A Simple Framework for Open-Vocabulary Segmentation and Detection
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
Abstract
我们介绍了OpenSeeD,这是一个简单的开放词汇分割和检测框架,它可以从不同的分割和检测数据集中联合学习。为了弥补词汇和注释粒度的差距,我们首先引入了一个预训练的文本编码器,对两个任务中的所有视觉概念进行编码,并为它们学习一个公共的语义空间。与仅在分割任务上训练的同行相比,这给了我们相当好的结果。为了进一步调和它们,我们确定了两个差异:i)任务差异——分割需要提取前景目标和背景内容的掩码,而检测只关心前者;ii)数据差异——框和掩码注释具有不同的空间粒度,因此不能直接互换。为了解决这些问题,我们提出了一种解耦解码来减少前景/背景之间的干扰,以及一种条件掩码解码来帮助生成给定框的掩码。为此,我们开发了一个包含所有三种技术的简单编码器-解码器模型,并在COCO和Objects365上对其进行了联合训练。在预训练之后,我们的模型在分割和检测方面都表现出竞争性或更强的零样本可迁移性。具体而言,OpenSeeD在5个数据集的开放词汇实例和全景分割方面击败了最先进的方法,并在类似设置下优于之前在LVIS和ODinW上的开放词汇检测工作。当迁移到特定任务时,我们的模型在COCO和ADE20K上实现了新的SoTA,用于全景分割,在ADE20K和Cityscapes上实现了实例分割(图中的下一行显示了OpenSeeD和以前的SoTA方法的性能比较)。最后,我们注意到,OpenSeeD是第一个探索联合训练在分割和检测方面的潜力的工作,并希望它能被视为在开放世界中为这两项任务开发单一模型的有力基准。代码将在https://github.com/IDEA-Research/OOpenSeeD上发布。
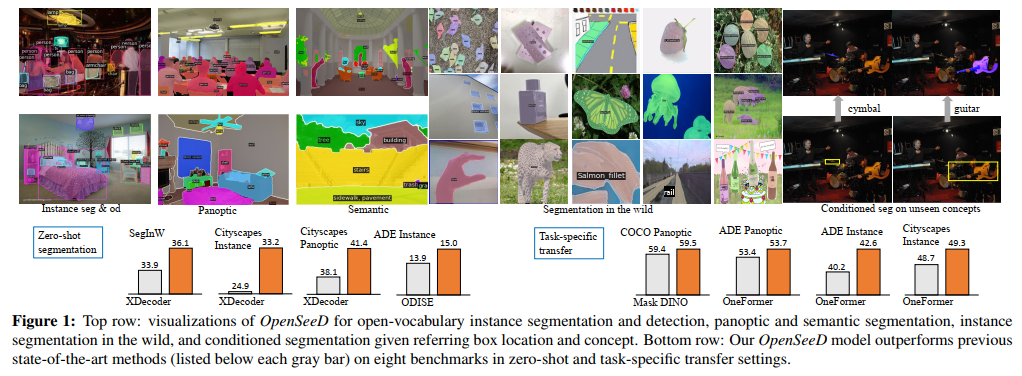
1. Introduction
2. Related Work
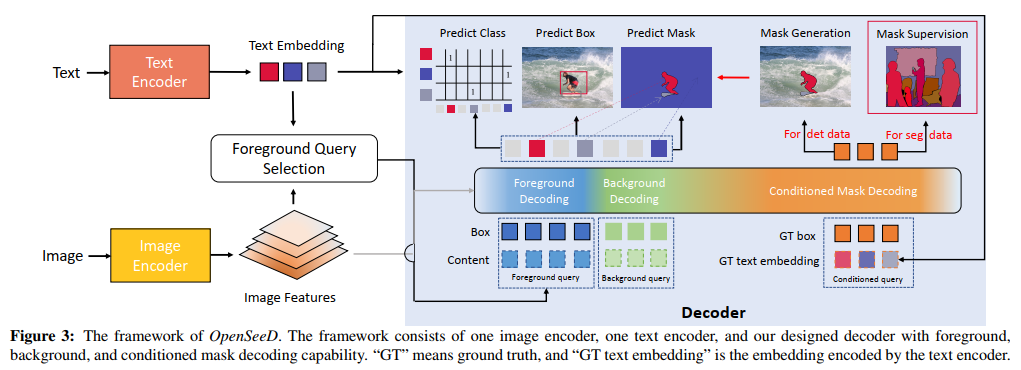
3. Method
给定分割和检测数据集,OpenSeeD旨在学习这两项任务的开放词汇模型。形式上,设![]() 表示大小为M的分割数据集,
表示大小为M的分割数据集,![]() 表示大小为N的检测数据集,其中c是图像中的视觉概念,m和b分别是相应的掩码和框。假设
表示大小为N的检测数据集,其中c是图像中的视觉概念,m和b分别是相应的掩码和框。假设![]() 是
是![]() 中出现的独特K个视觉概念的词汇。OpenSeeD的目标是学习在
中出现的独特K个视觉概念的词汇。OpenSeeD的目标是学习在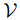 及之外中检测和分割视觉概念。
及之外中检测和分割视觉概念。
为了实现这一目标,我们提出了一种通用的编码器设计,并为我们的OpenSeeD使用了一个文本编码器,如图3所示。我们的模型将图像I和词汇表作为输入,并输出一组预测,包括掩码Pm、框Pb和分类分数Pc。总体而言,![]() 。更具体地说,我们的模型由一个图像编码器EncI、一个文本编码器EncT和一个解码器Dec组成。给定图像I和词汇表,我们首先分别通过EncI和EncT对它们进行编码:
。更具体地说,我们的模型由一个图像编码器EncI、一个文本编码器EncT和一个解码器Dec组成。给定图像I和词汇表,我们首先分别通过EncI和EncT对它们进行编码:
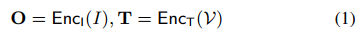
其中图像特征O ∈ RH×W×C,文本特征T={t1, t2, … , tK}。然后,解码器以L个查询Q ∈ RL×C作为输入,并对图像特征进行交叉处理得到输出:
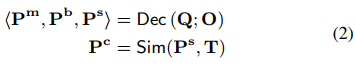
其中Ps是解码的语义。视觉-语义匹配分数Pc是通过计算Ps和T之间的相似性得分从Sim(Ps, T)中导出的,用于计算训练过程中的损失和预测推理过程中的类别。
3.1. Basic Loss Formulation
在这个基本公式中,我们试图通过促进共享的视觉语义空间来调和这两项任务,而不涉及其他问题。对于多个任务和数据集,我们的损失函数可以写成如下:

为了清楚起见,我们省略了每个损失项的权重。请注意,对于分割任务,我们可以从掩码m导出精确的框![]() ,并使用它们来计算框损失,如项
,并使用它们来计算框损失,如项![]() 所示。通过对所有项进行求和,我们的模型可以实现相当好的开放词汇性能。此外,它可以使用检测和分割数据进行端到端的预训练,从而允许它使用单个权重集执行开放词汇分割和检测。
所示。通过对所有项进行求和,我们的模型可以实现相当好的开放词汇性能。此外,它可以使用检测和分割数据进行端到端的预训练,从而允许它使用单个权重集执行开放词汇分割和检测。
尽管建立了一个强有力的基准,但正如前面讨论的那样,我们必须考虑这两项任务之间的内在差异。语义和全景分割需要识别前景和背景,而检测只关注于定位前景目标。因此,对两个任务使用相同的查询会产生冲突,从而显著降低性能。此外,良好的框预测通常表明良好的掩码,反之亦然。在检测和分割数据上单独训练框和掩码头阻碍了来自两个数据集的空间监督的协同作用。
为了解决上述差异,我们为我们的OpenSeeD引入了一种新的解码器设计。我们将查询Q分为三种类型:Lf前景查询Qf、Lb背景查询Qb和Ld条件查询Qd,并为每种类型提出特定于查询的计算。在下文中,我们将描述如何在第3.2节中解耦前景和背景解码以解决任务差异,并在第3.3节中使用条件掩码解码来解决数据差异。
3.2. Bridge Task Gap: Decoupled Foreground and Background Decoding
在不失一般性的情况下,我们将实例分割和检测中出现的视觉概念定义为前景,而全景分割中的内容类别则被视为背景。为了减轻任务差异,我们分别用前景查询Qf和背景查询Qb执行前景和背景解码。具体来说,对于这两种查询类型,我们的解码器预测两组输出,包括前景的![]() 和背景的
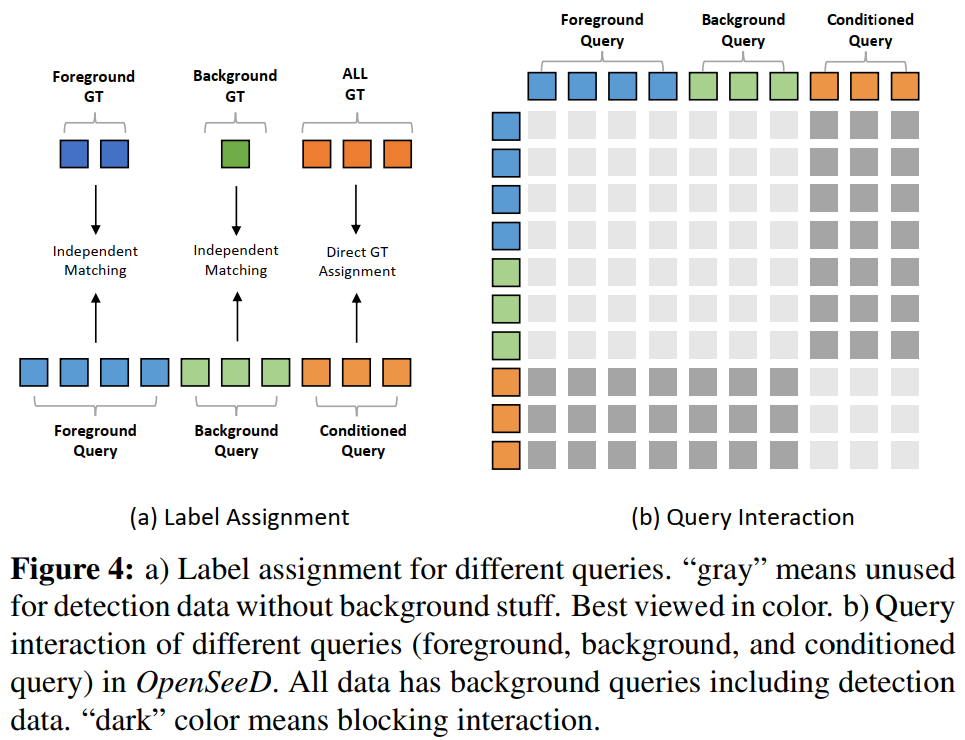
和背景的![]() 。我们还将分割数据集中的基本事实分为两组:(cf, mf)和(cb, mb),然后分别对这两组进行两个独立的匈牙利匹配过程,如图4(a)所示。因此,前景和背景解码都用于分割,而只有前景解码用于检测。因此,公式(3)中我们的基本损失被重新公式化为:
。我们还将分割数据集中的基本事实分为两组:(cf, mf)和(cb, mb),然后分别对这两组进行两个独立的匈牙利匹配过程,如图4(a)所示。因此,前景和背景解码都用于分割,而只有前景解码用于检测。因此,公式(3)中我们的基本损失被重新公式化为:

其中,![]() 和
和![]() 分别从mf和mb导出。基于这种显式解耦,我们的模型最大限度地提高了检测和分割数据集的前景监督的协作性,并显著减少了前景和背景类别之间的干扰。尽管是解耦的,但我们注意到这两种类型的查询共享相同的解码器,并以自注意力的方式相互作用,如图4(b)所示。下面我们将解释如何确定前景和背景查询。
分别从mf和mb导出。基于这种显式解耦,我们的模型最大限度地提高了检测和分割数据集的前景监督的协作性,并显著减少了前景和背景类别之间的干扰。尽管是解耦的,但我们注意到这两种类型的查询共享相同的解码器,并以自注意力的方式相互作用,如图4(b)所示。下面我们将解释如何确定前景和背景查询。
语言引导的前景查询选择。开放词汇设置与传统的闭集设置的不同之处在于,需要一个模型来定位远远超出训练词汇的大量前景目标。然而,事实是,我们的解码器包含有限数量的前景查询(通常只有几百个),这使得它很难处理图像中所有可能的概念。为了解决这个问题,我们提出了一种称为语言引导的前景查询选择的方法,以根据给定的文本概念自适应地选择查询,如图第3左部分所示。给定图像特征O和文本特征T,我们使用轻量级模块来预测框并为每个特征打分:
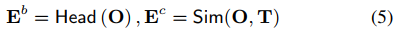
其中Head是框头。然后,我们根据Ec中的分数,从Eb和O中选择Lf个排名靠前的条目。然后,将这些选定的Lf图像特征和框作为前景查询提供给解码器(图3中的蓝色方块)。通过仅选择与文本相关的token作为解码器查询,我们减轻了解码无关语义的问题,并提供了更好的查询初始化。这种提出前景查询的自适应方式使我们的模型能够在测试场景中有效地转换到新的词汇表。
可学习的背景查询。与前景查询不同,我们在背景查询中使用可学习的查询嵌入有两个原因。首先,查询选择不能很好地工作,因为所选的参考点往往延伸到大的非凸背景区域之外,导致次优结果。其次,背景内容的类别数量比前景相对较少,并且单个图像通常包含一些不同的内容(例如,“天空”、“建筑”)。因此,对我们的模型使用可学习查询可以充分有效地处理背景内容类别,并很好地推广到开放词汇设置。背景查询在图3中用绿色方块标记。
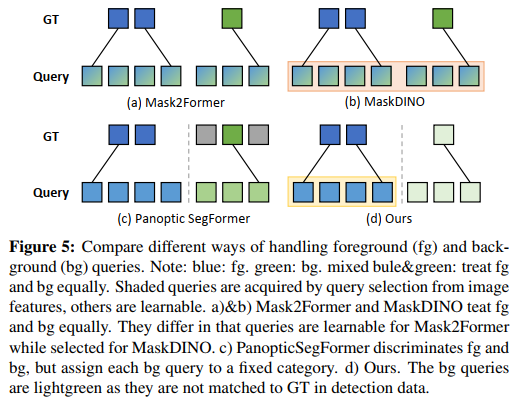
与以往工作的比较。在图5中,我们展示了我们的方法与其他方法在处理前景和背景方面的比较。Mask2Former [5]和MaskDINO [29]在进行全景分割时平等地处理前景和背景,与仅在前景类上训练的相同模型(实例分割)相比,导致前景目标的掩码平均精度(AP)次优。Panoptic Segformer [32]将前景和背景查询分开,但它们的背景查询具有固定的语义,每个查询都对应于预定义的背景类别,这限制了它们处理开放词汇类别的能力。相反,我们的方法通过语言引导的选择机制提出了前景查询,并且我们的背景查询是完全可学习的,消除了预定义词汇的限制。
3.3. Bridge Data Gap: Conditioned Mask Decoding
我们的最终目标是通过使用单个损失函数来训练多个任务来弥合数据差距,从而产生以下损失函数1:
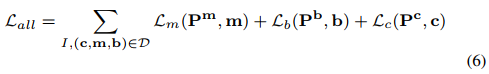
在此,D表示分割和检测数据集的并集。然而,损失函数需要检测数据的掩码注释和分割数据的框注释,导致两个任务之间的空间监督粒度存在差异。如我们之前所讨论的,我们可以容易地将目标掩码m转换为框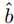 ,这将原始分割数据
,这将原始分割数据![]() 扩充为
扩充为![]() 。然而,对于检测数据Db,我们仅得到粗略的位置(框)和类别。然后一个有趣的问题来了——给定这些先验,我们能得到它的掩码吗?为了解决这个问题,我们求助于包含从标签和框到掩码的丰富映射的分割数据,即(c, b) → m,并提出条件掩码解码来学习映射,如图3最右侧部分所示。给定基本事实概念和框(c, b),我们使用解码器来解码掩码:
。然而,对于检测数据Db,我们仅得到粗略的位置(框)和类别。然后一个有趣的问题来了——给定这些先验,我们能得到它的掩码吗?为了解决这个问题,我们求助于包含从标签和框到掩码的丰富映射的分割数据,即(c, b) → m,并提出条件掩码解码来学习映射,如图3最右侧部分所示。给定基本事实概念和框(c, b),我们使用解码器来解码掩码:
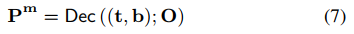
其中 t 是为概念提取的文本特征。基于公式(7),问题变成了“我们能从分割数据中学习一个好的映射吗?该映射能很好地推广到不同类别的检测数据?”
1 我们在这里不区分前景项和背景项,而在实践中,前景项和背景项的划分如公式4所示。此外,这种损失函数被认为是理想的,我们无法在稍后描述的在线掩码辅助方法中实现它。

映射假设验证。为了回答这个问题,我们进行了一项试点研究。我们训练一个模型,该模型学习在COCO [4]上解码以GT概念和框为条件的掩码,然后在ADE20K [58]上评估条件解码性能。结果如表1所示。比较前两行,我们可以发现以GT概念和框为条件的掩码解码显著提高了质量(掩码AP从8.6提高到46.4),甚至达到了与COCO相似的水平(46.4 vs. 53.2)。这些结果表明,我们学到的掩码解码可以很好地推广到具有新类别的新数据集。为了进一步验证,我们在图6中可视化解码的掩码。

交互式细分。上述研究为图像分割提供了一个新的接口。除了从头开始分割图像外,用户还可以通过绘制方框(点击四点)来提示目标的位置,我们的OpenSeeD可以以相当高的质量生成其掩码。这种能力可能有助于加速分割数据的注释,尤其是对于那些有方框的数据。我们将对此进行全面研究作为今后的工作。
条件掩码解码训练。基于已验证的假设,我们添加所有GT框和标签作为条件查询,以同时学习前景/背景解码和条件掩码解码,如图3所示。它统一了我们所有的任务,使OpenSeeD能够在联合语义空间中学习更广义的条件解码。基于此,我们可以从字面上推导出目标检测数据的伪掩码![]() ,并获得增广
,并获得增广
![]() 。下面我们将详细说明这些伪掩码是如何用于训练的。
。下面我们将详细说明这些伪掩码是如何用于训练的。
条件掩码生成以引导检测数据。训练的条件掩码解码部件也可以用于辅助检测数据作为分割指导。我们提出了两种方法来利用生成的掩码来指导我们的模型训练,即在线掩码辅助和离线掩码辅助。对于在线掩码援助,我们只训练一个模型并实时生成掩码。我们没有直接使用生成的掩码作为掩码监督,而是使用掩码来帮助匹配预测和GT实例,因为掩码质量不足以进行监督。尤其是在早期阶段(如表1第三行所示)。至于离线掩码辅助,我们用条件掩码解码训练我们的模型,直到收敛,并为检测数据生成掩码注释。带注释的数据集可以用于训练分割模型。考虑到检测数据只有实例级注释,在这两种情况下,生成的掩码都有望改进实例分割。关于这两种方法的更多细节在附录中进行了讨论。
与去噪训练的比较。与使用去噪训练的模型(DN)[28,29,55]相比,条件掩码解码在两个方面有所不同。首先,他们的设计选择是不同的。DN将噪声添加到GT框和标签中以进行重建,但我们的模型学习生成以GT先验为条件的掩码。其次,它们的设计目的不同。DN旨在加速训练收敛(理解),而我们的方法旨在为检测数据生成掩码(生成)。
4. Experiment
4.1. Experimental Setup
4.2. Open-Vocabulary Benchmarking
4.3. Direct and Task-Specific Transfer
4.4. Segmentation and Detection in the Wild
4.5. Ablation
5. Conclusion
我们提出了OpenSeeD,这是一个简单的开放式词汇分割和检测框架,它使用单个模型从不同的分割和检测数据集中联合学习。为了弥补前台目标和后台对象之间的任务差距,我们提出了一种基于语言引导的前台查询选择解耦解码方法。我们还联合训练了一个条件掩码解码任务,该任务在推理过程中提供了一个交互式分割接口,并有助于在训练过程中弥合检测数据的数据缺口。结果表明,我们的统一模型在保持合理检测性能的同时,显著提高了开放分割的性能。联合预训练的模型也可以无缝转移,以提高紧密词汇表的性能。
局限性。在这项工作中,我们旨在探索训练用于分割和检测的开放词汇模型的潜力。OpenSeeD既不使用引用/基础数据,也不使用大规模的图像-文本对来进一步丰富我们的训练数据和语义覆盖范围。我们将更大规模的联合训练留给未来的工作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号