Go探索-String
字符
字符梗概
-
ASCII字符集 → (GB2312,BIG5,GBK...) → unicode通用字符集 → utf-8,ascii子符集,一个符号对应一个数字编号,数字编号即可以二进制形式表示这个字符GB2312,BIG5,GBK等编码,是各个语言以自己国家语言为标准制定的字符编码规则unicode,unicode 学术学会制作的全球统一化的通用字符集
,实现了跨语言、跨平台的文本转换与处理utf-8,是一种变长编码与解码规则,ascii 字符集及其他常用字符集编码与解码用一个字节表示,而汉字编码与解码由 3 个字节表示
-
关系
- ascii 编码,表示 128 个英文字符与二进制间的关系,gbk
编码是汉字编码,一个 ascii 字符由 1 个字节组成,一个汉字由多个字符组成;utf8 - unicode 规定了不同字符在二进制上的表示形式,但是并没有规定改如何存储,有些需要 3 个字符,有些需要 2 个字符,想 a 这种字符,ascii 用一个字节就能表示,但是在 unicode 中会用 2 个字节,空间浪费
- utf-8 解决 unicode 编码存储问题,它是一种变长的编码方式,ascii 码表里的字符仍然用一个字节来存储,一个汉字用 3 个字节来存储
- ascii 编码,表示 128 个英文字符与二进制间的关系,gbk
-
编码/解码模板
编号 编码模板 [0,127]0???????[128,2047]110????? 10??????[2048,65535]1110???? 10?????? 10??????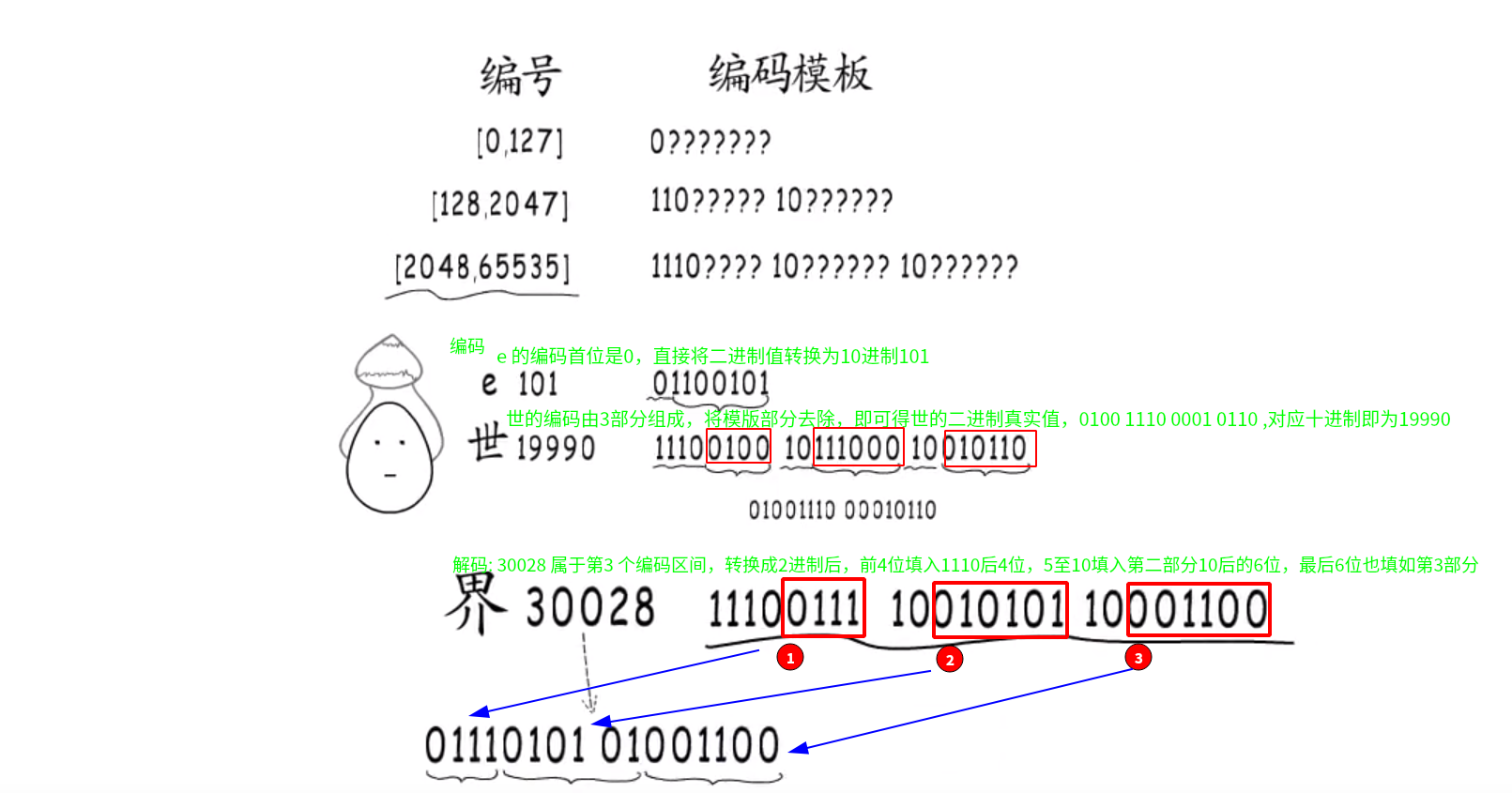
string
type StringHeader struct {
Data uintptr
Len int
}
-
Data存储的是数据,存储在只读内存中的,不能对已经定义的字符串进行修改 -
Len表示存储数据占用的字节(byte)数,例eggo世界
占用 10 个字节,前 4 个字母对应一个 unicode 码点,世由 utf8 编码后由 3 个 unicode 表示,界同理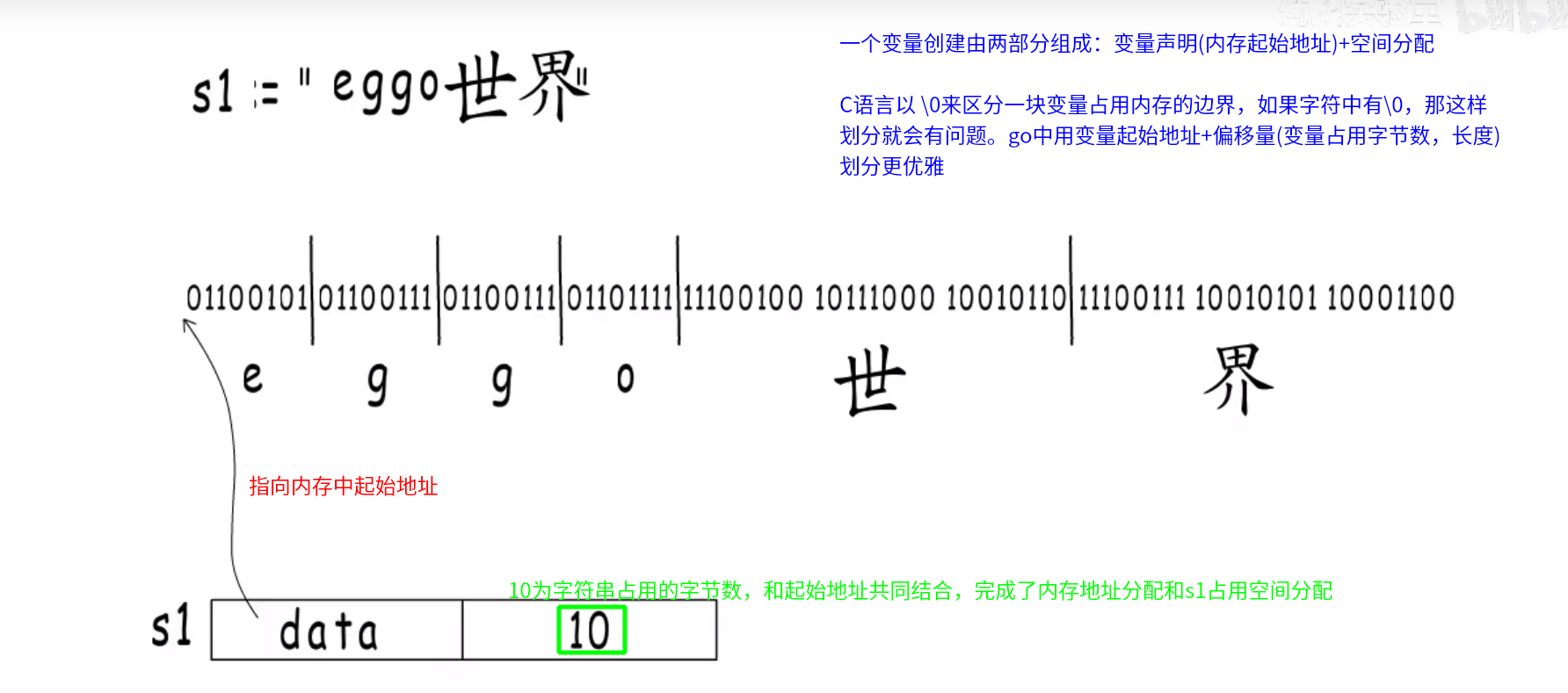
-
示例
package main
import (
"fmt"
)
/**
值类型:打印地址,直接用取值符(&)打印。
引用类型:打印地址,%p 打印
*/
func main() {
s1 := "eggo世界"
fmt.Printf("%c\n", s1[2]) // 字符串底层是只读的字节数组,可以通过索引获取值
fmt.Printf("s1: addr=%v,value=%v \n", &s1, s1)
fmt.Printf("s1: addr=%p\n", &s1)
bs := ([]byte)(s1) // 重新分配内存,并拷贝s1的内容到[]byte切片中
bs[2] = 'o'
fmt.Printf("%c\n", bs[2])
// [101 103 111 111 228 184 150 231 149
// 140],228和184和150共同组成了世,231和149和140 共同组成了界
fmt.Printf("bs: value=%v \n", bs)
fmt.Printf("bs: addr=%p \n", bs)
}
严律己、宽待人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号