python基础知识点小结(2021/2/9)
python基础知识点小结(2021/2/9)持续更新中~~
入门小知识
python 一个面向对象、动态、强类型的解释型语言,下面我们给出一个网图来看一看
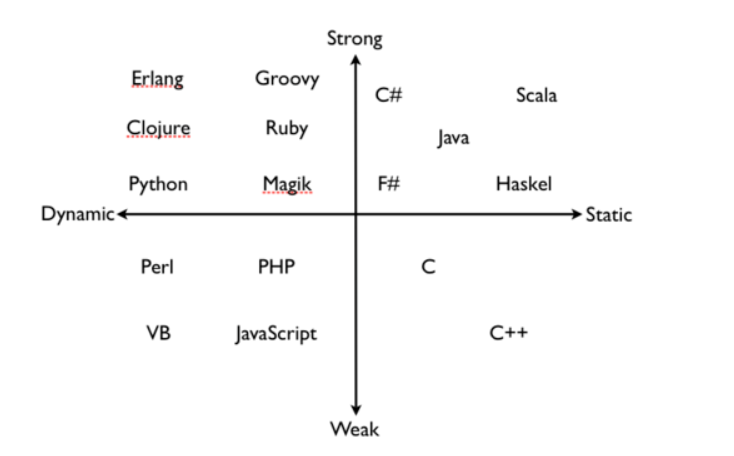
- 动态类型语言:在运行期进行类型检查的语言,也就是在编写代码的时候可以不指定变量的数据类型,比如Python和Ruby,或者说如果一门语言可以在运行时改变变量的类型,那我们称之为动态类型语言
- 静态类型语言:它的数据类型是在编译期进行检查的,也就是说变量在使用前要声明变量的数据类型,这样的好处是把类型检查放在编译期,提前检查可能出现的类型错误,典型代表C/C++和Java.相反。如果一门语言不可以在运行时改变变量的类型,则称之为静态类型语言
- 强类型语言,一个变量不经过强制转换,它永远是这个数据类型,不允许隐式的类型转换。举个例子:如果你定义了一个double类型变量a,不经过强制类型转换那么程序int b = a无法通过编译。典型代表是Java。如果一门语言倾向于不对变量的类型做隐式转换,那我们将其称之为强类型语言
- 弱类型语言:它与强类型语言定义相反,允许编译器进行隐式的类型转换,典型代表C/C++。相反,如果一门语言不可以在运行时改变变量的类型,则称之为静态类型语言
python不倾向于对变量的类型做隐式转换,因此是一门强类型语言:a = 1b = "1"a < b // Type errora == b // false,符合==的意思,类型都不一样显然是不相等的1 + 1.1 // 2.1,为了符合直觉做了隐式转换其次,python可以在运行时改变变量的类型,因此python是一门动态类型语言:a = 1a = "1" // 不会报错
判断一个语言是否是强类型语言的标准只有一个:
如果语言经常隐式地转换变量的类型,那这个语言就是弱类型语言,如果很少会这样做,那就是强类型语言。
Python很少会隐式地转换变量的类型,所以Python是强类型的语言
强弱类型语言+动态静态语言辨析的内容来源
常见赋值
a=b=c=1 # 连续赋值
b=1,2,3 # 元组
a,b=1,a # 下图解释, a=1,b=a是同时执行的,不是先 a = 1 然后 b = 3,因此 b 接受的是 a 原来的数字

cmd
- 在cmd上进行python,直接输入 \(\quad python\)
- 退出cmd输入 \(\quad exit()\)
- 到指定文件夹上运行python文件 \(\quad python 路径文件名.py\)
python注释
- 单行注释\(\quad\#\)
- 多行注释\(\quad ''''''\quad\) 6个单引号
- 当python 使用中文时,有时候会出错,记得加上
- 注释的快捷键 **Ctrl + / **
# -*- coding:utf-8 -*-
变量、标识符和关键字
变量
- \(python\)变量可以是任意数据类型,命名规则和\(c,c++\)相同
- python值得一提的是他的变量本质,类似于标签和指针
关键字
- 是已经被\(python\)内部使用的名称
- \(import\quad keyword; \quad keyword.kylist\)
输出与输入
输出
- 普通的输入输出\(\quad print('这是普通输入输出')\)
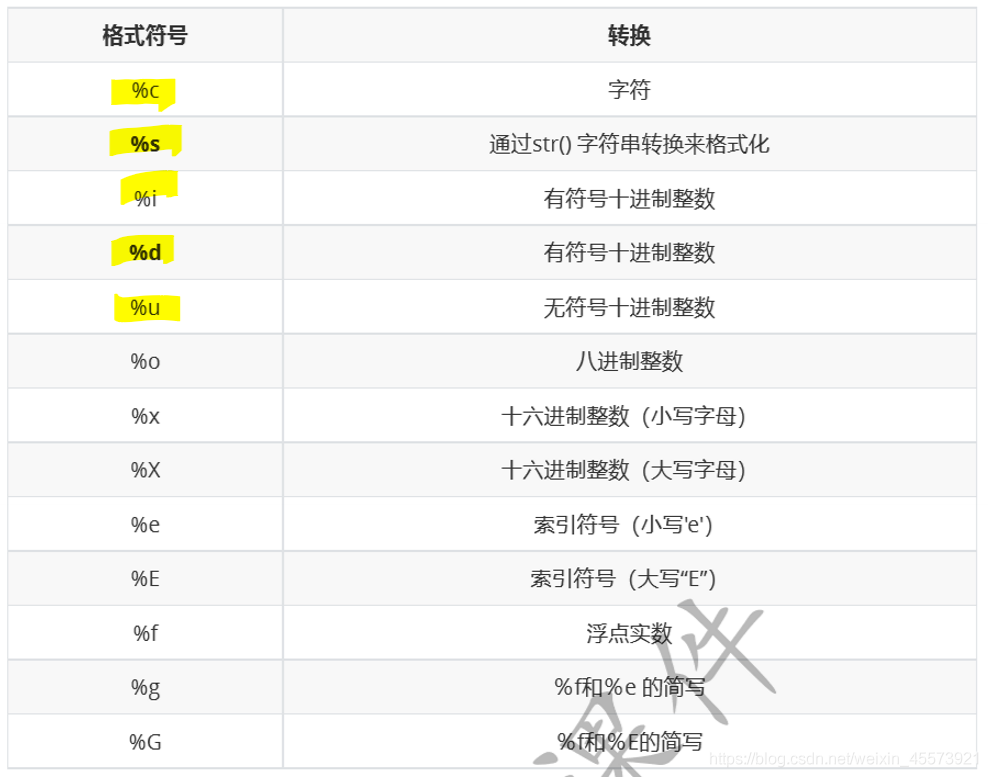
- 格式化输入输出\(\quad print('我的姓名是\%s,我的年龄是\%d'\%(name, age))\)
- 同c++,c一样,使用\(\quad\) '\n'\(\quad\)换行
- 常见的格式符号如下
输入
- 接收变量 = input('输入提示');
- 注意接收的输入
- input接受的数据是字符串,想要变成整数啥的,需要使用\(\quad int(),\quad eval(),\quad float(),\quad str()\)
- 下面看几个有趣的实验
# 表达式的计算直接就使用 eval(),简单方便好使
>>> a = 123
>>> b = eval(input())
a * 2
>>> b
246
运算符和表达式
算数运算符
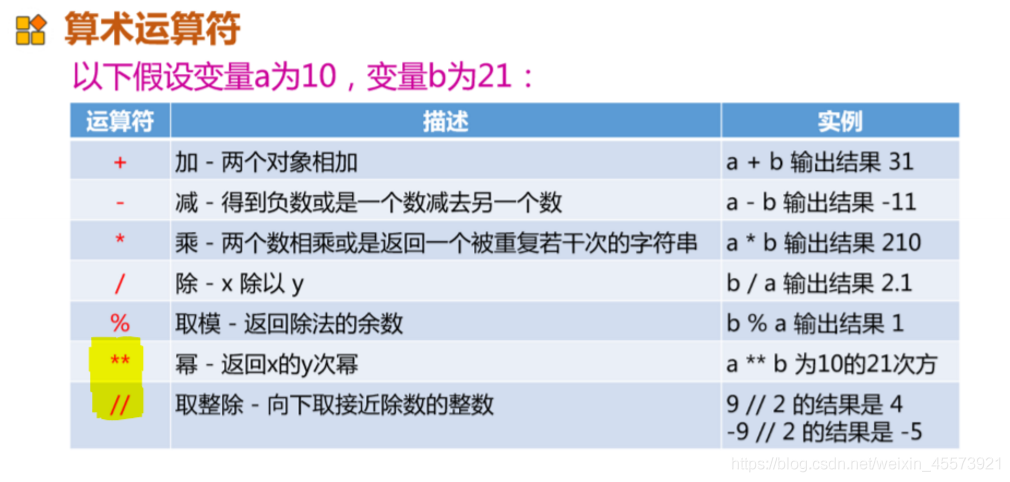
- 注意,负数求余的正负,关键是看\(\quad \% \quad\)后数字的正负
小实验
>>> a = 12.5
>>> b = 2
>>> a % b
0.5
>>> a / b
6.25
>>> a // b
6.0
>>> a ** b
156.25
>>> b ** a
5792.618751480198
>>> -15 % -2 # 余数的正负,跟随 % 后数的正负
-1
>>> 15 % -2
-1
>>> -15 % 2
1
>>> 15 % 2
1
比较运算符

赋值运算符

位运算符

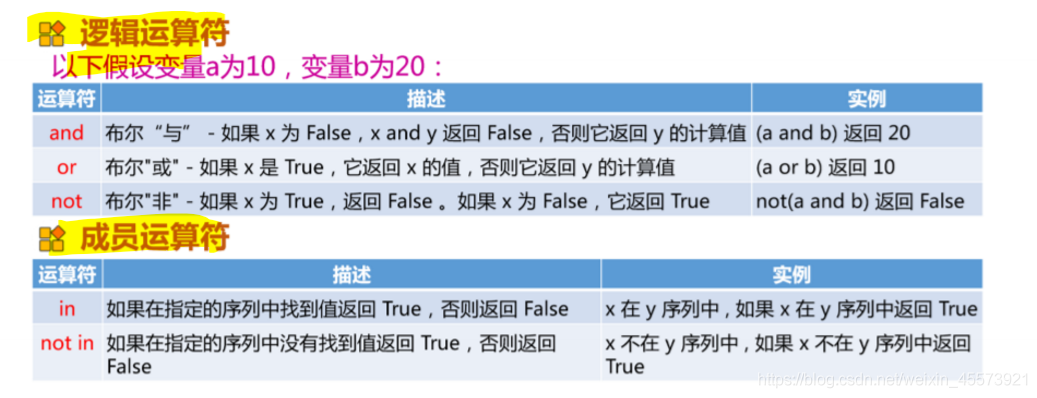
逻辑运算符和成员运算符
身份运算符

运算符优先级
\(\quad\quad\quad\quad\quad\)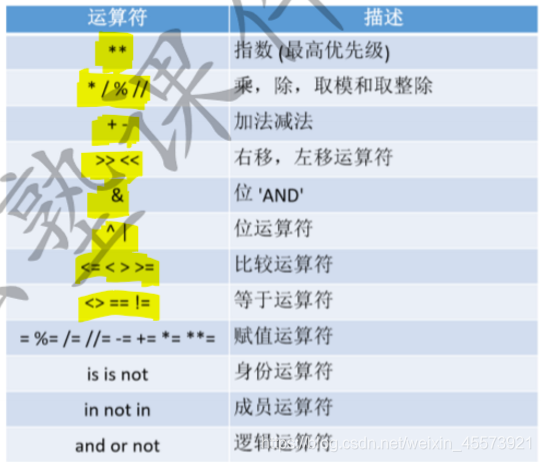
判断语句&循环语句&调用库
注意 : 冒号
判断语句
理论讲解
- if ~ else ~
- if ~ elif ~ elif ~~~ else
- 嵌套
- 注意要缩进!!
- 石头剪刀布小游戏 py 代码
调用py库
- 将整个模块导入 \(\quad import \quad some\_module\)
- 从某个模块中导入某个函数\(\quad from \quad some\_module \quad import \quad some\_function\)
- 从某个模块中导入多个函数\(\quad from \quad some\_module \quad import \quad first\_func,second\_func...\)
- 将某各模块中的函数全部导入\(\quad from \quad some\_module \quad import \quad\) \*
import random as rd
'''
规则: 剪刀(0),石头(1),布(2),退出(3),其他输入都是不合法
首先是一个while循环,然后不断的接收输入的数据,
输入数据合法
是退出信号
直接退出
石头剪刀布
我们的random数据做比较,输出你赢了,你输了,是平局
输入不合法
要求重新输入,并说出游戏规则
'''
gesture = ["石头", "剪刀", "布"];
while True:
print('--------------------------------------------------------');
_data = input('规则: 剪刀(0),石头(1),布(2),退出(3),其他输入都是不合法\n请输入数据:')
_rdm = rd.randint(0, 2);
if _data == '0' or _data == '1' or _data == '2': # 合法的正确输入,和随机数比大小
_data = int(_data);
print('玩家出的是%s' % gesture[_data]);
print('电脑出的是%s' % gesture[_rdm]);
if _data == _rdm:
print("双方平局");
elif _data == 0 and _rdm == 2 or _data == _rdm + 1:
print('玩家赢了');
else:
print('玩家输了');
elif _data == '3': # 游戏退出
print('游戏结束');
break;
else: # 非法输入
print('输入数据错误,请重新输入');
continue;
循环语句(for&while\(\Rightarrow\)break&continue&pass)
for循环形式
借助range()
- 注意range(start, end, step), 从start开始,步长为step,一直到end(但是取不到end)
for i in range(5): # 输出的是 0~4,不会到5的
print(i);
for i in range(1, 6, 2): # 输出的是1, 3, 5
print(i);
用于列表和字符串
name = 'tengzhou'
for i in name: #会把 tenghzhou 在一行输出
print(i, end='');
while循环形式
练习1~n的累加和,和偶数的 累加和
n = 100;
sum_all = 0; sum_even = 0; i = 1;
while i <= n:
sum_all += i; # 任意数
if (i & 1) == 0: # 偶数
sum_even += i;
i += 1
print('1~100的数字和为:', sum_all);
print('1~100的偶数和为:', sum_even);
break, continue, pass语句
break, continue, pass的区别与联系

练习打印九九乘法表
i = 1;
j = 1;
# 打印 i * j
# i 作为外层循环,j 作为内层循环
while i <= 9:
j = 1;
while j <= i:
if j < i:
print("%d * %d = %2d" % (i, j, i * j), end = ', \t');
else:
print("%d * %d = %2d" % (i, j, i * j));
j += 1;
i += 1;
str&list&tuple&dict&set
字符串
String字符串
- 常用单引号、双引号、三引号括起来,使用反斜杠 \ 来进行转义特殊字符.
- Python3默认UTF-8进行编码,所有字符串都是unicode字符串。
- 支持字符串的拼接、截取等等多种运算。
- 使用str 进行强制类型转化
单引号、双引号、三引号选取的区别与联系 <\font>
下面我们给出几个例子来看出使用单引号和双引号的区别
example 1: 字符串 I'am a student
- 使用单引号 'I'am a student' \(\Rightarrow\)必须使用转义字符
- 使用双引号 "I'm a student" \(\Rightarrow\)直接写就可以
example 2:字符串 Tom said "I like you"
- 使用单引号 'Tom said "I like you"' \(\Rightarrow\)直接写就可以
- 使用双引号 "Tom said "I like you"" \(\Rightarrow\)必须使用转义字符
三引号的应用:可以不在一行
- 有时被用于注释,其实注释的就是未被变量标记的字符串
下面看一下在代码中的显示
其中str1=str2, str3 = str4, s1=s2=s3=s4
# 单引号的和双引号的区别,关键在于转义字符
str1 = 'I\'am a student';
str2 = "I'am a student";
str3 = 'She said "I like you"';
str4 = "She said \"I like you\""
print('str1=', str1);
print('str2=', str2);
print('str3=', str3);
print('str4=', str4);
# 三引号
s1 = '''line1
line2'''
s2 = 'line1\nline2'
s3 = "line1\nline2"
s4 = 'line1\
\nline2'
print('s1=', s1);
print('s2=', s2);
print('s3=', s3);
print('s4=', s4);
转义字符
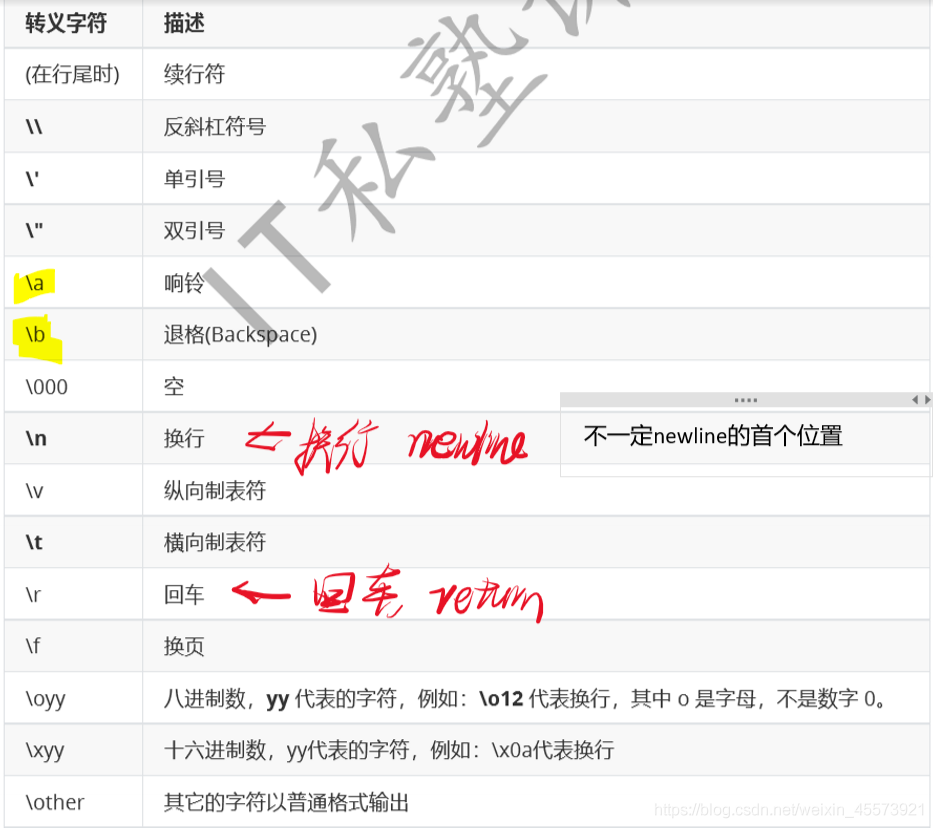
字符串的截取与连接
- print(str[0:7:2]); # [起始:终止:步长]-->[st:step:ed],注意是取不到 ed 的
- print(r'hello\npython'); # 在字符串面前加一个 r 表示原始字符串,不会发生转义。
- print(str[0:-1]); # 输出字符串0到倒数第二个,其实-1表示是最后一个,但是[st:ed]取不到最后一个。
直接上代码的示例
# 字符串的截取与连接
str = "shandong"
print(str); # 输出字符串
print(str[:]); # 输出字符串
print(str[0:]) # 输出字符串
print(str[0:-1]); # 输出字符串0到倒数第二个
print(str[0]); # 输出第0个字符, 从0开始计数
print(str[2:5]); # 输出第2个到第4个字符,从0开始计数
print(str[2:]); # 输出第2个到最后
print(str * 2); # 输出两遍
print(str + 'tengzhou') # 字符串连接后输出
print(str[:5]); # 输出从第0个到第5个字符
print(str[0:7:2]); # [起始:终止:步长]-->[st:step:ed],注意是取不到 ed 的
print('------------------------------');
print('hello\nshandong');
print(r'hello\npython'); # 在字符串面前加一个 r 表示原始字符串,不会发生转义。
字符串的常见操作


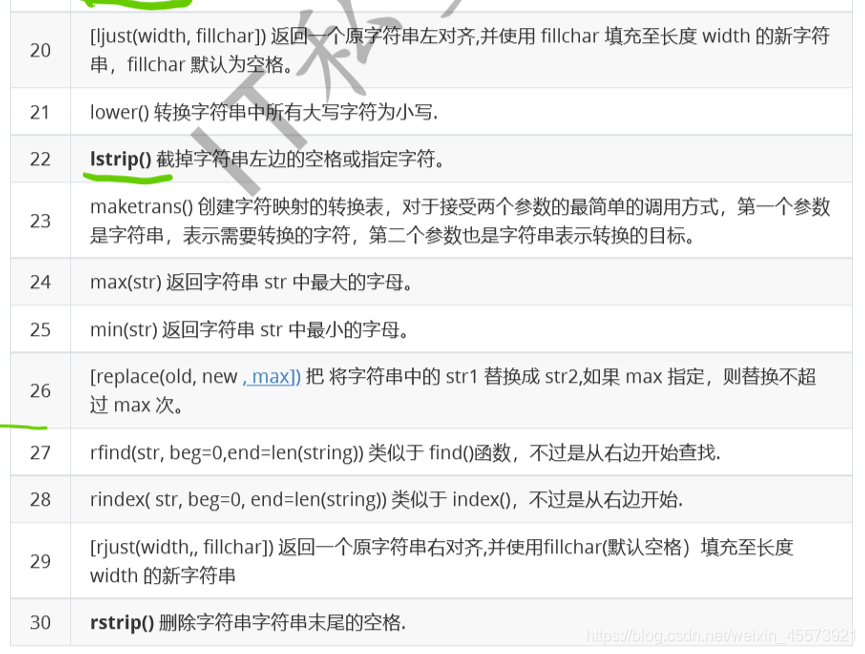
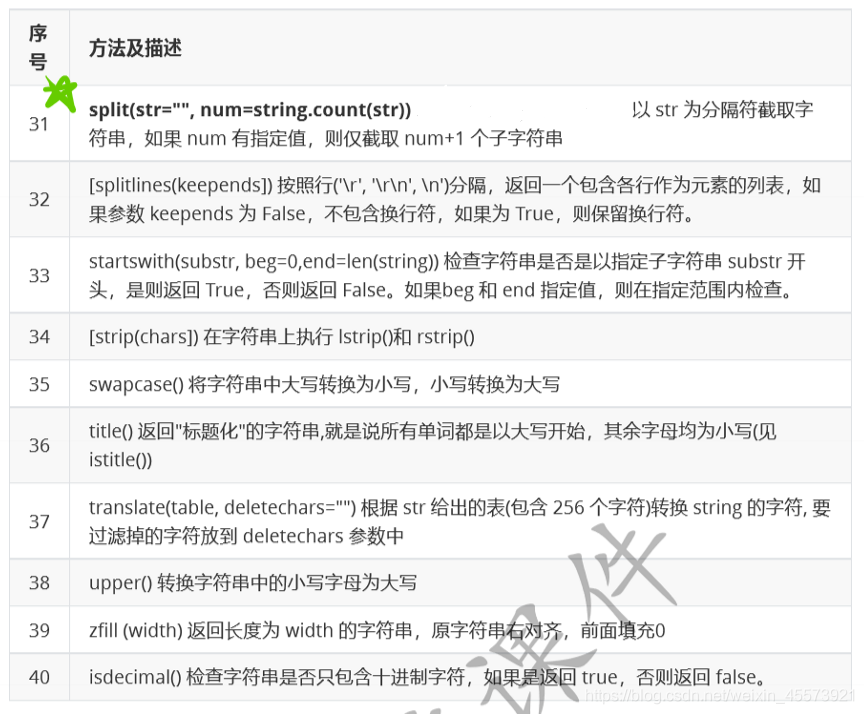
列表
- 列表中的数据结构可以不同,支持数字、字符串,也可以包括自身(列表的嵌套)。
- 列表元素写在 [] 之间,用 ‘,’分隔开。eg:list = ['abcd', 123, 2.123, 'python', 36.5];
- 索引值和 str类似,0表示开始数值, -1表示末尾的开始位置
- 同 string 相同, + 表示列表的拼接, * 表示列表的重复
列表的定义与访问
详情请看下面的代码示例
test_list = ['shanghai', 'beijing', "hunan", 123];
for x in test_list: # 输出形式 1
print(x);
for i in range(len(test_list)): # 输出形式 2
print(test_list[i]);
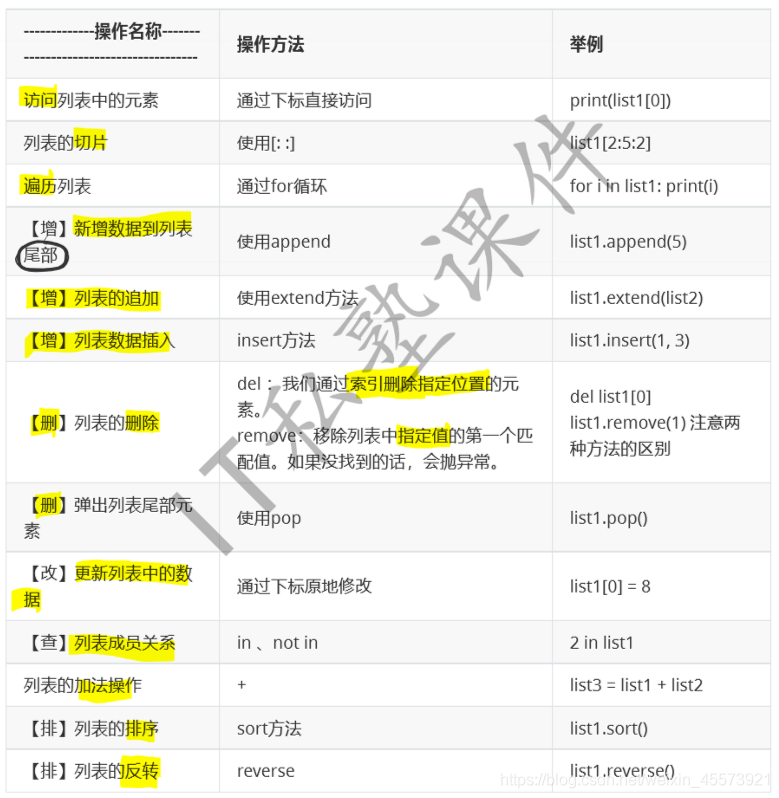
列表的常用操作
- 直接下标访问、切片、遍历列表
- 增加:append(element), extend(List)相当于将列表中的元素遍历进行append(), insert()插入到具体的位置
- 删除:del(idx), remove(val), pop(void)
- 修改,直接进行下标访问进行修改
- 查询是否在列表中, In, not in
- + 用于连接
- 列表的排序sort(), 翻转的reverse()
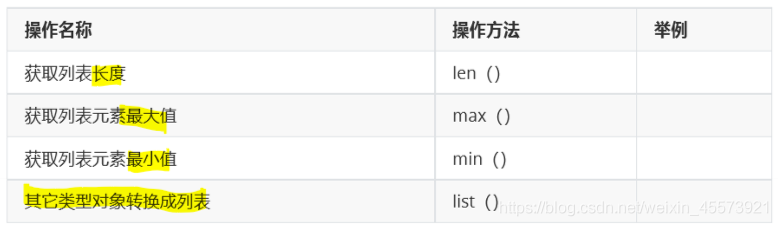
- 长度,最大值、最小值、强制类型转换: len, max, min, list;
列表的嵌套

import random
offices = [[], [], []]; # 三个办公室
teacher = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']; # 8个教室
for tea_name in teacher:
tmp = random.randint(0, 2);
offices[tmp].append(tea_name);
i = 1;
for off in offices:
print('办公室%d有%d人'%(i, len(off)), end='\n\t');
for tea in off:
print(tea, end=' ');
print('');
print('-'* 10);
i += 1;
编程作业

作业的实现的代码如下:
# 商品数据定义
products = [["iphone", 6888], ["MacPro", 14800], ["XiaoMin6", 2499],
["Coffee", 31], ["Book", 60], ["Nike", 699]];
# 商品显示
i = 0;
print('-'*6, ' 商品列表 ', '-'*6);
for goods in products:
print('%d\t'%i, goods[0], '\t', goods[1]);
i += 1;
# 商品购买的循环
buy_goods = [];
while True:
tmp = input('请输入商品标号,或者是输入q退出\n');
if tmp == 'q':
print('退出成功');
break;
elif tmp.isnumeric():
tmp = eval(tmp);
if tmp < 0 or tmp >= len(products):
print('数据输入错误,请重新输入');
continue;
else:
buy_goods.append(products[tmp]);
else:
print('数据输入错误,请重新输入');
continue;
# 打印购买的商品和总价
print('-'*6, ' 购买的商品为 ', '-'*6);
money = 0;
for goods in buy_goods:
print('%s\t%d'%(goods[0], goods[1]));
money += goods[1];
print('总价=%d'%money);
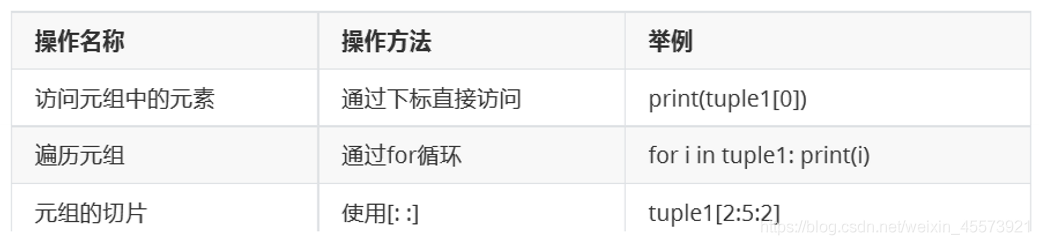
元组
- 元组与list类似,但是tuple的数据不可以被修改。元素写在小括号里面,元素之间用逗号分开。
- 元组的元素不可变,但是可以包括可变对象,eg:list,而且list内部是可以加的
- 定义只有一个元素的tuple,必须加逗号,因为不加逗号就看成是一个加括号的表达式
代码尝试:
my_tuple = ([1, 2, 3],);
for i in my_tuple: # 原本 tuple 元素的遍历输出
print(i);
my_tuple[0].append(2); # 添加的新元素
for i in my_tuple: # 原本 tuple 元素的遍历输出
print(i);
for i in my_tuple: # 标签指的是一个地方,是被删除的!!,相当于引用
i.pop();
for i in my_tuple:
print(i);
结果
[1, 2, 3]
[1, 2, 3, 2]
[1, 2, 3]
元组的定义和访问
- 创建一个空元祖
- 元组的定义
- 元组的访问
- 元组的元素值是不允许修改的,但是我们可以对元组进行连接组合形成一个新的元组。
- 将元组删除释放之后,再次访问会报错,是非法的。
# 创建空元祖
tuple1 = ();
# 创建仅仅一个元素的元组
tuple1 = (2, ); # 注意,元组指向内存单元的内容不可以改,但是变量作为便签是可以指向其他地方的
int1 = (2); # 这个不加逗号的不是元组,是一个整数表达式
# 元组的访问
tuple1 = ('Google', 'baidu', 2000, 2020);
tuple2 = (1, 2, 3, 4, 5, 6, ); # 这个后面的逗号是可加可不加的
print("tuple1[0]=%s"%tuple1[0]);
print("tuple1[2]=%d"%tuple1[2]);
print("tuple1[2]=%s"%tuple1[2]);
print('%s'%1); # 整数也是可以直接 %s 转换为 string 类型的
print(str(1));
print('tuple2[1~5]:', tuple2[1:5]);
# 假设元组某个元素是可变类型list,我们看看list是否可以正常修改 --> 是可以正常修改的
tup3 = ([0], );
print(type(tup3));
for x in tup3:
print(x);
x.extend([2, 3, 4, 5, 6]);
x.pop();
for y in tup3:
print(y);
# 尝试修改其他的
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# 下面的操作是非法的
# tup1[0] += 2;
# 我们可以进行元组的连接
tup3 = tup1 + tup2;
for i in tup3:
print(i);
# 我们释放一下tup1内存试一试
del tup1
print(tup3); # 这个是ok的,所以说tup3是新开的内存
print('-' * 6);
''' 都报错,说明还是别用了,释放之后,在为重新赋值之前就别用。
i = tup1;
print('1', type(i));
# print(tup1); # 什么都输出不了了,被释放了
'''
常用操作

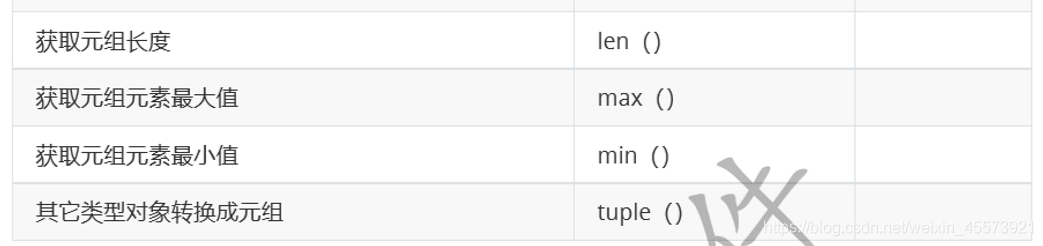
| 操作名称 | 操作方法 | 举例 |
|---|---|---|
| 元组的加法操作 | + | tup3 = tup1 + tup2 |
字典
- 字典是无序对象的集合,使用(key-value)存储,支持告诉查询
- 键(key)必须使用不可变数据类型
- 同一个字典中键必须是唯一的
# 字典的测试
d = {'Mich':99, 'aadf':25, 123:24, 25:[123, ]} #[123,]:10不行,但是10:[123, ]是可以的,即key不可变,val可变
print(d['Mich'])
print(d[123]) # 后面的会覆盖前面的
字典的定义与访问
- 字典的定义需要使用{}, 不同于元组,因为他的可区别性强,因此编译器在编译的时候不需要额外的加分号。
- 字典和列表类似,可以存储多种数据结构;
- 对比列表,列表元素的查找根据下标,字典查找元素是根据‘名字’。
- 字典的每个元素由两部分组成,\(key:value\)
- 当字典根据键访问数值时候,使用 \(dict[key]\)当元素不存在的时候会报错,但是当使用\(dict.get(key, default='')\),键值不存在时,会返回默认值空,或者是自己填。
下面是代码尝试
info = {'name':'小妖怪', 'age':21};
print(info['name']);
print(info['age']);
# print(info['sex']); # 不存在会报错
# 使用 get 成员函数
x = info.get('sex');
print(x);
print(type(x));
print(info.get('sex', '啥也没有'))
常用操作

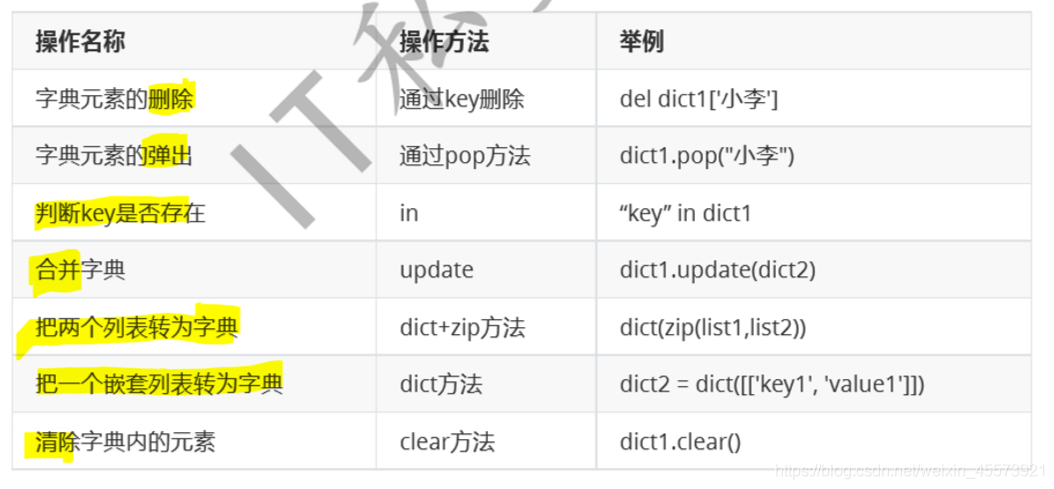
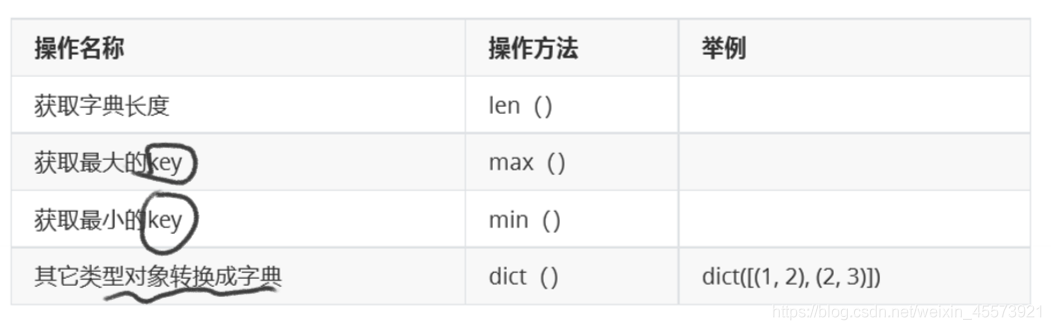
集合
- 想要定义的时候直接强制类型转化就行。
- set是无序的,任何重复元素都会被过滤掉。
- 相当于仅有key 的字典,数据不可以是可变类型list,但是可以为元组 tuple
- 相比较\(c ++\) 中的集合,他的数据类型是可变的。
set1 = set([1, 2, 3, 4, 4, 0, 1, 2]);
for i in set1:
print('%d '%i, end='');
set1.add('adf'); # 只能加一个
# set1.add(['adfa', 'dfa']) 应该是不能加可变类型list
set1.add(('adfa', 'dfa')) # 但是可以加元组 tuple
set1.update(set([5, 6, 7 , 8])); # 这个加的是一个集合
print('')
for i in set1:
print(i, end=' ');
常用操作
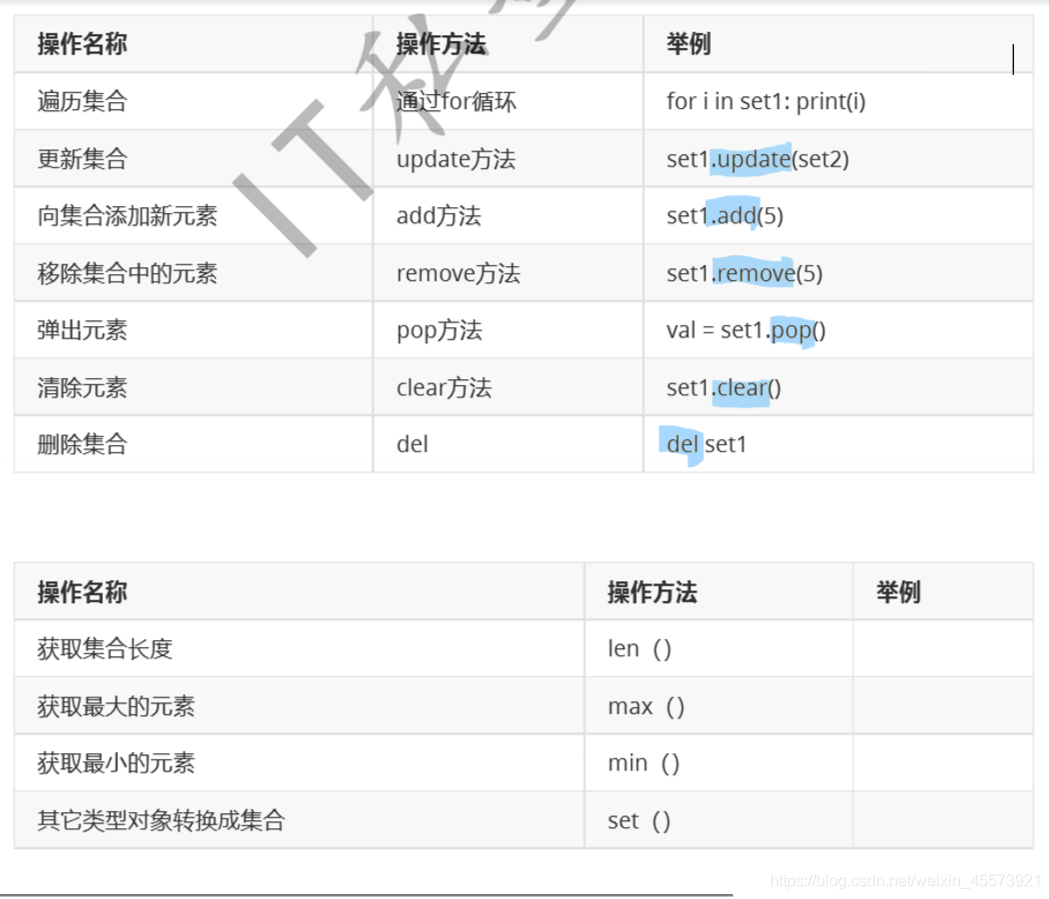
小结
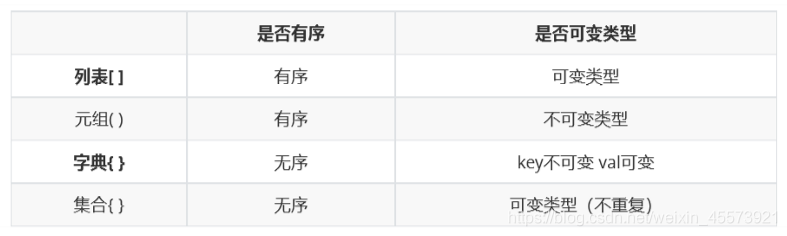
函数
函数的概念
- 为了提高编程的效率和代码的复用性,将常用的一段代码封装成一个模块,这个就是函数。
函数的定义和调用
def 函数名():
代码
demo:
def printInfo():
print('-' * 6);
print('python 永远滴神');
print('-' * 6);
if __name__ == '__main__':
printInfo()
cmd的执行结果
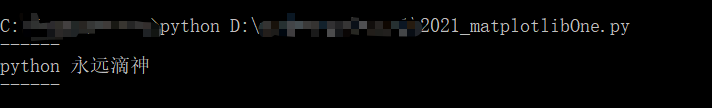
函数参数
demo代码如下
def mul(a, b):
print('%d*%d=%d'%(a, b, a * b));
return;
if __name__ == '__main__':
mul(5, 2);
函数的返回值
- python中的函数返回多个值(本质是元组,和c ++ 的vector, set, map类似)
def divide(a, b):
return a//b, a%b;
if __name__ == '__main__':
print(divide(100, 3));
x, y = divide(100, 3);
print('x=%d, y=%d'%(x, y))
运行结果:
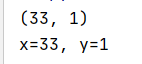
课堂练习

代码
# 打印一条线的函数,默认含有 6 个'-'
def print_One_Line(cnt = 6):
print('-' * cnt);
return;
# 默认打1行,1行6个
def print_Line(a = 1, b = 6):
for i in range(a):
print_One_Line(b);
return;
# 三个数字的和
def three_sum(a, b, c):
return a + b + c;
# 三个数字的平均数值
def three_ave(a, b, c):
return three_sum(a, b, c) / 3;
# 主函数起始点,调用自定义函数
if __name__ == '__main__':
print_One_Line();
print_Line(5);
print(three_sum(1, 2, 3));
print(three_ave(1, 2, 3));
print(type(three_ave(1, 2, 3)));
局部变量和全局变量
- 在函数外面定义的是全局变量
- 全局变量可以在定义的函数内部访问(无同名的局部变量的前提下),但是如果想要修改的话,就需要global声明一下,否则不需要,
- 再有全局变量 a 的情况下,倘若函数中出现 a,仅仅访问,那就是全局变量,倘若修改了,而且没有global声明,那么就是局部变量,想要修改必须使用关键字global声明一下。
- 如果是局部变量,需要提前赋值(声明,在使用之前),如果是全局变量要提前global说明
附示例代码:
# 局部变量修改
def local_var_func():
print('-' * 8)
a = 5 # 因为后面有赋值,所有说是局部变量,局部变量必须在前面就有赋值,要在用 a 之前
print('before : a = %d' % (a))
a = 200
print('after : a = %d' % (a))
print('-' * 8)
# 全局变量修改
def global_var_func():
print('-' * 8)
global a # 全局变量必须要提前说,否则有问题,在 用 a 之前
print('before : a = %d' % (a))
a = 300
print('after : a = %d' % (a))
print('-' * 8)
a = 100 # 全局变量
# 主要是开始位置
if __name__ == '__main__':
# global a 有了会报错,默认是这个 global
print('main a = %d'%a)
a = 1010
print('main a = %d' % a)
local_var_func()
print('after local : main a = %d' % a)
global_var_func()
print('after global : main a = %d' % a)
函数的注意事项
- 函数调用时候的传参顺序
- 局部变量,全局变量的预先声明
- 带默认值参数值的函数
- 注意作用域
文件操作
- 文件常有4类操作,分别是打开文件,读文件,写文件,关闭文件
文件的打开与关闭

# 打开文件
f = open('test1.txt', 'w'); # 打开方式可以有很多,如上整理所示
# 关闭文件
f.close()
文件的读写
使用write写数据
\(f.write('写入内容')\)
- 注意,当文件不存在时,会创建,文件存在时会清空原文件的内容,然后写入。
- 写入的什么内容就是什么内容,没有\n作为end默认结尾
demo:
# 打开文件
f = open('test1.txt', 'w+'); # 打开方式可以有很多
# 文件写入
f.write('this is write thing!!!!!') # 不会像 print 一样默认加 \n
# 关闭文件
f.close()
使用read读数据
- \(f.read(num)\),其中\(num\)是按照字节进行计数的,\(num\)默认长度等于当前所剩文件字节长度,即从当前指针位置到文件末尾都被读取。
- \(open('filename', 'readingway')\),读写方式默认是只读。
- 倘若多次读,读取的数据是上一次读的下一个位置。
- 函数的返回值类型是字符串
demo:
# 打开文件
f = open('test1.txt', 'r'); # 打开方式可以有很多
# 文件读取
context = f.read(5)
print(context)
context = f.read()
print(context)
# 关闭文件
f.close()
readlines读数据
- 没有参数,每次将文件全部读出,返回值是一个列表,列表的元素是一行
- 注意输出的时候, print end里面的\n 可以省去了
# 打开文件
f = open('test1.txt', 'r'); # 打开方式可以有很多
# 文件读取
context = f.readlines()
print(type(context))
print(context)
for i in context:
print(i, end='') # 注意我们的一行字符串已经包含 \n 了,输出的时候注意格式,可以把print 里面的\n给去掉
# 关闭文件
f.close()
结果展示
<class 'list'>
['123456789\n', 'abc\n', 'def\n', 'ghi']
123456789
abc
def
ghi
readline读数据
- 读出的是 str,而且注意他后面是有 '\n'的
# 打开文件
f = open('test1.txt', 'r'); # 打开方式可以有很多
# 文件读取
context = f.readline()
print(type(context))
i = 0
while context != '':
i += 1
print('i=%d:%s'%(i, context), end='') # 同理,end 不要 \n,要换成空串
context = f.readline()
if context == '':
break
# 关闭文件
f.close()
运行结果:
<class 'str'>
i=1:123456789
i=2:abc
i=3:def
i=4:ghi
linecache模块输出特定行
\(text=linecache.getline('filename', lineCnt)\)
import linecache
text = linecache.getline('test1.txt', 2)
print('-' * 6)
print(text, end='')
print('-' * 6)
运行结果:
------
abc
------
文件的相关操作
基本都是调用 \(OS\)模块中的部分函数完成
- 文件的重命名 \(os.rename(old\_name, new\_name)\)
- 文件的删除 \(os.remove(name)\)
- 创建文件夹 \(os.mkdir(name)\)
- 获取当前目录 \(os.getcwd()\)
- 改变默认目录 \(os.chdir(路径)\)'../'表示上一级
- 获取目录列表 \(os.listdir(路径)\), './'表示当前路径下的目录列表
- 删除文件夹 \(os.rmdir(文件夹名)\)
文件重命名
倘若不在当前路径下,需要给他加全
import os
os.rename('D:\\pythonTry\\test.txt', 'D:\\pythonTry\\test2.txt')
文件的删除
倘若不在当前路径下,需要给他加全
import os
os.remove('D:\\pythonTry\\test2.txt')
创建文件夹
倘若不在当前路径下,需要给他加全路径的位置
import os
os.mkdir('D:\\PythonTry\\test2') # 在 D:\pythonTry这里加一个名字为 test2的文件夹
获取当前目录(路径)
import os
print(os.getcwd())
获取目录列表
返回值是一个列表,内容是当前目录下的内容
import os
print(os.listdir("./"))
print(os.listdir("D:\\pythontry"))
结果输出:
['.idea', '2021_matplotlibOne.py', '2021_matplotlibTwo.py', 't1.png', 'test2.txt']
['lessonOne11_8', 'test1', 'test2', 'test2.txt']
改变默认目录
import os
print(os.getcwd()) # 查看当前路径
os.chdir('../') # 返回上一级
print(os.getcwd()) # 查看当前路径
os.chdir('D:\\PythonTry\\test1') # 返回特定路径
print(os.getcwd()) # 查看当前路径
结果显示
D:\PythonTry\test1
D:\PythonTry
D:\PythonTry\test1
删除文件夹
import os
os.rmdir('D:\\pythontry\\test2')
错误与异常
异常简介
- 当python检测到一个错误时,解释器就无法继续执行了,反而会出现错误的提示,这就是异常。
捕获异常 try ... except ...
经典的语法示例
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
下面我们以打开文件失败出现的 IOError示例
try:
f = open("D:\\pythontry\\123.txt", 'r');
context = f.readlines();
for u in context:
print(u, end='');
except IOError: # 当不存在该文件,或者是无法打开时
print('文件打不开')
下面介绍几种常见的Error
详细查看链接:https://www.cnblogs.com/smilelin/p/11451581.html
TypeError:类型错误,对象用来表示值的类型非预期类型时发生的错误
AttributeError:属性错误,特性引用和赋值失败时会引发属性错误
NameError:试图访问的变量名不存在。
SyntaxError:语法错误,代码形式错误
KeyError:在读取字典中的key和value时,如果key不存在,就会触发KeyError错误。
IndexError:索引错误,使用的索引不存在,常索引超出序列范围,序列中没有此索引(index)
IndentationError:缩进错误
TabError: Tab 和空格混用
except 捕获多个、所有异常,并获取异常的信息描述
参考资料和链接地址
- 大部分截图都是来自 IT私塾课件
- python常见报错类型参考于https://www.cnblogs.com/smilelin/p/11451581.html
- 动态语言、静态语言、强类型语言和弱类型语言参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号