四.机器学习算法篇-逻辑回归
1. 逻辑回归的原理
逻辑回归名字里带着回归,并不是回归,而是用回归的方式解决分类的算法。
逻辑回归的输入:ℎ(w)= w_0+w_1x_1+w_2x_2+…= w^Tx
这个输入跟线性回归很相似。
然后看下Sigmoid 函数
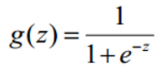
画下这个函数的图像
代码示例
import numpy as np
from matplotlib import pyplot as plt
def sigmod(t):
return 1/(1+np.exp(-t))
x = np.linspace(-10, 10, 500)
y = sigmod(x)
plt.figure(figsize=(8,4),dpi=80)
plt.plot(x, y)
plt.show()

可以看到自变量取值为任意实数,值域[0,1],这就等同于概率值
将逻辑回归的输入带入到sigmod函数中。
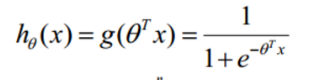
然后得到逻辑回归的预测函数,这样就完成了由值到概率的转换,假定一个阈值为0.5,默认也是取0.5,大于0.5概率归于1,小于0.5概率的归为0,这就完成了一个二分类的问题。
那么就有
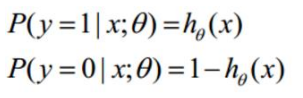
整合下得到
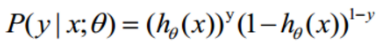
3.逻辑回归的损失函数
- 推导方式一
由预测函数推导
![预测函数]()
没有其他特别的,依然是似然函数开始
![在这里插入图片描述]()
接着取对数
![在这里插入图片描述]()
l(θ)取最大值是我们最希望,但通常优化的习惯是取最小值,所以这里取-l(θ), 整理后,可得如下
![在这里插入图片描述]()
代入得到
![在这里插入图片描述]()
这个就是逻辑回归的损失函数。
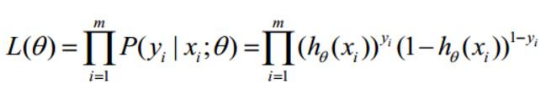
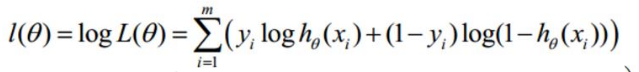
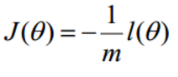
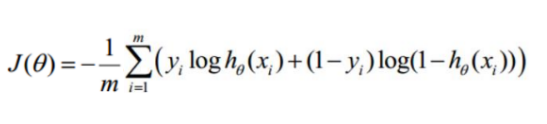
求导

- 推导方式二
逻辑回归解决的是二分类问题,设y是我们目标值(1, 0),p则是预测概率值,
若y的真实值为1,则预测的p越大,损失越小,预测的p越小,损失越大
若y的真实值为0,而预测的p越大,损失越大,预测的p越小,损失越小
那么我可以设定损失函数为
![在这里插入图片描述]()
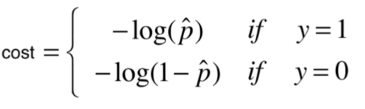
我们下y=1和y=0时,损失函数的图像
代码示例
from matplotlib import pyplot as plt
from matplotlib import font_manager
import numpy as np
font = font_manager.FontProperties(fname="/usr/share/fonts/wps-office/msyhbd.ttf", size=12)
def log(t):
return np.log(t)
p = np.arange(0.1, 1, 0.1)
y1 = -log(p)
y2 = -log(1-p)
plt.plot(p, y1, label='y=1')
plt.plot(p, y2, label='y=0')
plt.legend(prop=font, loc='best')
plt.show()
得到

对损失函数进行下整合得到
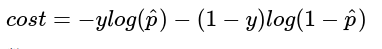
然后得到损失函数
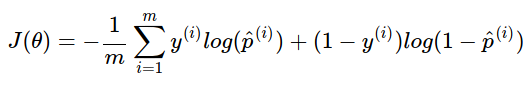
与第一个方式推导结果相同。
4.鸢尾花示例
# coding:utf-8
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from matplotlib import pyplot as plt
from matplotlib import font_manager
font = font_manager.FontProperties(fname="/usr/share/fonts/wps-office/msyhbd.ttf", size=15)
def logist_fun():
# 加载数据集
iris = datasets.load_iris()
x = iris.data # 特征值
y = iris.target # 目标值
# 目标值有三个,这里只取0和1,做二分类演示
data = pd.DataFrame(x)
data['y'] = y
data = data[data['y'] !=2 ]
print(data)
x = data.loc[:,[0, 1, 2, 3]]
y = data.loc[:, 'y']
print(x)
# 分割数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=102)
# 标准化
stand = StandardScaler()
x_train = stand.fit_transform(x_train)
x_test = stand.transform(x_test)
# 建立模型
lr = LogisticRegression(C=1.0)
lr.fit(x_train, y_train)
y_predict = lr.predict(x_test)
score = lr.score(x_test, y_test)
print("准确率{}".format(score))
return y_predict, y_test
def draw_fun(y_predict, y_test):
x = range(1,len(y_predict)+1)
plt.figure(figsize=(25, 5), dpi=80)
plt.scatter(x, y_test, label="真实值",color='blue', linewidths=20)
plt.scatter(x, y_predict,label='预测值', color='red', linewidths=3)
x_tick = list(x)
y_tick = list(range(0,3))
plt.legend(prop=font, loc='upper left')
plt.xticks(list(x), x_tick)
plt.yticks(y_tick)
plt.grid(alpha=0.8)
plt.show()
if __name__ == '__main__':
y_predict, y_test = logist_fun()
draw_fun(y_predict, y_test)
结果如图

5.逻辑回归的决策边界
以鸢尾花数据集为例子,简单化,只取前两个特征,和目标值为0和1的数据集,然后画下分布图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from sklearn import datasets
font = font_manager.FontProperties(fname="/usr/share/fonts/wps-office/msyhbd.ttf", size=15)
iris = datasets.load_iris()
x = iris.data # 特征值
y = iris.target # 目标值
data = pd.DataFrame(x)
data['y'] = y
# 目标值有三个,这里只取0和1, 特征值也只取两个,做二分类演示
data = data[data['y'] != 2].loc[:, [0, 1, 'y']]
X0_0 = data[data['y']==0].loc[:,0]
X0_1 = data[data['y']==0].loc[:,1]
X1_0 = data[data['y']==1].loc[:,0]
X1_1 = data[data['y']==1].loc[:,1]
print(data.head())
plt.scatter(X0_0, X0_1, color='blue')
plt.scatter(X1_0, X1_1, color='red')
plt.show()
图像如下
 我们设定的阈值为0.5,也就是
我们设定的阈值为0.5,也就是
等于0.5, 则
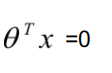
在示例中,则有
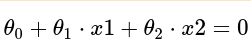
其中θ0 是偏置, θ1和θ2是系数,x1和x2是特征值,转换后,有
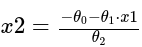
修改下代码绘制决策边界
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
font = font_manager.FontProperties(fname="/usr/share/fonts/wps-office/msyhbd.ttf", size=15)
iris = datasets.load_iris()
x = iris.data # 特征值
y = iris.target # 目标值
data = pd.DataFrame(x)
data['y'] = y
# 目标值有三个,这里只取0和1, 特征值也只取两个,做二分类演示
data = data[data['y'] != 2].loc[:, [0, 1, 'y']]
# 逻辑回归
x = data.loc[:,[0, 1]]
y = data.loc[:, 'y']
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=102)
logic_reg = LogisticRegression()
logic_reg.fit(x_train, y_train)
# x2特征值和x1的关系
def x2(x1):
global logic_reg
return (-logic_reg.intercept_[0] - logic_reg.coef_[0][0] * x1)/logic_reg.coef_[0][1]
X0_0 = data[data['y']==0].loc[:,0]
X0_1 = data[data['y']==0].loc[:,1]
X1_0 = data[data['y']==1].loc[:,0]
X1_1 = data[data['y']==1].loc[:,1]
x1_plot = np.arange(4,8)
x2_Plot = x2(x1_plot)
plt.scatter(X0_0, X0_1, color='blue')
plt.scatter(X1_0, X1_1, color='red')
plt.plot(x1_plot,x2_Plot)
plt.show()
结果如下

6.添加多项式扩展
对于线性的分类,决策边界,就是类似一条直线,那如果是非线性的,如下图

它的决策边界是类似一个椭圆,这时候可以引入多项式。
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
from matplotlib.colors import ListedColormap
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
font = font_manager.FontProperties(fname="/usr/share/fonts/wps-office/msyhbd.ttf", size=15)
# 构造数据集
np.random.seed(666)
X = np.random.normal(0, 1, size=(500, 2))
y = np.array(X[:,0]**2 + X[:,1]**2 < 1.5, dtype='int')
def pnf(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1)
)
x_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(x_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap)
poly_log_reg = pnf(degree=2)
poly_log_reg.fit(X, y)
plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
如图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号