
人生苦短,我用python
导航
- 报表!报表!
- 代码去哪儿了
- 乱码
- 复杂查询
- 人生苦短,我用python
- 实战案例
- 结语
- 参考
本文共计3252字,感谢您的阅读,预计阅读时长3min。
人生苦短,我用python。
第一次接触pyton是在2018年底。那一年,去了一家做AI教育的公司。
那一年,也是人工智能风靡的一年。因为大部分的AI库都是基于Python的,所以python也被炒得热乎朝天。
真正下定决心开启python之旅,其实是两年之后。一部分原因是在学习推荐算法,而更重要的原因是为了应对各种繁杂的数据报表。
报表!报表!
离开上家公司之后,去了另外一家新兴行业的创业公司。
因为所在项目组是新成立的,所以前期老板会要求导出数据报表。当然,随着业务的不断发展,这种需求几乎一直都有。
人工导出报表,总是让人不堪其扰。
而这种需求总是不固定的。有些报表是临时的,有些报表可能会使用几个月。
好不夸张地说,这年写的报表超过了过去职业生涯的总和。
最可气的是,这种导出报表,在领导们看来了就是写几句sql的事情,没有必要体现在工作任务中。
代码去哪儿了
我们平时其实都会忙于正式的工作——项目的编码。
所以,这些项目都是会提交到git仓库。
而那些临时性的报表需求,简单一点的我就写个sql处理了,复杂一点的会用C#或者Java写个导出功能代码。
但是,需求繁杂,管理也不够正式。当下次同样的需求来的时候,又会满世界去找代码...
乱码
有人说,很多数据库客户端工具也能导出数据到excel? 没有必要写程序导出。
但是,有的导出之后,在本机打开是正常的,发送给别人就成了乱码。
这里还是建议是用程序导出,可以设置合适的格式。
复杂查询
报表本身用于数据分析。数据库的设计总是很难满足不同维度的数据导出,又说一些复杂的报表,往往需要超过3张以上数据库表才能完成。
联表的复杂度就不用多说,如果有些表数据太大,sql执行超时也是很普遍的。
而程序处理,显得更加灵活。
人生苦短,我用python
对比了多种语言,踩过了无数的坑,最终发现python这一利器。
python具备很多优点:
- 简单易学:相对于java等,语法更简单,更易上手,适用于编程初学者。
- 数据分析数据挖掘:海量数据的处理是 Python 的强项。
- 轻量:随手写一个python文件即可执行。如果使用
C#或者Java,需要构建一个项目。
特别适合做数据统计和分析。
实战案例
需求:
导出2018-11-12~2019-01-01时间段内的文章到excel表格,字段如下:
| 文章ID | 文章类型 | 标签 | 标题 | 创建时间 |
|---|
使用Python来实现,比较简单,这里给出一个万能模板,您只需要更改数据库连接,sql即可。
#_*_coding:utf-8_*_
#导入pymysql的包
import pymysql
import pymysql.cursors
# 导入excel操作包
import xlwt
from datetime import datetime
def get_data(sql):
# 创建数据库连接
#获取一个数据库连接,注意如果是UTF-8类型的,需要制定数据库
#port 必须是数字不能为字符串
#conn=pymysql.connect(host='localhost',user='root',password='bhwcu2a9',db='passbook',port=3306,charset='utf8')
conn = pymysql.connect(
host='localhost',
user='root',
password='zhikecore123',
db='zhike_street',
port=3306,
charset='utf8')
#conn=pymysql.connect(host='ec2-161-189-70-43.cn-northwest-1.compute.amazonaws.com.cn',user='meb_im',password='nvfoFPR4hnQZfeGkCwBN',db='meb_im',port=3306,charset='utf8')
# 创建游标
cur = conn.cursor()
# 执行查询,
cur.execute(sql)
# 由于查询语句仅会返回受影响的记录条数并不会返回数据库中实际的值,所以此处需要fetchall()来获取所有内容。
result = cur.fetchall()
#关闭游标
cur.close()
#关闭数据库连接
conn.close
# 返给结果给函数调用者。
return result
def getResult(name):
# 将sql作为参数传递调用get_data并将结果赋值给result,(result为一个嵌套元组)
sql = """
SELECT
`Id`,
`ArticleTypeName`,
`Tags`,
`Title`,
`CreateTime`
FROM
`article`
WHERE createtime > '{dtBegin}'
AND createtime < '{dtEnd}'
"""
info = {'dtBegin': '2018-11-12','dtEnd':'2019-01-01'} # 参数是字典类型
sql = sql.format(**info)
print(sql)
result = get_data(sql)
# 实例化一个Workbook()对象(即excel文件)
wbk = xlwt.Workbook()
# 新建一个名为Sheet1的excel sheet。此处的cell_overwrite_ok =True是为了能对同一个单元格重复操作。
sheet = wbk.add_sheet('Sheet1', cell_overwrite_ok=True)
# 表头
header_row = ["文章ID", "文章类型", "标签", "标题", "创建时间"]
# 获取当前日期,得到一个datetime对象如:(2016, 8, 9, 23, 12, 23, 424000)
today = datetime.today()
# 将获取到的datetime对象仅取日期如:2016-8-9
today_date = datetime.date(today)
# 遍历result中的没个元素。
for i in range(len(result)):
data = [result[i][0], result[i][1],result[i][2],result[i][3],result[i][4]]
if i==0:
for j in range(len(header_row)):
# 第一个参数代表行,第二个参数是列,第三个参数是内容,第四个参数是格式
sheet.write(i, j, header_row[j])
#对result的每个子元素作遍历,
for k in range(len(data)):
sheet.write(i+1, k, data[k])
# 以传递的name+当前日期作为excel名称保存。
wbk.save(name + str(today_date) + '.xls')
# 如果该文件不是被import,则执行下面代码。
if __name__ == '__main__':
getResult('_article_static')
代码中几乎每行都有注释,这里不再赘述。
至此,代码已经编写完成,我们保存为_article_static_with_header.py文件。
接下来,就是让代码run起来,导出到excel。
这里需要注意的是,我们需要提前搭建好python的运行环境。新手同学可以参考《Python安装和使用教程(windows)》。
我这里使用的编辑器是VS Code,推荐您也使用。
上面的代码用VS Code 编辑器打开之后,执行
执行之后,生成了一个excel文件。
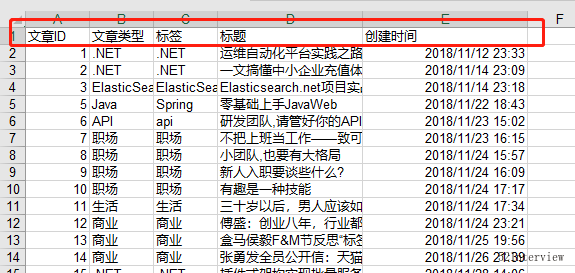
数据就已经导出成功了。
结语
python对于数据处理具有天然优势,比如它的pandas,非常强大。有兴趣的同学可以进一步研究。
在实际使用过程中,一个文件就可以处理一个报表需求,管理也很方便。
在大数据时代,数据分析已经变得越来越受重视,如果您需要经常需要导出报表或者想成为一名数据分析工程师,那就赶快入手python吧!
参考





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术