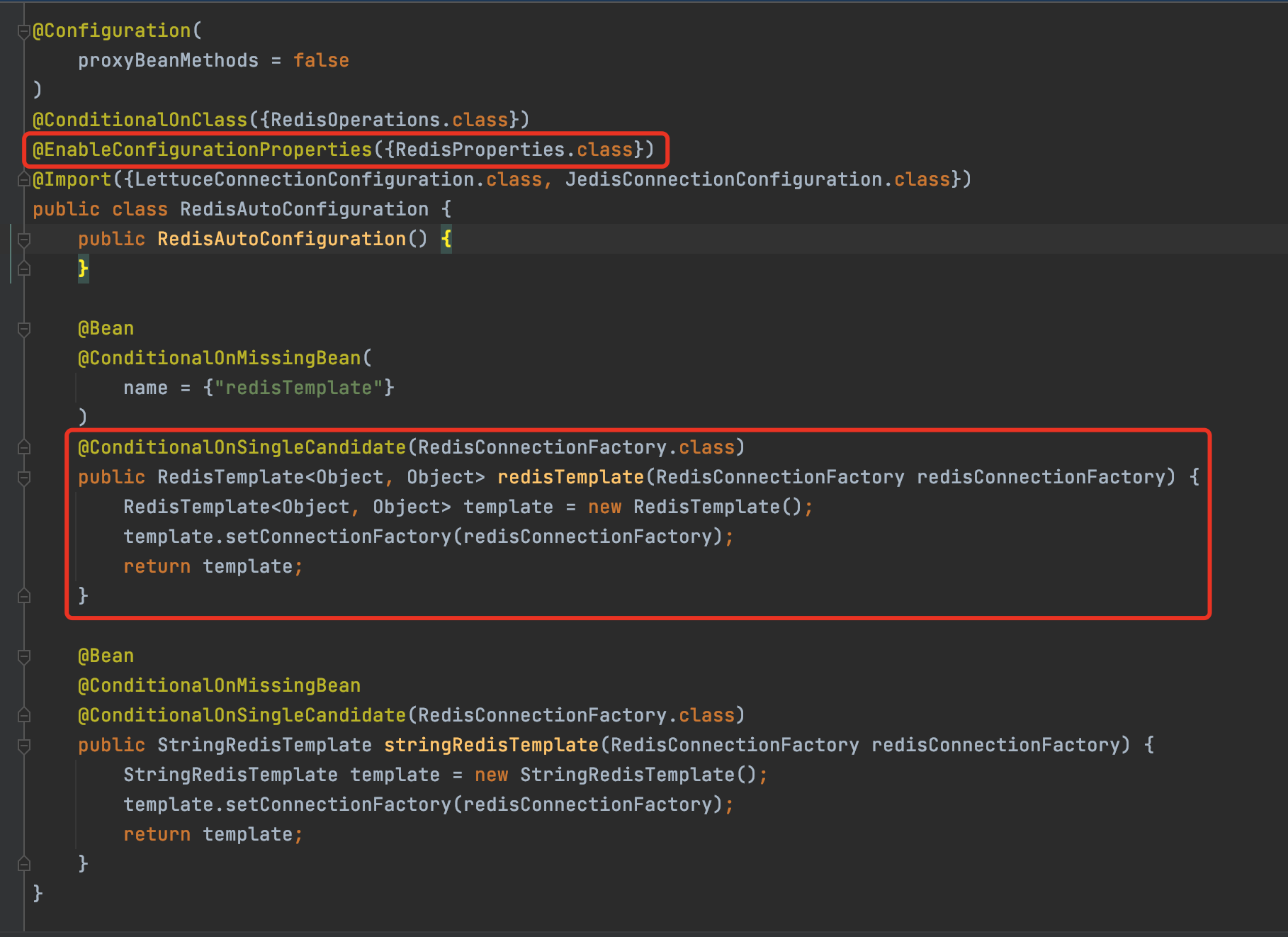
找到了这个 RedisAutoConfiguration 的配置类,看到绑定了RedisProperties类。
以及注入的两个方法:
第一个就是和MangoDB和RabbMq一样熟悉的模板类:RedisTemplate,我们之后就可以直接使用这个模板类简单的来使用redis了
第二个就是StringRedisTemplate ,为什么会有两个Template 呢?这是因为在redis 中大部分使用的就是 String类型。
默认的Template并没有过多的配置,也没有使用 序列化 的配置,而我们的redis对象都是需要序列化的,之后会在配置中加上,RedisTemplate 默认用的都是两个Object 类型,我们一般使用 String,Object 类型,会造成强制转换,通过注解了解当不存在 redisTempla 类的时候生效,也就是说我们可以自定义一个redisTemplate的类替换掉它。
我们点进RedisTemplate类中
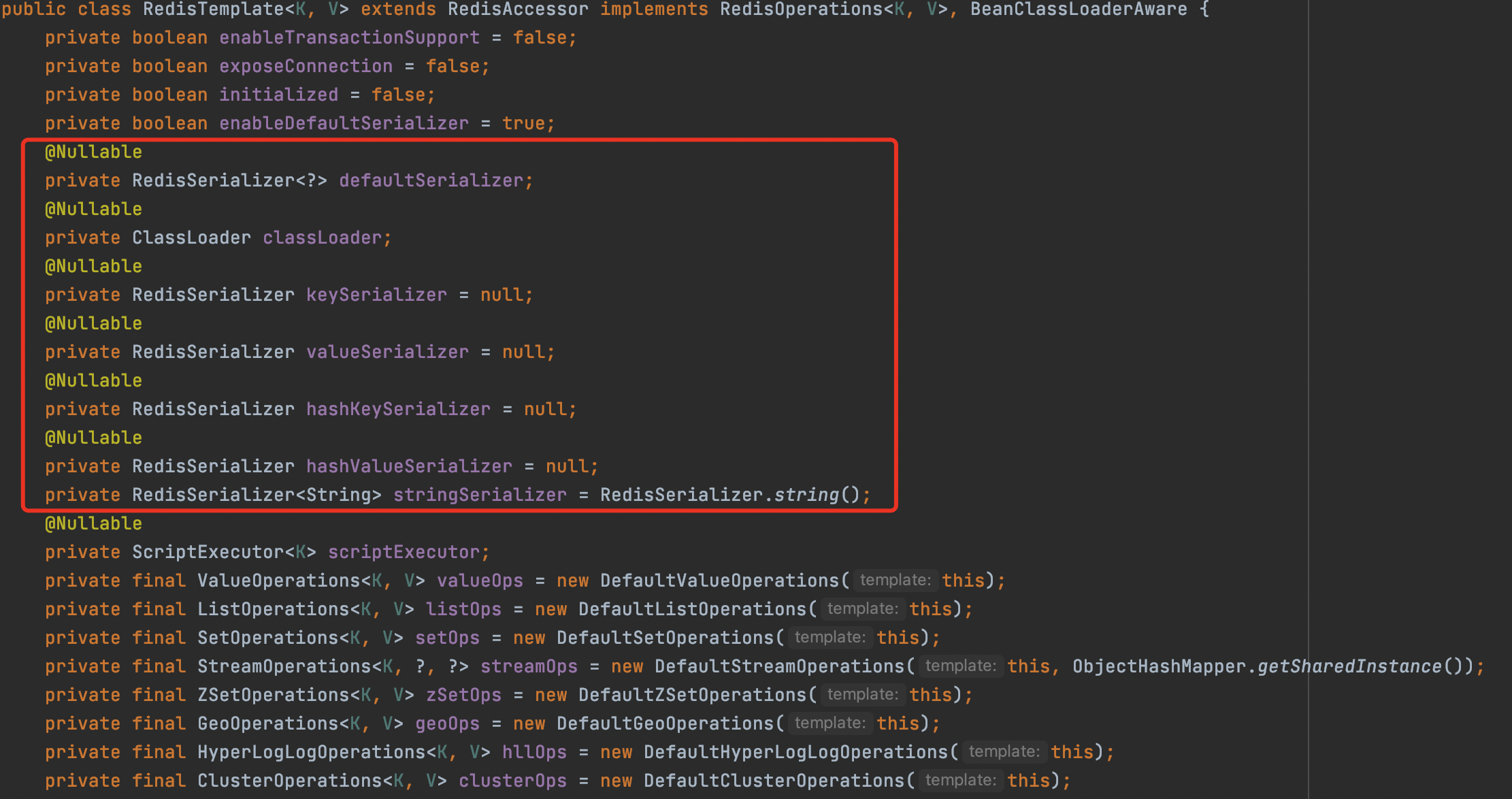
这里有数据结构值的序列化配置,我们可以找一下默认的序列化
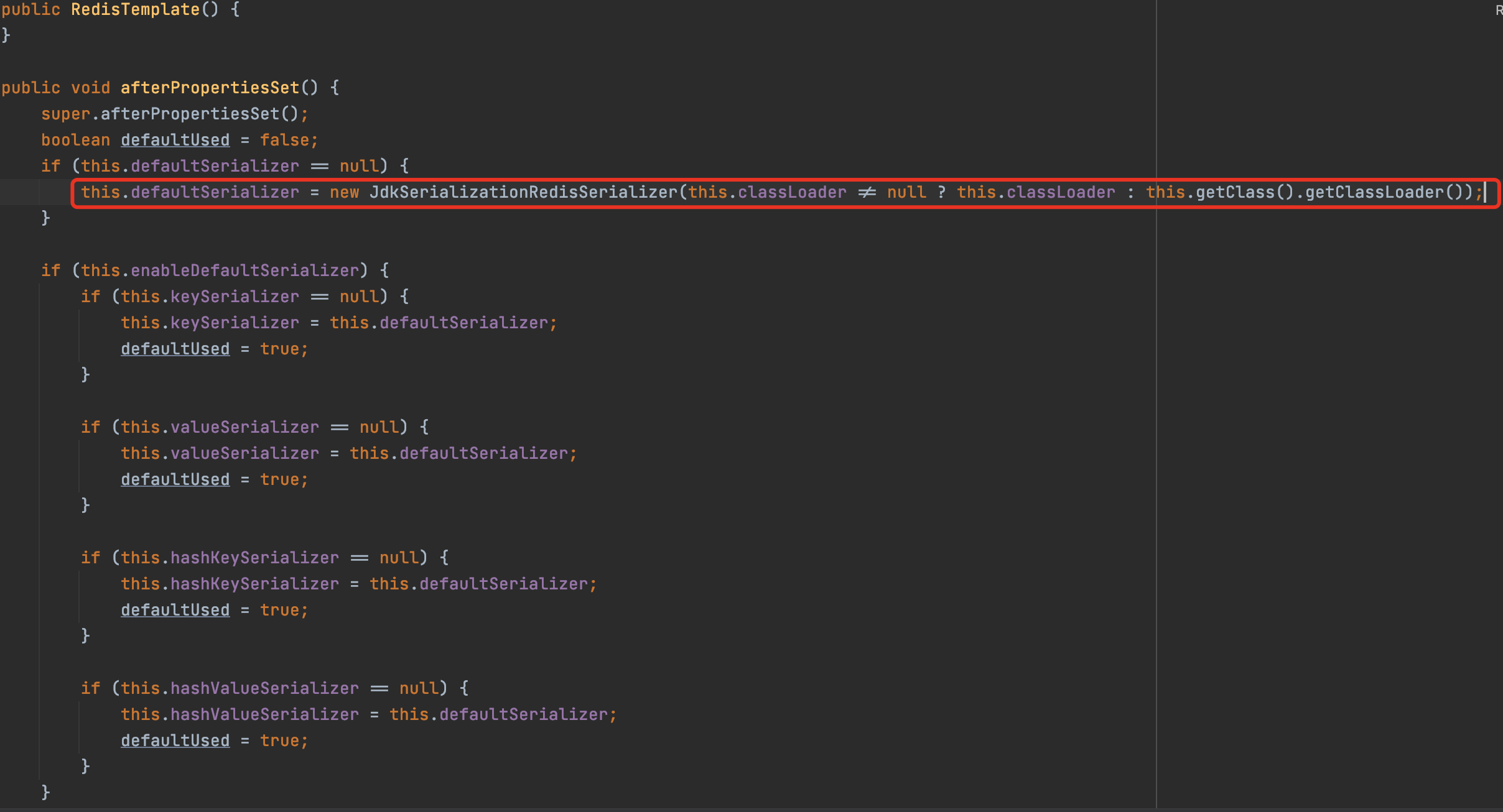
发现如果没有配置序列化方式,默认会使用jdk的序列化,这会让字符串转义,我们一般使用json来序列化。
我们再看看 RedisProperties 类,可以看到属性和一些默认的配置,比如 redis 默认使用的是0号数据库、采用本地的服务以及使用的6379端口
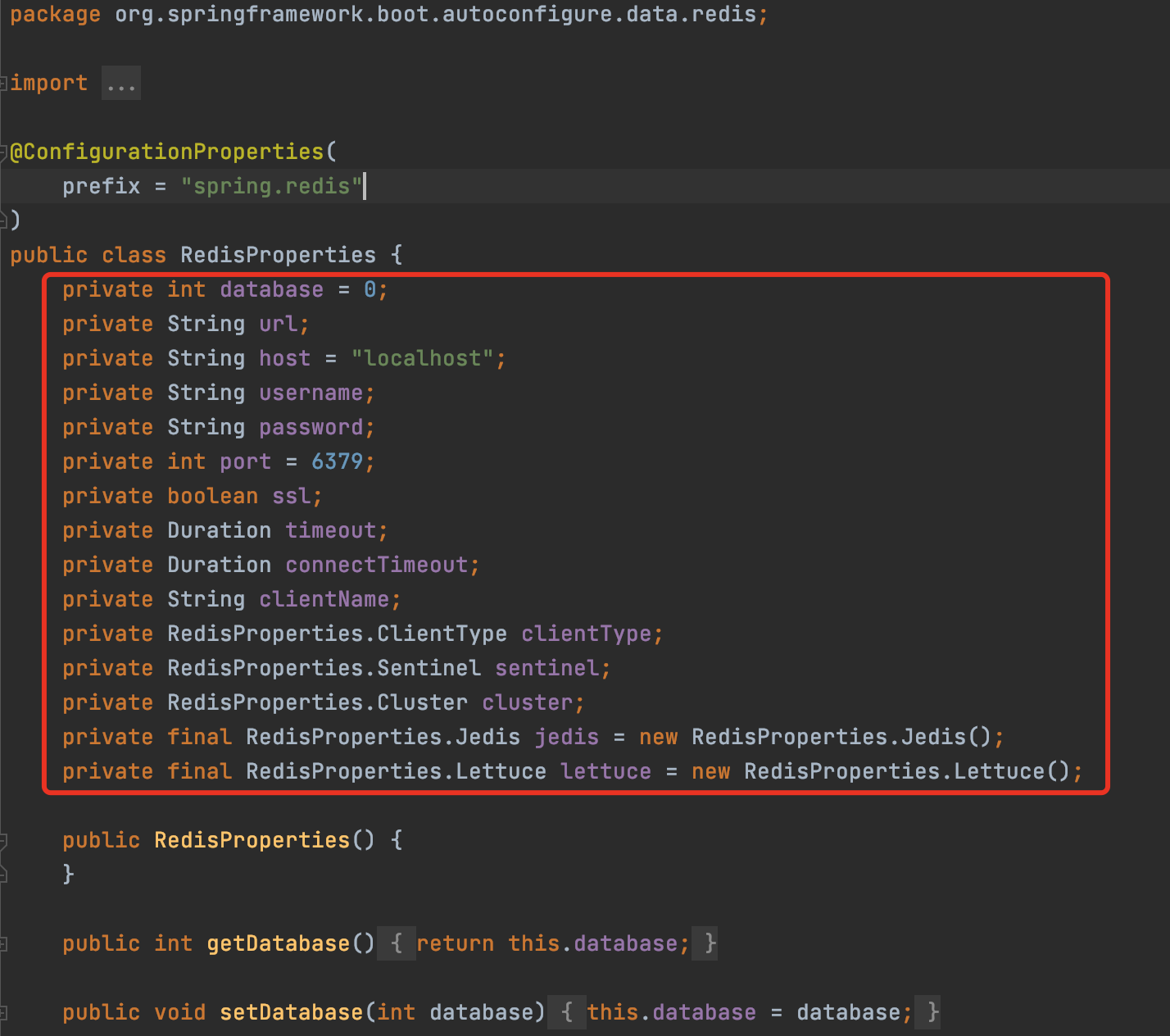
3、在Application文件中配置 Redis
# host默认是本地连接
spring.redis.host=127.0.0.1
# 端口号
spring.redis.port=6379
# redis的数据库,默认是0
spring.redis.database=1
4、测试使用
在我们测试类中注入RedisTemplate
@Autowired
private RedisTemplate redisTemplate;
redisTemplate数据类型,对应关系如下:
操作字符串,String --> opsForValue()
操作列表,List --> opsForList()
操作集合,Set --> opsForSet()
操作有序集合,Zset --> opsForZSet()
操作哈希,Hash --> opsForHash()
操作位置,Geo --> opsForGeo()
操作基数,Hypeloglog --> opsForHyperLogLog()
操作位图,bitmaps --> opsForValue().setBit()
@Test void contextLoads() { // 操作字符串,String --> opsForValue() System.out.println("-----------------------string------------------------"); redisTemplate.opsForValue().set("string01", "test01"); System.out.println("string01:" + redisTemplate.opsForValue().get("string01")); // 操作列表,List --> opsForList() System.out.println("-----------------------list------------------------"); redisTemplate.opsForList().leftPush("list01", "leftValue01"); redisTemplate.opsForList().rightPush("list01", "rightValue02"); System.out.println("list01:" + redisTemplate.opsForList().range("list01", 0, -1)); // 操作集合,Set --> opsForSet() System.out.println("-----------------------Set------------------------"); redisTemplate.opsForSet().add("set01", "value01", "value02", "value03", "value04"); redisTemplate.opsForSet().add("set02", "value01", "value03", "value05", "value07"); System.out.println("set01:" + redisTemplate.opsForSet().members("set01")); System.out.println("set02:" + redisTemplate.opsForSet().members("set02")); System.out.println("set01和set02的差集:" + redisTemplate.opsForSet().difference("set01", "set02")); System.out.println("set01和set02的并集:" + redisTemplate.opsForSet().union("set01", "set02")); System.out.println("set01和set02的交集:" + redisTemplate.opsForSet().intersect("set01", "set02")); // 操作有序集合,Zset --> opsForZSet() System.out.println("----------------------Zset-------------------------"); redisTemplate.opsForZSet().add("Zset01", "a", 1); redisTemplate.opsForZSet().add("Zset01", "b", 2); redisTemplate.opsForZSet().add("Zset01", "c", 3); redisTemplate.opsForZSet().add("Zset01", "d", 4); System.out.println("Zset正序:" + redisTemplate.opsForZSet().rangeByScore("Zset01", 1, 4)); System.out.println("Zset倒序:" + redisTemplate.opsForZSet().reverseRange("Zset01", 0, 4)); // 操作哈希,Hash --> opsForHash() System.out.println("-----------------------hash------------------------"); redisTemplate.opsForHash().put("hash01", "name", "zhangsan"); redisTemplate.opsForHash().put("hash01", "age", 18); System.out.println("hash01的name:" + redisTemplate.opsForHash().get("hash01", "name")); System.out.println("hash01中是否存在age:" + redisTemplate.opsForHash().hasKey("hash01", "age")); // 操作位置,Geo --> opsForGeo() System.out.println("-------------------------geo----------------------"); HashMap<String, Point> map = new HashMap<>(); map.put("beijing", new Point(116.23128, 40.22077)); map.put("shanghai", new Point(121.48941, 31.40527)); redisTemplate.opsForGeo().add("geo01", map); System.out.println("geo01中beijing到shanghia的直线距离(km):" + redisTemplate.opsForGeo().distance("geo01", "beijing", "shanghai", Metrics.KILOMETERS)); Circle circle = new Circle(new Point(119.31315, 36.33333), new Distance(1000, Metrics.KILOMETERS)); System.out.println("geo01中距离坐标119.31315,36.3333的距离为10s00km的城市:" + redisTemplate.opsForGeo().radius("geo01", circle)); // 操作基数,Hypeloglog --> opsForHyperLogLog() System.out.println("-------------------------hypeloglog----------------------"); redisTemplate.opsForHyperLogLog().add("hype01", "1", "2", "2", "3", "4", "4", "5"); System.out.println("hype01去重之后的数量:" + redisTemplate.opsForHyperLogLog().size("hype01")); // 操作位图,bitmaps --> opsForValue().setBit() System.out.println("-------------------------bitmaps----------------------"); redisTemplate.opsForValue().setBit("bit01", 1, true); redisTemplate.opsForValue().setBit("bit01", 2, false); redisTemplate.opsForValue().setBit("bit01", 3, true); System.out.println("bit01的第1天状态:" + redisTemplate.opsForValue().getBit("bit01", 1)); System.out.println("bit01的第2天状态:" + redisTemplate.opsForValue().getBit("bit01", 2)); // 获取redis的连接对象,操作数据库 RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); connection.flushAll(); connection.flushDb(); }
5、自定义 RedisTemplate
上面通过源码我们得知了默认的RedisTemplate使用的是jdk的序列化。所以我们重新定义一个RedisTemplate,使用json的序列化
我们先建一个简单的user对象
package com.redis.pojo; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.springframework.stereotype.Component; @Component @AllArgsConstructor @NoArgsConstructor @Data public class User { private String name; private Integer age; }
我们再建一个config的包,新建一个 redisTemplate 的类
package com.redis.config; import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annotation.PropertyAccessor; import com.fasterxml.jackson.databind.ObjectMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer; import org.springframework.data.redis.serializer.StringRedisSerializer; @Configuration public class RedisConfig { // redis默认的序列化使用的是jdk的方式,我们一般会使用json格式序列化,这个时候,我们就需要编写自己的配置,让默认的配置不生效 @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) { // 方便开发使用<string,object> RedisTemplate<String, Object> template = new RedisTemplate(); template.setConnectionFactory(redisConnectionFactory); // jackson的序列化设置 Jackson2JsonRedisSerializer<Object> objectJackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class); ObjectMapper objectMapper = new ObjectMapper(); objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); objectMapper.activateDefaultTyping(objectMapper.getPolymorphicTypeValidator()); objectJackson2JsonRedisSerializer.setObjectMapper(objectMapper); // string的序列化设置 StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // key采用string的序列化方式 template.setKeySerializer(stringRedisSerializer); // hash的key采用string的序列化方式 template.setHashKeySerializer(stringRedisSerializer); // value的序列化方式采用jackson template.setValueSerializer(objectJackson2JsonRedisSerializer); // hash的value序列化方式采用Jackson template.setHashValueSerializer(objectJackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } }
测试看效果:
@Test void UserTest() throws JsonProcessingException { redisTemplate.opsForValue().set("user_toString",new User("zhangsan",18).toString()); System.out.println("对象toString的数据:"+redisTemplate.opsForValue().get("user_toString")); User user = new User("张三", 18); // 对象格式化json String jsonUser = new ObjectMapper().writeValueAsString(user); redisTemplate.opsForValue().set("user",jsonUser); System.out.println("对象json格式化的数据:"+redisTemplate.opsForValue().get("user")); }
Redis.config 详解
在我们安装redis的目录下找到我们的 redis.config 文件,来探究一下 redis 可以配置什么,有什么功能
1、配置内存单位,配置不区分大小写
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
2、INCLUDES 包含,可以导入其他的配置
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Note that option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
3、NETWORK 网络配置
bind 127.0.0.1 ::1 # 绑定ip
protected-mode yes # 开启受保护模式
port 6379 # 端口号
4、GENERAL 通用配置
daemonize no # 以守护进程(后台)的方式运行,默认是no,我们需要自己开启为yes
pidfile /var/run/redis_6379.pid # 已后台方式运行,需要指定一个 pid 文件
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
loglevel notice # 日志级别
logfile "" # 日志文件目录
databases 16 # 数据库数量,默认是16个数据库
always-show-logo no # 是否显示log
5、SNAPSHOTTING 快照,持久化
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 key changed
# * After 300 seconds (5 minutes) if at least 100 keys changed
# * After 60 seconds if at least 10000 keys changed
#
# You can set these explicitly by uncommenting the three following lines.
#
# save 3600 1 # 在指定时间内操作了多少次,则会持久化到文件 .RDB/.AOP
# save 300 100
# save 60 10000
stop-writes-on-bgsave-error yes # 持久化出错,是否继续工作
rdbcompression yes # 是否压缩RDB文件,需要消耗CPU资源
rdbchecksum yes # 保存RDB文件时,校验是否正确
dbfilename dump.rdb # RDB文件的名称
dir /opt/homebrew/var/db/redis/ # RDB文件存放的目录
6、REPLICATION 复制
replica-serve-stale-data yes # 使用主从复制,从节点可以接收访问请求
7、SECURITY 安全
requirepass 123465 # 密码
密码设置之后,使用redis需要授权
> config set requirepas "123456"
> config get requirepas
> auth 123456
8、CLIENTS 客户端
# maxclients 10000 # 可连接最大数
9、内存管理
# maxmemory <bytes> # 最大内存
# maxmemory-policy noeviction # 内存到达上限的策略,例如:移除一些过期的key、报错等等
mybatis 整合 redis 实现二级缓存
mybatis 有一级缓存和二级缓存之分,通俗的理解如下
一级缓存:
SqlSession 级别的缓存,在同一个连接(connection)中,相同的查询语句,第二次不会走数据库,默认开启
二级缓存:
夸SqlSession级别的缓存,在多个连接(connection)中,相同的查询语句,第二次不会走数据库,需要手动开启
开启二级缓存的方式:
1、springboot的配置文件中添加 :
mybatis.configuration.cache-enabled=true
2、在对应的Mapper配置文件中,加入 <cache /> 标签即可
整合 redis 实现二级缓存步骤
首先,我们需要知道mybatis如何实现二级缓存的,为什么加了一个配置就可以实现二级缓存,我们知道了这一点,就可以用类似的方式实现redis 的缓存
在mapper配置文件中 <cache/> 标签 是有一个type的属性,我们可以去 Cache 这个接口中查询一下实现类
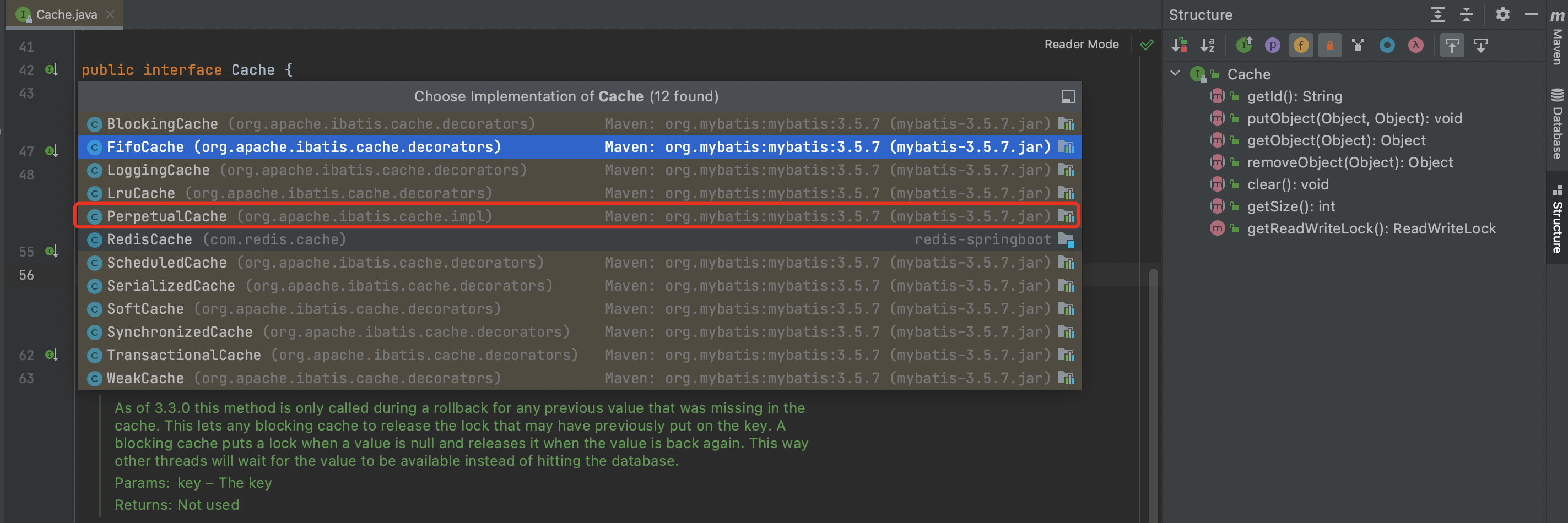
<cache type="org.apache.ibatis.cache.impl.PerpetualCache" >
实现类是 PerpetualCache
然后再来想一想是不是 我们也可以写一个自定义缓存的类实现 Cahe 接口,放到 cache 标签中的 type属性中呢?下面就是实现步骤
1、新建一个 cache 的包,创建一个 MyCache的类,实现 Cache 的接口中的方法,要注意的是Cache这个接口的包要是mybatis的
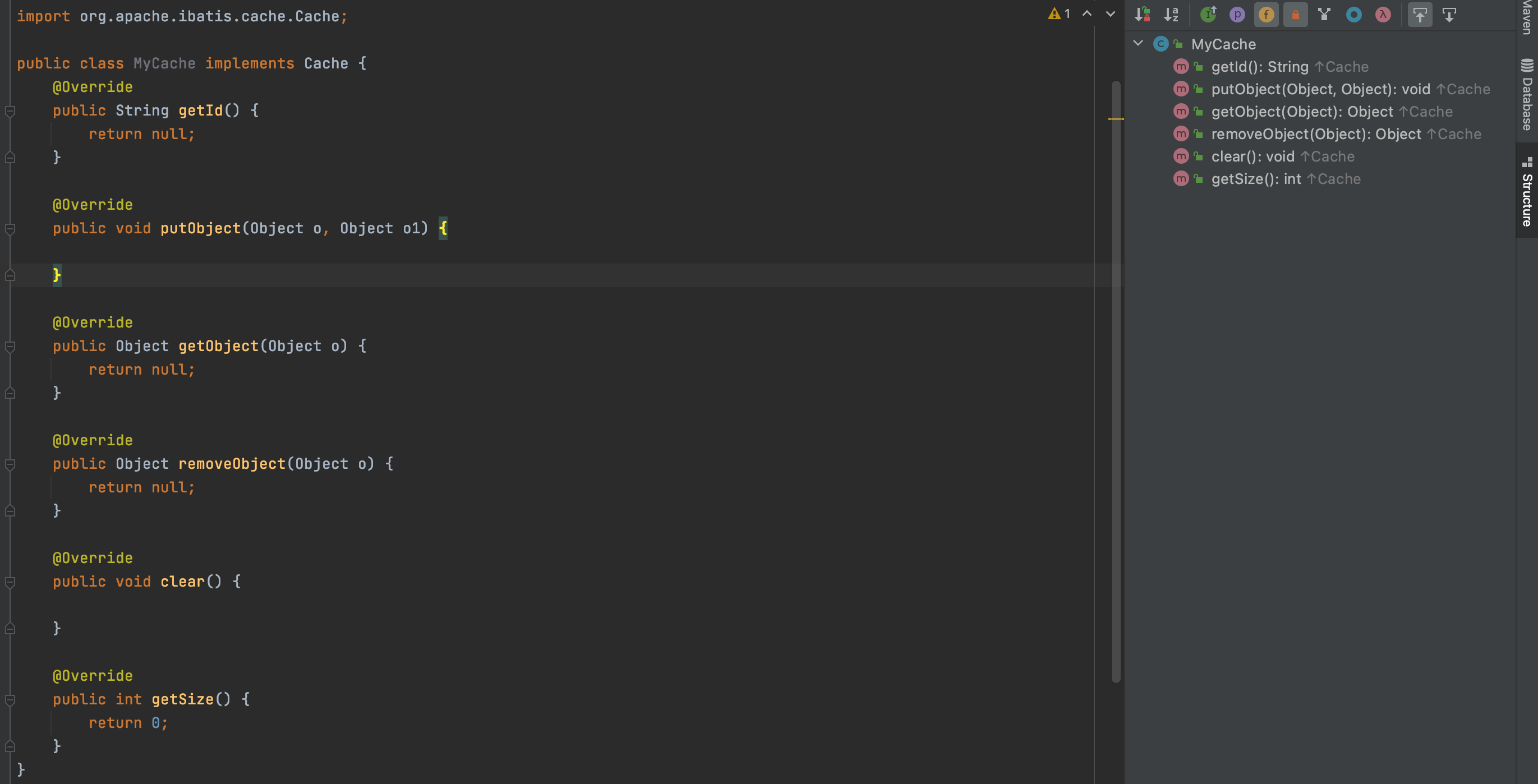
类创建好之后, 我们将 cache 中的 type 换成我们编写的 MyCache 这个类
<cache type="com.redis.cache.MyCache"/>
在测试类中定义一个方法
@Test
public void testFindOne(){
userService.findUserById(1);
System.out.println("======================");
userService.findUserById(1);
}
然后运行,看看会不会报错
Caused by: org.apache.ibatis.cache.CacheException: Invalid base cache implementation (class com.redis.cache.MyCache). Base cache implementations must have a constructor that takes a String id as a parameter. Cause: java.lang.NoSuchMethodException: com.redis.cache.MyCache.<init>(java.lang.String) at org.apache.ibatis.mapping.CacheBuilder.getBaseCacheConstructor(CacheBuilder.java:202) at org.apache.ibatis.mapping.CacheBuilder.newBaseCacheInstance(CacheBuilder.java:190) at org.apache.ibatis.mapping.CacheBuilder.build(CacheBuilder.java:94) at org.apache.ibatis.builder.MapperBuilderAssistant.useNewCache(MapperBuilderAssistant.java:139) at org.apache.ibatis.builder.xml.XMLMapperBuilder.cacheElement(XMLMapperBuilder.java:213) at org.apache.ibatis.builder.xml.XMLMapperBuilder.configurationElement(XMLMapperBuilder.java:117) ... 84 more Caused by: java.lang.NoSuchMethodException: com.redis.cache.MyCache.<init>(java.lang.String) at java.lang.Class.getConstructor0(Class.java:3082) at java.lang.Class.getConstructor(Class.java:1825) at org.apache.ibatis.mapping.CacheBuilder.getBaseCacheConstructor(CacheBuilder.java:200) ... 89 more
发现报错了,错误信息说我们的构造方法中需要一个id 的参数,
如果不知道是什么意思,也可以直接去看 Cache 的实现类,也就是 PerpetualCache 这个类中是怎么写的
这个 id 相当于 mapper文件中的namespace ,我们也可以参照这种方法来
// 相当于mapper的namespace private final String id;
// 必须存在一个构造方法 public MyCache(String id) { System.out.println("id=" + id); this.id = id; }
@Override public String getId() { return this.id; }
再次运行,发现运行成功,没有报错。
2、在 MyCache 中使用 RedisTemplate
由于 RedisTemplate 是工厂模式创建的,所以我们要拿到springboot 的工厂对象来创建redisTemplate
所以我们创建一个 ApplicationContextUtil 的工具类
package com.redis.utils;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
// 用来获取springboot创建好的工厂
@Component
public class ApplicationContextUtil implements ApplicationContextAware {
// 保留下来的工厂
private static ApplicationContext applicationContext;
// 将创建好的工厂以参数的样式传递给这个类
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
// 提供在工厂中获取对象的方法 RedisTemplate -> redisTemplate
public static Object getBean(String beanName){
return applicationContext.getBean(beanName);
}
}
接着在我们的MyCache 类中 使用,我们先编写一个方法
private RedisTemplate getRedisTemplate() {
RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate");
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
然后就可以在 MyCache 中 调用方法getRedisTemplate() 来使用了
package com.redis.cache; import com.redis.utils.ApplicationContextUtil; import org.apache.ibatis.cache.Cache; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.serializer.StringRedisSerializer; import org.springframework.util.DigestUtils; public class MyCache implements Cache { // 相当于mapper的namespace private final String id; // 必须存在一个构造方法 public MyCache(String id) { System.out.println("id=" + id); this.id = id; } @Override public String getId() { return this.id; } // 缓存中放入值 @Override public void putObject(Object key, Object value) { System.out.println("==========key:" + key.toString()); System.out.println("==========value:" + value); String id = DigestUtils.md5DigestAsHex(this.id.getBytes()); getRedisTemplate().opsForHash().put(id, key.toString(), value); } // 缓存中取出值 @Override public Object getObject(Object key) { System.out.println("==========key:" + key.toString()); String id = DigestUtils.md5DigestAsHex(this.id.getBytes()); return getRedisTemplate().opsForHash().get(id, key.toString()); } // 为mybatis的方法,目前没有实现 @Override public Object removeObject(Object key) { System.out.println("==========删除:" + key); return null; } @Override public void clear() { System.out.println("=========清除:"); String id = DigestUtils.md5DigestAsHex(this.id.getBytes()); getRedisTemplate().delete(id); } // 计算缓存的数量 @Override public int getSize() { String id = DigestUtils.md5DigestAsHex(this.id.getBytes()); // 获取hash中的key value 数量 return getRedisTemplate().opsForHash().size(id).intValue(); } private RedisTemplate getRedisTemplate() { RedisTemplate redisTemplate = (RedisTemplate) ApplicationContextUtil.getBean("redisTemplate"); redisTemplate.setKeySerializer(new StringRedisSerializer()); redisTemplate.setHashKeySerializer(new StringRedisSerializer()); return redisTemplate; } }

