索引
-
原理
索引在MySQL中也叫做“键”或者"key"(primary key,unique key,还有一个index key),是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要,减少io次数,加速查询。(其中primary key和unique key,除了有加速查询的效果之外,还有约束的效果,primary key 不为空且唯一,unique key 唯一,而index key只有加速查询的效果,没有约束效果)
强调:一旦为表创建了索引,以后的查询最好先查索引,再根据索引定位的结果去找数据
索引的影响
1、在表中有大量数据的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
'''
索引的作用主要是用来加速查询的效率,数据存储时,会根据聚集索引存储成一种数据结构,叫做B+树的数据结构(下图),数据都回存储在叶子节点上(图中最下面的一层),除了聚集索引还有普通话索引,普通索引存储的是索引字段这一列的数据和聚集索引(回表操作),存储数据的时候选择索引尽量选择字段数据较小的尾索引字段
'''
-
索引的数据结构
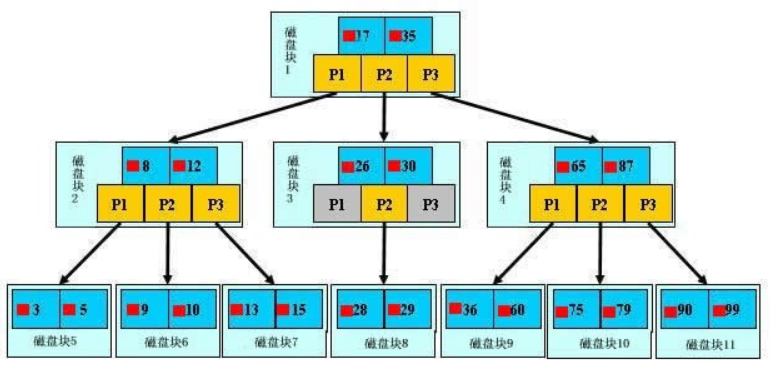
-
主键索引
#添加主键索引:
创建的时候添加: 添加索引的时候要注意,给字段里面数据大小比较小的字段添加,给字段里面的数据区分度高的字段添加(一般添加到id字段上).
聚集索引的添加方式
创建的时候添加
Create table t1(
id int primary key,
)#方式一
Create table t1(
id int,
primary key(id)
)#方式二
表创建完了之后添加
Alter table 表名 add primary key(id);#当数据量大的时候,效率会很慢
删除主键索引:
Alter table 表名 drop primary key;#当数据量大的时候,效率会很慢
-
普通索引
#普通索引:
'''
当查询的数据就是普通索引这一列的时候,普通索引也叫覆盖索引
'''
创建:
Create table t1(
Id int,
Index index_name(id)
)
Alter table s1 add index index_name(id);
Create index index_name on s1(id);
删除:
Alter table s1 drop index u_name;
DROP INDEX 索引名 ON 表名字;
-
联合索引
#联合索引(联合主键\联合唯一\联合普通索引)
Create table t1(
Id int,
name char(10),
Index index_name(id,name)
)
'''
联合索引在申明的时候,是申明几个字段作为索引,再查找的数据的时候,如果也要使用索引来提升查询速度,就要按照索引字段的顺序来查找,比如在查找一条数据的时候,联合索引的字段为name,age,那个在指定where条件的时候,一定更要使用到name字段,否则就无法使用这个索引,还有当使用联合索引的时候,多个字段中,如果出现范围查找的字段,那么在这个范围字段后面的字段再查找的时候联合索引也无法使用
'''
#explain可以查看查找数据时,扫描了多少条数据,数字越少速度越快
explain select * from student where name='田cai';
-
唯一索引
#唯一索引:
Create table t1(
int unique,
)
Create table t1(
id int,
unique key uni_name (id)
)'''unique key 后面是给这个索引取名字,这个名字可以写可以不写,不写的情况下一般以指定的索引字段名命名'''
表创建好之后添加唯一索引:
alter table s1 add unique key u_name(id);
删除:
Alter table s1 drop index u_name;
事务和锁
#行锁:
select * from 表名 where id=1 for update;#排他锁,上锁之后,其他用户对这个表的增删改查就回阻塞,等你操作完成之后,其他用户才能操作
SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE;#共享锁(其他用户可以查询,不能对数据进行增删改)
#表锁:
共享读锁:lock table tableName read;
独占写锁:lock table tableName write;
批量解锁:unlock tables;
#事务:
begin;或者 start transaction;#开启事务
commit;提交#提交事务
rollback;回滚#回滚事务
https://www.cnblogs.com/clschao/articles/10034539.html#_label4(博客链接)
'''
原子性(Atomicity):事务是一个原子操作单元。在当时原子是不可分割的最小元素,其对数据的修改,要么全部成功,要么全部都不成功。
一致性(Consistent):事务开始到结束的时间段内,数据都必须保持一致状态。
隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行。
持久性(Durable):事务完成后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。。'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号