End-to-End Object Detection with Transformers
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

European conference on computer vision, 2020
Abstract. 我们提出了一种新的方法,将目标检测视为一个直接集合预测问题。我们的方法简化了检测流程,有效地消除了对许多手工设计的组件的需求,如非最大值抑制程序或锚生成,这些组件明确地对我们关于任务的先验知识进行编码。新框架的主要组成部分,称为DEtection TRansformer或DETR,是一种基于集合的全局损失,通过二分匹配强制进行唯一预测,以及一种Transformer编码器-解码器架构。给定一组固定的学到目标查询,DETR对目标和全局图像上下文的关系进行推理,以直接并行输出最后一组预测。与许多其他现代探测器不同,新模型概念简单,不需要专门的库。DETR在具有挑战性的COCO目标检测数据集上展示了与完善且高度优化的Faster R-CNN基线相当的准确性和运行时性能。此外,DETR可以很容易地泛化,以统一的方式产生全景分割。我们证明,它显著优于竞争基线。训练代码和预训练模型可在https://github.com/facebookresearch/detr上获得。
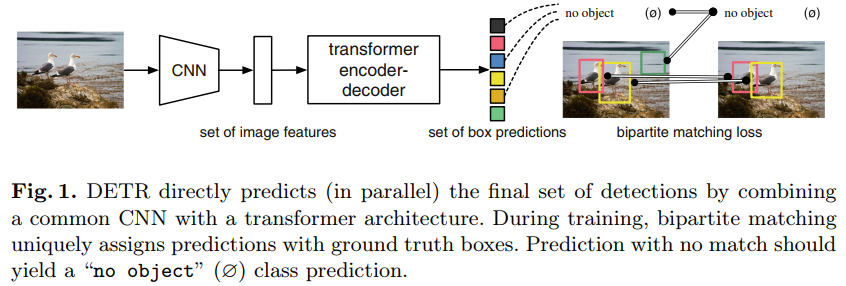
1 Introduction
目标检测的目标是为每个感兴趣的目标预测一组边界框和类别标签。现代检测器通过在一大组提议(proposal)[5,36]、锚[22]或窗口中心[45,52]上定义代理回归和分类问题,以间接的方式解决这一集合预测任务。它们的性能受到后处理步骤、锚集的设计以及将目标框分配给锚的启发式方法的显著影响[51]。为了简化这些流水线,我们提出了一种直接集预测方法来绕过代理任务。这种端到端的理念在复杂的结构化预测任务(如机器翻译或语音识别)方面取得了重大进展,但在目标检测方面尚未取得重大进展:之前的尝试[4,15,38,42]要么添加了其他形式的先验知识,要么在具有挑战性的基准上与强大的基线相比没有竞争力。本文旨在弥合这一差距。
我们通过将目标检测视为直接集合预测问题来简化训练流水线。我们采用了一种基于Transformer [46]的编码器-解码器架构,这是一种用于序列预测的流行架构。Transformer的自注意力机制明确地对序列中元素之间的所有成对相互作用进行建模,使这些架构特别适合于集合预测的特定约束,例如去除重复预测。
我们的DEDetection TRansformer (DETR,见图1)一次预测所有目标,并使用集合损失函数进行端到端训练,该集合损失函数在预测目标和真实目标之间执行二分匹配。DETR通过丢弃对先验知识进行编码的多个手工设计的组件(如空间锚或非最大抑制)来简化检测流水线。与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在任何包含标准ResNet [14]和Transformer [46]类的框架中轻松复制。
与以前关于直接集合预测的大多数工作相比,DETR的主要特征是二分匹配损失和Transformer与(非自回归)并行解码的结合[7,9,11,28]。相比之下,先前的工作侧重于RNN的自回归解码[29,35,40-42]。我们的匹配损失函数唯一地将预测分配给真正事实目标,并且对预测目标的排列是不变的,因此我们可以并行发射它们。
我们在最流行的目标检测数据集之一COCO [23]上评估了DETR,并与竞争激烈的更快R-CNN基线[36]进行了比较。更快的RCNN经历了多次设计迭代,自最初发布以来,其性能得到了极大的提高。我们的实验表明,我们的新模型达到了可比的性能。更准确地说,DETR在大型目标上表现出明显更好的性能,这一结果可能是由Transformer的非局部计算实现的。然而,它在小目标上的性能较低。我们预计,未来的工作将以FPN [21]的开发为Faster R-CNN所做的相同方式改进这一方面。
DETR的训练设置在多个方面与标准目标探测器不同。新模型需要超长的训练时间表,并且受益于Transformer中的辅助解码损失。我们将深入探讨哪些组件对演示的性能至关重要。
DETR的设计理念很容易扩展到更复杂的任务中。在我们的实验中,我们表明,在预训练的DETR之上训练的简单分割头在全景分割[18]上优于竞争性基线,这是一项具有挑战性的像素级识别任务,最近越来越受欢迎。
2 Related Work
我们的工作建立在几个领域的先前工作的基础上:用于集合预测的二分匹配损失、基于Transformer的编码器-解码器架构、并行解码和目标检测方法。
2.1 Set Prediction
没有规范的深度学习模型可以直接预测集合。基本的集合预测任务是多标签分类(例如,参见[32,39]以获取计算机视觉背景下的参考文献),其中基线方法,一对一,不适用于诸如元素之间存在底层结构(即,接近相同的框)的检测等问题。这些任务的第一个困难是避免接近重复。大多数当前的检测器使用后处理(如非最大抑制)来解决这个问题,但直接集合预测是免后处理的。它们需要全局推理方案来对所有预测元素之间的交互进行建模,以避免冗余。对于恒定大小的集合预测,密集全连接网络[8]是足够的,但代价高昂。一种通用的方法是使用自回归序列模型,如循环神经网络[47]。在所有情况下,损失函数都应通过预测的排列保持不变。通常的解决方案是基于匈牙利算法[19]设计损失,以找到真正事实和预测之间的二部匹配。这增强了排列不变性,并保证每个目标元素具有唯一匹配。我们遵循二部匹配损失方法。然而,与大多数先前的工作相反,我们远离自回归模型,使用具有并行解码的Transformer,我们将在下面进行描述。
2.2 Transformers and Parallel Decoding
2.3 Object Detection
3 The DETR Model
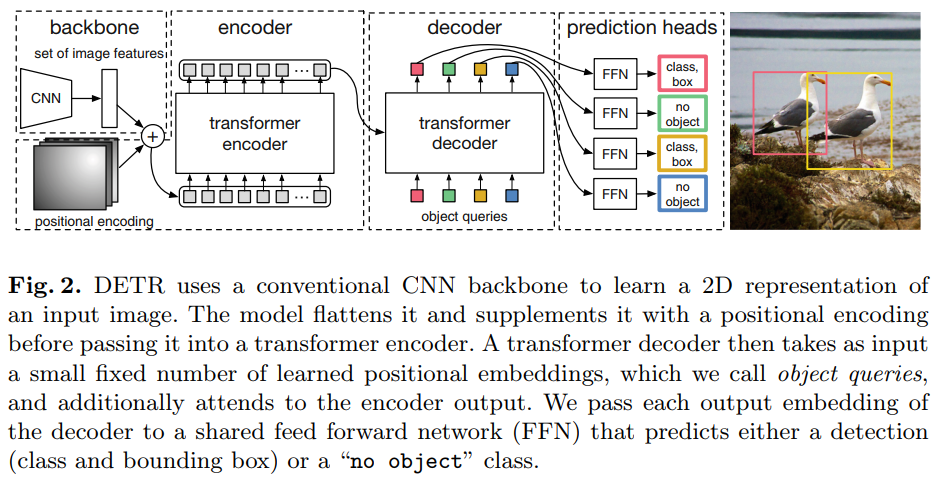
两个因素对于检测中的直接集合预测至关重要:(1) 集合预测损失,它迫使预测框和真正事实框之间进行唯一匹配;(2) 一种结构,它(在一次传播中)预测一组目标并对它们的关系进行建模。我们在图2中详细描述了我们的结构。
3.1 Object Detection Set Prediction Loss
DETR在通过解码器的单次传播中推断出固定大小的N个预测集合,其中N被设置为显著大于图像中目标的典型数量。训练的主要困难之一是根据真正事实对预测目标(类别、位置、大小)进行评分。我们的损失在预测目标和真正事实目标之间产生最优二部匹配,然后优化特定目标(边界框)的损失。
令我们用y表示目标的真正事实集,并且![]() 表示N个预测的集合。假设N大于图像中目标的数量,我们也将y视为一组用∅填充(无目标)的大小为N的集合。为了找到这两个集合之间的二部匹配,我们搜索具有最低成本的N个元素
表示N个预测的集合。假设N大于图像中目标的数量,我们也将y视为一组用∅填充(无目标)的大小为N的集合。为了找到这两个集合之间的二部匹配,我们搜索具有最低成本的N个元素![]() 的置换:
的置换:
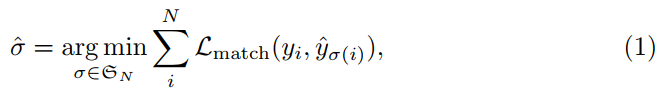
其中,![]() 是真正事实yi和具有指数σ(i)的预测之间的成对匹配成本。在先前的工作(例如[42])之后,使用匈牙利算法有效地计算了该最优分配。
是真正事实yi和具有指数σ(i)的预测之间的成对匹配成本。在先前的工作(例如[42])之后,使用匈牙利算法有效地计算了该最优分配。
匹配成本同时考虑了类预测以及预测框和真正事实框的相似性。真正事实集的每个元素 i 可以看作yi = (ci, bi),其中ci是目标类标签(可以是∅),bi ∈ [0, 1]4是定义真正事实框中心坐标及其相对于图像大小的高度和宽度的向量。对于具有指数σ(i)的预测,我们将类ci的概率定义为![]() 。利用这些符号,我们将
。利用这些符号,我们将![]() 定义为
定义为![]() 。
。
这种寻找匹配的过程与现代检测器中用于将提议[36]或锚[21]匹配到真正事实目标的启发式分配规则起着相同的作用。主要的区别在于,我们需要找到一对一匹配来进行无重复的直接集合预测。
第二步是计算损失函数,即前一步中匹配的所有配对的匈牙利损失。我们定义的损失类似于常见目标检测器的损失,即类预测的负对数似然和稍后定义的框损失![]() 的线性组合:
的线性组合:
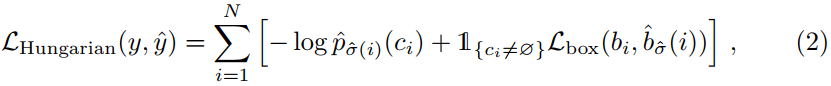
其中,![]() 是在第一步骤(1)中计算的最优分配。在实践中,当ci = ∅时,我们将对数概率项的权重降低10倍,以说明类别不平衡。这类似于更快的R-CNN训练程序如何通过二次采样来平衡正/负提议[36]。请注意,目标和∅之间的匹配成本不取决于预测,这意味着在这种情况下,成本是一个常数。在匹配成本中,我们使用概率
是在第一步骤(1)中计算的最优分配。在实践中,当ci = ∅时,我们将对数概率项的权重降低10倍,以说明类别不平衡。这类似于更快的R-CNN训练程序如何通过二次采样来平衡正/负提议[36]。请注意,目标和∅之间的匹配成本不取决于预测,这意味着在这种情况下,成本是一个常数。在匹配成本中,我们使用概率![]() 而不是对数概率。这使得类预测项与
而不是对数概率。这使得类预测项与![]() 可以同单位度量,并且我们观察到更好的经验性能。
可以同单位度量,并且我们观察到更好的经验性能。
边界框损失。匹配成本和匈牙利损失的第二部分是对边界框进行评分的![]() 。与许多将框预测作为相对于一些初步猜测的Δ的检测器不同,我们直接进行框预测。虽然这种方法简化了实现,但它带来了损失的相对缩放问题。最常用的l1损失对于小框和大框将具有不同的尺度,即使它们的相对误差相似。为了缓解这个问题,我们使用了l1损失和广义IoU (GIoU)损失[37]
。与许多将框预测作为相对于一些初步猜测的Δ的检测器不同,我们直接进行框预测。虽然这种方法简化了实现,但它带来了损失的相对缩放问题。最常用的l1损失对于小框和大框将具有不同的尺度,即使它们的相对误差相似。为了缓解这个问题,我们使用了l1损失和广义IoU (GIoU)损失[37]![]() (这是尺度不变的)的线性组合。总体而言,我们的框损失是
(这是尺度不变的)的线性组合。总体而言,我们的框损失是![]() ,定义为
,定义为![]() ,其中
,其中![]() 是超参数。这两个损失通过批处理中目标的数量进行归一化。
是超参数。这两个损失通过批处理中目标的数量进行归一化。
补充材料——GIoU:用于解决IoU在边界框不重叠的情况下的优化问题。


3.2 DETR Architecture
整体DETR架构非常简单,如图2所示。它包含三个主要组件,我们在下面描述:用于提取紧凑特征表示的CNN主干、编码器-解码器Transformer和用于进行最终检测预测的简单前馈网络(FFN)。
与许多现代检测器不同,DETR可以在任何深度学习框架中实现,该框架只需几百行就可以提供通用的CNN主干和Transformer架构实现。在PyTorch [31]中,DETR的推理代码可以在不到50行的代码中实现。我们希望我们方法的简单性将吸引新的研究人员加入检测界。
主干。从初始图像![]() (具有3个颜色通道1)开始,传统的CNN主干生成较低分辨率的激活图
(具有3个颜色通道1)开始,传统的CNN主干生成较低分辨率的激活图![]() 。我们使用的典型值为C=2048和H, W=H0/32, W0/32。
。我们使用的典型值为C=2048和H, W=H0/32, W0/32。
Transformer编码器。首先,1x1卷积将高级激活图 f 的通道维数从C降低到更小的维数d。创建新的特征图![]() 。编码器期望一个序列作为输入,因此我们将z0的空间维度折叠为一个维度,从而产生d×HW的特征图。每个编码器层都有一个标准架构,由一个多头自注意力模块和一个前馈网络(FFN)组成。由于Transformer架构是置换不变的,我们用固定位置编码[3,30]来补充它,这些固定位置编码被添加到每个注意力层的输入中。我们遵循[46]中描述的架构的详细定义,请参阅补充材料。
。编码器期望一个序列作为输入,因此我们将z0的空间维度折叠为一个维度,从而产生d×HW的特征图。每个编码器层都有一个标准架构,由一个多头自注意力模块和一个前馈网络(FFN)组成。由于Transformer架构是置换不变的,我们用固定位置编码[3,30]来补充它,这些固定位置编码被添加到每个注意力层的输入中。我们遵循[46]中描述的架构的详细定义,请参阅补充材料。
Transformer解码器。解码器遵循Transformer的标准架构,使用多头自注意力和编码器-解码器注意力机制来转换大小为d的N个嵌入。与原始转换器的不同之处在于,我们的模型在每个解码器层并行解码N个目标,而Vaswani等人[46]使用自回归模型,每次预测一个元素的输出序列。我们请不熟悉这些概念的读者参阅补充材料。由于解码器也是置换不变的,所以N个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是习得的位置编码,我们称之为目标查询,与编码器类似,我们将它们添加到每个注意力层的输入中。解码器将N个目标查询转换为输出嵌入。然后,通过前馈网络(在下一小节中描述)将它们独立解码为框坐标和类标签,得到N个最终预测。使用自注意力和编码器-解码器对这些嵌入的关注,该模型使用所有目标之间的成对关系对所有目标进行全局推理,同时能够将整个图像用作上下文。
预测前馈网络。通过具有ReLU激活函数和隐藏维度d的3层感知机和线性投影层来计算最终预测。FFN预测相对于输入图像的框的归一化中心坐标、高度和宽度,线性层使用softmax函数预测类标签。由于我们预测了一组固定大小的N个边界框,其中N通常远大于图像中感兴趣目标的实际数量,因此使用额外的特殊类标签∅来表示在槽内未检测到目标。该类在标准目标检测方法中扮演类似于“背景”类的角色。
辅助解码损失。我们发现在训练期间在解码器中使用辅助损失[1]是有帮助的,特别是有助于模型输出每个类的正确数量的对象。每个解码器层的输出用共享层范数归一化,然后馈送到共享预测头(分类和框预测)。然后,我们像往常一样对匈牙利损失进行监督。
4 Experiments
4.1 Comparison with Faster R-CNN and RetinaNet
4.2 Ablations
4.3 DETR for Panoptic Segmentation
5 Conclusion


 浙公网安备 33010602011771号
浙公网安备 33010602011771号