

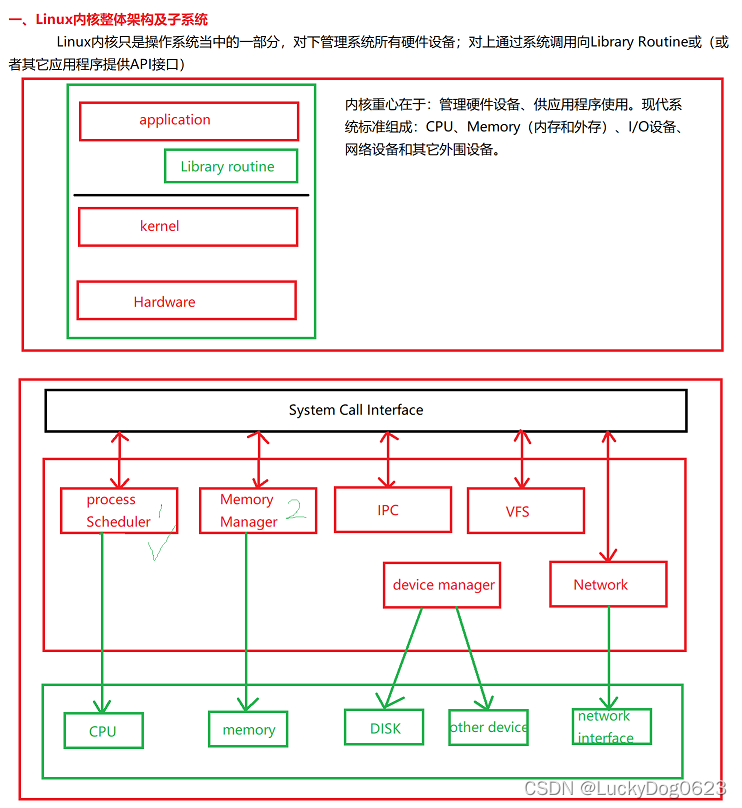
一、内存管理架构
内存管理子系统架构包括:用户空间、内核空间和硬件部分。
![]()
![]()
1、用户空间
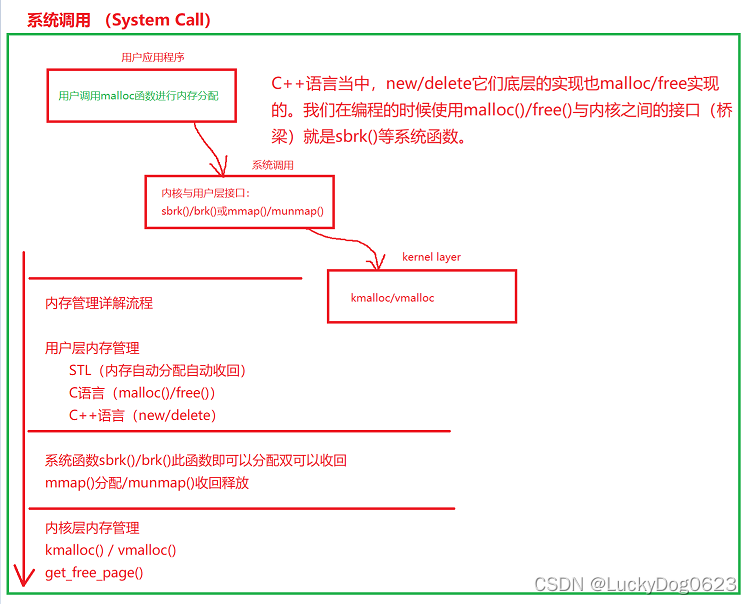
应用程序使用malloc()函数申请内存资源、通过free()函数释放内存资源;malloc/free是glibc库的内存分配器ptmalloc提供的接口。ptmalloc使用系统调用brk或者mmap向内核申请内存(一页为单位),然后进行分成很小的内存块分配给对应的应用程序。
2、内核空间
虚拟内存管理负责从进程的虚拟地址分配虚拟页。sys_brk来扩大或者压缩堆,sys_mmap用来在内存映射区域分配虚拟页,munmap用来释放虚拟页,页分配器(伙伴分配器)负责分配物理页。
内核空间拓展功能,不连续页分配器提供分配内存的接口vmalloc/vfree。在内存碎片化的时候,申请连续物理页的成功率很低,可以申请不连续的物理页,然后映射成连续的虚拟页。
内存控制组用来控制进程占用的内存资源。当内存碎片的时候,找不到连续的物理页,内存碎片整理通过迁移的方式得到连续的物理页。在内存不足的时候,页回收负责回收物理页。
3、硬件
MMU包含一个页表缓存(tlb),保存最近使用过的页表映射,避免每次把虚拟地址转换物理地址都需要查内存中的页表。解决处理器执行速度和内存速度不匹配的问题,中间增加一个缓存。一级缓存分为数据缓存和指令缓存,二级缓存作用是协调一级缓存和内存之间的工作效率。
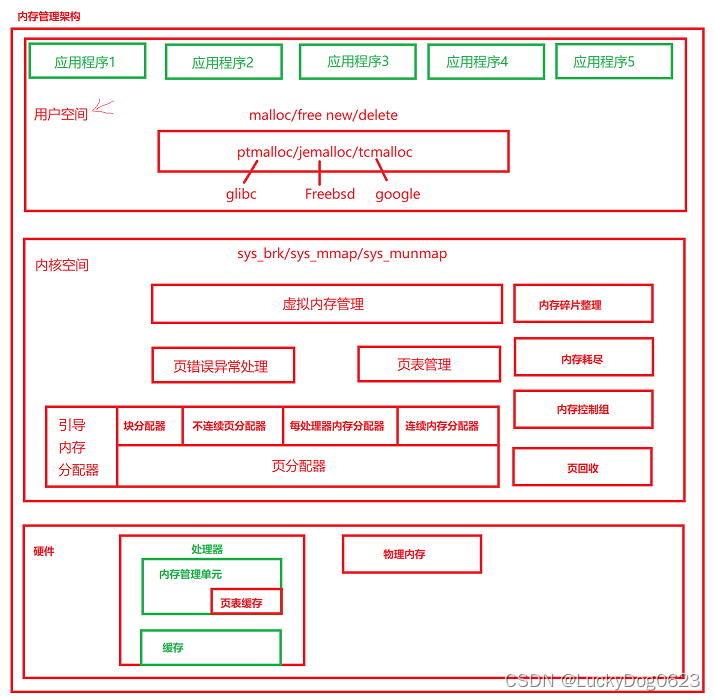
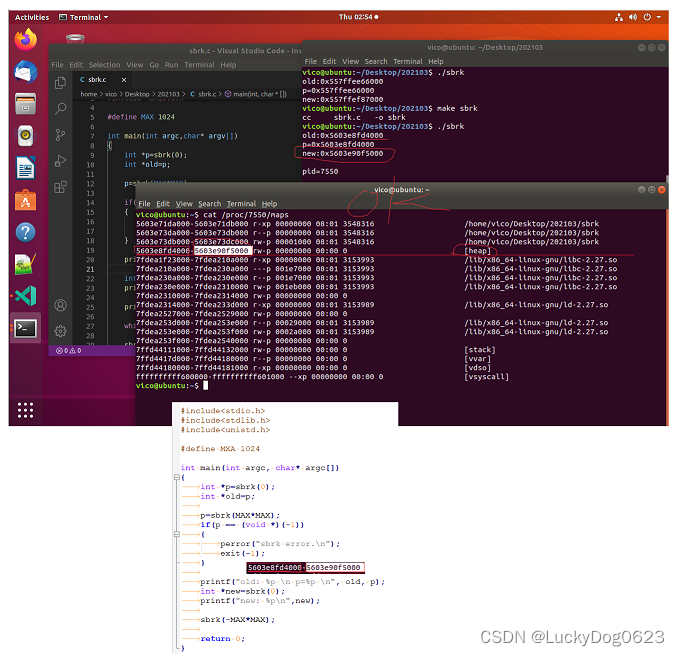
4、直接通过系统调用,内存分配实例分析:---sbrk和brk函数既可以分配,页可以回收,取决于函数参数

#include<stdio.h> #include<stdlib.h> #include<unistd.h> #define MXA 1024 int main(int argc, char* argc[]) { int *p=sbrk(0); //这里是啥意思?void *sbrk(intptr_t increment); int *old=p; p=sbrk(MAX*MAX); //分配内存 if(p == (void *)(-1)) { perror("sbrk error.\n"); exit(-1); } printf("old: %p \n p=%p \n", old, p); int *new=sbrk(0); printf("new: %p\n",new); sbrk(-MAX*MAX); 回收内存 return 0; }
![]()
5、问题
堆的大小90f5000 - 8fd4000 = 0x00121000 并不等于p=sbrk(MAX*MAX);
1024*1024=0x00100000 ??
6、如何查看系统中进程的内存情况?
cat /proc/进程号/maps

1、用户虚拟地址的划分
进程的用户虚拟空间的起始地址是0, 长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。ARM64架构定义的宏如下:
D:\linux-4.1.2\Linux-4.12\arch\arm64\include\asm\memory.h
32位用户空间程序:TASK_SIZE == TASK_SIZE_32 == 0x100000000等于4GB
64位用户空间程序:TASK_SIZE == TASK_SIZE_64,即2^VA_BITS字节。一般情况是编译的时候配置VA_BITS的值。

aston@ubuntu$ grep -rn --colour 'CONFIG_ARM64_VA_BITS' . --include=* ./arch/arm64/configs/defconfig:74:CONFIG_ARM64_VA_BITS_48=y
aston@$ grep -rnw --colour 'CONFIG_ARM64_VA_BITS' . --include=* CONFIG_ARM64_VA_BITS在编译的时候配置
./arch/arm64/include/asm/memory.h:66:#define VA_BITS (CONFIG_ARM64_VA_BITS)
./arch/arm64/Makefile:90: (0xffffffff & (-1 << ($(CONFIG_ARM64_VA_BITS) - 32))) \
./arch/arm64/Makefile:91: + (1 << ($(CONFIG_ARM64_VA_BITS) - 32 - 3)) \
aston@ubuntu:/mnt/hgfs/share/025-linux-4.12/Linux-4.12$

![]()
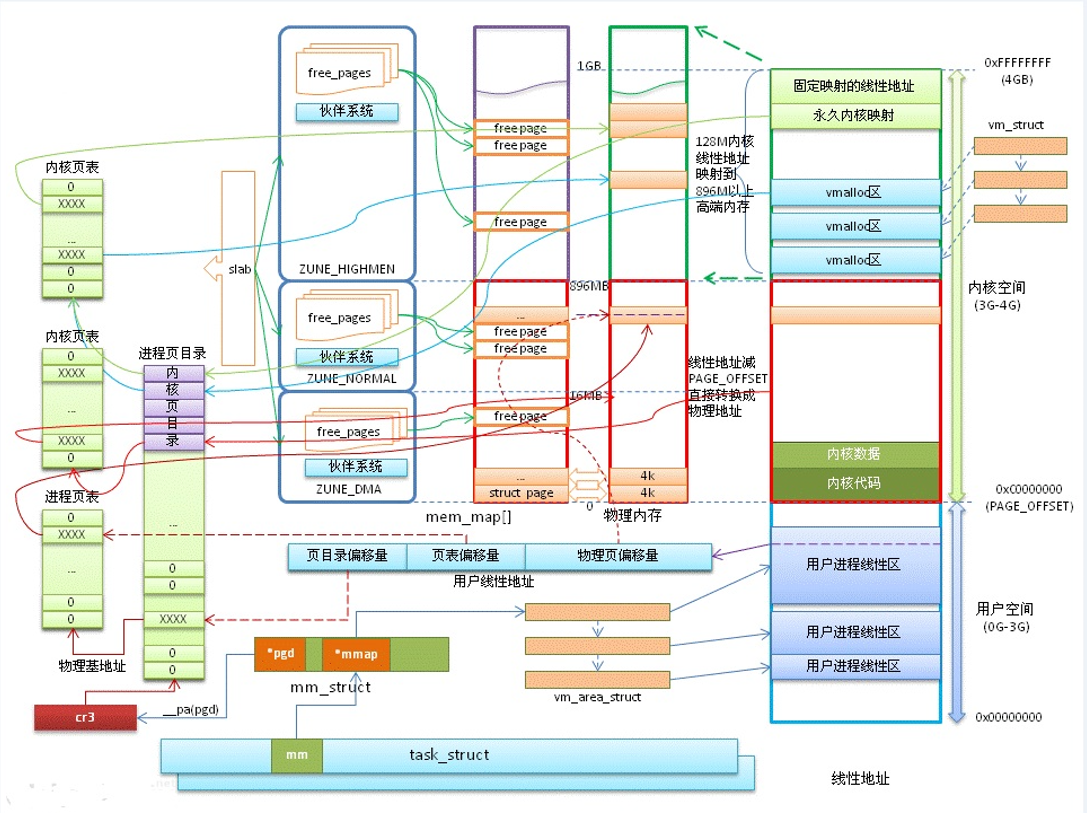
关于内核空间的内存分布情况:注意高端内存的使用

一下也是关于整个32位arm架构的内存布局架构:
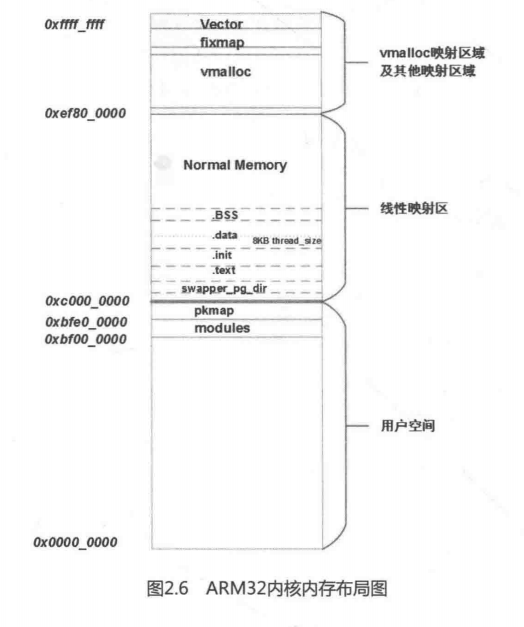
-
直接映射区:线性空间中从 3G 开始最大 896M 的区间,为直接内存映射区
-
动态内存映射区:该区域由内核函数 vmalloc 来分配
-
永久内存映射区:该区域可访问高端内存
-
固定映射区:该区域和 4G 的顶端只有 4k 的隔离带,其每个地址项都服务于特定的用途,如:ACPI_BASE 等
64位arm处理器内核内存布局分布情况:

![]()

![]()
struct mm_struct { struct vm_area_struct *mmap;/* 虚拟内存区域链表,每个进程都有list of VMAs */ struct rb_root mm_rb;//虚拟内存区域的红黑树 u32 vmacache_seqnum;/* per-thread vmacache */ #ifdef CONFIG_MMU //在内存映射区域找到一个没有映射的区域 unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags); #endif unsigned long mmap_base;/*内存映射区域的起始地址 base of mmap area */ unsigned long mmap_legacy_base;/* base of mmap area in bottom-up allocations */ #ifdef CONFIG_HAVE_ARCH_COMPAT_MMAP_BASES /* Base adresses for compatible mmap() */ unsigned long mmap_compat_base; unsigned long mmap_compat_legacy_base; #endif unsigned long task_size;/*用户虚拟地址空间的长度 size of task vm space */ unsigned long highest_vm_end; /* highest vma end address */ pgd_t * pgd;//指向页全局目录,也就是一级页表 /** * @mm_users: The number of users including userspace. * * Use mmget()/mmget_not_zero()/mmput() to modify. When this drops * to 0 (i.e. when the task exits and there are no other temporary * reference holders), we also release a reference on @mm_count * (which may then free the &struct mm_struct if @mm_count also * drops to 0). */ atomic_t mm_users;//共享一个用户虚拟地址空间的线程的数量,也就是线程组包含的线程的数量 /** * @mm_count: The number of references to &struct mm_struct * (@mm_users count as 1). * * Use mmgrab()/mmdrop() to modify. When this drops to 0, the * &struct mm_struct is freed. */ atomic_t mm_count;//内存描述符的引用计数 atomic_long_t nr_ptes; /* PTE page table pages */ #if CONFIG_PGTABLE_LEVELS > 2 atomic_long_t nr_pmds; /* PMD page table pages */ #endif int map_count; /* number of VMAs */ spinlock_t page_table_lock; /* Protects page tables and some counters */ struct rw_semaphore mmap_sem; struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock */ unsigned long hiwater_rss; /* 进程所拥有的最大页框数 High-watermark of RSS usage */ unsigned long hiwater_vm; /* 进程线性区中最大页数 High-water virtual memory usage */ unsigned long total_vm; /* 进程地址空间的大小 Total pages mapped */ unsigned long locked_vm; /* 锁住而不能换出的页的个数 Pages that have PG_mlocked set */ unsigned long pinned_vm; /* Refcount permanently increased */ unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */ unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */ unsigned long stack_vm; /* VM_STACK */ unsigned long def_flags; /*代码段的起始地址和结束地址 数据段的起始和结束地址*/ unsigned long start_code, end_code, start_data, end_data; /*堆的起始地址和结束地址,栈的起始地址*/ unsigned long start_brk, brk, start_stack; /*参数字符串的起始地址和结束地址,环境变量的起始地址和结束地址*/ unsigned long arg_start, arg_end, env_start, env_end; /**/ unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */ /* * Special counters, in some configurations protected by the * page_table_lock, in other configurations by being atomic. */ struct mm_rss_stat rss_stat; struct linux_binfmt *binfmt; cpumask_var_t cpu_vm_mask_var; /* 处理器的特定内存管理上下文 Architecture-specific MM context */ mm_context_t context; unsigned long flags; /* Must use atomic bitops to access the bits */ struct core_state *core_state; /* coredumping support */ #ifdef CONFIG_AIO spinlock_t ioctx_lock; struct kioctx_table __rcu *ioctx_table; #endif #ifdef CONFIG_MEMCG /* * "owner" points to a task that is regarded as the canonical * user/owner of this mm. All of the following must be true in * order for it to be changed: * * current == mm->owner * current->mm != mm * new_owner->mm == mm * new_owner->alloc_lock is held */ struct task_struct __rcu *owner; #endif struct user_namespace *user_ns; /* store ref to file /proc/<pid>/exe symlink points to */ struct file __rcu *exe_file; #ifdef CONFIG_MMU_NOTIFIER struct mmu_notifier_mm *mmu_notifier_mm; #endif #if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS pgtable_t pmd_huge_pte; /* protected by page_table_lock */ #endif #ifdef CONFIG_CPUMASK_OFFSTACK struct cpumask cpumask_allocation; #endif #ifdef CONFIG_NUMA_BALANCING /* * numa_next_scan is the next time that the PTEs will be marked * pte_numa. NUMA hinting faults will gather statistics and migrate * pages to new nodes if necessary. */ unsigned long numa_next_scan; /* Restart point for scanning and setting pte_numa */ unsigned long numa_scan_offset; /* numa_scan_seq prevents two threads setting pte_numa */ int numa_scan_seq; #endif #if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION) /* * An operation with batched TLB flushing is going on. Anything that * can move process memory needs to flush the TLB when moving a * PROT_NONE or PROT_NUMA mapped page. */ bool tlb_flush_pending; #endif struct uprobes_state uprobes_state; #ifdef CONFIG_HUGETLB_PAGE atomic_long_t hugetlb_usage; #endif struct work_struct async_put_work; };

![]()

![]()

![]()

![]()

![]()

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话