Semantic-SAM: Segment and Recognize Anything at Any Granularity
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
在本文中,我们介绍了Semantic-SAM,这是一种通用的图像分割模型,可以以任何所需的粒度分割和识别任何东西。我们的模型提供了两个关键优势:语义感知和粒度丰富性。为了实现语义感知,我们跨粒度合并多个数据集,并对解耦的目标和部分分类进行训练。这使得我们的模型能够促进丰富语义信息之间的知识迁移。对于多粒度能力,我们提出了一种多选学习方案,使每个点击点能够在多个级别上生成对应于多个真实事实掩码的掩码。值得注意的是,这项工作首次尝试在SA-1B、通用和部分分割数据集上联合训练模型。实验结果和可视化结果表明,我们的模型成功地实现了语义感知和粒度丰富。此外,将SA-1B训练与其他分割任务(如全景分割和部分分割)相结合,可以提高性能。我们将在https://github.com/UX-Decoder/Semantic-SAM上提供代码和演示以供进一步探索和评估。
1 Introduction
遵循人类意图的通用且交互式人工智能系统在自然语言处理[46,47]和可控图像生成[52,66]中显示了其潜力。然而,这种用于像素级图像理解的通用系统仍然很少被探索。我们认为,通用分割模型应该具有以下重要特性:通用表征、语义感知和粒度丰富。无论具体的图像域或提示词上下文如何,该模型都能够获得通用表征,预测多粒度的分割掩码,并理解每个分割区域背后的语义。
先前的工作[31,70,58]试图研究这些性质,但只实现了部分目标。阻碍这种通用图像分割模型发展的主要障碍可归因于模型架构灵活性和训练数据可用性方面的限制。
- 模型结构。现有的图像分割模型架构由丢弃任何模糊性的单输入单输出流水线主导。虽然这种流水线在基于锚的CNN架构[24]和基于查询的Transformer架构[4,11]中都很普遍,并且在语义、实例和全景分割任务[39,68,30]中表现出了显著的性能,但它固有地限制了模型以端到端的方式预测多粒度分割掩码。尽管聚类后处理技术[13]可以为单个对象查询生成多个掩码,但对于粒度感知的分割模型来说,它们既不是高效的也不是有效的解决方案。
- 训练数据。扩展同时具有语义感知和粒度感知的分割数据集是一项代价高昂的工作。现有的通用目标和分割数据集,如MSCOCO [39]和Objects365 [53],提供了大量数据和丰富的语义信息,但仅在目标级别。另一方面,Pascal Part [9]、PartImageNet [23]和PACO [49]等部分分割数据集提供了更细粒度的语义注释,但其数据量有限。最近,SAM [31]已经成功地将多粒度掩码数据扩展到数百万张图像,但它不包括语义注释。为了实现语义感知和粒度丰富的双重目标,迫切需要统一对各种数据格式的分割训练,以促进知识迁移。然而,不同数据集在语义和粒度上的固有差异对联合训练工作构成了重大挑战。
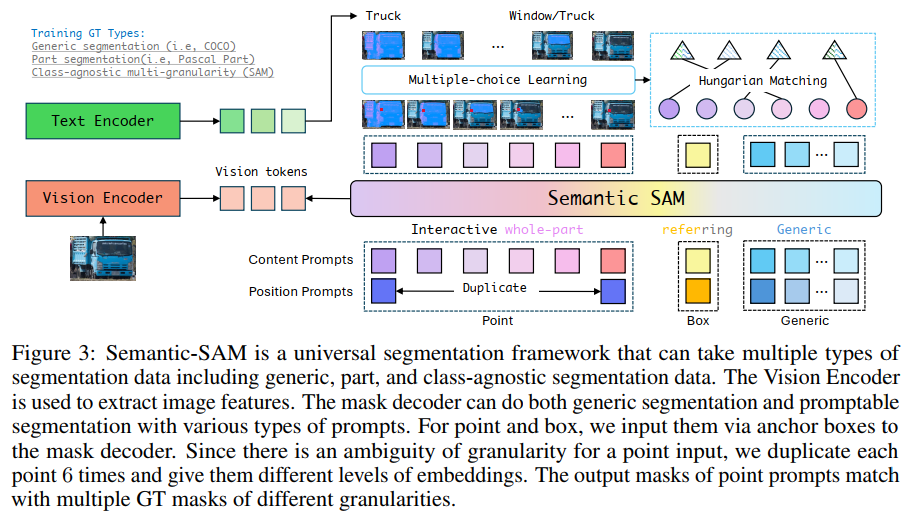
在本文中,我们介绍了Semantic-SAM,这是一种通用图像分割模型,旨在实现以任何所需粒度分割和识别目标。给定用户的一个点击点,我们的模型通过预测多个粒度的掩码来解决空间模糊性,并在目标和部分级别上添加语义标签。如图1所示,我们的模型生成了从人头到整个卡车的多级分割掩码。
多粒度能力是通过将多选学习设计[37,22]纳入解码器架构来实现的。每次单击都用多个查询表示,每个查询都包含不同级别的嵌入。训练这些查询以从表示不同粒度的所有可用的真正事实掩码中学习。为了在多个掩码和真正事实之间建立对应关系,我们采用了多对多匹配方案来确保单个点击点可以生成多粒度的高质量掩码。
为了实现具有通用能力的语义感知,我们引入了一种针对目标和部分的解耦分类方法,利用共享文本编码器对目标和部分进行独立编码。这使我们能够分别执行目标和部分分割,同时根据数据类型调整损失函数。例如,通用分割数据缺少部分分类损失,而SAM数据不包括分类损失。
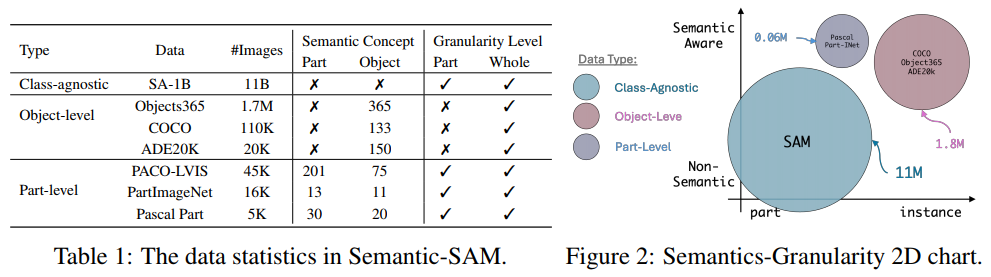
为了丰富我们模型中的语义和粒度,我们在三种类型的粒度上合并了七个数据集,包括MSCOCO [39]、Objects365 [53]、ADE2K [68]的通用分割、PASCAL Part [9]、PACO [49]、PartImagenet [23]和SA-1B [31]的部分分割。他们的数据格式被重新组织,以相应地匹配我们的训练目标。经过联合训练,我们的模型在各种数据集上都获得了强大的性能。值得注意的是,我们发现从交互式分割中学习可以改进通用分割和部分分割。例如,通过联合训练SA-1B提示分割和COCO全景分割,我们实现了2.3框AP的增益和1.2掩码AP的增益。此外,通过全面的实验,我们证明了我们的粒度完整性优于SAM,超过3.4 1-IoU。

2 Data Unification: Semantics and Granularity
为了实现多级语义,我们包括七个数据集,它们包含不同的粒度级别掩码。数据集包括SA-1B、COCO全景图、ADE2K全景图、PASCAL part、PACO、PartImageNet和Objects365。其中,COCO和ADE20k全景数据集包含目标级掩码和类标签。PASCAL part、PACO和PartImageNet包含目标级掩码和类标签。SA-1B包含最多6级掩码,不带标签,而Objects365包含大量用于目标级实例的类标签。这些数据集的详细信息如表1所示。我们在图2中进一步可视化了不同数据类型的数据分布。
3 Semantic-SAM
3.1 Model
我们的Semantic-SAM遵循Mask DINO [33],利用基于查询的掩码解码器来产生语义感知和多粒度掩码。除了通用查询外,它还支持两种类型的提示词,包括点和框,类似于SAM [31]。整个流水线如图3所示。
我们将点击和框提示词作为一种统一的格式表示为锚框。特别地,我们将用户点击点(x, y)转换为具有较小宽度w和高度h的锚框(x, y, w, h),以便锚框可以接近该点。为了捕捉不同粒度的掩码,首先对每次点击进行编码以定位提示词,并与K个不同的内容提示词相结合,其中每个内容提示词表示为给定粒度级别的可训练嵌入向量。在这里,我们根据经验选择K=6,考虑到SA-1B [31]中的大多数图像的每个用户点击最多有6个级别的掩码。更具体地,点击/框b=(x, y, w, h)分别被编码为K个内容嵌入和一个位置嵌入。我们将其内容嵌入表示为一组查询向量Q=(q1, ... , qK)。对于第 i 个查询,

其中
- qlevel是粒度级别 i 的嵌入,
- qtype区分查询类型,从点击或框嵌入中选择。
c的位置嵌入是通过正弦编码实现的。假设来自视觉编码器的输出图像特征是F,则所提出的Semantic-SAM的掩码解码器将输入图像上的点击表示为:
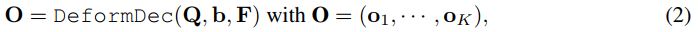
其中DeformDec(·, ·, ·)是一个可变形解码器,它以查询特征、参考框和图像特征为输入,输出查询特征。oi是第 i 个输入查询qi的模型输出。每个oi=(ci, mi)由预测的语义类别ci和掩码mi组成,它们分别用于构建概念识别损失和掩码预测损失。
3.2 Training
4 Experiments
4.1 Experimental Setup
4.2 Semantic Segmentation of Anything
4.3 Abaltions
4.4 Visualization
5 Related works
5.1 Generic Segmentation
5.2 Part Segmentation
5.3 Open-Vocabulary Segmentation
5.4 Interactive Segmentation
6 Conclusion
在本文中,我们提出了Semantic-SAM,它可以以任何所需的粒度分割和识别任何东西。除了进行通用的开放式词汇分割外,Semantic-SAM还展示了语义感知和粒度丰富的优势。为了实现这些优势,我们提出了对数据、模型和训练的改进,其中我们利用了来自多个粒度和语义级别的数据集、用于训练的多选学习以及用于建模的通用框架。综合实验和可视化验证了我们模型的语义意识和粒度丰富性。此外,Semantic-SAM是首次在SA-1B和其他经典分割数据集上联合训练的成功尝试。实验结果还表明,使用SA-1B进行训练可以改进其他任务,如全景和部分分割。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号