

学习内存相关知识发现一大堆概念,谁能帮忙捋清楚!!
1 内存屏障
什么是单方向内存屏障什么是双方向内存屏障??
内存屏障指令的基本原则:
(1)所有内存屏障指令之前的数据访问必须在该指令之前完成。
(2)所有内存屏障指令之后的数据必须等待该指令之后执行。
(3)如果有多条内存屏障指令,它们是按照顺序执行的。

1.1 数据存储屏障DMB指令:
(1)仅仅影响数据访问的访问序列;(2)data cache指令也算数据访问;(3)保证在DMB之前的数据访问可以被DMB后面的数据访问指令观察到。
1.2 数据同步屏障DSB指令:
(1)DSB指令比DMB指令严格很多;(2)在DSB之后后面的任何指令,必须等到如下完成了才能开始执行:①在DSB指令前面的所有数据访问必须执行完成。②在DSB之前的cache、branch predictor、TLB等指令必须执行完成。
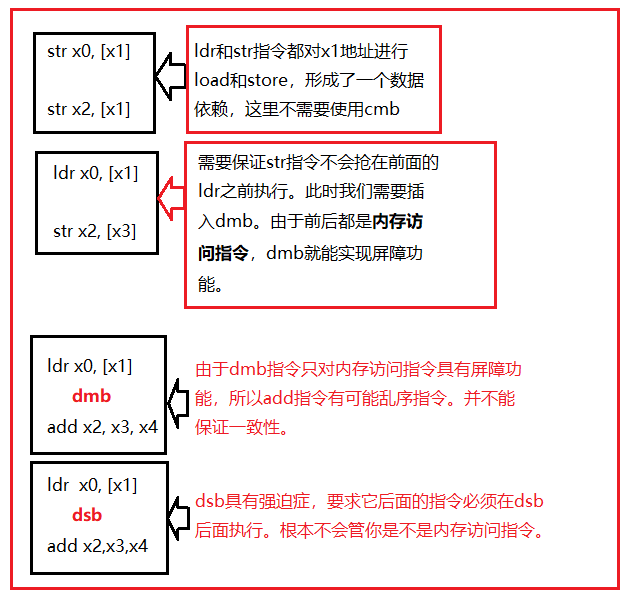

内存屏障分类:读内存屏障、写内存屏障、读写内存屏障。同时又根据作用域的不同分为:全系统共享域、内部共享域、不指定共享域、外部共享域。
读内存屏障指令load-load、load-store:相当于弱化了内存屏障指令。只拦截了读指令,不管其他指令。

写内存屏障指令stroe-store:只影响写操作,不影响加载操作
读写内存屏障指令: 读写都影响,也就是dmb本意。
1.3 内存屏障之间的关系
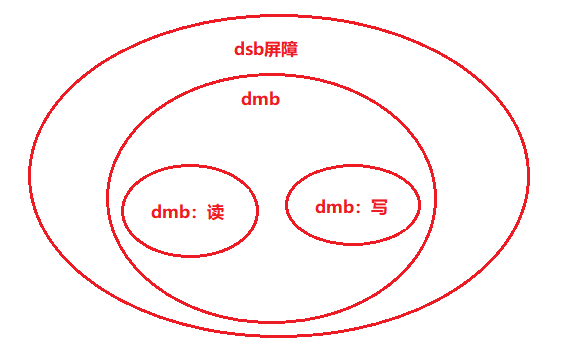
1.4结合armv8手册C3.2.7--单方向内存屏障原语解读
我们在前面讲的都是双方向内存屏障的指令。dmb dsb之类的都属于双方向内存屏障。armv8给我们提供单方向的内存屏障原子操作。
单方向内存屏障原语由分为:获取屏障原语acquire、释放屏障原语release、加载获取屏障原语load-acquire、存储释放原语store-release。
(1)acquire:该屏障原语之后的读写操作不能重排到该屏障原语之前,(就是限制了不能在后面的指令跳过acquire内存屏障)通常该屏障原语和加载指令结合使用。具体是哪些指令呢???
(2)release:同上,不能重排到release内存屏障原语之后。(前面的不能跳过到后面执行)
注释:上面(1)(2)就组成了完整的内存屏障dsb。
(3)load-acquire:含有获取原语的读操作,相当于单方向向后的屏障指令。所有该指令后面的内存访问(读写指令都算么?)只能在加载-获取内存屏障指令执行后才能开始执行,并且要被其他CPU观察到。
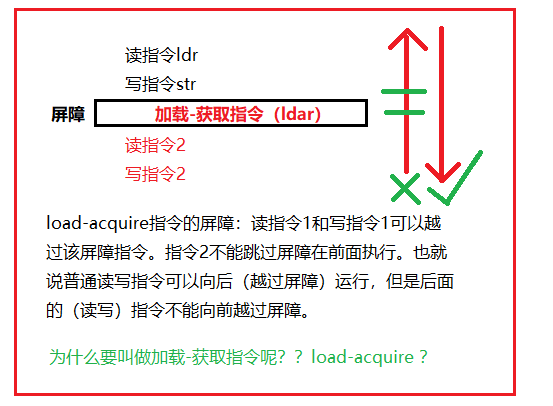
(4)store-release:
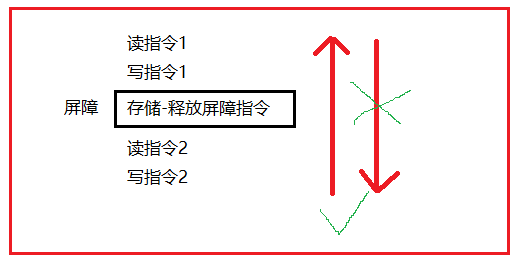
总结:

1.5 指令同步屏障ISB指令
ISB指令威力巨大,他会冲刷流水线,然后从指令cache或者内存中重新预取指令。
ISB指令保证:
①isb后面的指令都从cache或者内存中重新获取。为什么需要重新获取呢??
②isb指令之前的更改上下文的操作都已经完成,:包括cacahe,tlb和branch predictor等操作。改变系统的寄存器等。
2 内存序:C++引入的6中内存序如何理解?
它们的作用是对汇编上做重排干预和硬件上乱序执行干预和执行结果在多核的可见性的控制。
(1)为什么需要引入6种内存序
多核环境下多线程的并发访问是无法保证一致性的,需要软件层面的DF,std::Atomic默认就是SC(顺序一致性)的,但是这样可能会影响性能,因此标准库又额外提供了其他的memory order,以供用户在合适场景下选择并可以优化性能。但是要注意一点,memory order约束的是atomic附近的非atomic操作的行为,而不是atomic自身。std::memory_orders的引入使得用户可以在语言层面对多处理器环境下多线程共享的行为进行控制,忽略了编译器和cpu架构的影响。memory_order真正的实现机制是限制了内存操作指令之间的重排。
(2)顺序一致内存序和非顺序内存一致性
(3)6种内存序分类
虽然共有 6 个选项,但它们表示的是三种内存模型:
sequential consistent(memory_order_seq_cst),
relaxed(memory_order_relaxed).
acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel),
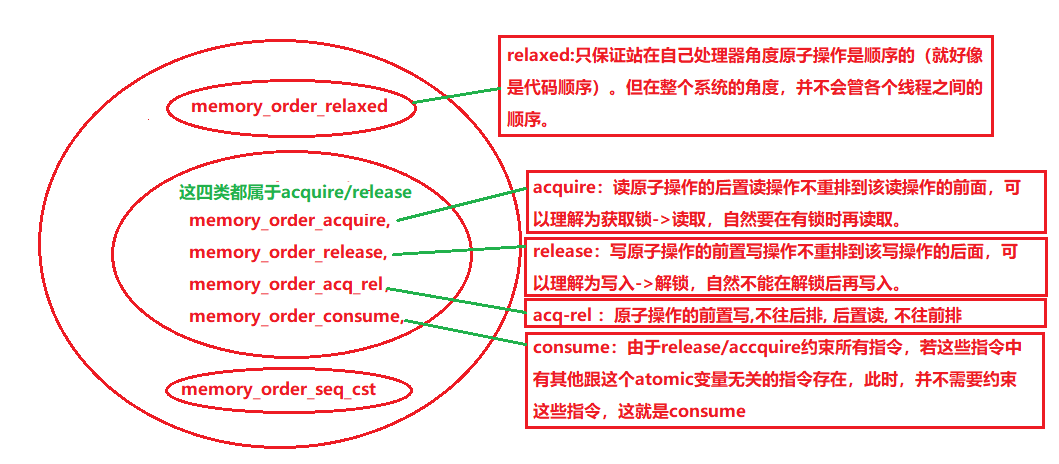
memory_order_relaxed:There are no synchronization or ordering constraints imposed on other reads or writes, only this operation’s atomicity is guaranteed。memory_order_relaxed实现最松散的一致性保证,只保证单线程的原子性,多线程之间的顺序是任意的,当然这个任意指的是在保证单线程原子性的前提下可以对指令进行任意重排。
注意:测试代码在x86上是跑不出来异常的,因为x86默认是release-acquire语义,换句话说x86上没有relax,所以对于主要在x86上开发的同学来说relax可以不用关注。
对memory_order_relaxed.:在原子变量上采用 relaxed ordering 的操作不参与 synchronized-with 关系。在同一线程内对同一变量的操作仍保持happens-before关系,但这与别的线程无关。 在 relaxed ordering 中唯一的要求是在同一线程中,对同一原子变量的访问不可以被重排。没有附加同步的情况下,“对每个变量的修改次序”(我的理解是对每个变量的写串行化)是唯一一件被多个线程共享的事。
memory_order_acquire:向前保证,本线程中所有读写操作都不能重排到memory_order_acquire的load之前。读原子操作的后置读操作不重排到该读操作的前面.读barrier生效, 也后置读也生效.
memory_order_release:写原子操作的前置写操作不重排到该写操作的后面. 写barrier生效, 则前置写也生效.
memory_order_acq_rel:原子操作的前置写,不往后排, 后置读, 不往前排。对应memory_order_acquire_release、对应memory_order_release, memory_order_acquire, memory_order_acq_rel。Acquire-release 中没有全序关系,但它供了一些同步方法。在这种序列模型下,原子 load 操作是 acquire 操作(memory_order_acquire), 原子 store 操作是 release操作(memory_order_release), 原子read_modify_write操作(如fetch_add(), exchange())可以是 acquire, release 或两者皆是(memory_order_acq_rel). 同步是成对出现的,它出现在一个进行 release 操作和一个进行 acquire 操作的线程间。 一个 release 操作 syncrhonized-with 一个想要读取刚才被写的值的 acquire 操作。这意味着不同线程仍然看到了不一样的次序,但这次序是被限制过了的。
memory_order_consume: memory_order_consume 是 acquire-release 顺序模型中的一种,但它比较特殊,它为 inter-thread happens-before 引入了数据依赖关系:dependency-ordered-before 和 carries-a-dependency-to.
如同 sequenced-before, carries-a-dependency-to 严格应用于单个进程,建立了 操作间的数据依赖模型:如果操作 A 的结果被操作 B 作为操作数,那么 A carries-a-dependency-to B. 这种关系具有传递性。
dependency-ordered-before 可以应用于线程与线程之间。这种关系通过一个 原子的被标记为 memory_order_consume 的 load 操作引入。这是 memory_order_acquire 内存序的特例:它将同步数据限定为具有直接依赖的数据。 一个被标记为 memory_order_release, memory_order_acq_rel 或 memory_order_seq_cst 的原子 store 操作 A dependency-ordered-before 一个被标记为 memory_order_consume 的欲读取刚被改写的值的原子 load 操作 B. 同时,如果 A dependency-order-before B, 那么 A inter-thread happens-before B.
如果一个 store 操作被标记为 memory_order_release, memory_order_acq_rel 或 memory_order_seq_cst, 一个 load 操作被标记为 memory_order_cunsume, memory_order_acquire 或 memory_order_seq_sct, 一连串 load 中的每个操作,读取的都是之前操作写下的值([3] Listing 5.11 举例说明了这一点),那么这一连串操作将构成 release sequence, 最初的 store 操作 synchronized-with 或 dependency-ordered-before 最后的 load.
不过[3]没有给出任何使用memory_order_consume的代码示例。
memory_order_seq_cst: 顺序一致次序。原子操作的前置读写, 不往后排, 后置读写, 不往前排.
SC作为默认的内存序,是因为它意味着将程序看做是一个简单的序列。如果对于一个原子变量的操作都是顺序一致的,那么多线程程序的行为就像是这些操作都以一种特定顺序被单线程程序执行。从同步的角度来看,一个顺序一致的 store 操作 synchroniezd-with 一个顺序一致的需要读取相同的变量的 load 操作。除此以外,顺序模型还保证了在 load 之后执行的顺序一致原子操作都得表现得在 store 之后完成。
内存模型与c++中的memory order - woder - 博客园 (cnblogs.com)
(4)案例分析
①写顺序保护:release

②读顺序保护:aquire

③读顺序削弱:consume
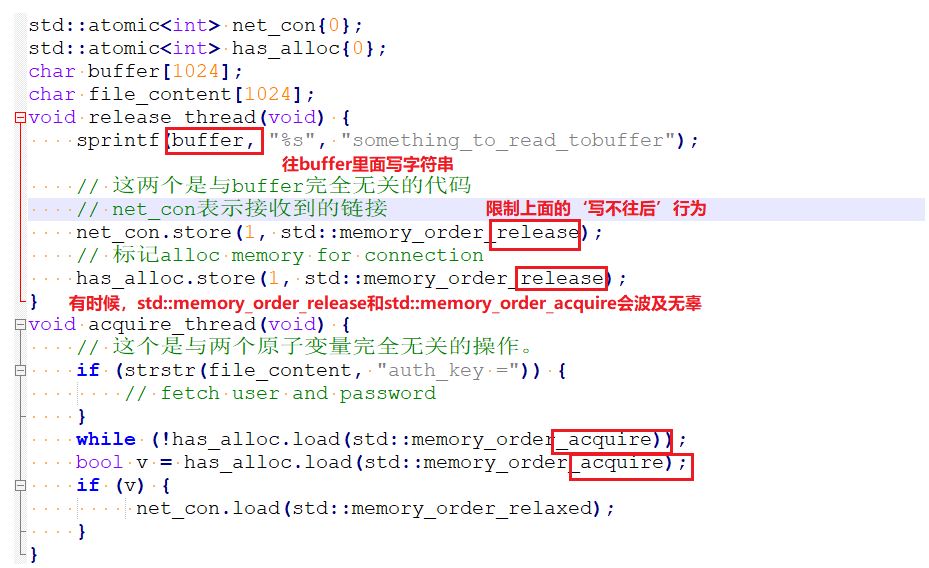

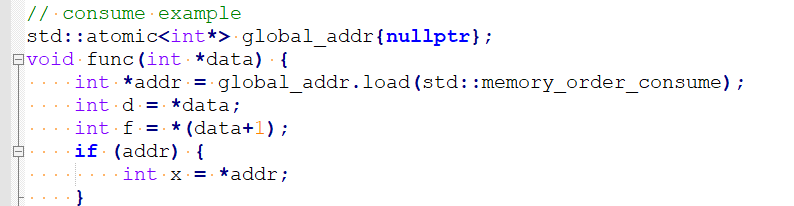
由于global_addr, addr, x形成了读依赖,那么这时候,这几个变量是不能乱序的。但是d,f是可以放到int *addr = global_addr.load(std::memory_order_consume);前面的。
而std::memory_order_acquire则要求d,f都不能放到int *addr = global_addr.load(std::memory_order_consume);的前面。这就是acquire与consume的区别。
④读写加强:acq_rel
有时候,可能还需要对读写的顺序进行加强。想一下std::memory_order_release要求的是写不后,也就是后面对内存的写都不能放到本条写语句之后。 但是,有时候可能需要解决这种情况。假设我们需要响应一个硬件上的中断。硬件上的中断需要进行如下步骤。
a.读寄存器地址1,取出数据checksum
b.写寄存器地址2,表示对中断进行响应
c.写flag,标记中断处理完成
由于读寄存器地址1与写flag,标记中断处理完成这两者之间的关系是读写关系。 并不能被std::memory_order_releaes约束。所以需要更强的约束来处理。这里可以使用std::memory_order_acq_rel,即对本条语句的读写进行约束。即表示写不后,读不前同时生效。 那么就可以保证a, b, c三个操作不会乱序。即std::memory_order_acq_rel可以同时表示写不后 && 读不前。
⑤最强约束:seq_cst
std::memory_order_seq_cst表示最强约束。所有关于std::atomic的使用,如果不带函数。比如x.store or x.load,而是std::atomic a; a = 1这样,那么就是强一制性的。即在这条语句的时候 所有这条指令前面的语句不能放到后面,所有这条语句后面的语句不能放到前面来执行。
3 缓存一致性
4 MESI
5 保序性
6 原子操作
7 内存一致性模型:强一致和弱一致内存模型区别是什么?
内存模型:SC(完全一致性),TSO(完全存储一致性),PSO(部分存储一致性),RMO(完全宽松)又该怎么理解??
(1)原子一致性内存模型(也叫做严格一致性模型):指通过一个全局时间比例部件来决定储存器的访问顺序。也就是说完全按照代码的顺序执行,每个代码有一个固定的时间点,后面的代码不可能在前面执行。这总做法的代价非常大,效率特别低。
(2)顺序一致性内存模型(又称SC):采用每个处理器的局部时间比例部件来确定最新的数据的内存模型。也就说单处理器的时候,存储的访问方式执行方式就是按照代码顺序。但是在多处理器中,所有的内存访问都是原子的,其执行顺序不必严格按照时间的顺序。是否能理解为先到先得?然后顾名思义也叫顺序一致性。每个处理器按照顺序依次访问。先到先访问?
(3)处理器一致性内存模型:是顺序一致性内存访问模型的进一步弱化,放宽了“”“读-写”操作要求。没理解??
(4)弱一致性内存模型:对处理器一致性内存模型的进一步弱化。程序员通过内存屏障的同步指令来实现内存访问。例如,
