LiT: Zero-shot transfer with locked-image text tuning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Abstract
本文提出了对比调整,这是一种简单的方法,使用对比训练来对齐图像和文本模型,同时仍然利用它们的预训练。在我们的实证研究中,我们发现锁定的预训练图像模型和解锁的文本模型效果最好。我们将这种对比调整的例子称为“锁定图像调整”(LiT),它只是教文本模型从预训练的图像模型中读出新任务的良好表征。LiT模型获得了零样本迁移到新视觉任务的能力,如图像分类或检索。所提出的LiT具有广泛的适用性;它在多种预训练方法(有监督和无监督)以及使用三个不同的图像-文本数据集的不同架构(ResNet、视觉Transformer和MLP Mixer)上都能可靠地工作。使用基于Transformer的预训练ViTg/14模型,LiT模型在ImageNet测试集上实现了84.5%的零样本迁移准确率,在具有挑战性的分布外ObjectNet测试集实现了81.1%的零样本迁移准确率。
1. Introduction
迁移学习[44]是计算机视觉领域的一个成功范例[32,33,42]。零样本学习[35,36,65]是一种替代方法,旨在开发能够在没有特定任务数据或适应协议的情况下处理新任务的模型。最近,有人证明,网络源配对图像-文本数据可用于对零样本迁移的强模型进行预训练[30,45]。零样本迁移与经典的零样本学习的不同之处在于,迁移设置可以在预训练期间看到相关的监督信息;它是零样本,因为在迁移协议期间没有使用监督的样本。GPT-3 [3]通过自然语言使用模型提示词探索了类似的零样本迁移设置。
在[30,45]中,作者提出了一种对比学习框架,其中图像模型(或图像塔)与文本模型(或文本塔)同时训练。两个塔都经过训练,以最大限度地减少对比损失,这鼓励成对图像和文本的表征相似,而非成对图像和文字的表征不同。在测试时,通过将图像嵌入与文本类描述的嵌入进行比较,所得到的模型可以用于零样本图像分类。
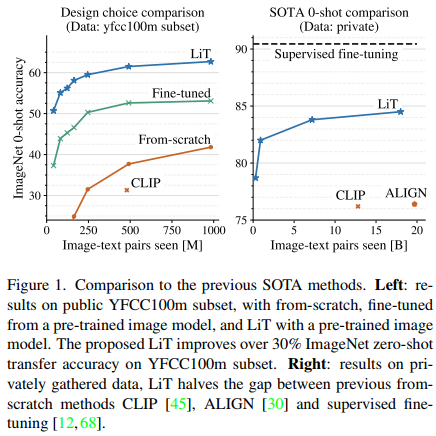
在本文中,我们采用了一个对比学习框架,并提出了一种更有效的数据和计算策略,称为对比调整。关键思想是使用图像-文本数据调整文本塔,同时使用预训练的强图像模型作为图像塔。在训练过程中,两个塔的权重都可以锁定或解锁,从而产生不同的设计选择,如图2所示。具体来说,我们发现锁定图像塔效果最好,如图1所示。我们将这种特定的对比调整实例称为“锁定图像调整”(LiT),它只是教文本模型从预先训练的图像模型中读出合适的表征。与从头开始的CLIP [45]或ALIGN [30]模型相比,LiT实现了更好的结果。使用预训练的模型ViT-g/14 [68],LiT在ImageNet上实现了84.5%的零样本迁移精度,将之前的最佳零样本迁移结果[30,45]与监督微调结果[12,68]之间的差距减半。与以前的监督和无监督方法相比,最佳LiT模型还为几种分布外(OOD) ImageNet测试变体设置了新的最先进技术。例如,它在具有挑战性的ObjectNet测试集[1]上实现了81.1%的准确率,比以前最先进的方法[45]高7.8%。
我们认为,LiT工作良好的原因在于其数据源的解耦以及用于学习图像描述符和视觉-语言对齐的技术。图像-文本数据可以很好地学习自然语言和视觉世界之间的对应关系,但同时,它可能不够精确和干净,无法产生最先进的图像描述符。在这篇论文中,我们仔细研究了这一假设,并用经验证据予以支持。
所提出的LiT与监督和自监督的预训练模型一起工作。我们使用视觉Transformer [20]、ResNet [32]和MLP Mixer [60]架构,在三个图像文本数据集上验证了LiT。我们还表明,使用自监督的预训练模型,即DINO [4]或MoCo-v3 [10],与从头开始的对比学习相比,LiT实现了更好的性能。
本文的另一个贡献是提出了高性能零样本模型的配方,该模型只能使用适度的计算资源和公共数据集进行训练。通过重新使用已经预训练好的模型(例如文献中公开发布的),可以摊销用于训练图像模型的计算资源。此外,我们探索了公开可用的数据集,如YFCC100m [59]和CC12M [5]。结合计算效率,我们希望促进更广泛的受众对零样本迁移研究的贡献。
2. Related work
3. Methods
3.1. Contrastive pre-training
与自由格式文本描述配对的图像集合(可能有噪声)已成为训练视觉模型的强大资源。其中的关键优点是它不受预定义类别的有限集合的限制,而是使用开放式自然语言来描述图像。因此,从这些数据中学到的模型可以作为零样本学习器,用于广泛的任务,例如分类和图像/文本检索。
对比预训练是从图像-文本数据中训练模型的一种特别有效的方法,最近被证明在实践中效果良好[30,45]。我们仔细研究了这种方法,并提出了一种简单但高效的方法来显著增强图像-文本数据的对比预训练。
图像和文本塔经过训练后,它们可以很容易地用于零样本分类:类名称或描述用文本模型获得嵌入。然后,对于给定的图像,选择具有最接近图像嵌入的嵌入的标签。这种方法也适用于图像-文本检索。
3.2. Contrastive-tuning
对比预训练可以被视为同时学习两个任务:(1) 学习图像嵌入和 (2) 学习文本嵌入以与图像嵌入空间对齐。虽然对图像-文本数据进行对比预训练可以很好地同时解决这两项任务,但这可能不是最佳方法。
当不对图像文本数据使用对比预训练时,学习图像嵌入的标准方法是使用(半)手动标记图像的大且相对干净的数据集。这种数据的大规模和高质量导致了最先进的图像嵌入。用于学习强大图像嵌入的一些数据集选择是ImageNet-21k [14]、JFT-300M [56]。
然而,这种常见的方法有一个明显的弱点:它仅限于预定义的一组类别,因此,生成的模型只能对这些类别进行推理。相比之下,图像-文本数据没有这种限制,因为它从自由形式的文本中学习,这些文本可能跨越广泛的现实生活概念。另一方面,可用的图像-文本数据可能比精心策划的数据集质量更低(用于学习图像嵌入)。
我们建议进行对比调整,以结合两种数据来源的优势。一种具体的方法是用已经使用更干净的(半)手动标记数据预训练的图像模型初始化对比预训练。通过这种方式,独立于图像嵌入来学习图像-文本对齐,从而从两个数据源中获益。
除了使用有监督的预训练图像模型外,所提出的对比调整也足够灵活,可以集成任何可以产生有意义表征的模型。我们在使用自监督的预训练图像模型的实验中验证了这一点。
类似的推理也可以应用于文本塔,因为有许多强大的预训练模型使用特定于文本的数据源和学习技术。
3.3. Design choices and Locked-image Tuning
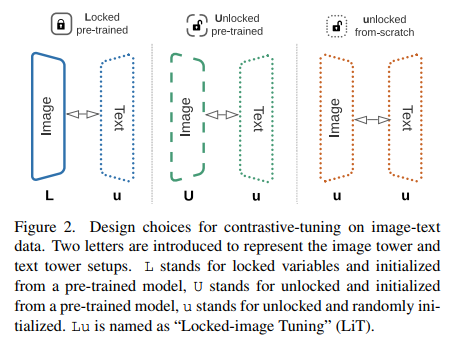
将预训练好的图像或文本模型引入对比学习环境涉及多种设计选择。首先,每个塔(图像和文本)可以独立地随机初始化,也可以从预训练的模型中初始化。对于预训练的模型,至少有两种变体:我们可以锁定(冻结)它或允许微调。请注意,在这两个极端之间有许多选择(例如,所选层的部分冻结或自定义学习率),但本文没有对其进行研究。
预训练的图像-文本模型可能具有不同的表征大小,而对比损失期望相同大小的表征。为了补偿,我们为每座塔添加了一个可选的线性投影(头),它将表征映射到一个公共维度。与这种简单的线性头相比,对基于MLP的头进行的初步研究并没有产生显著的改进。
我们引入两个字符的符号来讨论上面概述的潜在设计选择(见图2)。每个字符对为图像模型和文本模型选择的设置进行编码(按此顺序)。我们定义了三种潜在的设置:L (锁定权重,预训练模型初始化)、U (解锁/可训练权重,预训练模型初始化)和 u (解锁/可训练的权重,随机初始化)。例如,符号Lu表示锁定的预训练图像模型和解锁的(可训练的)随机初始化的文本模型。以前从零开始训练模型的工作[30,45]是uu。在我们的实验中,我们发现Lu设置工作得特别好,所以我们明确地将其命名为锁定图像调整(LiT)。
4. Image-text datasets
CC12M。概念说明文字数据集[51]从网页中提取、过滤和转换图像与alt文本对。我们使用最新的1200万图像-文本对版本,即CC12M [5]。由于URL过期,我们的实验只使用了1000万个图像-文本对。
YFCC100m。雅虎Flickr创意共享数据集[59]包含1亿个媒体对象。其中9920万张照片包含丰富的元数据,包括相机信息、时间戳、标题、描述、标签、地理位置等。[45]定义并使用1500万张经过过滤的高质量英文文本图像的子集,我们称之为YFCC100m-CLIP。附录E中介绍了对该数据集的详细调查以及如何最好地使用该数据集,包括是否对其进行过滤。
我们的数据集。我们按照与ALIGN [30]相同的过程收集了40亿个图像和alt文本对,使用相同的基于图像的过滤,但更简单的基于文本的过滤。附录L表明,减少文本过滤不会损害性能。为了避免误导性的评估结果,我们从我们的数据集中删除了我们评估的所有数据集中所有分割的几乎重复的图像。我们不认为创建我们的数据集是本文的主要贡献;我们只是简化了ALIGN [30]中的数据收集过程,以大规模证明我们的方法的有效性。
5. Experiments
5.1. Comparison to the previous state-of-the-art
5.2. Evaluation of design choices
5.3. LiT works better for more generally pretrained models
5.4. Which text model to use?
5.5. Do duplicate examples matter for LiT?
5.6. Technical advantages of locked image models
5.7. Preliminary multilingual experiments
6. Discussion
7. Conclusion
我们提出了一种称为对比调整的简单方法,该方法允许以零样本方式迁移任何预训练的视觉模型。更具体地说,所提出的LiT设置导致零样本迁移任务的实质性质量改进。它将从头开始的对比学习设置和每个任务监督的微调设置之间的差距减半。LiT可以使用公开可用的数据将公开可用的模型转化为零样本分类器,并与以前依赖更多专有数据的工作的性能相匹敌。
我们希望这项工作能推动未来的研究,即如何巧妙地重新使用和调整已经预先训练好的模型来解决不同的研究问题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号