2. tensorboard和 transform的使用
本篇文章主要介绍 pytorch 中 tensorboard 和 transform 的使用。
1、tensorboard
tensorboard原本是tensorflow的可视化工具,pytorch从1.2.0开始支持tensorboard。之前的版本也可以使用tensorboardX代替。
tensorboard常常作为一个辅助工具,可以把Pytorch中的参数传递到Tensorboad上面。
tensorboard 的打开与关闭
tensorboard 作为一个可视化的辅助工具,是通过将日志文件写入到我们的目标文件夹中实现
既然是通过文件的写入和读取来实现的,那么必定包含文件的打开与关闭操作,具体的代码如下所示:
from torch.utils.tensorboard import SummaryWriter
# 创建一个对象,并设置存储路径
writer = SummaryWriter('./logs')
writer.close()
add_image(), add_scalar()
了解文件的打开与关闭之后,下一步就是如何向日志文件中写入数据,这里主要是介绍最为常用的两个方法 SummaryWriter.add_image() 和 SummaryWriter.add_scalar()
- SummaryWriter.add_scalar()
首先,查看帮助文档
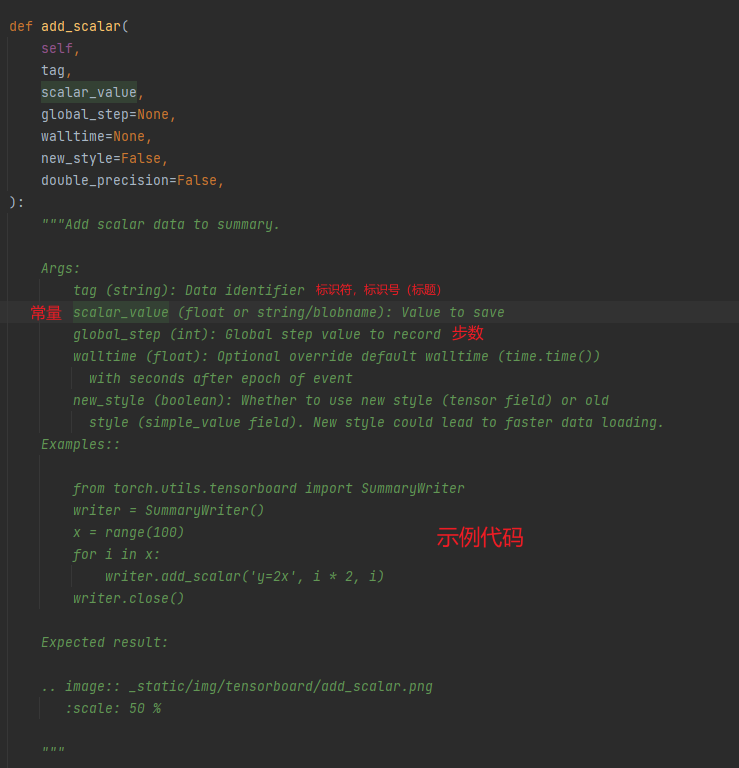
不能不夸奖一般 Pycharm 的帮助文档,写的非常详细(ctrl键按住,点击函数名即可)
那么,我们也写一个
from torch.utils.tensorboard import SummaryWriter
# 创建一个对象,并设置存储路径
writer = SummaryWriter('./logs')
for i in range(20):
writer.add_scalar("my:y=2x", i * 2, i)
writer.close()
- SummaryWriter.add_image()
帮助文档如下:
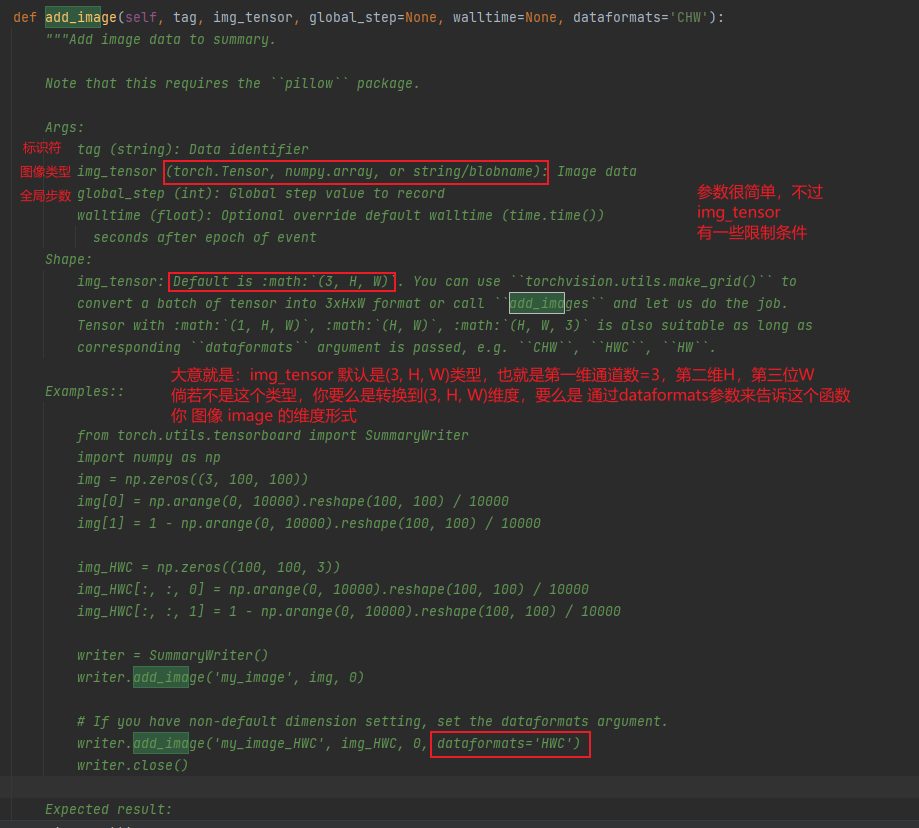
同样是照着葫芦画瓢,走一个
from torch.utils.tensorboard import SummaryWriter
# 用于读取图像和类型转化
from PIL import Image
import numpy as np
# 创建一个对象,并设置存储路径
img_path = r"F:\projects\pycharm\pytorch_dl\test\data\train\ants\0013035.jpg"
writer = SummaryWriter('./logs')
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
writer.add_image("test_img", img_array, 0, dataformats="HWC")
writer.close()
tensorboard 通过端口查看数据
需要在环境中cmd运行
tensorboard --logdir=logs
tensorboard --logdir=./logs --port=6066
默认端口号是6006,通过--port 参数我们可以指定特定的端口

tag 冲突处理
当我们在同一个 log 文件夹中,指定了同一个 tag,可能会照成显示图像的混乱,解决这个问题可以有以下这几个方法
-
更改日志文件存储位置
-
删除原本的日志文件
这两种方法都需要重启我们的 tensorboard 命令,ctrl + c 终止原本的 tenforboard 进程,然后开启新的 tensorboard进程即可
2、transform的使用
transform 的简单使用与 Tensor 数据类型
transform 顾名思义,就是用于数据类型转化的意思,他是torchvision模块下面的一个子模块transforms,该模块中包含大量用户数据类型转化的类型和方法。下面我们进入该模块中进行查看。 (注:pycharm 中 按住 ctrl 单机进去该模块即可)

常用的主要是一下这几个类:
Compose:通过查看帮助文档可知,他是 多个 transform 的结合体,也就是说可以进行多次 transform 变化
ToTensor:
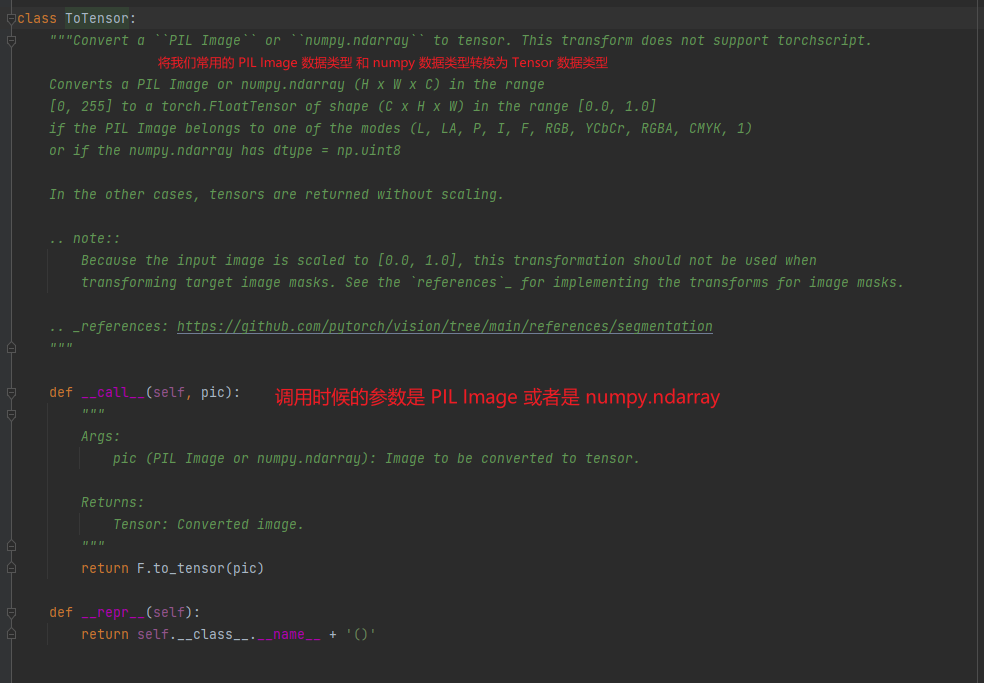
PILToTensor : Converts a PIL Image (H x W x C) to a Tensor of shape (C x H x W). 也是进行了类型的转换设置维度信息发生了变化
其他的请自行查看帮助文档,这里不再赘述。
下面,我进行一下简单使用的演示:
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import numpy as np
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\train\ants\5650366_e22b7e1065.jpg'
img_PIL = Image.open(img_path)
img_array = np.array(img_PIL)
tensor_trans = transforms.ToTensor()
img_tensor1 = tensor_trans(img_PIL)
img_tensor2 = tensor_trans(img_array)
writer = SummaryWriter('logs2')
writer.add_image('test1', img_tensor1, 0)
writer.add_image('test1', img_tensor2, 1)
writer.close()
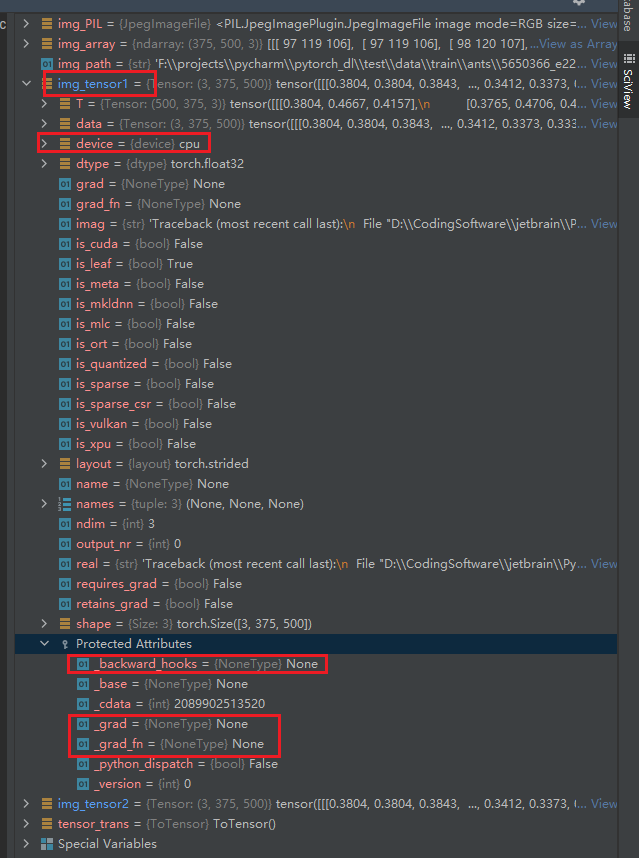
查看转换之后的 tensor 类型,可以看到一些专美用于做神经网络的属性,可以说tensor很大程度上是为了方面深度学习代码的书写(就像是 numpy 用于科学计算一样),
上面的代码中我们也使用 tensor,将其写在 Log 文件的 日志中去
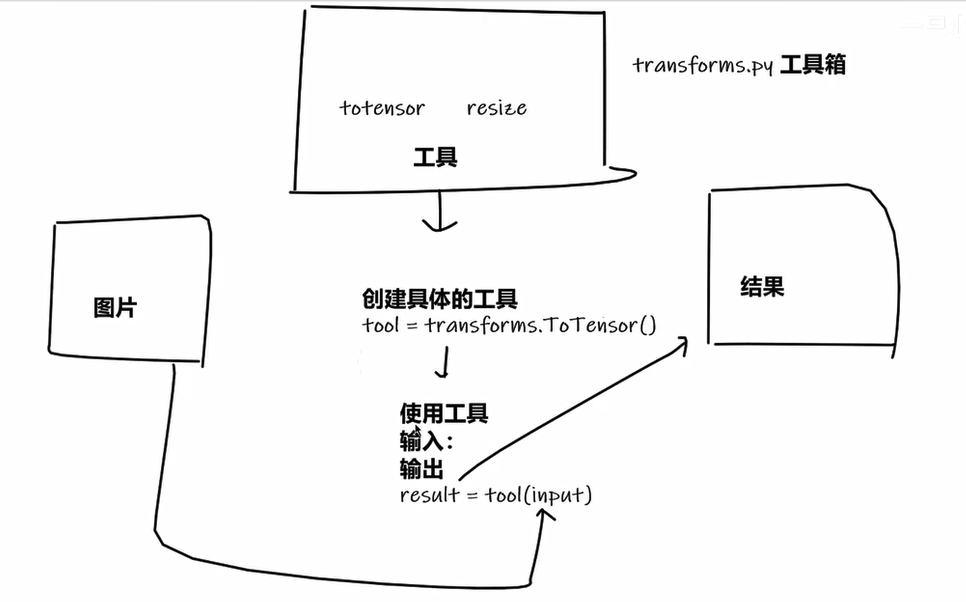
常见 transform 的使用
这里,我先引入一个小知识 pytorch 中类的 __call__函数和 forward函数都不用显示的调用函数,
这两个函数的作用是能够让python中的类的对象能够像方法一样被调用!具体可以参考博客:
深入探究# PyTorch中的 forward() 方法详解
transform 非常的常见,常常用于转化数据的格式(上一节有着些许的介绍),下面我将进行更为详细的介绍。
我们的函数的认知(尤其是库函数),主要从一下三种方面出发:
- 函数的作用 -- 这也是我们使用该函数的目的已经应用场景
- 函数的输入格式 -- 教会我们如何使用函数
- 函数的输出格式
在我看来,想要快速的了解函数的功能与使用方法,上手一个函数,还是需要看官方文档,幸好Pycharm IDE 中集成了帮助文档,虽然英文,不过写的足够详细,下面我将一个一个的介绍 transform 模块的常用函数
首先,我们还是大致看一下 transform.py 中的函数
下面,我们查看官方文档 + 使用 tensorboard 进行查看函数的作用
首先,我们先说2个小技巧:
- 输入代码的时候
ctrl+p可以提示函数参数 - 设置代码提示是是否忽略大小写(参考下午)
ToPILImage
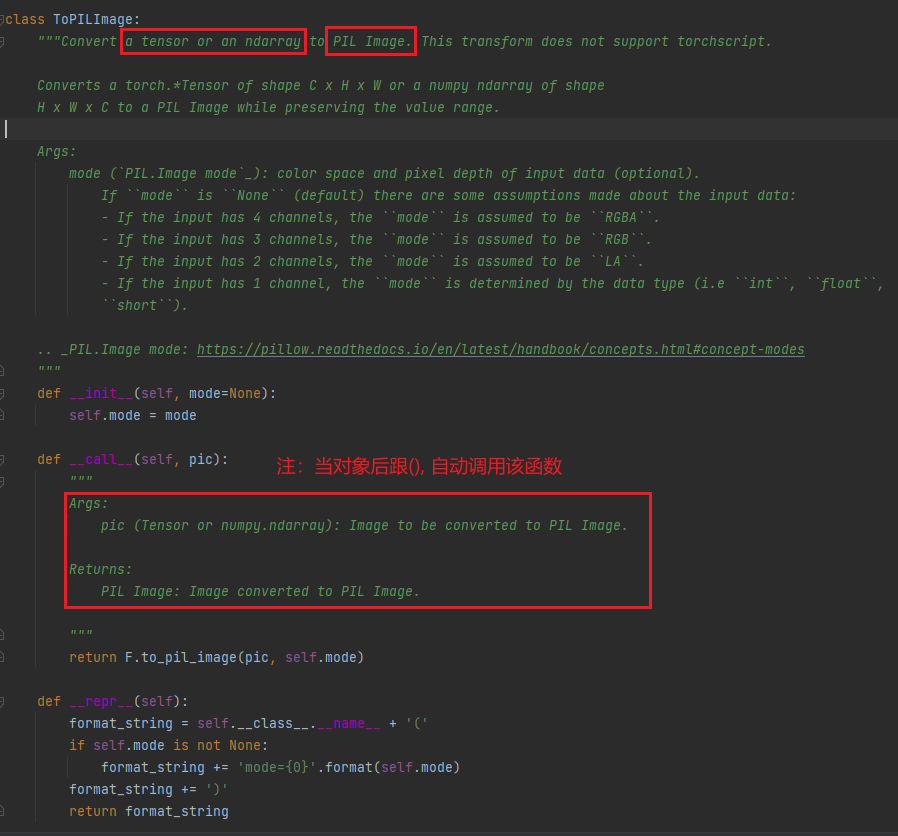
我们使用 cv2.read() 和 Image.open()分别进行读取图片,将其放入到 logs 文件中,通过 tensorboard进行查看
# 导入几个包
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array = cv2.imread(img_path) # 其实并不是失真,而是在导入图片时使用了opencv,正常展示顺序是RGB,而opencv的读取顺序是BGR,
trans_toPIL = transforms.ToPILImage()
trans_toTensor = transforms.ToTensor()
img_PIL = trans_toPIL(img_array) # 调用了 __call__ 函数,转化形成 PIL
img_PIL_2 = Image.open(img_path) # 直接读的 PIL图片格式
print(type(img_array))
writer.add_image('ndarrayy - PILImage - PILImage', img_array, 0, dataformats="HWC")
writer.add_image('ndarrayy - PILImage - PILImage', trans_toTensor(img_PIL), 1)
writer.add_image('ndarrayy - PILImage - PILImage', trans_toTensor(img_PIL_2), 2)
# close tensorboard
writer.close()
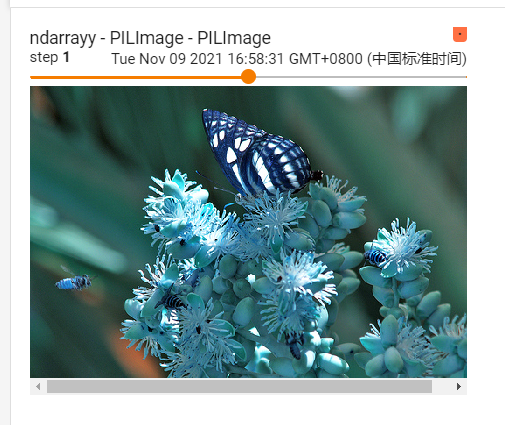
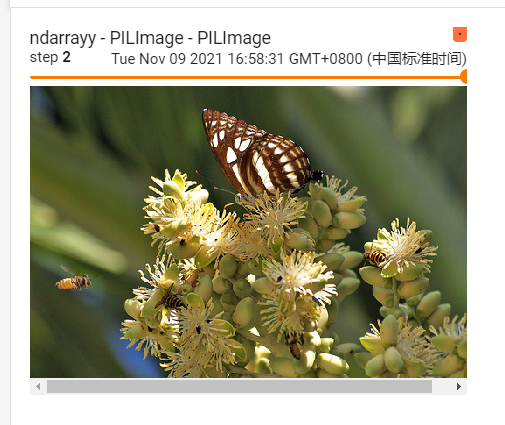
发现颜色出了问题
其实这不是cv2读取文件出现了问题,而是我们cv2读取文件 读取通道顺序为B、G、R
和我们平时的 RGB 顺序完全相反,所以造成了这种奇奇怪怪的现象,将其修改也较为简单
# 第一种方法,推荐使用该种方法,因为第一种方法存在问题
# 尤其是在转换 tensor的时候,我的 pycharm 会直接 报错,异常退出,我还找了半天bug
b,g,r = cv2.split(img_array) #分别提取B、G、R通道
img_array = cv2.merge([r, g, b]) # 可以将其写成一个函数封装一下子了
# 第二种方法
#img[:,:,0]表示图片的蓝色通道,对一个字符串s进行翻转用的是s[::-1],同样img[:,:,::-1]就表示BGR通道翻转,变成RGB
img_array = img_array[:, :, ::-1]
转化之后,再次运行一下,发现颜色正常。
注意:一定要将之前的 event 日志全部给删除,然后重启我们的 tensorboard 工具

这里,我再进行一下 cv2 的些许补充,主要是对下述代码进行讲解,具体请看注释
# 导入几个包
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array_bgr = cv2.imread(img_path) # 首先我们使用了 cv2 库函数读取了图片,bgr色彩,ndarray类型
img_PIL = Image.open(img_path) # 我们又使用了 Image 类读取了图片 PIL 类型
b, g, r = cv2.split(img_array_bgr) # 这一步,我们使用 bgr分离,将 img_array_bgr --> img_array_rgb
img_array_rgb = cv2.merge([r, g, b])
cv2.imshow("img_array", img_array_rgb)
cv2.waitKey()
cv2.imshow("img_array", img_array_bgr)
cv2.waitKey()
# 我们将 rgb, bgr 分别转换为 PIL 进行 show展示
img_PIL.show()
trans_toPIL = transforms.ToPILImage()
img_PIL_rgb = trans_toPIL(img_array_rgb)
img_PIL_rgb.show()
img_PIL_bgr = trans_toPIL(img_array_bgr)
img_PIL_bgr.show()
# close tensorboard
writer.close()
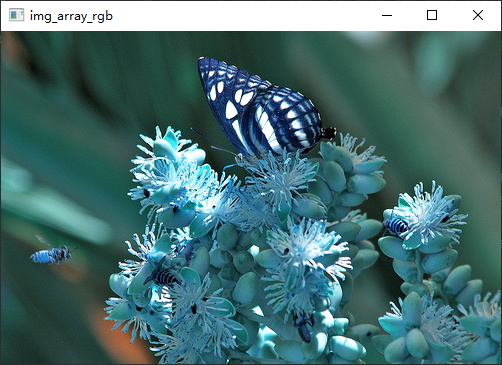
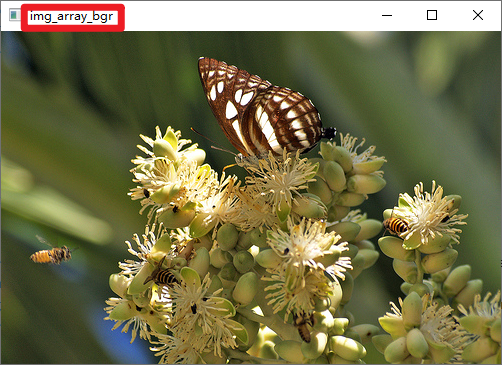

rgb和 img_PIL_Image_open都是一个图片

心得:
不难看出,cv2读取读片是 bgr, 解析显示图片也是 bgr,所以说仅仅是在 cv2 中使用,不需要进行 bgr->rgb 维度的转换,但是倘若cv2中混有 tensor,或者是 PIL因为他们使用了rgb 色系,应当进行相应类型的转换。
toTensor
这个之前讲过,也用过很多次,这里不再赘述(而且用法和 toPILImage 差不多)
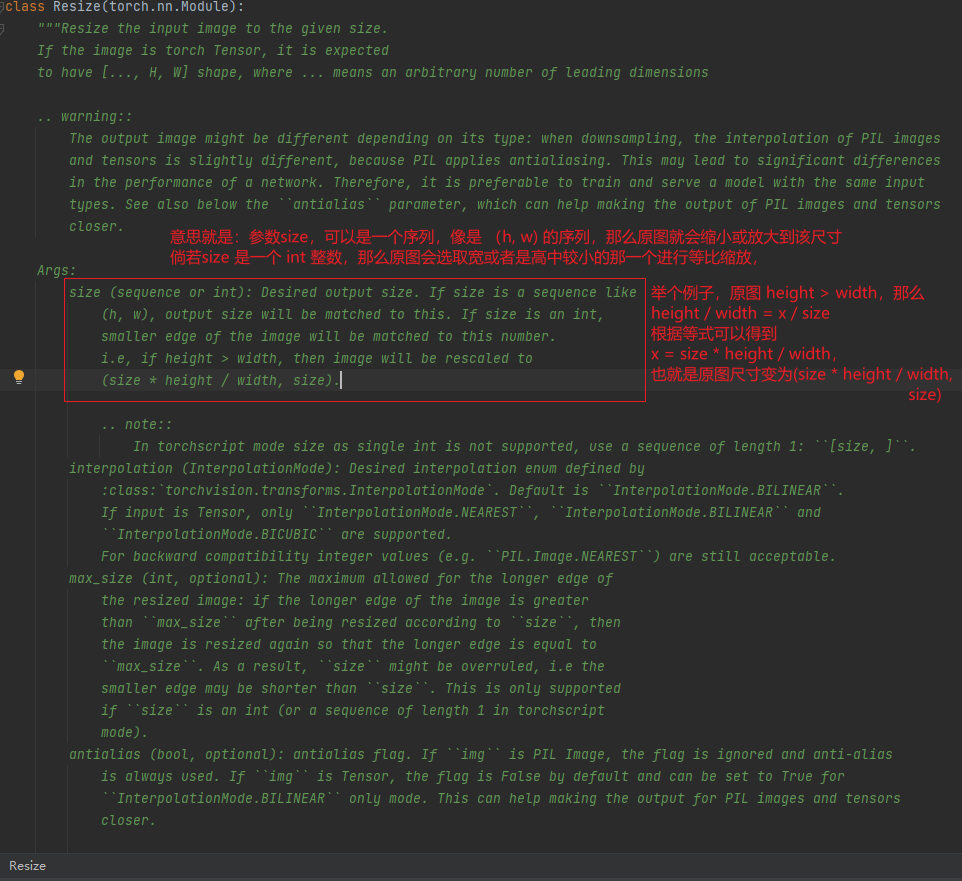
Resize
帮助文档的解释如下图所示:
直接找一个图进行实践即可(效果显著,像素变得非常的拉胯!!!)
# 导入几个包
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array = cv2.imread(img_path) # 其实并不是失真,而是在导入图片时使用了opencv,正常展示顺序是RGB,而opencv的读取顺序是BGR,
# img_array = img_array[:, :, ::-1]
b, g, r = cv2.split(img_array)
img_array2 = cv2.merge([r, g, b])
img_array3 = img_array[:, :, ::-1]
img_array = img_array2
trans_toPIL = transforms.ToPILImage()
trans_toTensor = transforms.ToTensor()
trans_resize = transforms.Resize(100)
trans_resize2 = transforms.Resize([100, 50]) # 注意这个[],因为他是一个序列 list
img_tensor = trans_toTensor(img_array)
img_tensor_resize = trans_resize.forward(img_tensor)
img_tensor_resize2 = trans_resize2.forward(img_tensor)
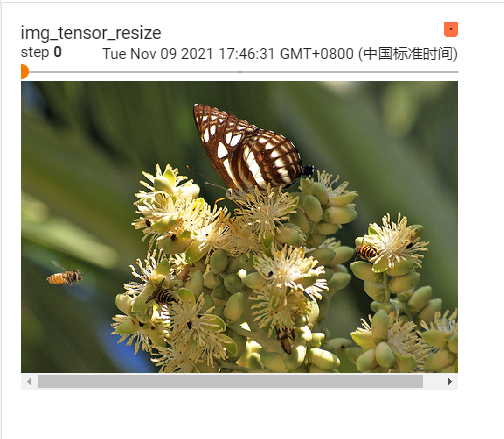
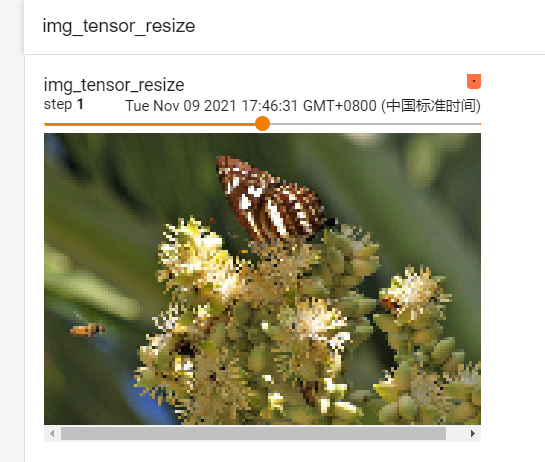
writer.add_image("img_tensor_resize", img_tensor, 0)
writer.add_image("img_tensor_resize", img_tensor_resize, 1)
writer.add_image("img_tensor_resize", img_tensor_resize2, 2)
# close tensorboard
writer.close()
debug 查看他的像素值变化:


Normalize
Normalize,规范化,特殊情况下也可以成为归一化,
归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。归一化有同一、统一和合一的意思。
归一化的目的简而言之,是使得没有可比性的数据变得具有可比性,同时又保持相比较的两个数据之间的相对关系,如大小关系;或是为了作图,原来很难在一张图上作出来,归一化后就可以很方便的给出图上的相对位置等。
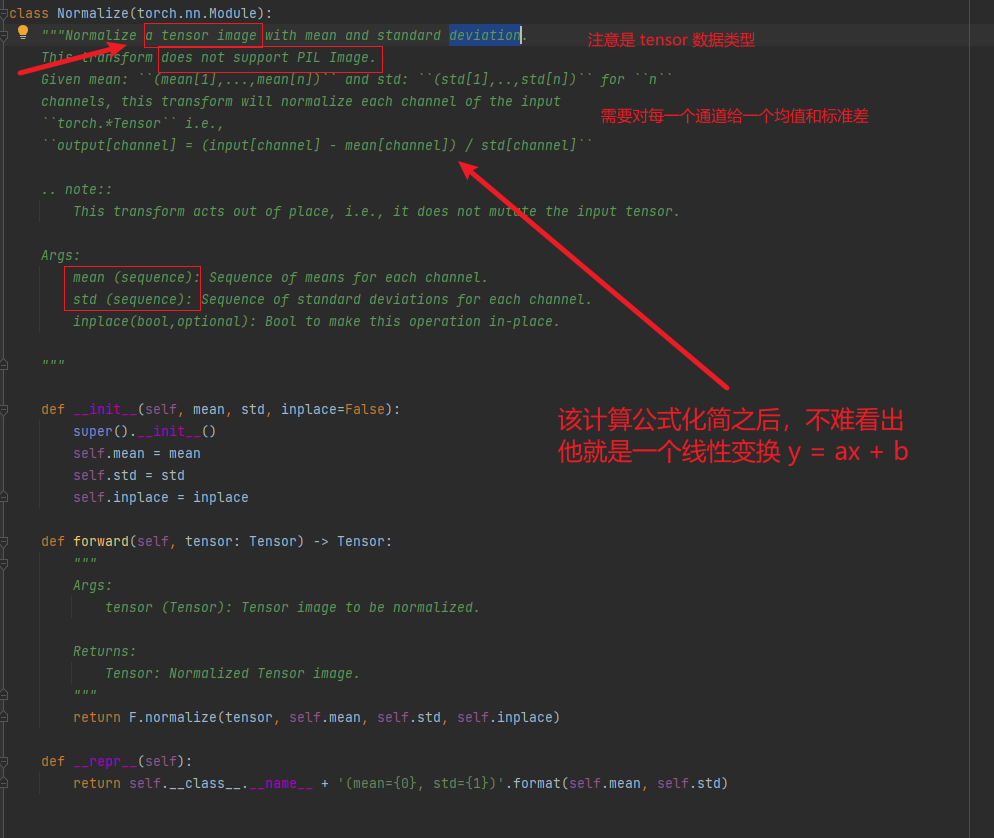
帮助文档的解释如下图所示:
走一个小代码试一试
# 导入几个包
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array_bgr = cv2.imread(img_path) # 其实并不是失真,而是在导入图片时使用了opencv,正常展示顺序是RGB,而opencv的读取顺序是BGR,
img_PIL = Image.open(img_path)
b, g, r = cv2.split(img_array_bgr)
img_array_rgb = cv2.merge([r, g, b])
trans_to_tensor = transforms.ToTensor()
trans_to_PIL = transforms.ToPILImage()
trans_to_norm = transforms.Normalize([1, 2, 3], [3, 4, 5])
img_tensor = trans_to_tensor(img_array_rgb)
img_tensor_norm = trans_to_norm(img_tensor)
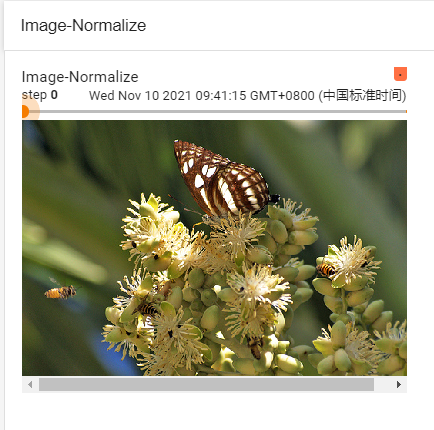
writer.add_image("Image-Normalize", img_tensor, 0)
writer.add_image("Image-Normalize", img_tensor_norm, 1)
# close tensorboard
writer.close()
倘若你的 tensorboard 出现了问题,请记得退出你的 tensorboard 进程,并且删除你的日志文件,在此运行改程序,倘若还有问题,可能是你的代码、或者是环境出了问题。

Compose
帮助文档的解释如下图所示:
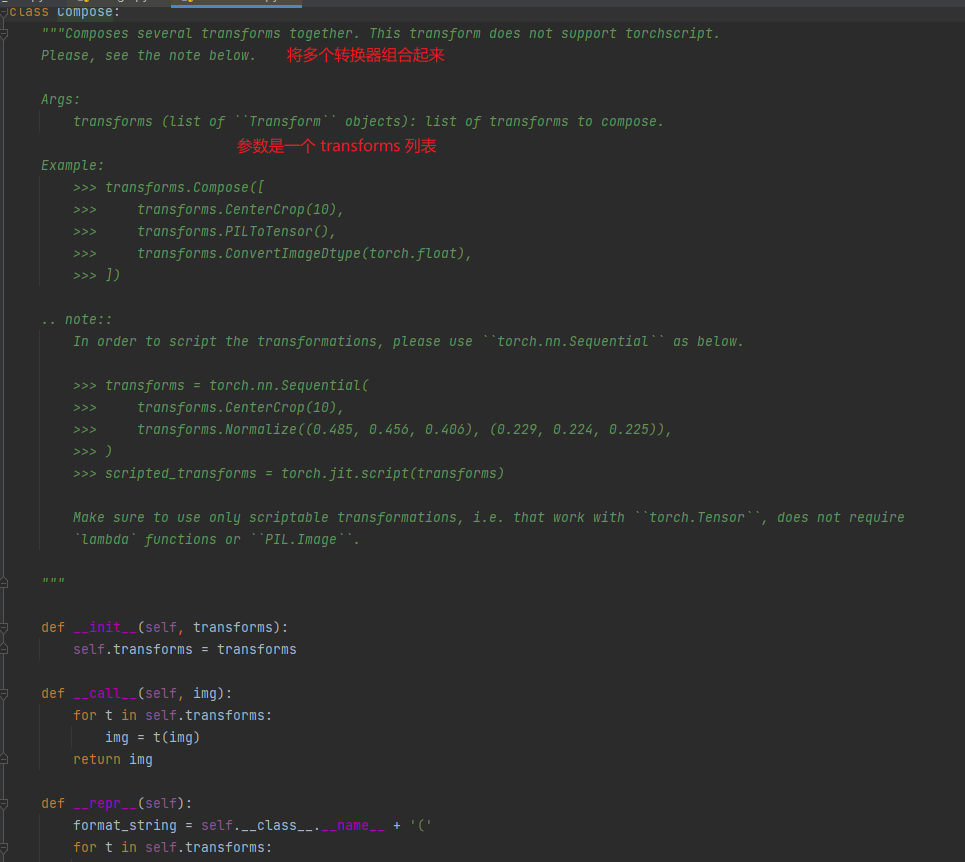
直接进行上手实验,我们连接一个 ToTensor、Resize 、 Normalize 的转换器,代码如下图所示:
# 导入几个包
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array_bgr = cv2.imread(img_path) # 其实并不是失真,而是在导入图片时使用了opencv,正常展示顺序是RGB,而opencv的读取顺序是BGR,
img_PIL = Image.open(img_path)
b, g, r = cv2.split(img_array_bgr)
img_array_rgb = cv2.merge([r, g, b])
trans_to_tensor = transforms.ToTensor()
trans_compose = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(200),
transforms.Normalize([1, 2, 3], [1, 2, 3])
])
img_compose = trans_compose(img_array_rgb)
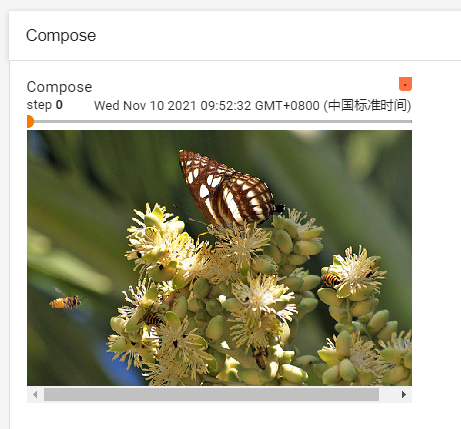
writer.add_image("Compose", trans_to_tensor(img_array_rgb), 0)
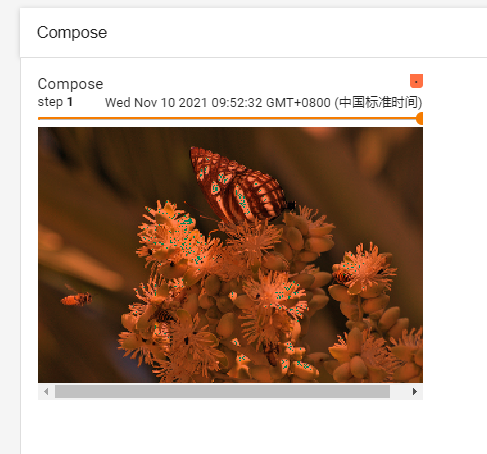
writer.add_image("Compose", img_compose, 1)
# close tensorboard
writer.close()
结果如下所示:
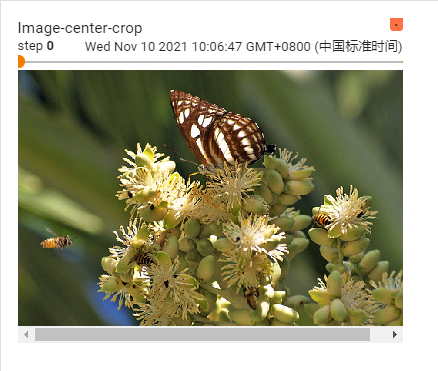
CenterCrop
帮助文档的解释如下图所示:
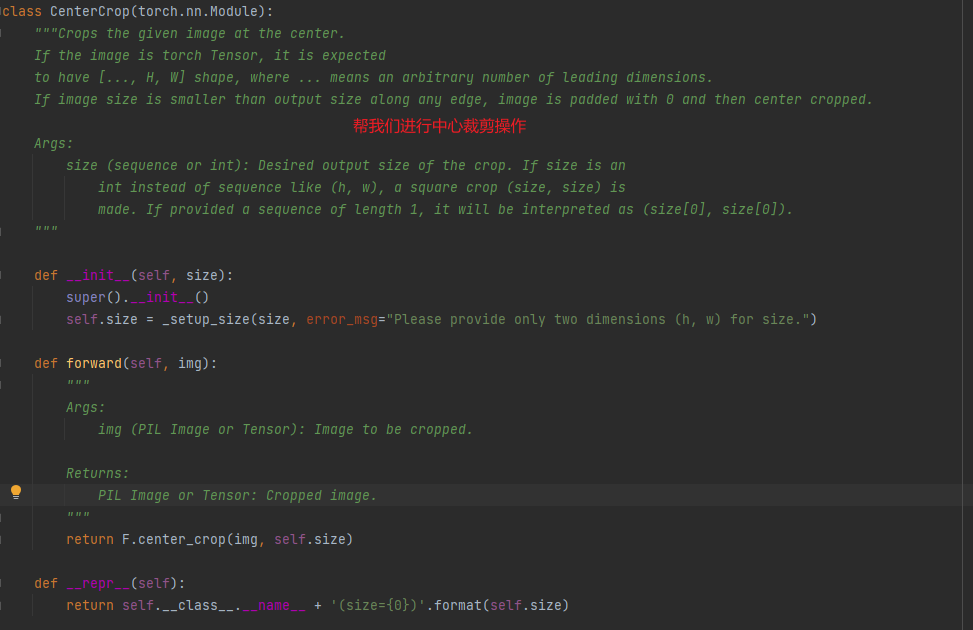
直接上代码:
# 导入几个包
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import cv2
import numpy as np
# define the variable and open tensorboard
writer = SummaryWriter('logs')
img_path = r'F:\projects\pycharm\pytorch_dl\test\data\val\bees\72100438_73de9f17af.jpg'
# read the image
img_array_bgr = cv2.imread(img_path) # 其实并不是失真,而是在导入图片时使用了opencv,正常展示顺序是RGB,而opencv的读取顺序是BGR,
img_PIL = Image.open(img_path)
b, g, r = cv2.split(img_array_bgr)
img_array_rgb = cv2.merge([r, g, b])
trans_to_tensor = transforms.ToTensor()
trans_center_crop = transforms.CenterCrop((100, 100))
img_tensor = trans_to_tensor(img_array_rgb)
img_center_crop = trans_center_crop(img_tensor)
writer.add_image("Image-center-crop", img_tensor, 0)
writer.add_image("Image-center-crop", img_center_crop, 1)
# close tensorboard
writer.close()

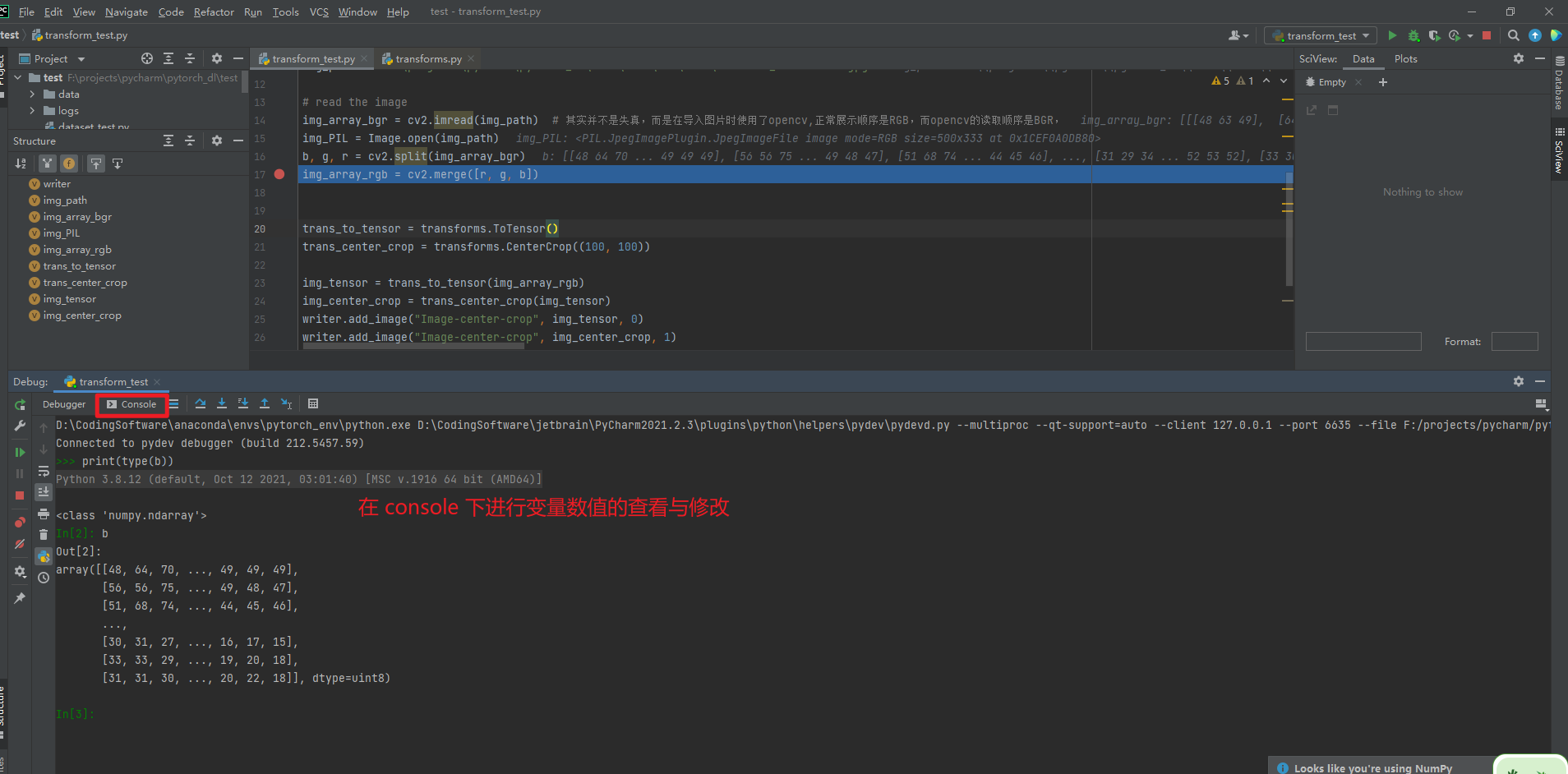
pycharm 的小技巧
- pycharm 的断点调试,非常的好使,主要是因为他还至此在断点中查看变量的数值,并且可以进行变量的修改,简直就是和 Python console 一样,用起来都很爽

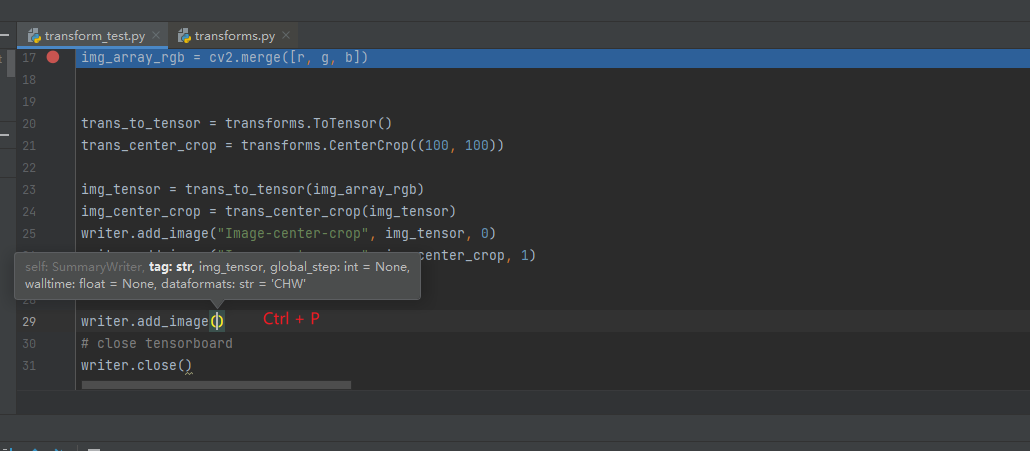
- pycharm
ctrl+p查看代码提示
- 顺便提一嘴,查看帮助文档的时候,尽量自己查看,不要使用翻译软件(不是很准),主要是注意 输入、输出和函数的功能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号