
6. pytorch损失函数和优化器
正文
损失函数,又叫目标函数,用于计算真实值和预测值之间差异的函数,和优化器是编译一个神经网络模型的重要要素。本篇文章主要对 pytorch 中的 损失函数和优化器进行讲解。
1. 损失函数
损失函数简介
神经网络进行前向传播阶段,依次调用每个Layer的Forward函数,得到逐层的输出,最后一层与目标数值比较得到损失函数,计算误差更新值,通过反向传播逐层到达第一层,所有权值在反向传播结束时一起更新。
也就是说损失函数主要有两大作用,
- 计算实际输出和目标输出的差距;
- 为我们的更新输出提供一定的依据;
下面我们通过 查阅 pytorch 的官方文档来介绍一下 pytorch 中的损失函数:
pytorch 中的损失函数
进入torch.nn 的官方帮助文档,找到损失函数 Loss function 这一项。我们主要介绍 损失函数中的 nn.L1Loss、nn.MSELoss、nn.CrossEntropyLoss这三种。
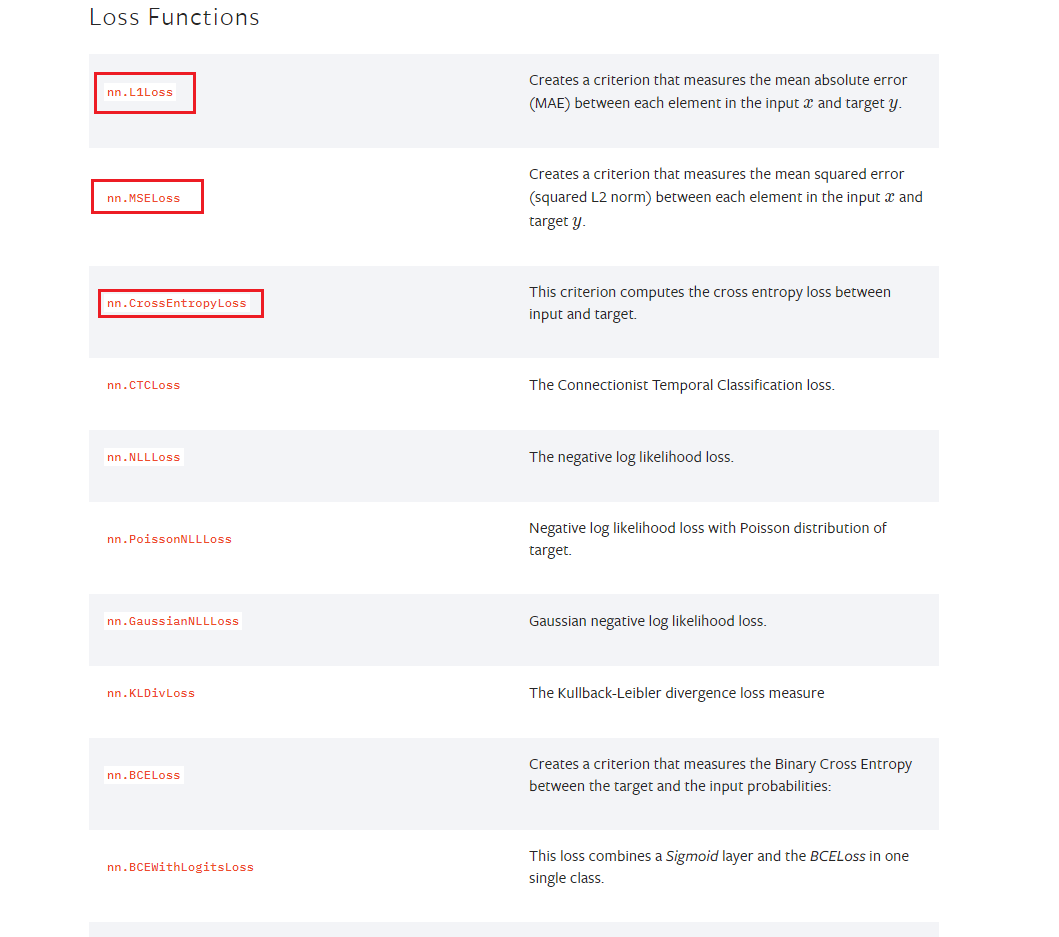
nn.L1Loss
查看官方帮助文档:
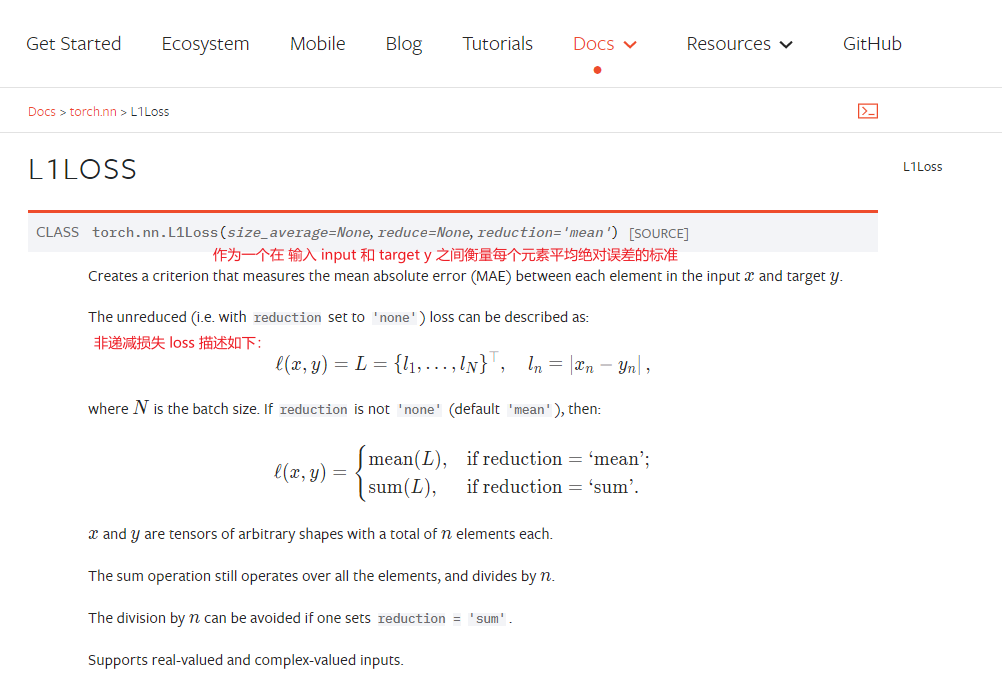
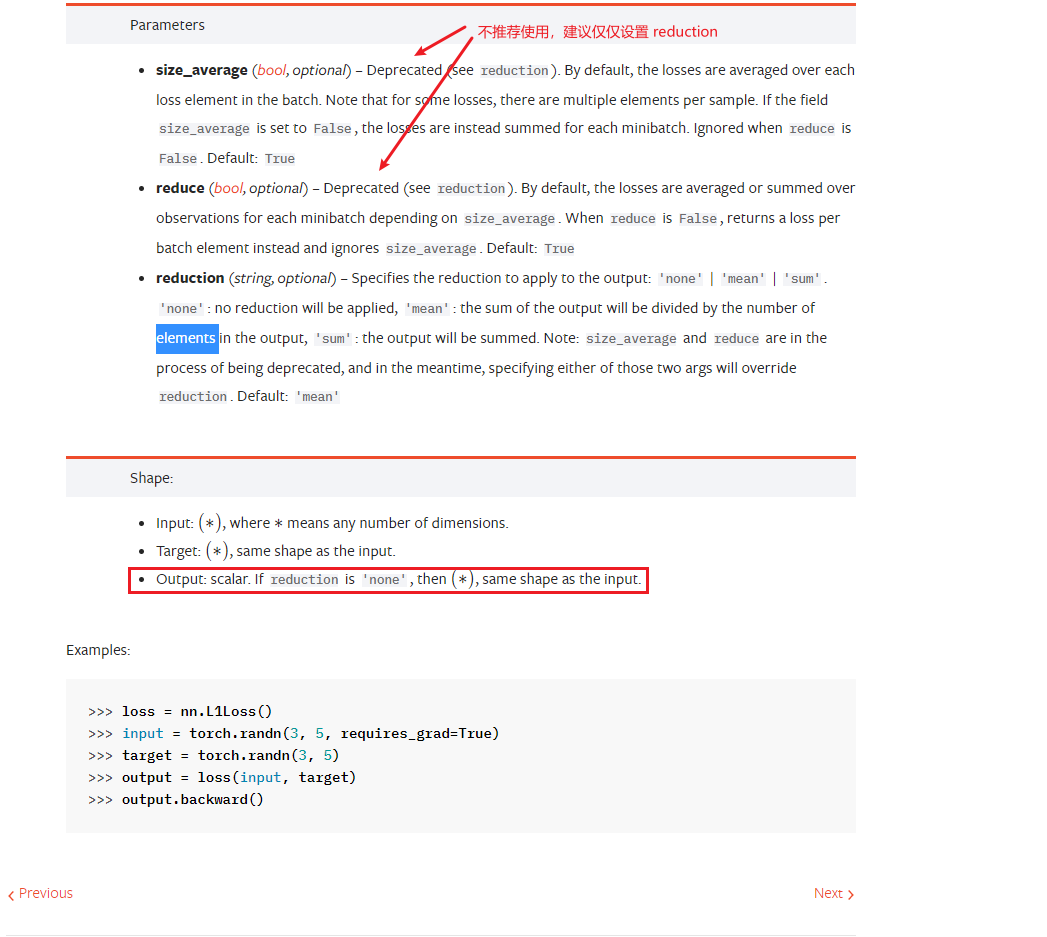
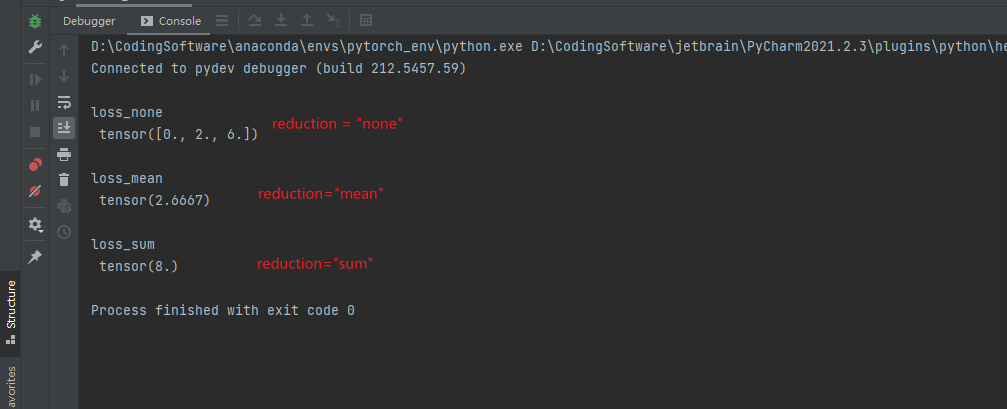
设置三个 reduction 参数进行使用:
import torch import torchvision import torch.nn as nn # 这个 torch 的类型一定要设置,可以是浮点数、也可以是虚数 input = torch.tensor([1, 2, 3], dtype=torch.float32) target = torch.tensor([1, 4, 9], dtype=torch.float32) loss_function_none = nn.L1Loss(reduction="none") loss_function_mean = nn.L1Loss(reduction="mean") loss_function_sum = nn.L1Loss(reduction="sum") loss_none = loss_function_none(input, target) loss_mean = loss_function_mean(input, target) loss_sum = loss_function_sum(input, target) print("\nloss_none\n", loss_none) print("\nloss_mean\n", loss_mean) print("\nloss_sum\n", loss_sum)
结果也是非常的好理解,如下所示:
nn.MSELoss
查看MSELoss 官方文档
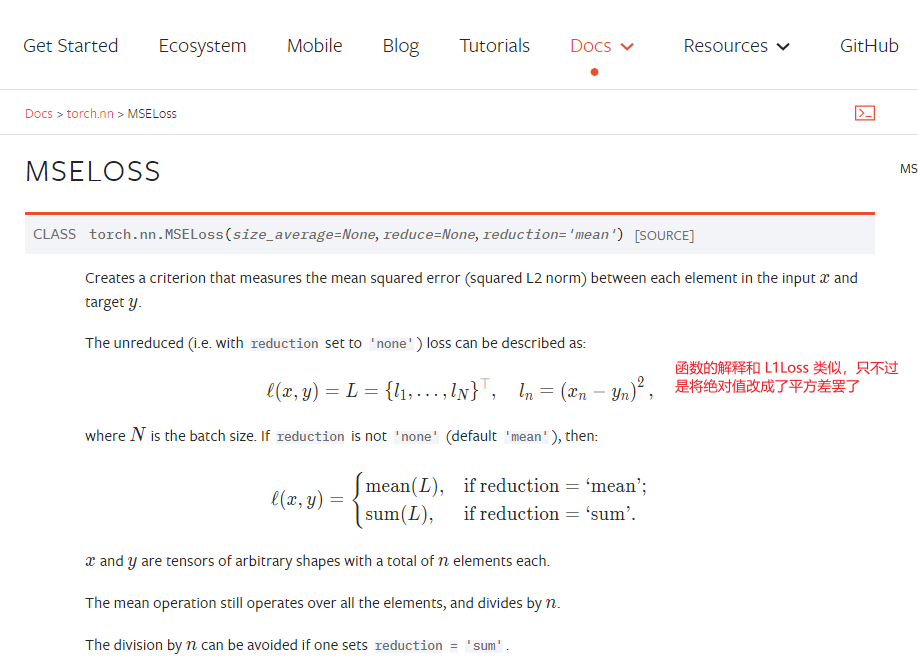

代码演示:
import torch import torchvision import torch.nn as nn # 这个 torch 的类型一定要设置,可以是浮点数、也可以是虚数 input = torch.tensor([1, 2, 3], dtype=torch.float32) target = torch.tensor([1, 4, 9], dtype=torch.float32) loss_function_none = nn.MSELoss(reduction="none") loss_function_mean = nn.MSELoss(reduction="mean") loss_function_sum = nn.MSELoss(reduction="sum") loss_none = loss_function_none(input, target) loss_mean = loss_function_mean(input, target) loss_sum = loss_function_sum(input, target) print("\nloss_none\n", loss_none) print("\nloss_mean\n", loss_mean) print("\nloss_sum\n", loss_sum)

CrossEntropyLoss
CrossEntropyLoss,翻译过来就是交叉熵损失。首先,我们来介绍一下什么是交叉熵。
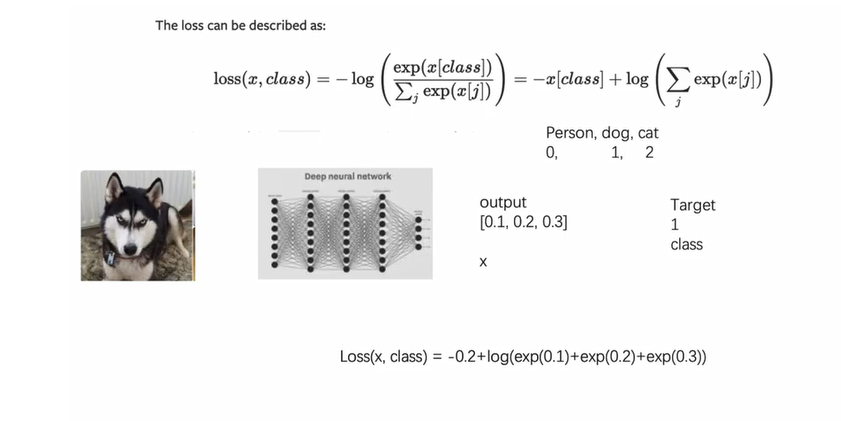
给定输入向量 x,x[i] 表明类别是 i 的可能性强度,那么 对于输入 x,他对于类别 class 的交叉熵如上图所示,
经过化简之后为:
其中n表示为种类的数量,class 为某一个特定的类别。
不难得知 肯定是大于 0 的,而且我们可以分析一下这个函数的合法性:
- 倘若 x[class] 比重越大,那么损失函数计算的数值将越接近于0,也就说是他越为合理
- 倘若其他 j 比重越大, 即 x[j] 越大,损失函数计算数值 也会变大,说明也比较合理
也就是说,该损失函数,可以将提高识别为目标类的概率,降低识别为其他类的概率。
下面,我们来看一下官方的帮助文档(pytorch的该帮助文档有些恐怖!!!):
有能力的看一下官方文档,我翻译的可能不是很准确,但也是尽力的标注和翻译了。


因为二分类交叉熵可以用作分类问题的求解,我们将其用到 我们 CIFAR10 写过的网络中去。
import torch import torchvision import torch.nn as nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter images_path = "../../data_cifar10" logs_path = "../../logs" dataset = torchvision.datasets.CIFAR10(root=images_path, train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset=dataset, batch_size=64, drop_last=False) class MyModel(torch.nn.Module): def __init__(self): super(MyModel, self).__init__() self.model = torch.nn.Sequential( nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Flatten(start_dim=1, end_dim=-1), # 将它展平之后, dimension0 是 batch,后面的特征需要改变 nn.Linear(in_features=1024, out_features=64), nn.Linear(in_features=64, out_features=10) ) def forward(self, x): return self.model(x) my_model = MyModel() cross_entropy_loss_func = nn.CrossEntropyLoss() # 这是一个简单的测试 # 一定要注意我们 output 和 target 的 shape 情况 output = torch.tensor([0.1, 0.2, 0.3]) target = torch.tensor([1]) output = torch.reshape(output, (1, 3)) print(cross_entropy_loss_func(output, target)) for images, targets in dataloader: images_proceed = my_model(images) cross_entropy_loss = cross_entropy_loss_func(images_proceed, targets) cross_entropy_loss.backward() print("this is the cross entropy loss")
在 cross_entropy_loss.backward() 后面打入断点,可以看到 backward 的效果:
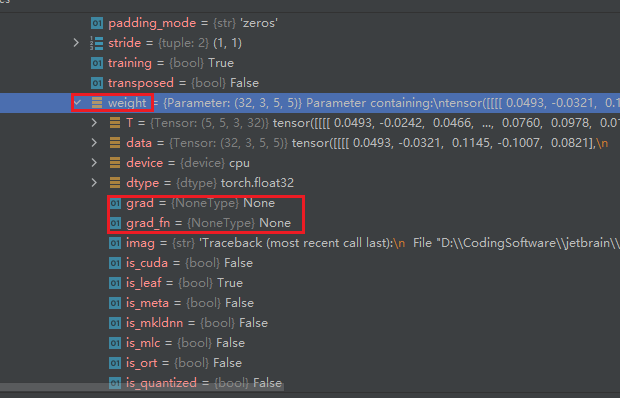
查看 my_model -> model -> Protected Attributes -> _modules -> 任选其中一个,这里我们选择 0,
查看他的 bias 和 weight ,下面的 grad 梯度属性都是 None

断点接着往下执行,一走到 cross_entropy_loss.backward()后面,可以看到

数值有所更新,backward 起到了相应的效果。
2. 优化器
优化器的简介和文档
我们知道,神经网络的学习的目的就是寻找合适的参数,使得损失函数的值尽可能小。解决这个问题的过程为称为最优化。解决这个问题使用的算法叫做优化器。
还是老规矩,我们首先查看 pytorch 优化器的官网
相比于之前 torch.nn 中的帮助文档,torch.optim 显得更为工程化,直接就是教你使用 优化器的步骤。
优化其部分代码
小建议
lr: learning rate 学习速率,不可太大,也不可太小,太大的话或导致算法的不稳定,太小的话又导致学习的速度太慢。推荐,一开始的时候 ,我们采取比较大的学习速率来进行学习,学习到后面,采用比较小的学习速率来进行学习
使用优化器的步骤
1、先定义一个优化器
2、对优化器的参数进行清零 optim.zero_grad()
3、调用损失函数的 backward,反向传播,求出每一个节点的梯度情况 result_lose.backward()
4、优化器.step 对每个参数进行调优 optim.step()
SGD : 梯度下降法(stochastic gradient descent,SGD)
根据梯度进行控制输出,每一个需要调整的参数,对于神经网络来说,或者是对于卷积层来说,其中的每一个卷积核都是需要进行调整的,通过设置grad 梯度,采用反向传播,每一个节点、或者说是每一个需要更新的参数,他都要求出一个对应的梯度,然后在优化的过程中根据梯度尽心进行优化,最终将整个loss进行降低。
下面我们以 SGD 优化器为例写一个小代码,跑一下我们之前的 CIFAR10 model 搭建的网络。
首先,还是瞄一眼 SGD 优化器的文档:
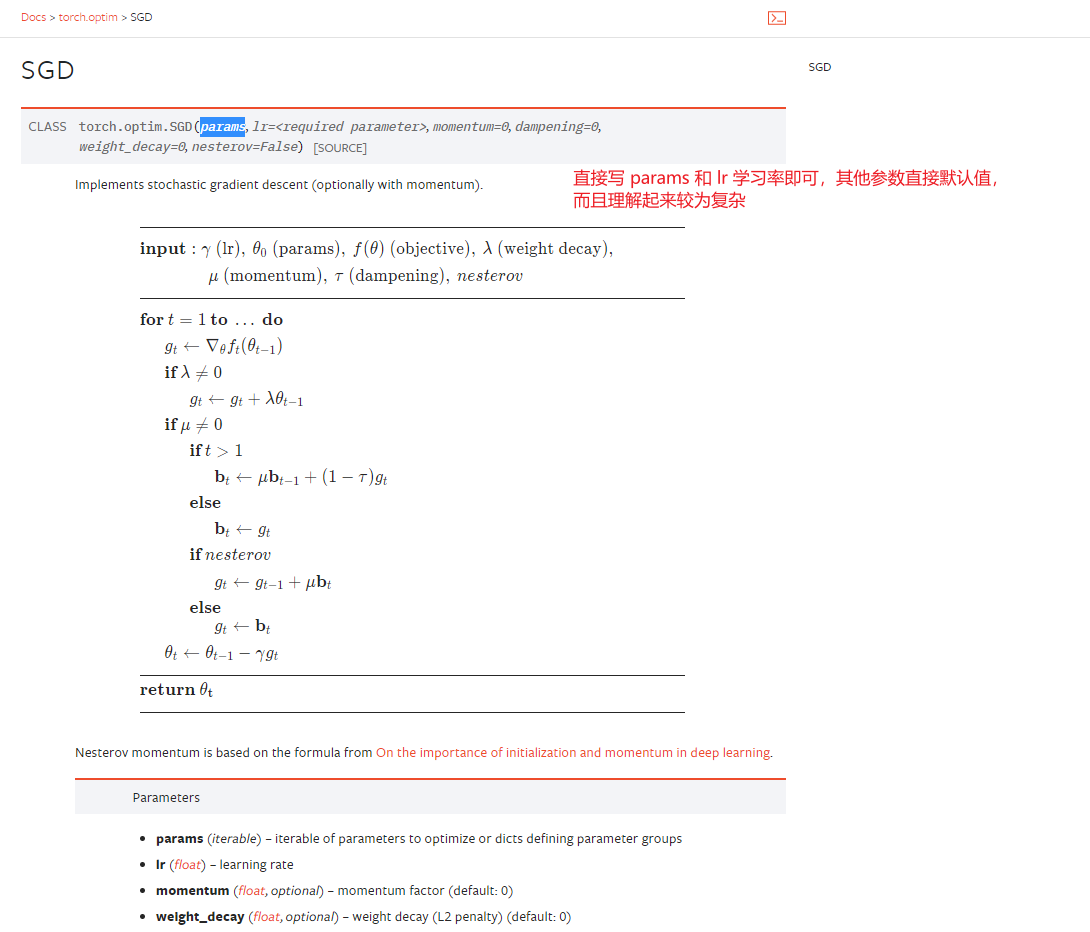
将 torch.optim.SGD 优化器加入到CIFAR10代码中
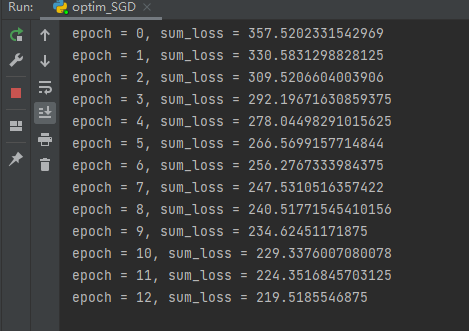
import torch import torchvision import torch.nn as nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter images_path = "../../data_cifar10" logs_path = "../../logs" dataset = torchvision.datasets.CIFAR10(root=images_path, train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset=dataset, batch_size=64, drop_last=False) class MyModel(torch.nn.Module): def __init__(self): super(MyModel, self).__init__() self.model = torch.nn.Sequential( nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(kernel_size=2, padding=0), nn.Flatten(start_dim=1, end_dim=-1), # 将它展平之后, dimension0 是 batch,后面的特征需要改变 nn.Linear(in_features=1024, out_features=64), nn.Linear(in_features=64, out_features=10) ) def forward(self, x): return self.model(x) my_model = MyModel() cross_entropy_loss_func = nn.CrossEntropyLoss() optim_SGD = torch.optim.SGD(my_model.parameters(), lr=0.02) for epoch in range(100): sum_loss = 0 for images, targets in dataloader: images_proceed = my_model(images) cross_entropy_loss = cross_entropy_loss_func(images_proceed, targets) optim_SGD.zero_grad() # 梯度清空 cross_entropy_loss.backward() optim_SGD.step() # 前进 # print("this is the cross entropy loss") sum_loss += cross_entropy_loss print(f"epoch = {epoch}, sum_loss = {sum_loss}")
运行结果:
下面,让我们打一个断点查看一下优化器的具体优化内容,主要是参看 `weight`` 也就是我们卷积核的变化:
从下面的两个图片可以看到确实是发生了变化!
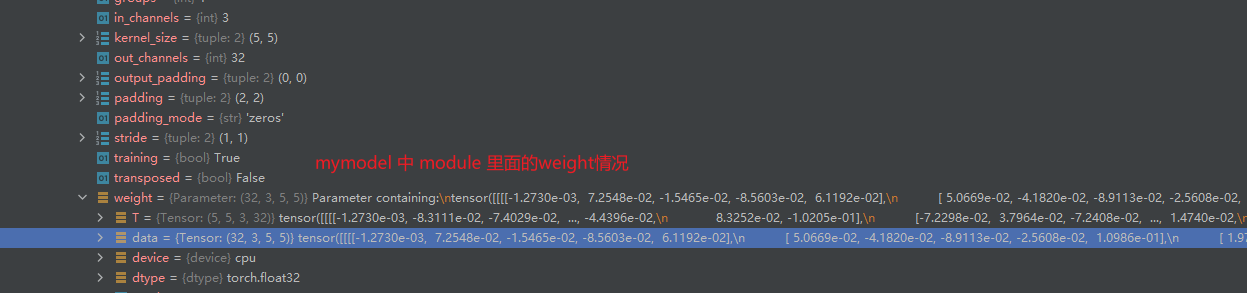

接着查看 optim_SGD.zero_grad() 作用,请看函数执行前 module grad 参数的数值


参考文献
参考博客:Pytorch 的损失函数Loss function
Date:2021/11/12


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)