「杂文」蒙特卡洛树搜索算法实现黑白棋 AI
写在前面
人工智能实验报告。
妈的我真的不会写实验报告,感觉一堆屁话
妈的下棋下不过爆搜,感觉大脑被白子雷普了
白子?白子……嘿嘿嘿我的白子
实验内容
黑白棋是一个经典的策略性游戏,一般棋子双面为黑白两色。因为行棋之时将对方棋子翻转,则变为己方棋子,又称翻转棋(Reversi)。游戏使用 \(8\times 8\) 的棋盘,通过相互翻转对方的棋子,最后以棋盘上谁的棋子多来判断胜负。
游戏规则:
-
棋局开始时,两个黑棋位于 E4 和 D5,两个白棋位于 D4 和 E5,如下图所示:

-
黑方先行,双方交替下棋。
-
一步合法的棋步包含:在一个空格新落下一个棋子,并且反转对手至少一个棋子;新落下的棋子与棋盘上已有的同色棋子间,对方被夹住的所有棋子都要反转过来。可以横向、纵向、沿对角线夹,夹住的位置上必须全部都是对手的棋子,不能有空格。
-
一步合法棋可以在数个(横向、纵向、对角线)方向上翻棋,任何被夹住的对手棋子都必须被翻转过来,棋手无权选择不去翻某个棋子。
-
若一方没有合法棋步,则该方这一轮只能弃权,由对手落子,
-
若一方至少有一步合法棋步可下,则该方必须落子,不得弃权。
-
棋局持续下去,直到棋盘填满或者双方都无合法棋步可下。
实验要求
- 使用蒙特卡洛树搜索算法实现。
- 使用 Python 语言。
- 蒙特卡洛树搜索算法部分需要自行实现,不得使用现存的包、工具或接口。
实验环境
- Python 3.9.12
- Anaconda3-2024.02-1-Windows-x86_64
- QT6 6.4.1
- Qt Creator 8.0.2
实验原理
蒙特卡洛方法(Monte Carlo method)
蒙特卡罗方法(英语:Monte Carlo method),也称统计模拟方法,是1940年代中期提出的一种以概率统计理论为指导的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。
通常蒙特卡罗方法可以粗略地分成两类:
- 一类是所求解的问题本身具有内在的随机性,借助计算机的运算能力可以直接模拟这种随机的过程。
- 另一种类型是所求解问题可转化为某种随机分布的特征数,通过随机抽样的方法以随机事件出现的频率估计其概率,或以抽样的数字特征估算随机变量的数字特征并将其作为问题的解。
在解决实际问题的时候应用蒙特卡罗方法主要有两部分工作:
- 用蒙特卡罗方法模拟某一过程时,需要产生各种概率分布的随机变量。
- 用统计方法把模型的数字特征估计出来,从而得到实际问题的数值解。
蒙特卡洛树搜索(Monte Carlo tree search)
蒙特卡洛树搜索(英语:Monte Carlo tree search;简称:MCTS)是一种用于某些决策过程的启发式搜索算法,一个主要的使用例是电脑围棋程序。该算法将蒙特卡洛方法中的随机抽样方法用于游戏树搜索中,用于求解游戏中某给定局面的较优操作策略。
蒙特卡洛树搜索的每个循环包括如图所示的四个步骤:

- 选择(Selection):从根节点 R 开始,连续向下按照某种策略选择子节点至叶子节点 L,令游戏树向最优的方向扩展,这是蒙特卡洛树搜索的精要所在。
- 扩展(Expansion):除非任意一方的输赢使得游戏在叶节点 L 结束,否则根据操作创建一个或多个子节点并选取其中一个子节点 C。
- 仿真(Simulation):再从节点 C 开始,用随机策略进行游戏。
- 反向传播(Backpropagation):使用随机游戏的结果,更新从 C 到 R 的路径上的节点信息(访问次数与奖励值)。
在选择过程中,选择子结点的主要困难是:在较高平均胜率的移动后,在对深层次变型的利用和对少数模拟移动的探索,这二者中保持某种平衡。第一个在游戏中平衡利用与探索的公式被称为UCT(Upper Confidence Bounds to Trees,上限置信区间算法 ),基于 UCB1 公式,在选择子结点 C 尽量使下列表达式具有最大值:
其中:
- \(w_c\):子节点 C 的奖励值,在对其子节点进行树搜索的反向传播过程中更新。
- \(n_c\):子节点 C 的访问次数,同上。
- \(n_u\):父节点的访问次数。
目前蒙特卡洛树搜索的实现大多是基于 UCT 的一些变形,本次实验的蒙特卡洛树搜索算法基于上述经典 UCB1 公式进行。
实验思路
考虑使用蒙特卡洛树搜索算法解决黑白棋问题。
具体地,考虑定义棋盘类用于描述某时刻的棋盘状态与完成棋盘操作,定义节点类用于建立蒙特卡洛树搜索的结构,定义 AI 类用于完成蒙特卡洛树搜索算法并给出某棋盘状态下 AI 的最优解。上述三个类中的算法具体描述如下。
棋盘类
- 使用 \(8\times 8\) 的二维列表描述棋盘状态,列表中每个位置与棋盘中的每个位置一一对应。
- 支持对当前棋盘状态的如下操作:
- 对某一颜色求解当前可落子位置:枚举每个位置检查落子是否合法。
- 检查当前棋盘状态是否结束:检查两方是否均有合法落子位置。
- 对当前棋盘状态进行落子操作:枚举落子位置周围八个方向检查是否成功使对方棋子翻转。
- 求棋盘上两方棋子数量。
节点类
用于描述蒙特卡洛树搜索中的节点状态,与游戏时的棋盘状态一一对应。
则其中应有属性:
- 用于描述当前游戏状态:当前棋盘状态,当前一步玩家的颜色。
- 用于描述树的结构:父节点,子节点列表。
- 用于描述当前状态的最优行为:当前一步行动。
- 用于进行蒙特卡洛树搜索算法的参数:节点的访问次数,奖励值。
用于维护树的结构的方法:
- 检查是否所有代表下一棋盘状态的子节点是否均被建立。
- 建立子节点。
AI 类
对于某棋盘状态,基于节点类建立根节点 R,若干次运行上述实验原理中四个步骤求解较优操作策略。
四个步骤描述如下:
- 选择:连续向下按照 UCB 公式选择较优子节点,以一定概率进行扩展,并继续选择较优子节点直至叶子节点 L。
- 扩展:对于某节点,若它不为叶节点 L,则随机创建代表下一游戏状态的一个子节点。
- 仿真:对于某通过选择过程得到的叶节点,则在当前游戏状态交替进行若干次随机合法落子操作,根据最终黑白子数量差得到奖励值,并进行反向传播。
- 反向传播:使用随机游戏的结果,更新从 C 到 R 的路径上的节点信息(访问次数与奖励值)。
进行若干次操作后,对 R 按照 UCB 公式选择最优子节点,并将棋盘状态更新为子节点的状态。
代码结构
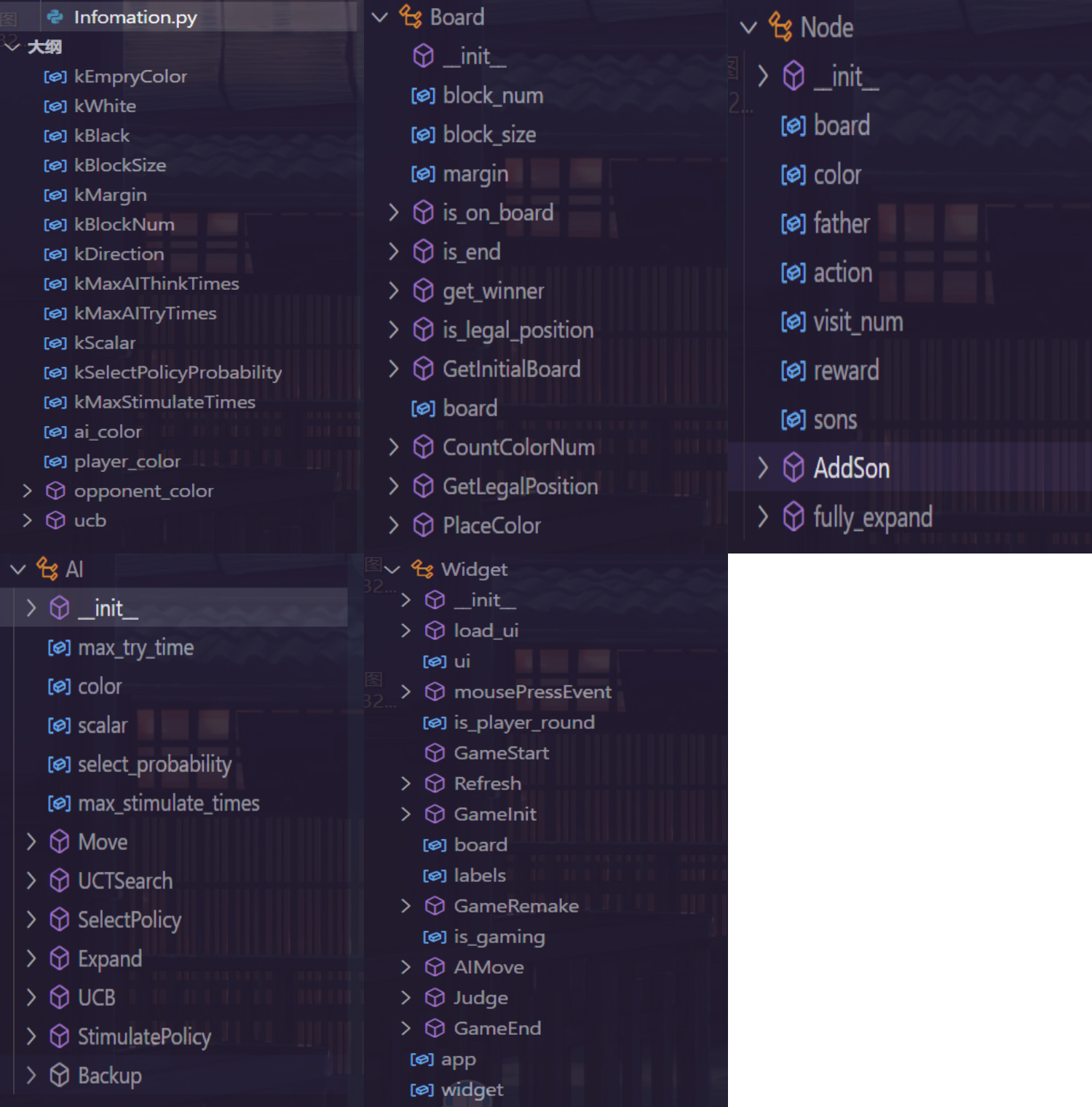
Infomation.py
用于存储全局常量与全局变量、全局函数。
- 为 Board 类提供棋盘信息。
- 为 Node 类、AI 类提供蒙特卡洛树搜索算法的参数与估值函数
ucb。 - 为 Widget 类提供游戏信息。
Board.py
棋盘类,包含属性:
block_num:棋盘上格子数量。block_size:棋盘上格子大小。margin:棋盘四周的空白宽度。
包含方法:
- 初始化方法
__init__()。 is_on_board(x, y):用于检查给定的坐标 \((x, y)\) 是否在棋盘范围内。is_end():检查游戏是否结束,即棋盘上是否没有合法的落子点。get_winner():获取游戏胜利者及胜利方与失败方的棋子数量之差。若游戏没有结束,返回 (-1, 0)。is_legal_position(x, y, color):判断给定坐标 \((x, y)\) 是否是color的合法的落子点,即判断坐标是否在棋盘内,且该位置为空,且在该位置落子后至少翻转了一个对手的棋子。GetInitialBoard():初始化棋盘。CountColorNum(color):统计指定颜色的棋子数量。GetLegalPosition(color):获取指定颜色的合法落子点。PlaceColor(x, y, color, is_test=False):在指定位置落子,并翻转对方的棋子并返回翻转棋子的数量。若 is_test 参数为 True,则只进行测试,不实际进行落子和翻转操作。
Node.py
蒙特卡洛树搜索的节点类,包含属性:
board:当前棋盘状态。color:当前一步玩家的颜色。father:父节点。action:当前一步行动。visit_num:节点的访问次数。reward:奖励值。sons:子节点列表。
包含方法:
- 初始化方法
__init__(board, color, father, action)。、 AddSon(board, action, color):向当前节点添加一个新的子节点。fully_expand():检查当前节点是否完全扩展。
AI.py
AI 的操作类,在其中进行蒙特卡洛树搜索算法。包含属性:
max_try_time:每次进行 UCT 搜索时的最大模拟次数。color:AI 的棋子颜色scalar:UCB 公式中的参数。select_probability:控制节点进行选择策略时一定概率选择不扩展的参数、max_stimulate_times:在节点处随机模拟时的最大模拟步数。
包含方法:
- 初始化方法
__init__(color)。 Move(board):创建根节点,调用 UCT (Upper Confidence Bound applied to Trees)搜索方法来选择最佳的落子位置。UCTSearch(root):多次调用SelectPolicy、StimulatePolicy和Backup方法来模拟最优策略并更新树节点,返回最优策略。SelectPolicy(node):在当前节点进行策略的选择,根据 UCB 公式选择具有最高置信上限的子节点,若节点未完全扩展则扩展节点,同时有一定概率在可扩展时也不扩展。Expand(node):扩展节点,在当前节点进行一次合法操作并创建新的子节点。UCB(node, scalar):根据 UCB 公式计算置信上限值,并选择具有最高置信上限值的子节点作为下一步动作。StimulatePolicy(node):在当前节点进行若干步随机模拟,根据模拟结果确定该节点的奖励值。Backup(node, reward):完成模拟得到奖励值后将结果反向传播到根节点,更新每个节点的访问次数和奖励值。
Widget.py
定义了用户界面 Widget 类,实现了黑白棋的游戏逻辑。
主要包含方法:
mousePressEvent:在玩家回合响应玩家在棋盘上的点击动作,根据点击位置进行落子并更新棋盘状态。GameStart():初始化棋盘并开始游戏。Refresh():刷新棋盘状态。GameInit():初始化游戏,创建棋盘对象并显示初始局面。GameRemake():重新开始游戏。AIMove():AI进行落子,调用AI.move选择最优的落子位置。Judge():判断游戏是否结束,若未结束则检查当前落子方是否有合法落子位置,若无则轮到另一方。GameEnd():游戏结束处理,弹出对话框显示胜负结果,并询问是否重新开始游戏。
运行结果

游戏初始状态截图

游戏进行截图

游戏结束截图
代码
Github 项目地址:https://github.com/Luckyblock233/Othello。
写在最后
算法原理参考:
算法实现参考:
- 主要参考:蒙特卡洛搜索实现黑白棋 _ 摸黑干活
- 深度解析黑白棋AI代码原理(蒙特卡洛搜索树MCTS+Roxanne策略)-CSDN博客
- 手撕蒙特卡洛树搜索算法_Monte Carlo Tree Search (MCTS),包括完整的 Python 代码实现 - 知乎
GUI 实现参考:
- 主要参考:Python+PyQt5实现五子棋游戏(人机博弈+深搜+α-β剪枝)_人机博弈案例大全-CSDN博客
- PyQt5之QMessageBox弹出式对话框_qmessagebox.show-CSDN博客
- pyqt QLabel详细用法_pyqt label-CSDN博客
- [PyQt5]基本控件9 - 图片显示QPixmap_pyqt5图片控件-CSDN博客
- pyqt5 Qlabel关于图片的展示_pyqt5 qlabel显示图像-CSDN博客
- PyQt5 随笔:信号与槽的两种使用方法:@pyqtSlot() 和 connect()-CSDN博客
捉虫参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号