3. Dataset、transform和Dataloader的联立使用
在前两篇我博客1.法宝函数、编译器的初级使用和使用Dataset 和2. tensorboard和 transform的使用中,我分别介绍了 Dataset 和 transform 的简单使用,并推荐使用了 pytorch 中常用的日志工具 tensorboard,在本篇博客中,我将继续介绍 Dataset 和 Dataloader的使用,主要介绍数据的加载方式。
1. Datasets + transform
torch.utils.data.Dataset 的回顾
老办法,我们还是先查看官方文档
pytorch.org 上的介绍:

pycharm 上的介绍:
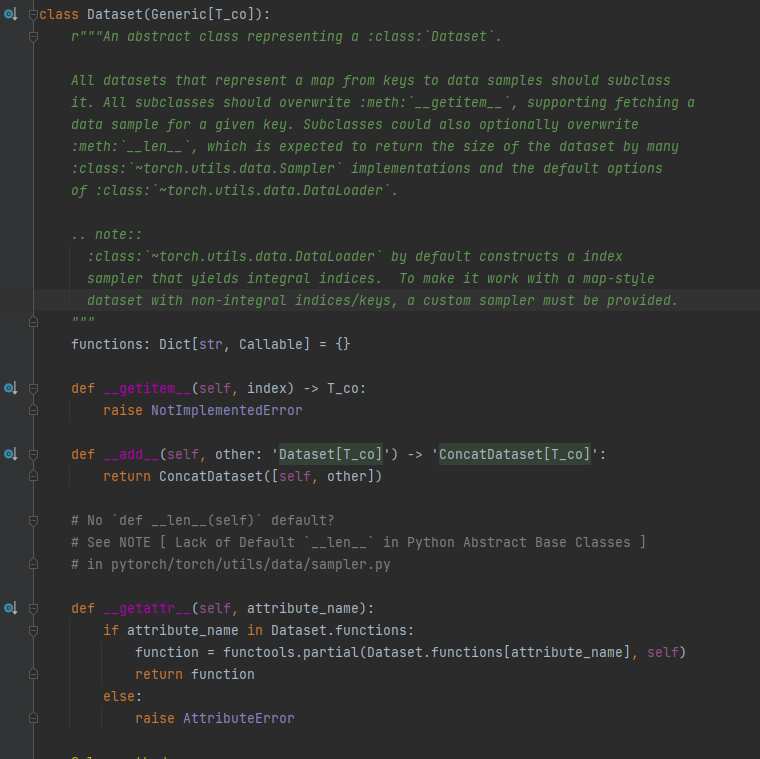
这两种介绍大同小异,就不再二次翻译了。
这个是我们之前学的 Dataset,直接进行继承该类
手写一个代码看看:
from PIL import Image
from torch.utils.data import Dataset
import os
class MyDataset(Dataset):
def __init__(self, root_dir, label):
"""传递文件所在位置的参数"""
self.root_dir = root_dir
self.label = label
self.label_path = os.path.join(self.root_dir, self.label)
self.img_name_list = os.listdir(self.label_path)
def __getitem__(self, idx):
"""根据文件所在的位置,读取文件后返回"""
img_path = os.path.join(self.label_path, self.img_name_list[idx])
return Image.open(img_path), self.label
def __len__(self):
return len(self.img_name_list)
if "__main__" == __name__:
my_data = MyDataset("./data/train", "ants")
img_data, label_data = my_data[0]
img_data.show()
transform 的回顾
transform使我们刚刚学过的,就是调用 transform 库中的帮助文档,如果不太了解的话可以查看一下我的上一篇博客2. tensorboard和 transform的使用。
Datasets
请注意,这里是 Datasets 而不是 Dataset,这是一个复数!我们首先查看一下他的帮助文档
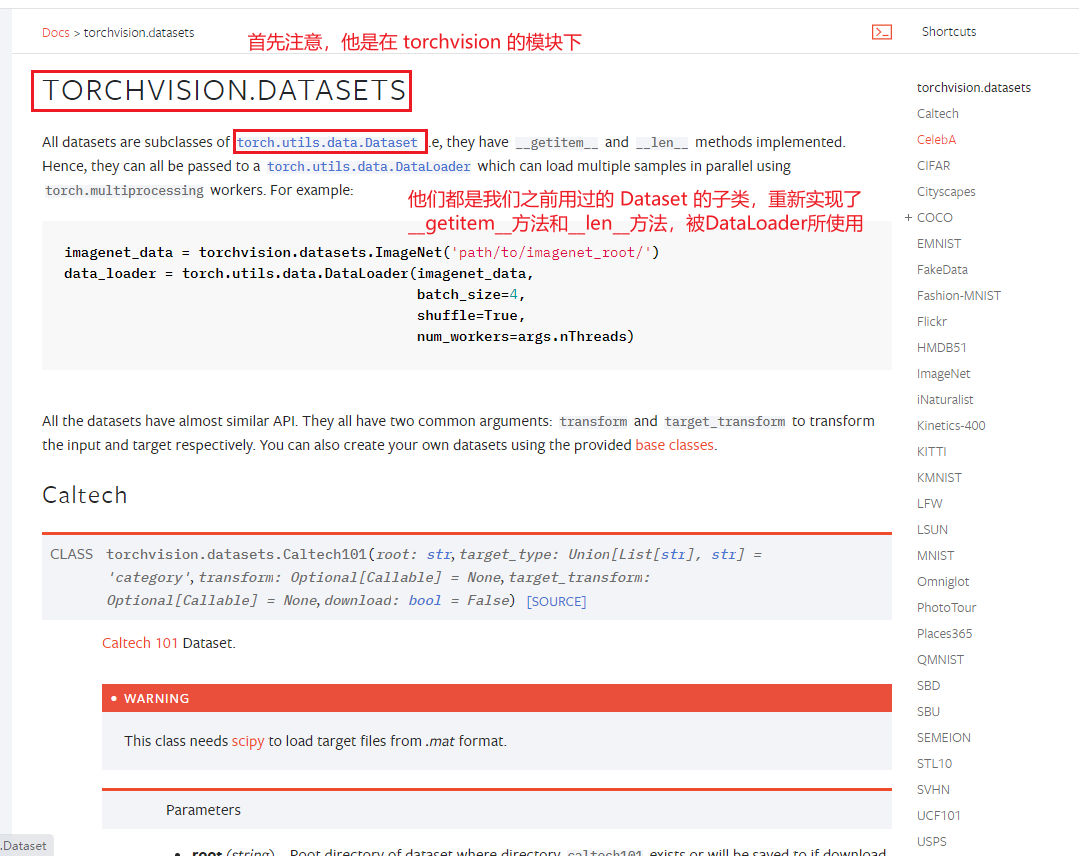
下面,我们以 torchvision.datasets.CIFAR10 为例,进行展示使用方法
CIFAR10 帮助文档
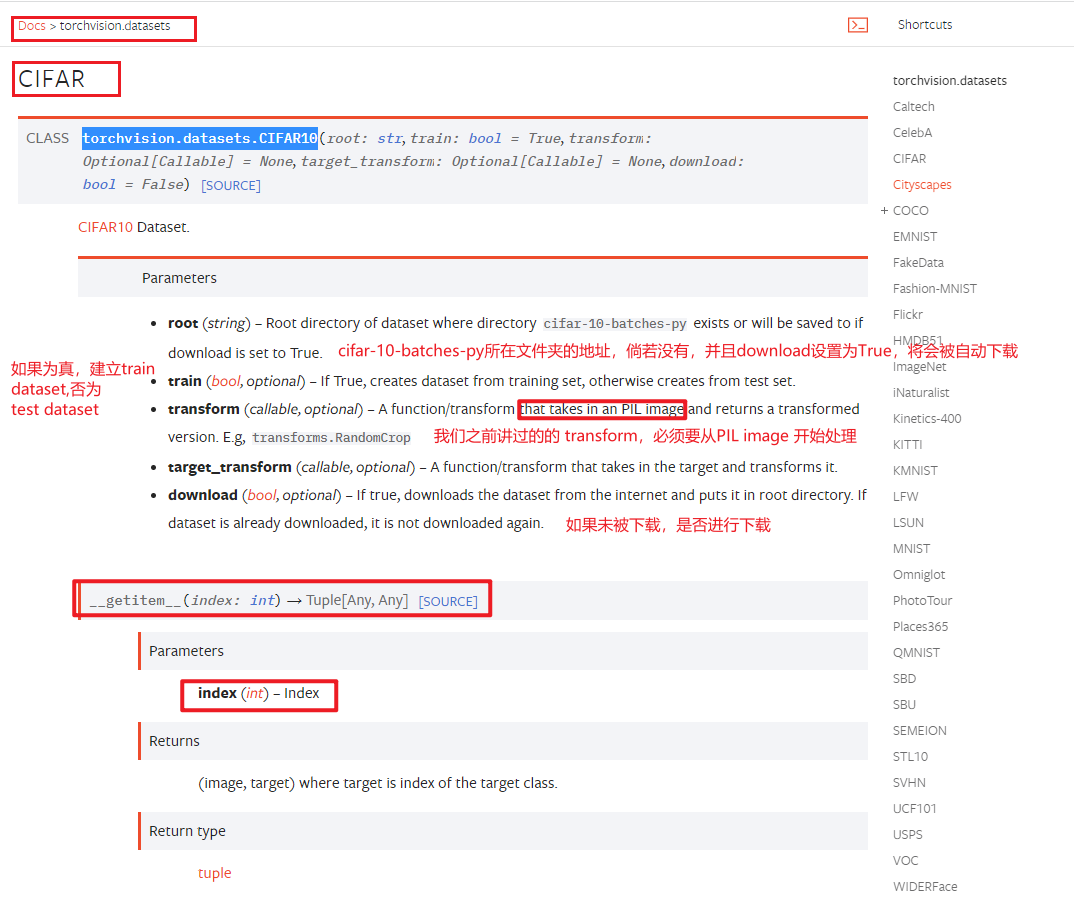
transform 和 target_transform 处理的对象不同,一个是 Image,一个是 image 对应的类别 target
CIFAR10的使用代码
from torchvision import datasets
from torchvision import transforms
from PIL import Image
import cv2
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import Dataset
root_dir = "data_cifar10"
data_train = datasets.CIFAR10(root=root_dir, train=True, transform=transforms.ToTensor(), download=True)
data_test = datasets.CIFAR10(root=root_dir, train=False, transform=transforms.ToTensor(), download=True)
targets = []
img, target = data_test[0]
trans_to_PIL = transforms.ToPILImage()
trans_to_PIL(img).show()
for i in range(10):
targets.append(data_test[i][1])
print(targets)
debug 过程中, 查看 data_train 的属性
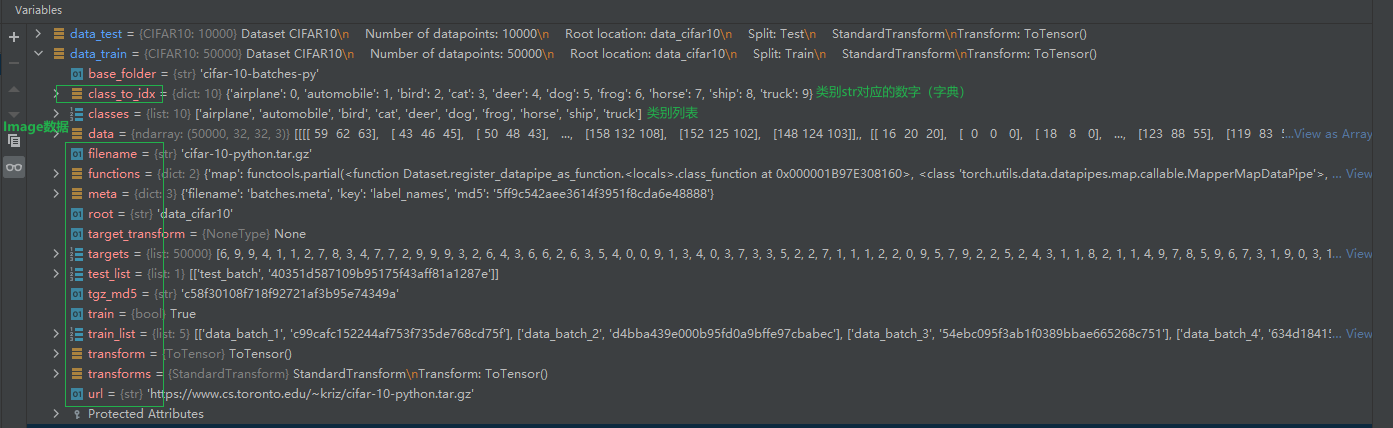
建议
-
download=True
当我们使用 dataset的 时候,最好设置download=True,通过设置参数为True,使得我们给定的 root 文件夹不存在数值的时候,自动下载文件,倘若存在的时候,并不会下载文件;也就是说,download=True,代码不容易出现一下奇奇怪怪的错误 -
资源下载
当我们下载文件比较慢的时候,可以通过自己手动下载,或者是借助一些下载工具完成下载,然后将其复制到我们的目标目录下即可。这主要是考虑到使用一些下载器其实能够起到一下加速下载的效果。
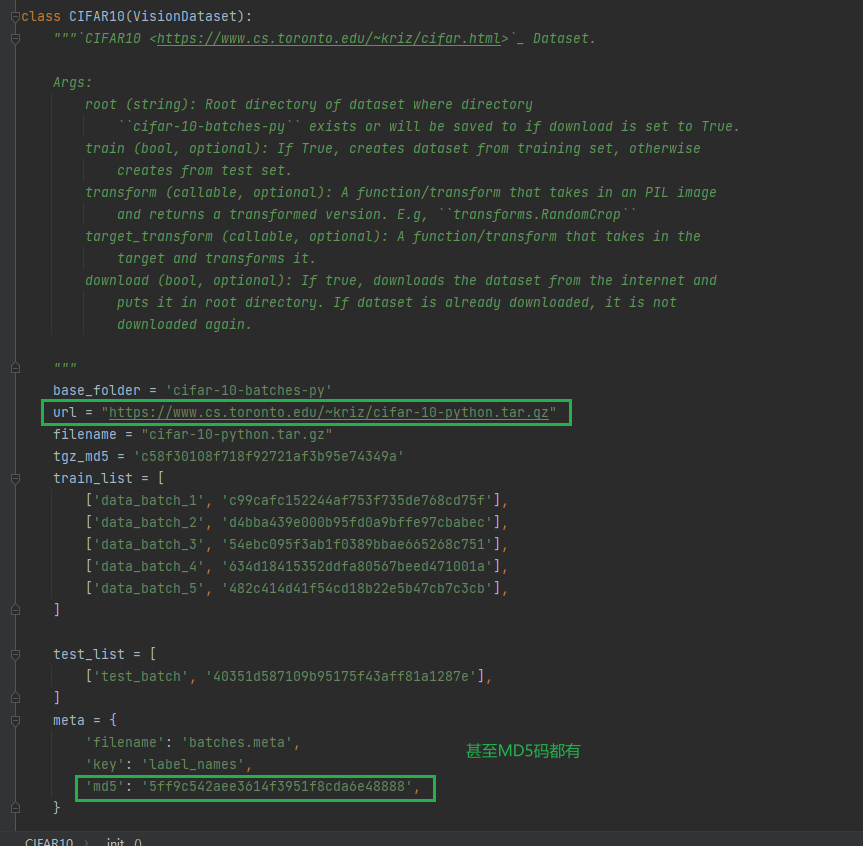
文件的下载链接也比较容易找到,如下图所示:


或者是进入我们的pycharm 帮助文档进行查找:

2. Dataloader
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。
下面,我们打开官方文档来一探究竟。
Dataloader 官方文档

Dataloader 的使用
import cv2
from PIL import Image
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
root_dir = "./data_cifar10"
dataset_train = datasets.CIFAR10(root=root_dir, train=True, transform=transforms.ToTensor(), download=True)
dataset_test = datasets.CIFAR10(root=root_dir, train=False, transform=transforms.ToTensor(), download=True)
dataloader_train = DataLoader(dataset=dataset_train, batch_size=64, shuffle=True, drop_last=True)
dataloader_test = DataLoader(dataset=dataset_test, batch_size=64, shuffle=True, drop_last=True)
log_dir = "logs"
writer = SummaryWriter(log_dir=log_dir)
for epoch in range(2):
step = 0
for data_imgs, data_targets in dataloader_test:
writer.add_images(f"epoch{epoch}", data_imgs, step) #
step += 1
writer.close()
代码中主要容易的是这句话
for data_imgs, data_targets in dataloader_test:
writer.add_images(f"epoch{epoch}", data_imgs, step) #
step += 1
第一个, 我们接受的是两个参数,一个是 data_imgs, 一个是 data_targets
writer.addImages,注意是 Images,因为添加的并不是一张图片
附录
几个经常导入的 包
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
from PIL import Image
import os

 浙公网安备 33010602011771号
浙公网安备 33010602011771号