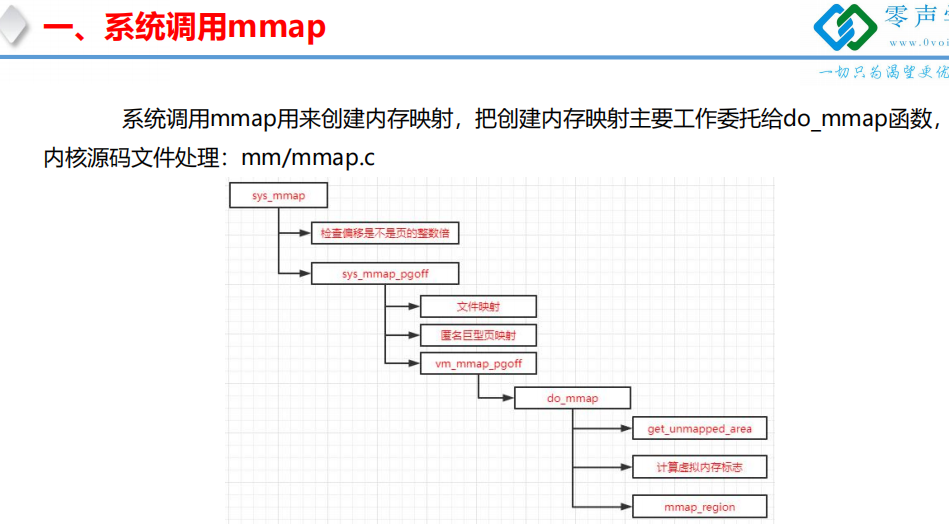
一、系统调用sys_mmap
(24条消息) 内存管理源码分析-mmap函数在内核的运行机制以及源码分析_HuberyPan的博客-CSDN博客_sys_mmap
void *mmap(void * addr, size_t length, int port, int flag, int fd, off_t offset);
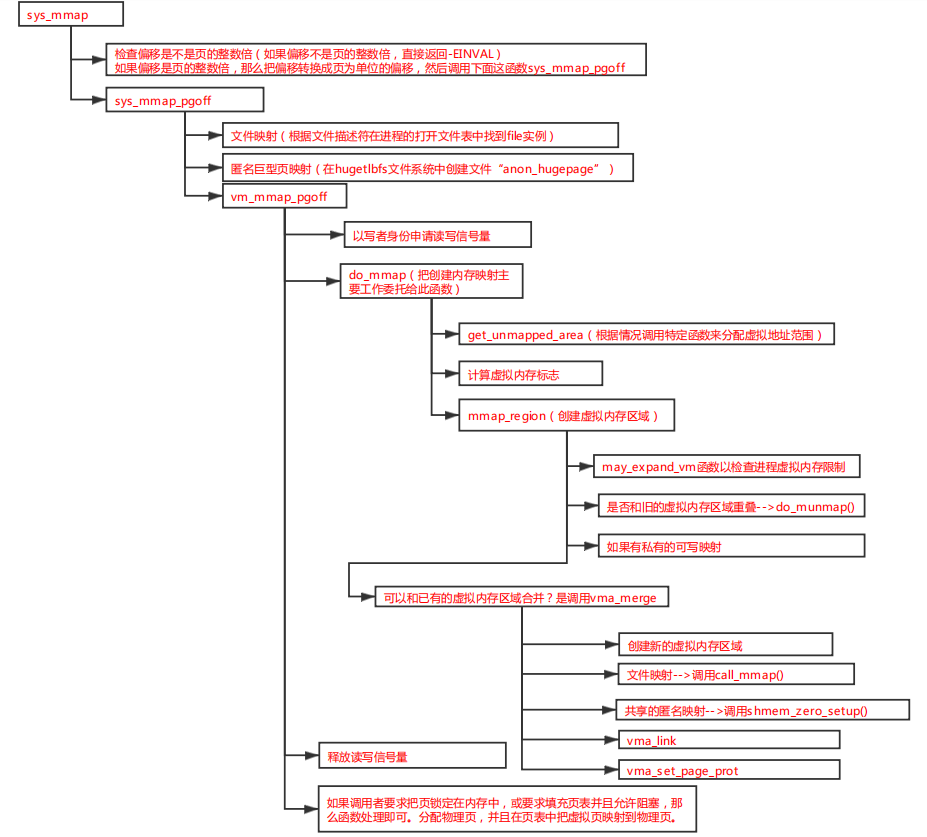
mmap--->sys_mmap-->sys_mmap_pgoff---> vm_mmap_pgoff---> do_mmap
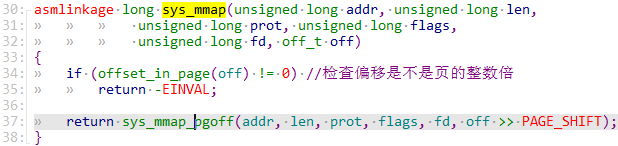
offset_in_page函数检查是否是页的整数倍,如果参数不是的话就直接出错返回。
// 注意off >> PAGE_SHIFT表达式,用于计算offset位于第几个页,32位的虚拟地址偏移12位即可得到当前页。
unsigned long sys_mmap_pgoff(unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, unsigned long fd, unsigned long pgoff) { struct file *file = NULL; unsigned long retval = -EBADF; if (!(flags & MAP_ANONYMOUS)) { // 如果不是匿名映射,则表示是基于文件的映射 file = fget(fd); // 文件映射先根据fd获取都文件对应的file结构 retval = -EINVAL; } flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE); retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff); out_fput: if (file) fput(file); //释放对file的引用 out: return retval; }
unsigned long vm_mmap_pgoff(struct file *file, unsigned long addr, unsigned long len, unsigned long prot, unsigned long flag, unsigned long pgoff) { unsigned long ret; struct mm_struct *mm = current->mm; // 获取当前进程的虚拟地址空间的管理结构 unsigned long populate; // 对应MAP_POPULATE参数,表示是否提前建立好页表 LIST_HEAD(uf);
ret = security_mmap_file(file, prot, flag); // 这个函数与安全相关,这里不作分析,默认返回true if (!ret) { down_write(&mm->mmap_sem); ret = do_mmap_pgoff(file, addr, len, prot, flag, pgoff, &populate, &uf); // 这个函数处理完毕之后,返回populate变量的值 up_write(&mm->mmap_sem); if (populate) mm_populate(ret, populate); // 根据populate参数的值,是否进行建立页表等操作 } return ret; }
static inline unsigned long
do_mmap_pgoff(struct file *file, unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags,unsigned long pgoff, unsigned long *populate, struct list_h ead *uf)
{
return do_mmap(file, addr, len, prot, flags, 0, pgoff, populate, uf);
}
这个函数首先处理的映射程度的页对齐,然后通过get_unmapped_area函数获取了一段未使用的内存,然后根据映射类型([文件,匿名] x [私有,共享])进行了对应的flag参数设置,接下来通过mmap_region函数完成映射过程,最后再判断一下是否要进行提前页表建立(populate=prefetch)。
unsigned long do_mmap(struct file *file, unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, unsigned long pgoff, unsigned long *populate,struct list_head *uf)) { struct mm_struct *mm = current->mm; vm_flags_t vm_flags; *populate = 0; // 初始化为不进行预先页表建立 len = PAGE_ALIGN(len); // len原来是字节的长度,这里转换为页长度,即将申请映射长度进行页对齐 addr = get_unmapped_area(file, addr, len, pgoff, flags); // 获取一段当前进程未被使用的虚拟地址空间,并返回其起始地址 if (addr & ~PAGE_MASK) // 如果地址不是是页对齐,addr值可能是错误值(大概类似-EINVAL这种?),然后将错误结果返回给用户了 return addr; vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
// 以上是检查flag的参数设置,将mmap的flag转换为vm_area_struct的flag if (flags & MAP_LOCKED) // 如果设置了MAP_LOCKED参数 if (!can_do_mlock()) // 检查一下内存可用空间等信息,看看是否可以进行mlock return -EPERM; if (mlock_future_check(mm, vm_flags, len)) // 继续检查是否可以进行mlock return -EAGAIN; if (file) { // 如果file不为NULL,则表示是基于文件的映射,如果是NULL则是匿名映射 struct inode *inode = file_inode(file); // 根据file获取inode结构 switch (flags & MAP_TYPE) { // 根据是私有映射还是共享映射进行不同的处理 case MAP_SHARED: // 共享映射 if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE)) return -EACCES; if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE)) // 判断是否为APPEND-ONLY文件,mmap不允许写入这种类型文件 return -EACCES; if (locks_verify_locked(file)) return -EAGAIN; // 更新一系列的使用于vm_area_struct的flag vm_flags |= VM_SHARED | VM_MAYSHARE; if (!(file->f_mode & FMODE_WRITE)) vm_flags &= ~(VM_MAYWRITE | VM_SHARED); case MAP_PRIVATE: // 私有映射,也是设置flag if (!(file->f_mode & FMODE_READ)) // 如果文件本身不允许读,那么就直接返回 return -EACCES; if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) { if (vm_flags & VM_EXEC) return -EPERM; vm_flags &= ~VM_MAYEXEC; } if (!file->f_op->mmap) return -ENODEV; if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP)) return -EINVAL; break; default: return -EINVAL; } } else { // 匿名映射,也是设置flag switch (flags & MAP_TYPE) { case MAP_SHARED: if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP)) return -EINVAL; pgoff = 0; // 共享匿名映射忽略pgoff vm_flags |= VM_SHARED | VM_MAYSHARE; break; case MAP_PRIVATE: pgoff = addr >> PAGE_SHIFT; // 匿名私有映射使用分配出来的addr作为pgoff break; default: return -EINVAL; } } addr = mmap_region(file, addr, len, vm_flags, pgoff); if (!IS_ERR_VALUE(addr) && ((vm_flags & VM_LOCKED) || (flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE)) *populate = len; // 根据返回的结果,以及MAP_POPULATE的参数,决定了进行页表建立的长度 return addr; }
mmap_region函数完成最后的映射过程,即将用户需要映射的虚拟地址范围建立起来,然后再将其加入当前进程的mm_struct结构中。
根据源码我们可以知道,该函数根据用户需要分配的地址空间的信息,或扩展当前的进程的虚拟地址空间范围,或创建一个新的vma结构加入到进程的mm_struct当中,这样当前进程就有了可以直接访问的mmap分配的内存区域。这样就完成了整个mmap的映射过程,但实质上只是分配了vma结构去进程的虚拟地址空间当中,访问的时候会触发page-fault缺页异常,才会给这些刚刚分配的虚拟地址空间的vma结构建立虚拟地址和物理地址的映射关系。
unsigned long mmap_region(struct file *file, unsigned long addr, unsigned long len, vm_flags_t vm_flags, unsigned long pgoff) { struct mm_struct *mm = current->mm; // 获取当前进程的mm_struct结构 struct vm_area_struct *vma, *prev; int error; struct rb_node **rb_link, *rb_parent; unsigned long charged = 0; if (!may_expand_vm(mm, len >> PAGE_SHIFT)) { // 检查需要的申请的长度是否超过的限制 unsigned long nr_pages; if (!(vm_flags & MAP_FIXED)) return -ENOMEM; nr_pages = count_vma_pages_range(mm, addr, addr + len); if (!may_expand_vm(mm, (len >> PAGE_SHIFT) - nr_pages)) return -ENOMEM; } /* Clear old maps */ error = -ENOMEM;
.......
.......
....... munmap_back: // 用find_vma_links函数寻找当前进程的虚拟地址空间所管理的内存块(vma)是否与目前预备分配的内存块的地址有相交的关系,如果有先将其unmap if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) { if (do_munmap(mm, addr, len)) return -ENOMEM; goto munmap_back; } if (accountable_mapping(file, vm_flags)) { charged = len >> PAGE_SHIFT; if (security_vm_enough_memory_mm(mm, charged)) return -ENOMEM; vm_flags |= VM_ACCOUNT; } // 当前申请的虚拟地址空间是否可以当前进程的虚拟地址空间进行合并,如果可以合并,直接修改当前进程的vma的vm_start和vm_end的值 vma = vma_merge(mm, prev, addr, addr + len, vm_flags, NULL, file, pgoff, NULL); if (vma) goto out; // 如果无法合并,根据用户申请的地址空间范围,分配一个新的vma结构 vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL); if (!vma) { error = -ENOMEM; goto unacct_error; } // 初始化vma的信息 vma->vm_mm = mm; vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_flags = vm_flags; vma->vm_page_prot = vm_get_page_prot(vm_flags); vma->vm_pgoff = pgoff; INIT_LIST_HEAD(&vma->anon_vma_chain); if (file) { // 如果是文件映射 if (vm_flags & VM_DENYWRITE) { // 文件不允许写入 error = deny_write_access(file); if (error) goto free_vma; } if (vm_flags & VM_SHARED) { // 内存是共享的,能被其他进程访问 error = mapping_map_writable(file->f_mapping); // 增加mapping共享vma的统计数目,如果非共享的情况下,mapping的共享vma统计数目是-1 if (error) goto allow_write_and_free_vma; } vma->vm_file = get_file(file); // 增加file的引用计数,然后赋给vma->vm_file error = file->f_op->mmap(file, vma); // 调用文件系统的mmap函数作处理,文件系统会根据设计设定各自的mmap函数,同时还是设定fault函数去处理page fault的情况 if (error) goto unmap_and_free_vma; // 执行文件系统自身的mmap函数之后,重新赋值 addr = vma->vm_start; vm_flags = vma->vm_flags; } else if (vm_flags & VM_SHARED) { // 如果是匿名共享映射 error = shmem_zero_setup(vma); // 将映射的文件指向/dev/zero设备文件,基于这个设备文件创建共享内存映射,并利用system V的一套共享内存机制 if (error) goto free_vma; } vma_link(mm, vma, prev, rb_link, rb_parent); // 将新的vma结构加入到当前进程管理的虚拟地址空间的结构(mm_struct)的list当中 if (file) { if (vm_flags & VM_SHARED) mapping_unmap_writable(file->f_mapping); if (vm_flags & VM_DENYWRITE) allow_write_access(file); } file = vma->vm_file; out: perf_event_mmap(vma); vm_stat_account(mm, vm_flags, file, len >> PAGE_SHIFT); // 更新当前的虚拟地址空间的使用统计信息 if (vm_flags & VM_LOCKED) { if (!((vm_flags & VM_SPECIAL) || is_vm_hugetlb_page(vma) || vma == get_gate_vma(current->mm))) mm->locked_vm += (len >> PAGE_SHIFT); else vma->vm_flags &= ~VM_LOCKED; } if (file) uprobe_mmap(vma); vma->vm_flags |= VM_SOFTDIRTY; vma_set_page_prot(vma); return addr; }
二、系统调用sys_munmap
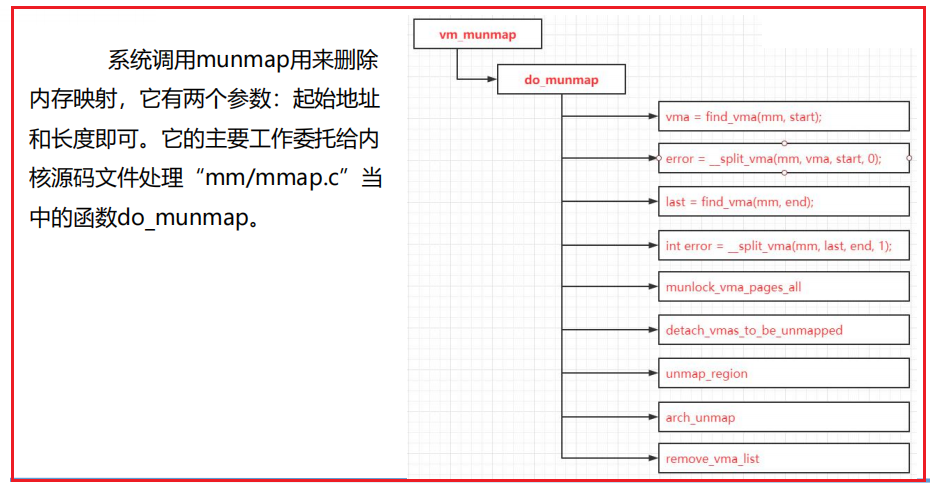
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len, struct list_head *uf) { unsigned long end; struct vm_area_struct *vma, *prev, *last; if ((offset_in_page(start)) || start > TASK_SIZE || len > TASK_SIZE-start) return -EINVAL; len = PAGE_ALIGN(len); if (len == 0) return -EINVAL; /*1 通过起始地址查找需要删除的vma Find the first overlapping VMA */ vma = find_vma(mm, start); if (!vma) return 0; prev = vma->vm_prev; /* we have start < vma->vm_end */ /* if it doesn't overlap, we have nothing.. */ end = start + len; if (vma->vm_start >= end) return 0; if (uf) { int error = userfaultfd_unmap_prep(vma, start, end, uf); if (error) return error; } /* * If we need to split any vma, do it now to save pain later. * * Note: mremap's move_vma VM_ACCOUNT handling assumes a partially * unmapped vm_area_struct will remain in use: so lower split_vma * places tmp vma above, and higher split_vma places tmp vma below. */ if (start > vma->vm_start) { int error; /* * Make sure that map_count on return from munmap() will * not exceed its limit; but let map_count go just above * its limit temporarily, to help free resources as expected. */ if (end < vma->vm_end && mm->map_count >= sysctl_max_map_count) return -ENOMEM; //2、如果只删除虚拟内存区域vma的start部分,那么分裂虚拟内存区域vma error = __split_vma(mm, vma, start, 0); if (error) return error; prev = vma; } /* Does it split the last one? */ //3、根据结束地址找到要删除的最后一个虚拟内存区域vma last = find_vma(mm, end); if (last && end > last->vm_start) { //4、如果只删除虚拟内存区域last的一部分,那么分裂虚拟内存区域vma int error = __split_vma(mm, last, end, 1); if (error) return error; } vma = prev ? prev->vm_next : mm->mmap; /* * unlock any mlock()ed ranges before detaching vmas */ if (mm->locked_vm) { struct vm_area_struct *tmp = vma; while (tmp && tmp->vm_start < end) { if (tmp->vm_flags & VM_LOCKED) { mm->locked_vm -= vma_pages(tmp); //5、针对删除的所有目标,如果询内存区域被锁定在内存中(不允许换出到交换区), //调用函数解除锁定. munlock_vma_pages_all(tmp); } tmp = tmp->vm_next; } } /* * Remove the vma's, and unmap the actual pages *6、调用次函数把所有目标从进程虚拟内存区域链表和树中删除,单独组成临时链表 */ detach_vmas_to_be_unmapped(mm, vma, prev, end);
//7、针对所有删除目标,在进程的页表中删除映射,并从处理器页表缓存中删除映射 unmap_region(mm, vma, prev, start, end); //8、执行处理器特定的处理操作 arch_unmap(mm, vma, start, end); /*9、删除所有目标 Fix up all other VM information */ remove_vma_list(mm, vma); return 0; }
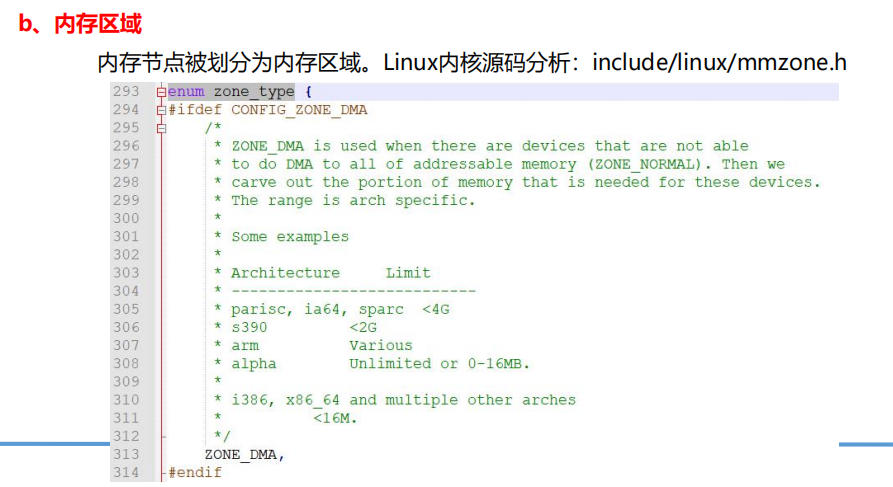
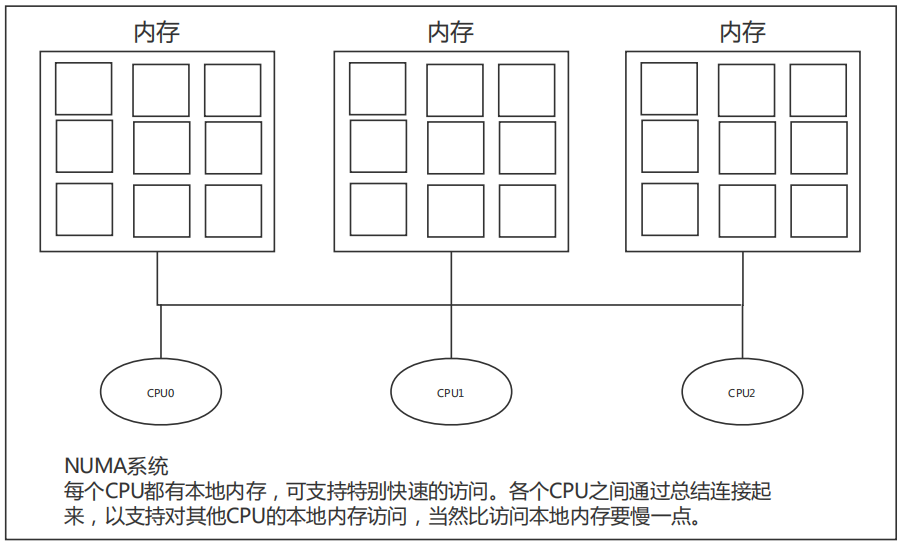
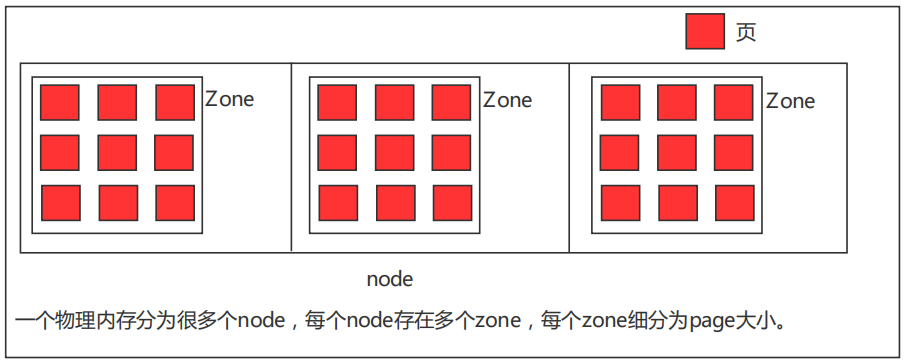
三、物理内存组织结构

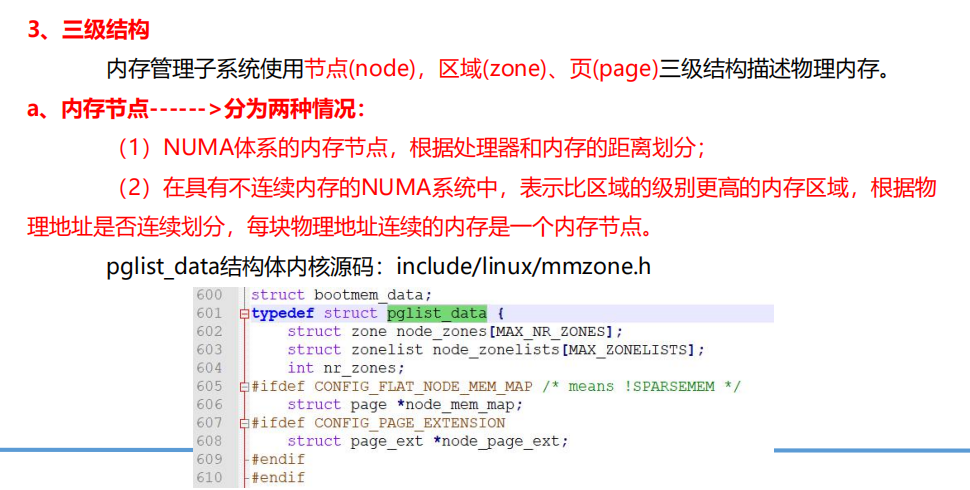
用来描述节点的结构体
typedef struct pglist_data { //该节点所在管理区为ZONE_HIGHMEM ZONE_NORMAL ZONE_DMA 包含了结点中各内存域的数据结构 struct zone node_zones[MAX_NR_ZONES]; /*备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存*/ struct zonelist node_zonelists[MAX_ZONELISTS]; /*表示该节点管理区的数目,1-3之间,并不是所有的节点都有三个管理区*/ int nr_zones; #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ struct page *node_mem_map; #ifdef CONFIG_PAGE_EXTENSION struct page_ext *node_page_ext; #endif #endif #ifndef CONFIG_NO_BOOTMEM struct bootmem_data *bdata;//引导内存bootmem分配器 #endif #ifdef CONFIG_MEMORY_HOTPLUG /* * Must be held any time you expect node_start_pfn, node_present_pages * or node_spanned_pages stay constant. Holding this will also * guarantee that any pfn_valid() stays that way. * * pgdat_resize_lock() and pgdat_resize_unlock() are provided to * manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG. * * Nests above zone->lock and zone->span_seqlock */ spinlock_t node_size_lock; #endif unsigned long node_start_pfn; unsigned long node_present_pages; /* total number of physical pages */ unsigned long node_spanned_pages; /* total size of physical page range, including holes */ int node_id; wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait; struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */ int kswapd_order; enum zone_type kswapd_classzone_idx; int kswapd_failures; /* Number of 'reclaimed == 0' runs */ #ifdef CONFIG_COMPACTION int kcompactd_max_order; enum zone_type kcompactd_classzone_idx; wait_queue_head_t kcompactd_wait; struct task_struct *kcompactd; #endif #ifdef CONFIG_NUMA_BALANCING /* Lock serializing the migrate rate limiting window */ spinlock_t numabalancing_migrate_lock; /* Rate limiting time interval */ unsigned long numabalancing_migrate_next_window; /* Number of pages migrated during the rate limiting time interval */ unsigned long numabalancing_migrate_nr_pages; #endif /* * This is a per-node reserve of pages that are not available * to userspace allocations. */ unsigned long totalreserve_pages; #ifdef CONFIG_NUMA /* * zone reclaim becomes active if more unmapped pages exist. */ unsigned long min_unmapped_pages; unsigned long min_slab_pages; #endif /* CONFIG_NUMA */ /* Write-intensive fields used by page reclaim */ ZONE_PADDING(_pad1_) spinlock_t lru_lock; #ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * If memory initialisation on large machines is deferred then this * is the first PFN that needs to be initialised. */ unsigned long first_deferred_pfn; unsigned long static_init_size; #endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */ #ifdef CONFIG_TRANSPARENT_HUGEPAGE spinlock_t split_queue_lock; struct list_head split_queue; unsigned long split_queue_len; #endif /* Fields commonly accessed by the page reclaim scanner */ struct lruvec lruvec; /* * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on * this node's LRU. Maintained by the pageout code. */ unsigned int inactive_ratio; unsigned long flags; ZONE_PADDING(_pad2_) /* Per-node vmstats */ struct per_cpu_nodestat __percpu *per_cpu_nodestats; atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS]; } pg_data_t;