P1074 靶形数独
知识点: 搜索, 剪枝
原题面
题目要求:
给定一 \(9 \times 9\) 的方格图, 部分方格中的数已知
要求将此方格图填数, 满足下列要求:
- 每一个下图中所示 \(3 \times 3\)方格图中 不得出现重复的数
- 每一行不出现 重复的数
- 每一列不出现 重复的数
同时, 每一个位置 都有 一个分值, 各位置分值按照下图所示 :
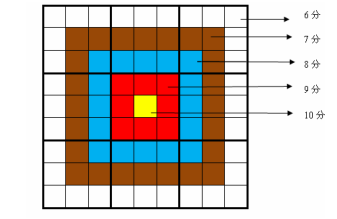
总分数即 每个方格上的分值和数字的乘积 的总和
求最大的总分数
分析题意:
似乎并没有什么 时间复杂度较低的方法,
能在保证正确性的情况下, 找到最优解 .
考虑使用搜索, 枚举各位置,
构造合法填数方案, 求每一合法填数方案分数的最大值
-
关于不重复出现的判断 :
题目要求 每一小九宫格, 每一行, 每一列都不出现重复数
考虑对 每一小九宫格, 每一行, 每一列, 可以选择的数的集合进行状压.
某一二进制上为 \(1\) , 代表此位置对应的数可以选择, 否则不可选择通过集合的性质 ,
对于每一个位置, 其上述三集合的并集, 即为此位置可选择的数的集合
选择 三个集合的并集 中的数 一定不会导致出现重复选择的情况
按照此方法构造的矩阵, 一定合法可以使用 \(lowbit\) 运算 来枚举二进制位上的 \(1\) , 以减少时间复杂度
实现了 上述过程后, 即可取得 \(80\) 分的好成绩(大雾
似乎找不到别的 常规方法进行优化
结合题目给定模型的性质 进行考虑 :
- 继续优化 :
当一个位置是 \(0\) 时, 才需要填数
显然 , 一个 \(0\) 位置 能够填入的数的个数, 会影响之后搜索的次数- 若一位置 可填入数的个数为 \(9\) , 从此位置可向下 \(dfs\) \(9\) 次
若一位置 可填入数的个数为 \(2\) , 只需从此位置向下\(dfs\) \(2\) 次即可
- 若一位置 可填入数的个数为 \(9\) , 从此位置可向下 \(dfs\) \(9\) 次
故应优先选择 可填入的数 较少的位置 进行搜索
为便于实现 , 将每行按照 \(0\) 的个数 进行排序, 先从 \(0\) 较少的行开始搜
#include <cstdio>
#include <ctype.h>
#include <algorithm>
#define lowbit(x) (x & - x)
#define max std::max
const int MARX = 15;
const int W[MARX][MARX] =//每一个未知的价值
{
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0, 6, 6, 6, 6, 6, 6, 6, 6, 6},
{0, 6, 7, 7, 7, 7, 7, 7, 7, 6},
{0, 6, 7, 8, 8, 8, 8, 8, 7, 6},
{0, 6, 7, 8, 9, 9, 9, 8, 7, 6},
{0, 6, 7, 8, 9,10, 9, 8, 7, 6},
{0, 6, 7, 8, 9, 9, 9, 8, 7, 6},
{0, 6, 7, 8, 8, 8, 8, 8, 7, 6},
{0, 6, 7, 7, 7, 7, 7, 7, 7, 6},
{0, 6, 6, 6, 6, 6, 6, 6, 6, 6}
};
const int BEL[MARX][MARX] =//每一个位置 所在小矩阵的编号
{
{0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0, 1, 1, 1, 2, 2, 2, 3, 3, 3},
{0, 1, 1, 1, 2, 2, 2, 3, 3, 3},
{0, 1, 1, 1, 2, 2, 2, 3, 3, 3},
{0, 4, 4, 4, 5, 5, 5, 6, 6, 6},
{0, 4, 4, 4, 5, 5, 5, 6, 6, 6},
{0, 4, 4, 4, 5, 5, 5, 6, 6, 6},
{0, 7, 7, 7, 8, 8, 8, 9, 9, 9},
{0, 7, 7, 7, 8, 8, 8, 9, 9, 9},
{0, 7, 7, 7, 8, 8, 8, 9, 9, 9}
};
//=============================================================
struct Line
{
int x, cnt;
}line[MARX];//记录, 每一行中 0的数量, 来确定搜索的顺序
int ans, MAP[MARX][MARX], que[MARX * MARX][3];//que: 各位置搜索的顺序
//sma:小矩形内 可选择数的状态; bigx,y:大矩形内 各行各列可选择数的状态
int usesma[MARX], usebigx[MARX], usebigy[MARX];
int Log2[1050];
//=============================================================
inline int read()
{
int s = 1, w = 0; char ch = getchar();
for(; !isdigit(ch); ch = getchar()) if(ch == '-') s = -1;
for(; isdigit(ch); ch = getchar()) w = (w << 1) + (w << 3) + (ch ^ '0');
return s * w;
}
bool cmp(Line fir, Line sec) {return fir.cnt < sec.cnt;}
void Prepare()
{
for(int i = 1; i <= 9; i ++) Log2[(1 << i)] = i;//预处理log2
for(int i = 1; i <= 9; i ++) line[i].x = i;//各行的序号
for(int i = 1; i <= 9; i ++) //初始化 小矩形内 可选择数的状态, 大矩形内 各行各列可选择数的状态
usesma[i] = usebigx[i] = usebigy[i] = (1 << 10) - 2;
for(int x = 1; x <= 9; x ++)//读入矩阵, 并计算每行0的个数
for(int y = 1; y <= 9; y ++)
MAP[x][y] = read(),
line[x].cnt += (MAP[x][y] == 0);
for(int i = 1; i <= 9; i ++) //枚举各位置, 更新可选择数的状态
for(int j = 1; j <= 9; j ++)
usebigx[i] ^= (1 << MAP[i][j]) ,
usebigy[j] ^= (1 << MAP[i][j]) ,
usesma[BEL[i][j]] ^= (1 << MAP[i][j]);
std :: sort(line + 1, line + 9 + 1, cmp);//按照0的个数, 对每一行进行排序
for(int i = 1, tot = 0; i <= 9; i ++)//根据排序后的结果, 确定搜索的顺序
for(int j = 1; j <= 9; j ++)
que[++ tot][1] = line[i].x,
que[tot][2] = j;
}
void Dfs(int now, int sum)
{
if(now > 81) {ans = max(ans, sum); return;}//所有位置 全部填完
int nowx = que[now][1], nowy = que[now][2], bel = BEL[nowx][nowy];//记录当前位置
if(MAP[nowx][nowy]) {Dfs(now + 1, sum + MAP[nowx][nowy] * W[nowx][nowy]); return ;}//当前位置 已被填过
int choose = (usesma[bel] & usebigx[nowx] & usebigy[nowy]);//三个 可选择的集合的交集, 即为此位置可选择的数的集合
for(int i = lowbit(choose); choose; choose -= i, i = lowbit(choose))//使用lowbit 取出可选择的数
{
if(i == 1) continue;//log2(1) = 0, 各位置不可填0, 故continue
MAP[nowx][nowy] = Log2[i];//填入
usesma[bel] ^= i, usebigx[nowx] ^= i, usebigy[nowy] ^= i;//更新可选择的数 的状态
Dfs(now + 1, sum + Log2[i] * W[nowx][nowy]);//搜索下一位置
MAP[nowx][nowy] = 0;//回溯
usesma[bel] |= i, usebigx[nowx] |= i, usebigy[nowy] |= i;
}
}
//=============================================================
int main()
{
Prepare();
Dfs(1, 0);
printf("%d", ans ? ans : - 1);
return 0;
}
作者@Luckyblock,转载请声明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号