
2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation
Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
UC Berkeley
丰富多级特征用于精准对象检测和语义分割
------------------------------------------------------------------------------------鉴于前一篇篇幅太长,此处采用缩略翻译
摘要:
开头大意就是说在权威(canonical)的PASCAL VOC数据集上,过去的人们都是搞一坨坨特征,然后再进行图像上下文分析(也就是空间几何结构,类似DPM),现在我们用CNNs达到了53.3%准确率。文章关键信息:(1)使用cnn对图像区域(region)进行检测和分割(2)因为标注好的训练数据太少,我们基于不同领域细调(domain-soecific fine-tuning)得到了很好提升效果。这种CNN+Region的组合,就是R-CNN。我们还和一种Overfeat方法进行了比较,他也是一种基于CNN的方法,但我们比他效果牛多了,测试数据集ILSVRC2013,200个类别。源码在这儿:http://www.cs.berkeley.edu/˜rbg/rcnn
1介绍:
大家都认同,特征真的TM的重要,过去人们搞了一堆堆特征,HOG啊,sift啊,balabala的。。。但图像对象检测的效果自从2012之后就提升很慢。
SIFT、HOG都是基于块直方图统计,某种意义上和我们视觉皮层规律相符合。但我们整个看东西的过程从皮层到大脑还会经历各种神经系统,中间可能产生的许多有用分级特征(hierarchical features)。
Fukushima提出过一种类似生物学的模型,Lecun提出过随机梯度下降法+反向传播的CNN架构。CNN在1990年代很多人使用,但后来因为SVM就冷下来。直到2012年的Alexnet出来才又火了(参考上一篇翻译)。
CNN分类火了之后,大家各种兴奋,开始讨论怎么把这个模型用到VOC数据集检测问题上呢???
我们来解答这个问题!本文展示了CNN用在检测上的效果,比HOG之流的方法效果牛B多了。主要也就两个问题:1、如何使用深度神经网络做检测?2、如何用小规模标注的数据集来训练大型神经网络模型?
检测(detection)和分类(classification)不同的就是检测需要定位(localization)(定位就是找一个点,检测就是再加上bindingbox),我们把定位看成一个回归问题(也就是特征和响应值的拟合)。其他也有人这么做,但效果很烂(我们的平均准确率(map)58.5%,他们的30.5%)。另外一种方法就是使用一个滑动窗口检测。过去CNN其实在检测上已经用了20多年,但结构都很简单,两个卷积层的样子,主要是行人,人脸检测,层数少的原因是想保留下高清图像细节。我们的有5个卷积层,有很大的感受野(receptive field)195*195和大步长32(感受野是个什么玩意,看这个:http://blog.sciencenet.cn/blog-597740-979117..html),这使得基于滑动窗口来进行精准定位变得很难。
而我们是采用产生区域的方法,产生区域的方法在检测和分割上都很有用。测试的时候我们每张图产生2000个区域,每个区域都用CNN提取特征,后用SVM分类。输入区域(region)的时候,我们会调整成固定大小。图1是整体架构和结果。
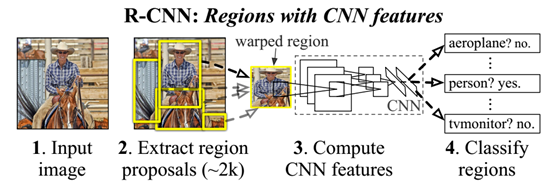
图1:对象检测整体框架:1、输入图像。2、提取2000个region。3、计算每隔区域特征。4、线性svm分类,准确率53.7%。不用CNN特征,而是用词袋模型,只有31.4%,DPM是3.4%。在200个类别的ILSVRC2013数据集上我们的准确率31.4%,overfeat24.3%
另外刚刚第二个问题:数据不够多。解决这个问题办法是:无监督预训练+细调。明白点说就是:在Imagenet上训练CNN,然后在VOC上细调。这样的效果是很好的,例子就是好多人直接用Alexnet提取特征然后做好多其他研究,什么场景识别啊,效果都不错。
我们训练速度也很高效,类别相关的计算项目就是一个小型的矩阵向量相乘,和非极大值抑制(Non-maximum suppression,http://blog.csdn.net/pb09013037/article/details/45477591),另外,我们的特征维数比起之前的要下降两个数量级(two order of magnitude)
我们发现加一个Bindingbox回归算法可以很好地降低错误率
我们发现我们的方法用在分割也很好,VOC2011上准确率47.9%
2 使用R-CNN进行对象检测
方法简单概括就是:region提取 + CNN 特征提取 + SVM分类。

图2:VOC2007训练集图片打包样例
2.1 模块设计
区域提取:现今有很多区域提取算法:objectness、selective search、CPMC等等,由于R-CNN对于区域算法并不挑,所以为了好对比,我们使用selecttive search。
特征提取:直接使用Alexnet,五卷积和三全连接
我们会把region都resize到Alexnet要求的固定大小,但因为要平移裁剪,我们把region扩张16个像素。
2.2. 测试
把刚才的过程又复述一遍……一堆废话之后开始讨论下我们的算法时间。
13s/image on a GPU
53s/image on a CPU
一张图特征矩阵2000*4096,然后表述一大堆,意思就是我们的这个特征已经很小了,还适用于所有类别,还很省内存。
2.3. 训练
有监督预训练
这一步就是使用caffe+alexnet,我们的准确率稍差,因为训练集被我们精简了。
基于领域的精调(Domain-specific fine-tuning)
为了检测,我们在模型基础上调整,替换最后1000维输出变成我们的N+1维的输出,初始值随机,N是类别数目,1是背景。
然后输入区域作为图像来调整模型,还是用随机梯度下降(SGD),学习速率0.001(以前的1/10), 同一批(batch)训练样本128个包括96个正样本,32个负样本
对象类别分类器
怎样的算正样本,我们选择和标注结果(groundtruth)overlap 0.3以下的作为负样本。这是通过验证集严格筛选的,从{0,0.1,0.2,0.3……0.5}中尝试一遍会发现,选择0.5作为阈值,准确率下降5个百分点,选择0作为阈值,平均准确率下降4个百分点。注:正样本是严格groundtruth。
而我们的SVM分类器是在每个类别上优化的,使用了Hard-negative mining 技术,只需要遍历一遍所有样本就可以很快收敛。
附录B会讨论下,在SVM分类器和训练神经网络中,正负样本的定义是不同的。另外讨论为什么要用SVM替换softmax。
2.4. PASCAL VOC 2010-12的结果
废话不说,看结果。在12数据集上我们贴出来使用和不使用包围盒回归的结果(with
and without bounding-box regression)。

表 1: VOC2010平均检测准确率 (%)
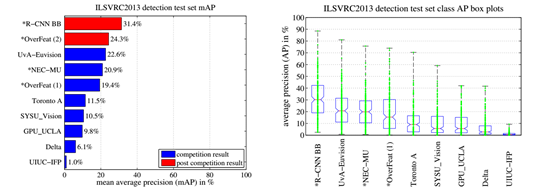
图 3: (左)
ILSVRC2013 平均检测准确率,(右) 每种方法两百个包围盒的箱形图(Box-plot)。没有 OverFeat的箱形图,因为每个类别结果没有公开,红线代表平均AP,盒底部和上部表示25%和75%The
red
line marks the median AP, the box bottom and top are the 25th and 75th
percentiles. 而上方和下方是最大最小AP. AP都画成绿点。
3. 可视化,剥离本质,和错误模型
3.1 可视化学习特征
第一层的特征很容易可视化,他们抓取了边缘和对比强烈的颜色,而如果要理解更上层就比较困难。Zeiler and Fergus (第0篇翻译中)使用了反卷积操作,而我们使用一种更加简便的方法。我们计算出region的响应度,然后进行排序,大概有1000万个,我们把这些区域进行最大值抑制然后显示出来。

