

Elasticsearch.net项目实战
elasticsearch.net项目实战
目录
- Elasticsearch+kibana
- 环境搭建
- windows 10环境配置
- 安装Elasticsearch
- head安装(非必需)
- 安装kibana
- 基本概念
- Index
- Type
- Document
- DSL的基本使用
- 增加
- 修改
- 查询
- 删除
- 环境搭建
- Elasticsearch .Net
- Low level client基本使用
- 项目实战
- 总结
- 参考
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最
先进、性能最好的、功能最全的搜索引擎库。
一说到全文搜索,lucene久负盛名。早年间,因为项目需要,接触过一个叫盘古分词的开源项目,借助其中的分词实现了分词搜索的功能。而盘古分词就是lucence的.NET版本。据说这个开源项目已经恢复更新并支持. NET Core,有兴趣的童鞋可以去围观一下(https://github.com/LonghronShen/Lucene.Net.Analysis.PanGu/tree/netcore2.0)。
我想很多童鞋都听过ELK,ELK是Elasticsearch、Logstash、Kibana。正好公司运维同事引入了这样一套体系,用于建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。虽然能够从一定程度上解决基本的问题,但是原生的kibana界面和查询方式都不够友好,很难推向广大的开发人员。于是我在想,我们是否可以利用这个开源的库集成到运维自动化平台当中,让这把利剑发挥出更大的价值。
一、环境搭建
本文是基于windows 10操作系统的es环境的搭建。
- java环境安装
由于es是java语言开发的,所以这里要安装java环境。
jdk下载:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
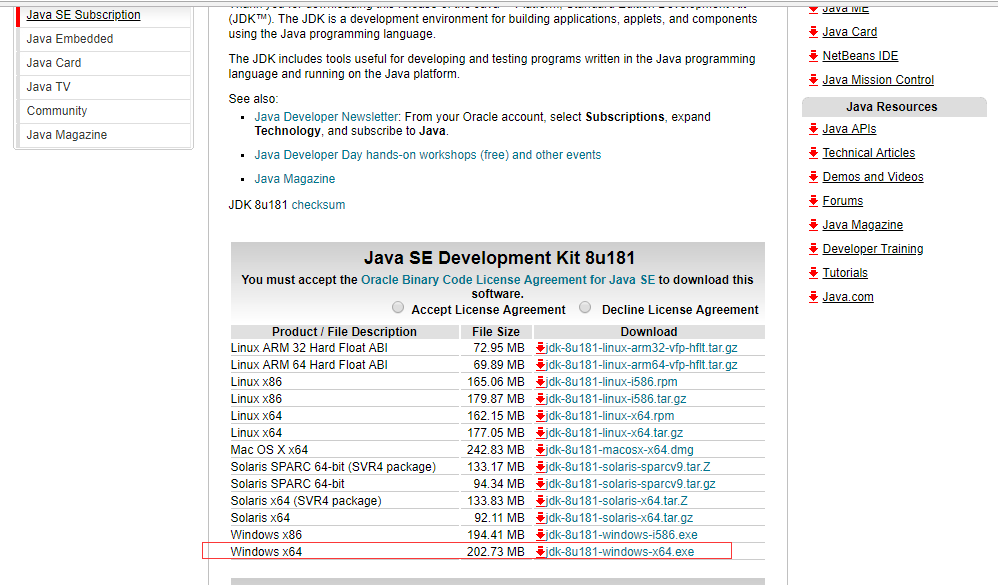
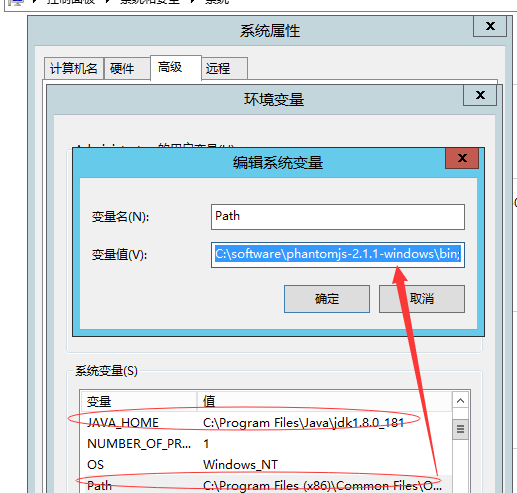
安装完成之后就是配置环境变量:
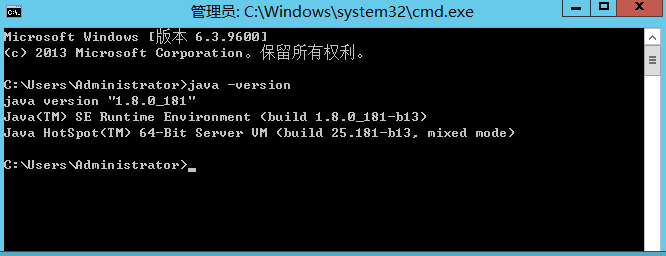
查看是否安装成功:
2.安装Elasticsearch
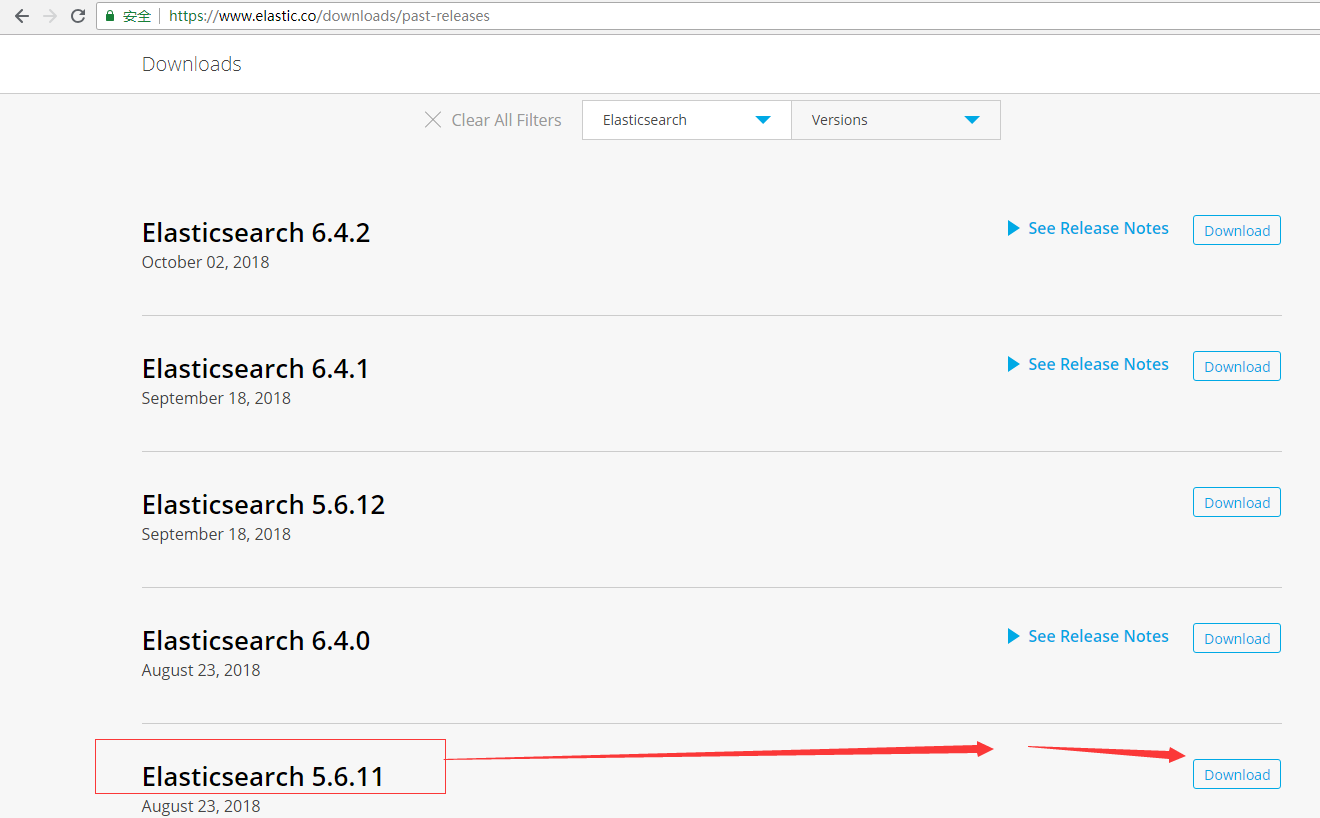
Elasticsearch版本已经比较多,初学者可能比较懵。特别是在安装head和Kibana的时候,如果版本不匹配,往往会导致无法使用。这里使用的是elasticsearch-5.6.11版本。
elasticsearch-5.6.11下载:
https://www.elastic.co/downloads/past-releases/elasticsearch-5-6-11
解压到C:\ELk 备用。
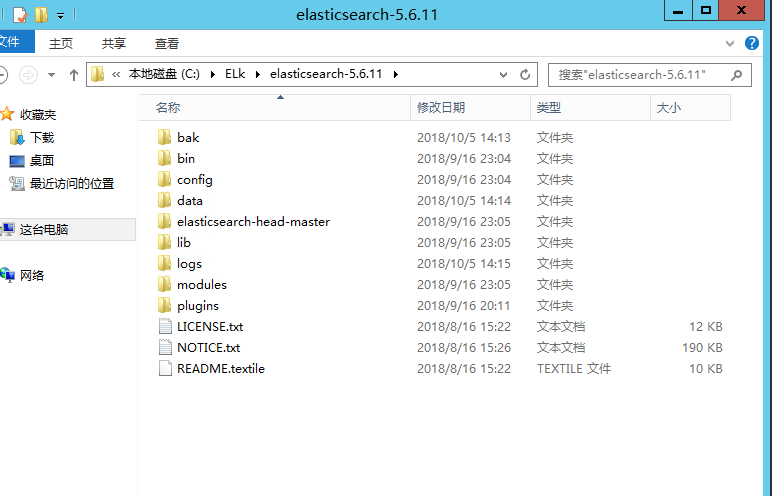
3.head安装(非必需)
es 4.x 版本安装head很简单,只需下载head插件解压到指定目录即可。es 5.x+需要借助node安装。
head下载:
解压到C:\ELk\elasticsearch-5.6.11
node下载:
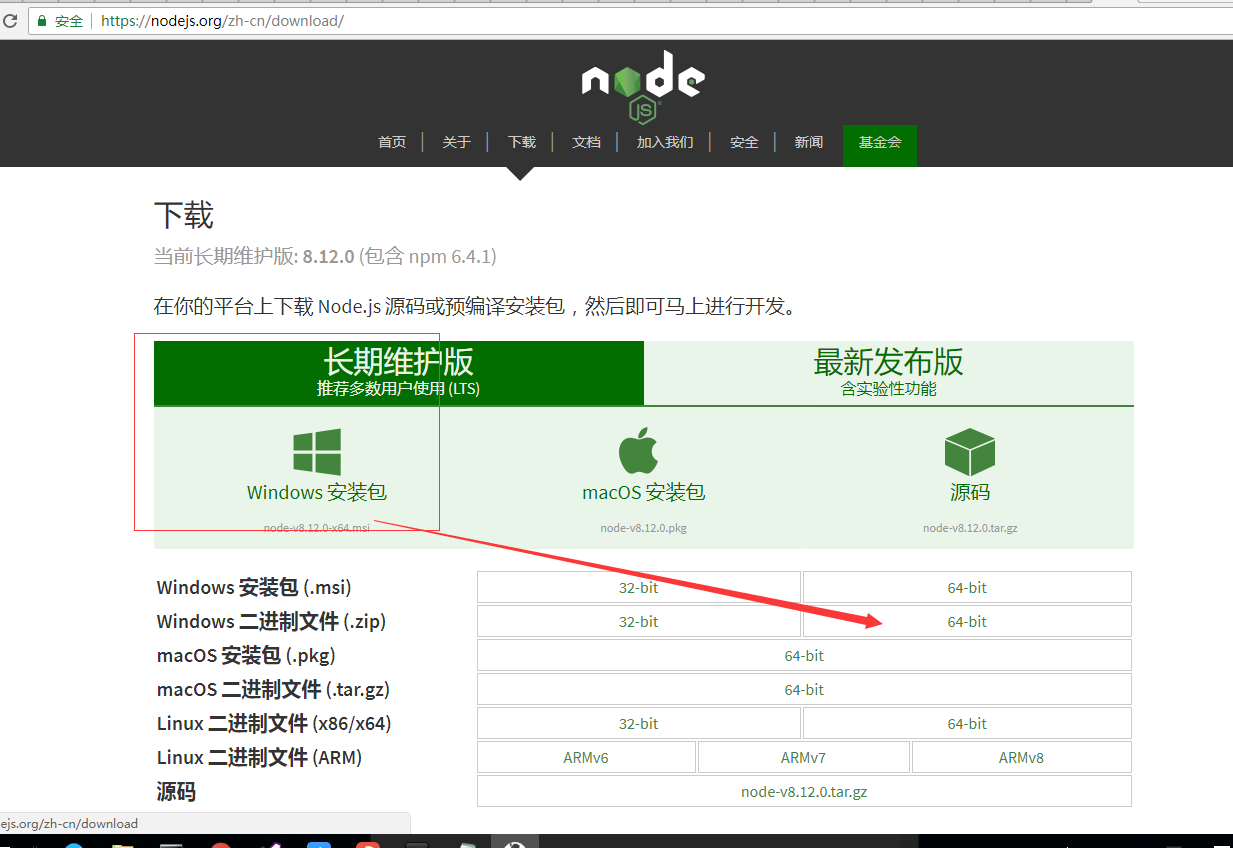
安装node
检查node和npm是否安装成功

path环境变量末尾 会自动增加 C:\Program Files\nodejs\
安装 phantomjs
官网:http://phantomjs.org/下载【配置环境变量】
安装grunt
npm install -g grunt-cli
执行C:\ELk\elasticsearch-5.6.11\bin\elasticsearch.bat
执行命令启动 head
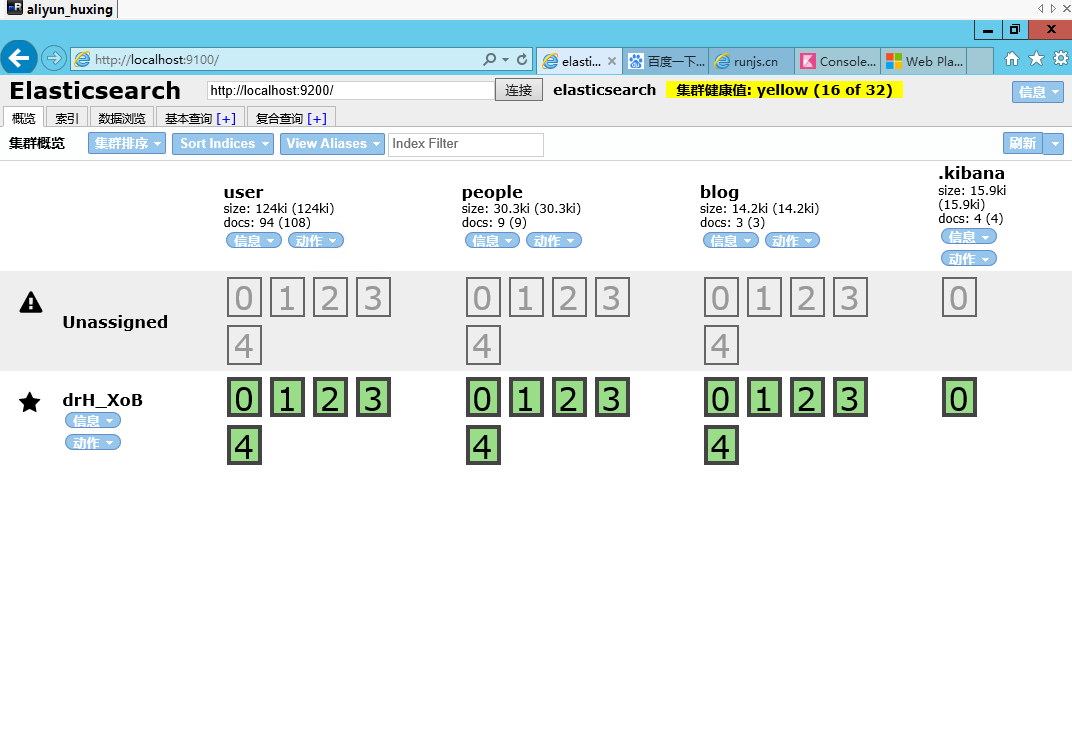
浏览器访问:http://localhost:9100/
4.安装kibana
导致为止,其实elasticsearch自身已经安装完成。通过Head就能很方便的操作es,但是kibana集成了head类似功能,并提供了更加友好的访问界面。
kibana-5.6.9-windows-x86下载:
下载之后,解压到C:\ELk\kibana-5.6.9-windows-x86
执行C:\ELk\kibana-5.6.9-windows-x86\bin\kibana.bat
浏览器访问:http://localhost:5601
二、基本概念
-
Cluster(集群)
集群是一个或多个节点(服务器)的集合,这些节点一起保存整个数据,并在所有节点上提供联合索引和搜索功能。
一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。

-
Node(节点)
节点是集群的一部分、存储数据并参与集群的索引和搜索功能的单个服务器。

-
Index
索引是具有相似特性的文档集合。
- 类似于关系型数据库中"库"的概念
-
Type
Type是具有一组公共字段的文档定义类型
例如,假设您运行一个博客平台并将所有数据存储在一个索引中。在该索引中,可以定义用户数据的类型、博客数据的另一种类型以及注释数据的另一种类型。
- 类似于关系型数据库中"表"的概念
-
Document
被索引信息的基本单元。
- 类似于关系型数据库的一个记录(行)
- 会被压缩成json格式
-
Shards & Replicas(分片&副本分片)
索引可以潜在地存储可以超过单个节点的硬件限制的大量数据。例如,占用1TB磁盘空间的十亿个文档的单个索引可能不适合单个节点的磁盘,或者可能太慢而无法单独为来自单个节点的搜索请求提供服务。
分片的两个主要原因:
- 它允许您水平分割/缩放您的内容卷。
- 它允许你分配和并行操作的碎片(可能在多个节点上)从而提高性能/吞吐量
在网络/云环境中,在任何时候都可以预期到故障,在碎片/节点不知何故脱机或由于任何原因消失的情况下,非常有用,并且强烈建议使用故障转移机制。为此,Elasticsearch允许您将一个或多个索引碎片的副本复制到称为副本碎片(replica shards)或简称为副本(replica)中。
复制是重要的两个主要原因:
- 在碎片/节点失败的情况下,它提供了高可用性。由于这个原因,需要注意的是,副本碎片永远不会分配到与原始/主碎片相同的节点上。
- 它允许您扩展搜索量/吞吐量,因为可以并行地在所有副本上执行搜索。
添加故障转移
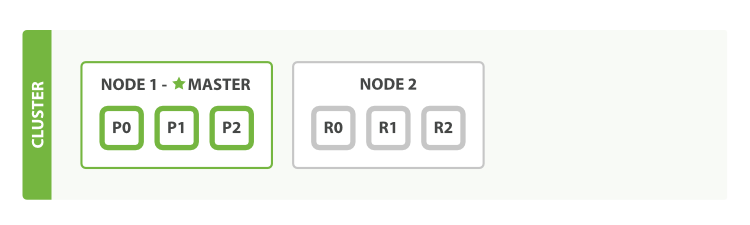
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。
拥有两个节点的集群——所有主分片和副本分片都已被分配。
三、DSL的基本使用
elasticsearch也像mysql一样提供了专门的语法来操作数据。Elasticsearch provides a full Query DSL (Domain Specific Language) based on JSON to define queries.
- 创建文档
PUT people/person/1?op_type=create
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
- 修改
POST /user/guest/20/_update
{
"doc": {
"RealName":"LukyHuu20"
}
}
- 查询
GET /user/guest/_search
{
"query": {
"match": {
"Id":22
}
}
}
- 删除
DELETE /user/guest/15
{
}
四、Elasticsearch .Net
elasticsearch是以restfulAPI方式对外提供接口,并提供客户端给多种语言使用。Elasticsearch uses standard RESTful APIs and JSON. We also build and maintain clients in many languages such as Java, Python, .NET, SQL, and PHP. Plus, our community has contributed many more. They’re easy to work with, feel natural to use, and, just like Elasticsearch, don't limit what you might want to do with them.
参考(https://www.elastic.co/products/elasticsearch)
1.Low level client基本使用
本文是介绍ES的.NET客户端,Elasticsearch .Net - Low level client[5.x]
通过引入对应的版本的客户端,便可通过C#操作ES。参考(https://www.elastic.co/guide/en/elasticsearch/client/net-api/5.x/elasticsearch-net.html)
连接
var settings = new ConnectionConfiguration(new Uri("http://example.com:9200"))
.RequestTimeout(TimeSpan.FromMinutes(2));
var lowlevelClient = new ElasticLowLevelClient(settings);
插入文档
var indexResponse = lowlevelClient.Index<byte[]>("user", "guest", user.Id.ToString(), user);
byte[] responseBytes = indexResponse.Body;
更新文档
var searchResponse = lowlevelClient.Update<string>("user", "guest", id.ToString(), new
{
doc = new
{
RealName = realname,
Description = description
}
});
bool successful = searchResponse.Success;
查询
var searchResponse = lowlevelClient.Search<string>("user", "guest", new
{
query = new
{
match = new
{
Id = id
}
}
});
bool successful = searchResponse.Success;
删除
var searchResponse = lowlevelClient.Delete<string>("user", "guest", id.ToString());
bool successful = searchResponse.Success;
2.项目实战
前面大致介绍了ES的安装和基本使用。那么,如何在项目中落地呢?
使用nuget安装Elasticsearch.Net 5.6.4
Install-Package Elasticsearch.Net -Version 5.6.4
安装完后,
基本的增删该查在项目中的实现上面已经有所介绍,这里重点讲一下查询:
笔者使用的.NET MVC5 Web框架,对于返回的结果笔者做了一个简单封装:
public class ESearchRoot<T>
{
/// <summary>
///
/// </summary>
public int took { get; set; }
/// <summary>
///
/// </summary>
public string timed_out { get; set; }
/// <summary>
///
/// </summary>
public _shards _shards { get; set; }
/// <summary>
///
/// </summary>
public Hits<T> hits { get; set; }
}
public class _shards
{
/// <summary>
///
/// </summary>
public int total { get; set; }
/// <summary>
///
/// </summary>
public int successful { get; set; }
/// <summary>
///
/// </summary>
public int skipped { get; set; }
/// <summary>
///
/// </summary>
public int failed { get; set; }
}
public class HitsItem<T>
{
/// <summary>
///
/// </summary>
public string _index { get; set; }
/// <summary>
///
/// </summary>
public string _type { get; set; }
/// <summary>
///
/// </summary>
public string _id { get; set; }
/// <summary>
///
/// </summary>
public string _score { get; set; }
/// <summary>
///
/// </summary>
public T _source { get; set; }
/// <summary>
///
/// </summary>
public List<int> sort { get; set; }
/// <summary>
///
/// </summary>
public Highlight highlight { get; set; }
}
public class Hits<T>
{
/// <summary>
///
/// </summary>
public int total { get; set; }
/// <summary>
///
/// </summary>
public string max_score { get; set; }
/// <summary>
///
/// </summary>
public List<HitsItem<T>> hits { get; set; }
}
public class Highlight
{
/// <summary>
///
/// </summary>
public List<string> Description { get; set; }
}
因为soure返回的对象是不定的,所以使用了泛型。
本项目soure对应的类,user:
///<summary>
///
/// </summary>
public class User
{
/// <summary>
///
/// </summary>
public string Account { get; set; }
/// <summary>
///
/// </summary>
public string Phone { get; set; }
/// <summary>
///
/// </summary>
public string Email { get; set; }
/// <summary>
///
/// </summary>
public string RealName { get; set; }
/// <summary>
///
/// </summary>
public string CanReview { get; set; }
/// <summary>
///
/// </summary>
public string CanExcute { get; set; }
/// <summary>
///
/// </summary>
public string Avatar { get; set; }
/// <summary>
///
/// </summary>
public string IsUse { get; set; }
/// <summary>
///
/// </summary>
public int Id { get; set; }
/// <summary>
///
/// </summary>
public string Name { get; set; }
/// <summary>
///
/// </summary>
public string Description { get; set; }
/// <summary>
///
/// </summary>
public DateTime CreateTime { get; set; }
/// <summary>
///
/// </summary>
public DateTime ModifyTime { get; set; }
}
项目使用了带条件的分页查询:
public List<AdminUser> GetBySomeWhere(string keyword, int limit, int pageSize, out int total)
{
List<AdminUser> users = new List<AdminUser>();
total = 0;
try
{
var settings = new ConnectionConfiguration(new Uri("http://localhost:9200/"))
.RequestTimeout(TimeSpan.FromMinutes(2));
var lowlevelClient = new ElasticLowLevelClient(settings);
//根据不同的参数 来构建不同的查询条件
var request = new object();
if (!String.IsNullOrEmpty(keyword))
{
request = new
{
from = limit,
size = pageSize,
query = new
{
match = new
{
Description = keyword
}
},
highlight = new
{
fields = new
{
Description = new { }
}
},
sort = new
{
Id = new
{
order = "desc"
}
}
};
}
else
{
request = new
{
from = limit,
size = pageSize,
query = new
{
match_all = new
{
}
},
highlight = new
{
fields = new
{
Description = new { }
}
},
sort = new
{
Id = new
{
order = "desc"
}
}
};
}
var searchResponse = lowlevelClient.Search<string>("user", "guest", request);
bool successful = searchResponse.Success;
var responseJson = searchResponse.Body;
if (!successful)
{
return users;
}
ESearchRoot<User> root = JsonHelper.JSONStringObject<ESearchRoot<User>>(responseJson);
if (root != null)
{
total = root.hits.total;
foreach (HitsItem<User> item in root.hits.hits)
{
if (item._source != null)
{
string highlightDescription = String.Empty;
StringBuilder sbDs = new StringBuilder();
if (item.highlight != null && item.highlight.Description.Count > 0)
{
//ighlightDescription = item.highlight.Description[0];
foreach (var d in item.highlight.Description)
{
sbDs.Append(d);
}
highlightDescription = sbDs.ToString();
}
AdminUser user = new AdminUser
{
Id = item._source.Id,
RealName = item._source.RealName,
Account = item._source.Account,
Email = item._source.Email,
Phone = item._source.Phone,
//IsUse=item._source.IsUse,
Avatar = item._source.Avatar,
Description = item._source.Description,
HighlightDescription = highlightDescription,
CreateTime = item._source.CreateTime,
ModifyTime = item._source.ModifyTime
};
users.Add(user);
}
}
}
return users;
}
catch (ElasticsearchClientException ex)
{
//Log4Helper.Error
}
return users;
}
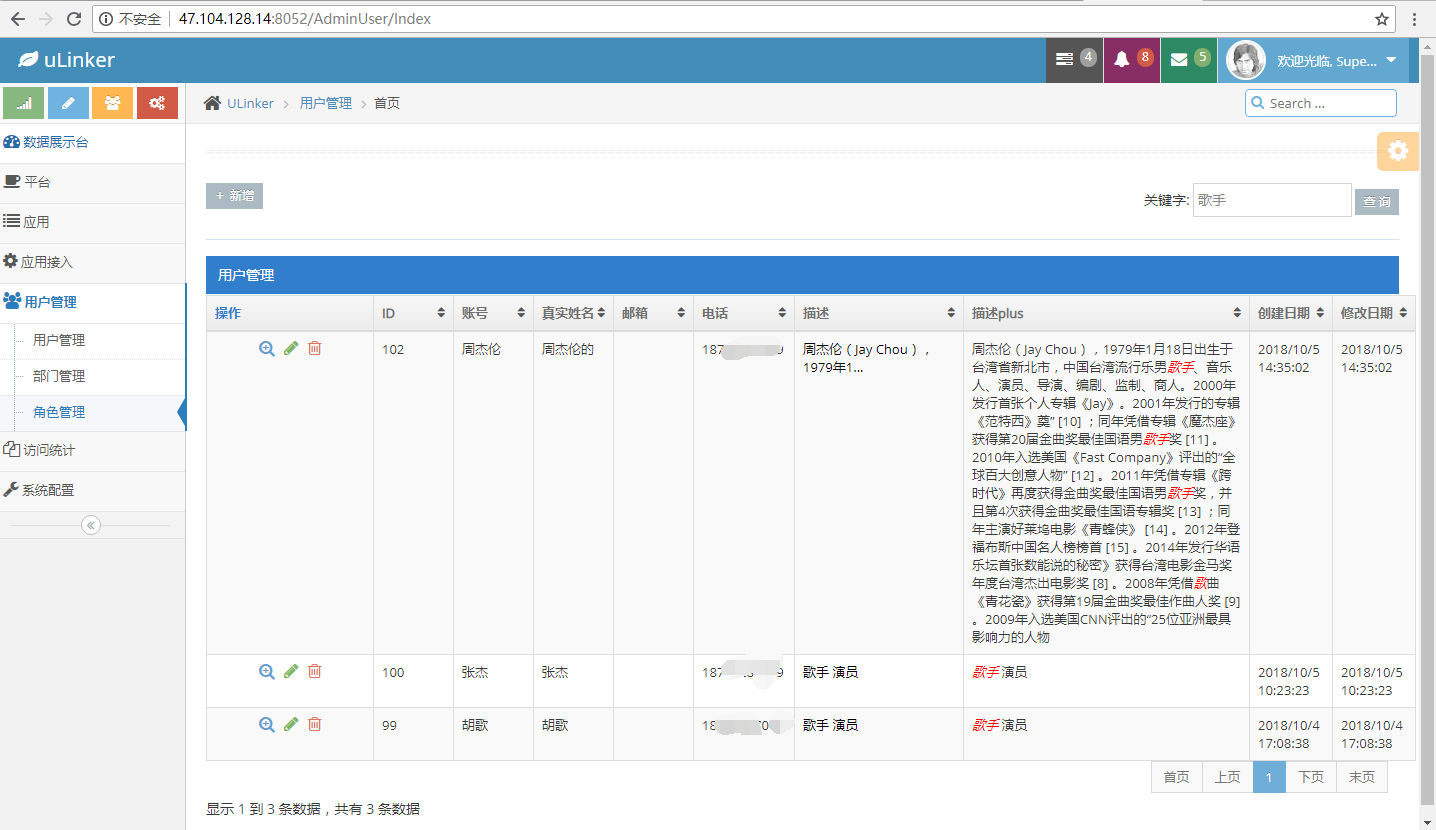
项目最终的效果如下:
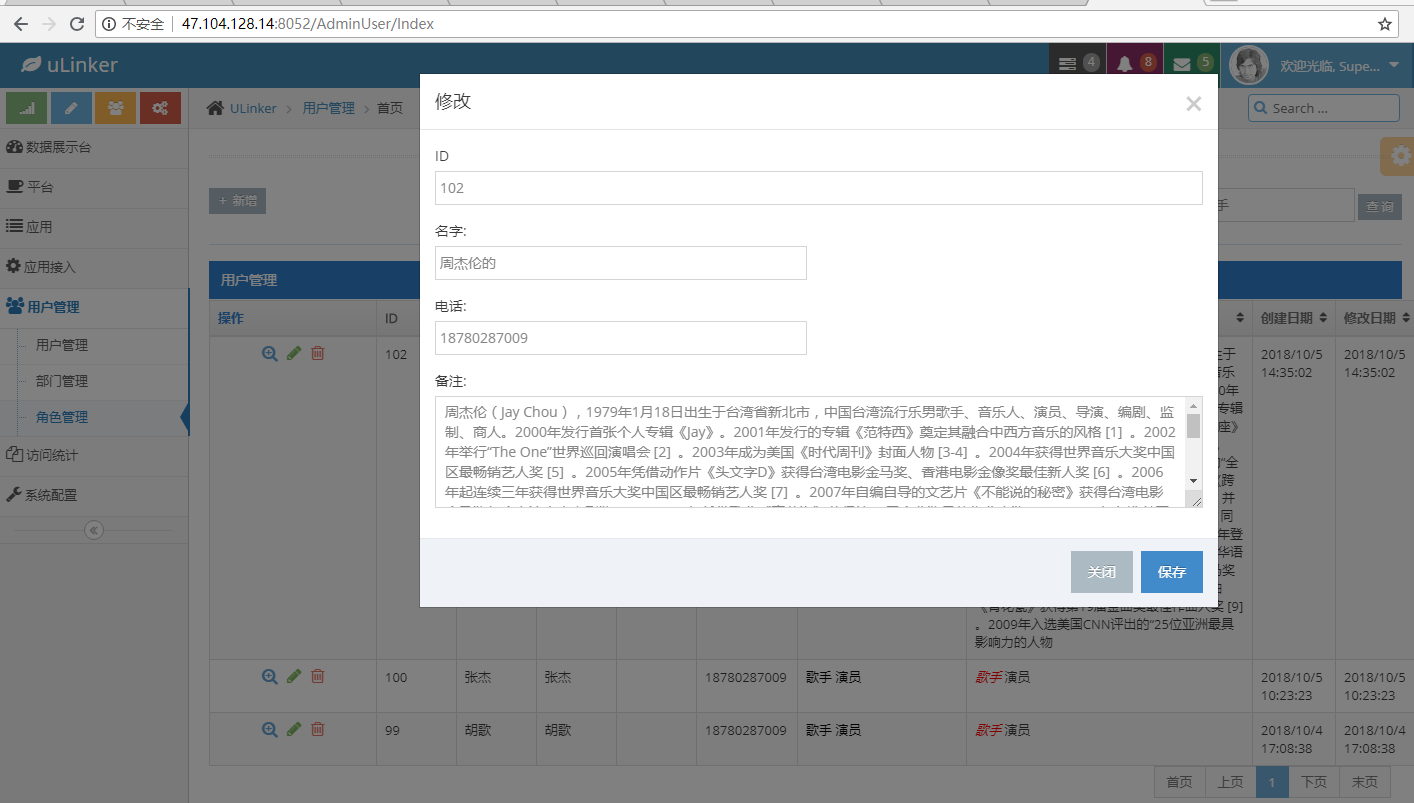
五、总结
elasticsearch是很强大的开源工具,在实现全文搜索上有其独到之处,也是大数据的分析方面利器,值得大家深入去研究和实践。
六、参考
- Elasticsearch权威指南
- Elasticsearch.Net 5.x
- Elasticsearch Reference [5.6] » Document APIs
- elasticsearch-net-example
- ElasticSearch安装及HEAD插件配置




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?