
StyleGAN踩坑指南
正文
本文主要介绍 StyleGAN,并用在 CheXpert 数据集上
在上一篇博客ProGAN / PGGAN中,我们介绍了 PGGAN 的原理,已经PGGAN如何增强图像生成的多样性和网络正则化,并最后对其实验的细节进行简略的说明;
首先,PGGAN 最主要的贡献在于提出了 Progressive Growing 的思想,并结合 fade in 的操作,平稳过渡,逐步生成高清图像;
同时,因为 GAN 网络容易导致 Mode Collapse,作者在 Ian 提出的 Minibatch Discriminator 的基础上进行了简化,得到了 Minibatch Standard Deviation,并取到了不错的实验效果,
为了减缓 GAN 在训练过程中, G、D网络训练不动,甚至因为恶性竞争导致网络整体变坏的情况,作者引入了 Equalized learning rate 和 Pixel Normalization
但是,我们仔细想一想,PGGAN 中生产的图像也只是随意的生成,我们没有办法对其进行控制,这也就导致他的实用价值不是很大,倘若我们可以对 生成图片的某些细节进行调控,那么他的应用价值将会大大增大。
因此,PGGAN 的作者,Tero Karras,苦思冥想,提出了一个新的 GAN,并称之为 StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks Tero Karras, S. Laine, Timo Aila Published 12 December 2018 (Citations 3,066)。StyleGAN 主要偏重于对网络结构进行改进,并借鉴了 style transfer literature 的部分,引入了 noise 变量,并增添了一些训练的 trick,下面我们进行介绍
StyleGAN 简介
对应原文 Abstract 和 1.Introduction 部分
在StyleGAN 论文中,作者 Tero Karras 对论文进行了大致的总结。StyleGAN是受风格迁移启发而提出了一个新的GAN网络架构。他可以可以自动学习、无监督的分离高维属性;并可以加入随机的变量;有着更为直观、尺度精准的控制,并且取得了非常好的效果,生成图片在插值角度上效果不错,成功将隐空间解耦;而且论文提出了 GAN 隐空间解耦的衡量指标(非本文重点),和新的人脸数据集
Introduction 部分,思路的由来进行更为细腻的介绍(个人觉着这部分讲得不错,主要是为什么进行这样做)。 Tero Karras 观察到 虽然传统的 GAN 网络发展迅速,但是仍然是一个黑盒操作,使用者不知内部的原理,无法对生成图片属性进行精确地控制。也就是说隐空间 noise 的属性很难理解,生成图片的属性在 latent space 中并没有解耦开,所以说我们无法施加控制。受Style transfer literature 的启发,StyleGAN 网络架构从可学习的 constant input出发,在 Progressive Growing 的过程中调整 Style,达到不同时期的 Style 控制不同尺度的图片大小,因而产生不同效果的目的,达到对生成图片部分属性人为控制的目的。
然而,style 的产生之前,需要输入 noise,并经过多层 MLP 的操作,效果会更好,生成图片的属性更能够解耦开。这是因为原本的 noise z 遵循一定的分布,比如说高斯分布、均匀分布;但是受分布限制的噪声可能导致一定程度的特征缠绕,因此StyleGAN中设计了 Mapping network。 noise 经过 8 层MLP(mapping network),几乎可以映射到任何分布的隐空间就可能没有这种限制,也更容易进行生成图片属性的解耦。
之后,作者又介绍了判断Generator 隐空间耦合程度的方法(非本文重点),并提出了FFHQ人脸数据集,有着更好的多样性。
StyleGAN 网络结构
对应原文 2. Style-based generator 部分
StyleGAN 的网络结构,是改变论文中最为重要的部分,它所体现的正是 Style 対生成图片的控制过程,如下图所示:
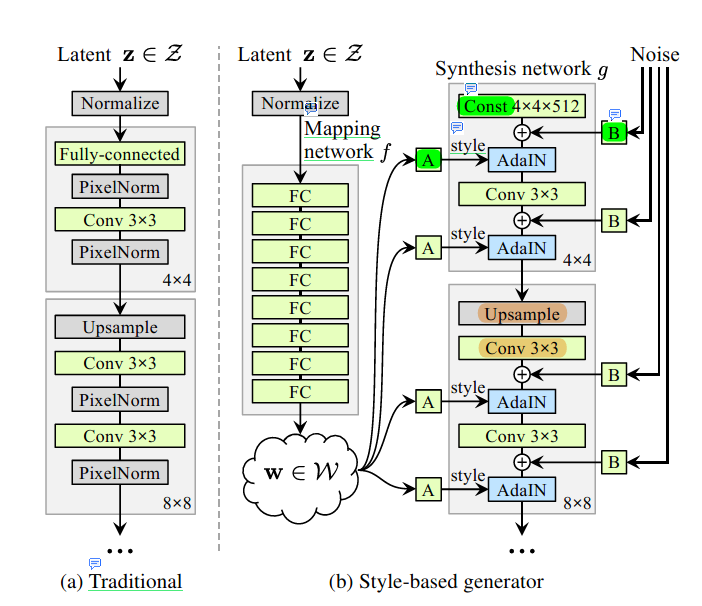
图(a) Traditional 正是 我们上一篇博客所提到的 ProGAN / PGGAN 网络架构,不再进行描述。 图(b) 是作者 Tero Karras 提出的 StyleGAN 网络结构。 StyleGAN 的 Discriminator 使用的是 PGGAN (ProGAN) 的 Discriminator 架构,他的改进集中在了 Generator 上。 StyleGAN 的生成器 Generator 主要分为两大部分 Mapping network 和 Synthesis network。
单看 Mapping network , 它接受我们输入的 Latent ,经过 Normalize (Pixel Norm),进行 8 层 MLP 中,得到我们的 , 相比较于 不受概率分布的影响,更容易进行生成图片的属性解耦。 再看 Synthesis network,他的网络结构大致和 PGGAN 中 Generator 相似,不过在输入上,换成了 可学习的 Const,存在 AdaIN 操作,而 AdaIN 也是 StyleGAN 中最为重要的部分,他既接受了来自 Mapping network 的 Style,和加入了 Synthesis network 网络的上层输入部分。
AdaIN 的 Style 是如何来的呢?我们从 Mapping network 中拿到输出 ,,经过 A 运算(Learned affine transformations),转化为了 ,就是我们的 Style,channels 为 Synthesis network 在该阶段中channels 的数量,
AdaIN 接收上一层的输入又是什么呢?假设 Conv 3X3 输出的特征图 feature_maps 形状为 CXHXW,他会加入我们的 Noise,形状为 1XHXW, 不过 Noise 会经过 B 操作进行缩放(B仅仅是一个 CX1X1形状的可学习 缩放因子),噪声经过广播机制在 channel 维度上扩张,然后按照 B 中的可学习参数进行缩放,noise 经过处理形状为 CXHXW,与我们的 特征图 feature_maps 进行按位置相加,得到更新后的 feature_maps
得到了 feature_maps 和 Style 下面就是 AdaIN 操作。adaptive instance normalization (AdaIN) 操作 其实对我们我们加入噪声更新后的 feature_maps (C, H, W) 进行 的 style transfer,具体的运算规则为 , 其中 , 表示特征图, 和 分别表示 style transfer 之后的 标准差和均值。 和传统的 Style Transfer 的方法相比, StyleGAN 中的 Style 来源于 ,而不是一个目标样本图像,但是他们的作用类似,都去得了不错的效果,一下是论文的结果展示图表(FID 数值越低越好):
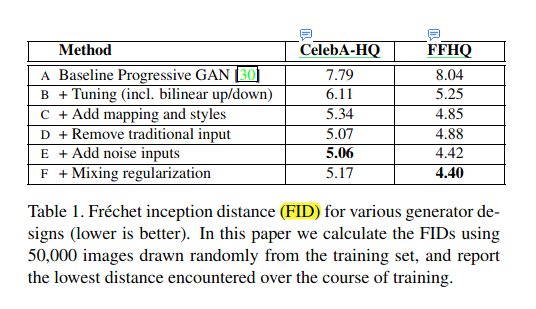
A 方法为普通的 PGGAN 产生的效果
B 方法加入了 bilinear 上采样/下采样,更长的训练时间和超参数的调整
C 方法加入了 mapping network,和 style 部分
D 方法移除了 传统的 noise input, 换成了可学习的 const,该方法有利于产生更加稳定、可信的输出
E 方法加入了 noise inputs,提高了图片的多样性
F 方法加入了 mixing regularization,我们后面会对该方法进行介绍。
StyleGAN 思考
该部分对应原文的 2.2. Prior art, 3. Properties of the style-based generator 部分,主要是针对 StyleGAN 未用到哪些部分(也就是可以改进的方向),什么是 Style Mixing(风格混合),什么是 Stochastic variation (Noise 的加入),以及 Style 和 Noise 的相互作用。
Prior art
介绍了相关工作,也算是提供了一种改进的方向。比如说可以加入 多Discriminator,或者是多分辨率的 DIscrimination,又或者是使用 self-attention。
同时之前工作条件 GAN 通过将 class label 通过 embed network 送到 Generator 中,但是并没有给 Noise 加入额外的 mapping network,文中反倒是利用起来。
不过,我认为,传统的方法,使用 MLP 映射 Noise Z,效果还真不一定会好,因为他们并没有 Style GAN 中解耦的需求,反倒是加入过多的 MLP,使得网络参数大、计算量大、且易过拟合。
Style Mixing
StyleGAN generator 借助 progressive growing 的过程来修改不同尺度大小的 Image,形成不同作用的 Style(比如说肤色是小粒度的 Style,而人的姿态是大粒度点的 Style)。我们可以将 mapping network 和 affine transformations 作为从给定了分布 z 中 提取不同粒度的 style,synthesis网络可以认为是基于给定的 style 来绘制一个新奇的人脸样本。在 network 上每一种粒度的 style 都可以影响生成图片的某一些特征。
让我们仔细的考虑 AdaIN操作,该操作首先将 feature map归一化,并使用学习到的 style 重新定义 feature map的均值和方差。均值和方差作为 features 的统计量,决定了当前 features map 的 style。 归一化 Normalization正是去除原始图片的统计风格信息,并加入学习到的图片风格信息。 又因为在 Progressive Growing 的过程中存在多个 AdaIN ,根据此时 Resolution 的大小,Style 也决定了不同的粒度。
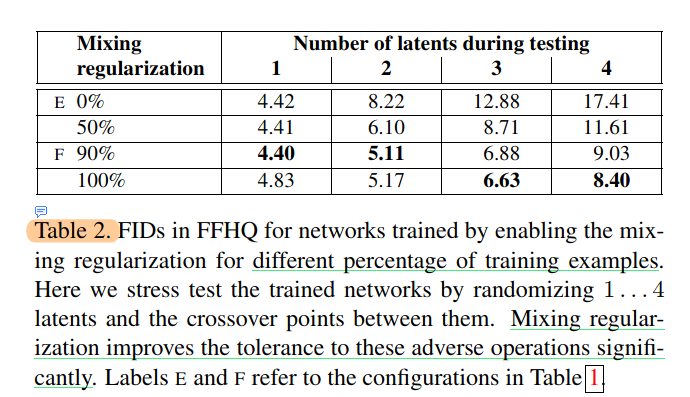
StyleMaxing 操作指的是我们使用两个 latent codes z_1, z_2, 生成 w_1, w_2, 在某一个 AdaIN 前使用 w_1, 某一个 AdaIN 后使用 w_2。
这种方法可以防止网络使得相邻的 Style 作用相似,减弱 Style 之间的耦合度,尤其是相邻的 Style。

Stochastic variation
人脸生成中,有很多因素都是随机的,如人脸的皱纹,发丝等等,但是传统生成器的方法直接通过 输入 z ,希望网络自己可以学习到随机噪声,因为噪声可能和位置无关(皱纹),这就给网络很大的挑战。现在我们网络结构直接添加 per-pixel noise 的噪声,来绕过这一传统的问题,不再是通过网络学习他们的随机性,降低了对于网络 capacity 的要求。 下面两张图具体介绍一下噪声的作用:

图中, (a) 展示的是 StyleGAN 生成的图片,(b)为我们对细节进行方法的图片,可以看出不同的噪声,他的头发细节部分有着细微的不同。生成100张不同 noise 的图片,计算 像素 standard deviation,可以看出噪声影响的区域主要在于头发和背景等等部分,人的姿态等部分几乎不会变化,这也正是我们需要的噪声控制。

(a)表示使用所有尺度 noise 生成的图片,(b)表示不使用noise 生成的图片,(c)表示仅仅使用小尺度 noise ()生成的图片,(d)表示使用大尺度 noise () 生成的图片,可以看出还是使用全尺度 (a) 生成图片的效果最好,(b)(d)过于平滑,有点类似于油画,然而(c)细节过于稠密,不太真实。
Separation of global effects from stochasticity
下面,我们更为细致的考虑 Noise 和 Style的作用,已经为什么无法相互替代。
首先,Style 作为统计性信息,可以认为是图像的 方差和标准差,它包含的是图像的全局性信息,比如说任务的姿态,肤色,性别等等。 噪声 noise 影响的是小范围,局部信息的变化,如皱纹,头发等等。
style transfer literature 中也提及 spatially invariant statistics (Gram matrix, channel-wise mean, variance, etc.) reliably encode the style of an image while spatially varying features encode a specific instance. 也就是说 空间的统计性信息,比如均值方差等等,能够可信的编码图像的 style 风格,而空间上变化的特征 能够编码一个具体的样例,也就是说 style 影响的正是图像的方格, noise 影响的是图像的不同,也正是形成不同细节 instance 的因素。
在StyleGAN Generator 中 Style 影响的正是均值、方差等等全局性的信息。因此像是姿态、光照、背景等全局的特性更容易被 Style 所控制。 同理, noise 是 pixel independent 加入的,生成噪声的时候,是逐个像素生成的,因此更容易被网络学习到影响随机变化。
因此,如果网络想要使用 Noise 控制 Pose 信息,可能会导致空间上的不一致性,进行容易被Discriminator惩罚。同理,如果网络使用 Style 控制 图片的随机变化,可能会产生周期性的影响(比如随机性的斑纹,变成周期性的特征),也会被惩罚。
换一个更易理解的话,那就是 Style 和 Noise 对于网络而言,有着更倾向于学习的部分,Style 对应图片的全局风格,Noise 对应局部特征。
Disentanglement studies
测量耦合方法的研究,这里不在讲了(因为我也不用,就没看)
Truncation trick in W
截断技巧可以调高生成图片的质量,在GAN网络训练过程中有所使用,(比如BigGAN),尽管他可能会使得图片多样性有所下降。下面我们介绍StyleGAN 截断技巧的使用方法和公式。相比前面介绍的网络框架,方法较为简单
首先,我们计算出 ,因为均值代表频率搞、更容易出现,也就是网络更新更好的图片。
然后,我们对给定的 进行缩放 ,
从主观上来判断,就是将 空间压缩到 附近,来提高图片生成质量,但也降低了多样性
参考文献
arxiv: A Style-Based Generator Architecture for Generative Adversarial Networks


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~