
Deep Exploration via Bootstrapped DQN
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NIPS 2016
Abstract
有效的探索仍然是强化学习(RL)的主要挑战。常见的探索抖动策略,如ε-贪婪,不进行时间扩展(或深度)探索;这可能导致数据需求呈指数级增长。然而,在复杂的环境中,大多数用于统计有效RL的算法在计算上是不可处理的。随机化价值函数提供了一种很有前途的泛化有效探索方法,但现有算法与非线性参数化价值函数不兼容。作为解决此类情况的第一步,我们开发了自举DQN。我们证明了自举DQN可以将深探索与深度神经网络相结合,实现比任何抖动策略都快的指数级学习。在Arcade学习环境中,自举DQN大大提高了大多数游戏的学习速度和累积性能。
1 Introduction
我们研究了智能体与未知环境相互作用的强化学习(RL)问题。智能体采取一系列动作,以最大限度地提高累积奖励。与标准的规划问题不同,RL智能体不是从对环境的完美了解开始的,而是通过经验来学习。这导致了探索与开发之间的根本权衡;智能体可以通过探索不太了解的状态和动作来提高其未来奖励,但这可能需要牺牲即时奖励。为了有效地学习,智能体应该只有在有宝贵的学习机会的时候才去探索。此外,由于任何动作都可能产生长期后果,因此智能体应该对可能的观察序列的信息价值进行推理。如果没有这种时序延伸的(深度)探索,学习时间可能会因指数因素而恶化。
RL理论文献提供了多种可证明有效的深度勘探方法[9]。然而,其中大多数是为具有小有限状态空间的马尔可夫决策过程(MDP)设计的,而其他则需要解决计算上难以解决的规划任务[8]。这些算法在复杂环境中是不实用的,在复杂环境下,智能体必须进行泛化才能有效操作。因此,RL的大规模应用依赖于统计上低效的探索策略[12],甚至根本没有探索[23]。我们在第4节中更详细地回顾了相关文献。
常见的抖动策略,如“-贪婪”,用一个数字来近似一个动作的值。大多数时候,他们会选择估计值最高的动作,但有时他们会随机选择另一个动作。在本文中,我们考虑了一种受汤普森采样启发的有效勘探的替代方法。这些算法有一些不确定性的概念,而是在可能的值上保持分布。他们根据最优策略的概率随机选择一个策略进行探索。最近的工作表明,随机值函数可以实现类似于Thompson采样的功能,而不需要棘手的精确后验更新。然而,这项工作仅限于线性参数化价值函数[16]。我们提出了这种方法的自然扩展,可以使用复杂的非线性泛化方法,如深度神经网络。我们证明了具有随机初始化的自举可以在低计算成本下为神经网络产生合理的不确定性估计。自举DQN利用这些不确定性估计进行高效(深入)探索。我们证明,这些好处可以扩展到大规模问题,而这些问题并不是为了突出深层勘探而设计的。自举DQN大大减少了学习时间,并提高了大多数游戏的性能。该算法计算效率高,可并行化;在一台机器上,我们的实现运行速度比DQN慢大约20%。
2 Uncertainty for neural networks
深度神经网络(DNN)代表了许多监督和强化学习领域的最新技术[12]。我们想要一种在统计上计算高效的探索策略,以及价值函数的DNN表示。为了有效地探索,第一步是量化价值估计中的不确定性,以便智能体能够判断探索动作的潜在好处。神经网络文献提出了大量基于参数贝叶斯推理的不确定性量化工作[3,7]。事实上,我们在实验中发现具有随机初始化[5]的简单非参数自举更有效,但本文的主要思想将适用于DNN中的任何其他不确定性方法。
自举原理是通过样本分布来近似总体分布[6]。在最常见的形式中,自举将数据集D和估计器Ψ作为输入。为了从自举分布生成样本,与数据集D基数相同的数据集![]() 在从D替换的情况下被均匀采样。然后将自举样本估计取为
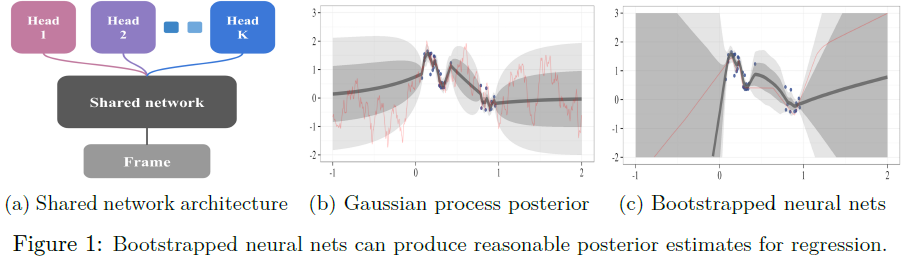
在从D替换的情况下被均匀采样。然后将自举样本估计取为![]() 。自举被广泛认为是20世纪应用统计学的一大进步,甚至有理论保证[2]。在图1a中,我们提出了一种从大型深度神经网络生成自举样本的高效且可扩展的方法。该网络由一个共享架构组成,其中K个自举“头”独立分支。每个头部仅在其数据的自举子样本上进行训练,并表示单个自举样本
。自举被广泛认为是20世纪应用统计学的一大进步,甚至有理论保证[2]。在图1a中,我们提出了一种从大型深度神经网络生成自举样本的高效且可扩展的方法。该网络由一个共享架构组成,其中K个自举“头”独立分支。每个头部仅在其数据的自举子样本上进行训练,并表示单个自举样本![]() 。共享网络学习所有数据的联合特征表示,这能够以降低头部之间的多样性为代价提供显著的计算优势。这种类型的自举可以在单个前向/反向传播中有效地训练;它可以被认为是数据相关的dropout,其中每个头的dropout掩码对于每个数据点是固定的[19]。
。共享网络学习所有数据的联合特征表示,这能够以降低头部之间的多样性为代价提供显著的计算优势。这种类型的自举可以在单个前向/反向传播中有效地训练;它可以被认为是数据相关的dropout,其中每个头的dropout掩码对于每个数据点是固定的[19]。
图1展示了在具有噪声数据的回归任务中,自举神经网络的不确定性估计示例。我们在数据中的50个自举样本上训练了一个全连接的2层神经网络,每层具有50个校正线性单元(ReLU)。按照标准,我们用随机参数值初始化这些网络,这在模型中引入了重要的初始多样性。我们无法使用先前文献[7]中的dropout方法为该问题生成有效的不确定性估计。更多细节见附录A。
3 Bootstrapped DQN
对于策略π,我们定义了状态s中动作a的价值![]() ,其中γ ∈ (0, 1)是一个折扣因子,用于平衡当前和未来奖励rt。该期望表示初始状态为s,初始动作为a,然后由策略π选择动作。最优价值为Q*(s, a) := maxπQπ(s, a)。为了扩展到大问题,我们学习Q值函数Q(s, a; θ)而不是表格编码。我们使用神经网络来估计这个价值。
,其中γ ∈ (0, 1)是一个折扣因子,用于平衡当前和未来奖励rt。该期望表示初始状态为s,初始动作为a,然后由策略π选择动作。最优价值为Q*(s, a) := maxπQπ(s, a)。为了扩展到大问题,我们学习Q值函数Q(s, a; θ)而不是表格编码。我们使用神经网络来估计这个价值。
从状态st、动作at、奖励rt和新状态st+1的Q学习更新由下式给出
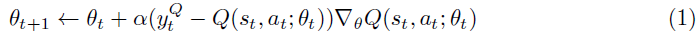
其中α是标量学习率,![]() 是目标价值rt + γ maxaQ(st+1, a; θ-)。θ-是目标网络参数,固定θ- = θt。
是目标价值rt + γ maxaQ(st+1, a; θ-)。θ-是目标网络参数,固定θ- = θt。
对Q学习更新的几个重要修改提高了DQN的稳定性[12]。首先,该算法从经验缓存的采样转换中学习,而不是完全在线学习。其次,该算法使用带有参数θ-的目标网络,这仅每隔τ个时间步骤从学习网络复制θ- ← θt,然后在更新之间保持固定。双重DQN[25]修改目标![]() 并有助于进一步1:
并有助于进一步1:
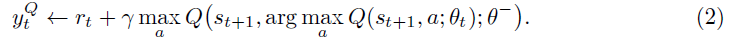
自举DQN通过自举修改DQN以近似Q值上的分布。在每个回合开始时,自举DQN从其近似后验中对单个Q值函数进行采样。然后,智能体在回合持续时间内遵循对该样本最优的策略。这是Thompson采样启发式算法对RL的自然适应,允许进行时间扩展(或深度)探索[21,13]。
我们通过并行构建Q值函数的![]() 自举估计来有效地实现该算法,如图1a所示。重要的是,这些价值函数中的每一个函数头Qk(s, a; θ)针对其自身的目标网络Qk(s, a; θ-)。这意味着每个Q1, ... , QK通过TD估计提供了对价值不确定性的时间扩展(和一致)估计。为了跟踪哪个数据属于哪个自举头,我们存储标志w1, ... , wK ∈ {0, 1},指示哪些头对哪些数据知情。我们通过随机均匀地选择k ∈ {1, ... , K}并在该回合的持续时间内遵循Qk来近似自举样本。我们在附录B中给出了一个实现自举DQN的详细算法。
自举估计来有效地实现该算法,如图1a所示。重要的是,这些价值函数中的每一个函数头Qk(s, a; θ)针对其自身的目标网络Qk(s, a; θ-)。这意味着每个Q1, ... , QK通过TD估计提供了对价值不确定性的时间扩展(和一致)估计。为了跟踪哪个数据属于哪个自举头,我们存储标志w1, ... , wK ∈ {0, 1},指示哪些头对哪些数据知情。我们通过随机均匀地选择k ∈ {1, ... , K}并在该回合的持续时间内遵循Qk来近似自举样本。我们在附录B中给出了一个实现自举DQN的详细算法。
1 在本文中,除非有明确说明,否则我们对所有DQN变体使用DDQN更新。
4 Related work
时间延伸的探索对于有效的强化学习是必要的,这并不是什么新鲜事。对于MDP上的任何先验分布,最优探索策略可以通过贝叶斯信念状态空间中的动态规划获得。然而,即使对于非常简单的系统,精确的解决方案也是难以解决的[8]。许多成功的RL应用程序侧重于泛化和规划,但仅通过低效的探索[12]或根本不进行探索[23]来解决探索问题。然而,这种探索策略可能效率很低。
许多探索策略都以“面对不确定性时的乐观主义”(OFU)原则为指导。这些算法为状态-动作对的价值添加了探索奖励,这可能导致有用的学习和选择动作以最大化这些调整后的价值。该方法最初是针对有限臂赌博机提出的[11],但该原理已通过泛化和表格RL[9]成功扩展到赌博机中。除了特定的确定性上下文[27]外,在复杂领域中导致有效RL的OFU方法在计算上是难以解决的。[20]的工作旨在通过DQN的变化来增加有效的奖金。所得到的算法依赖于大量手动调整的参数,并且仅适用于确定性问题。我们在附录D中将我们在Atari上的结果与他们的结果进行了比较,发现自举DQN比以前的方法有了显著的改进。
也许最古老的平衡探索与开发的启发式方法是由Thompson采样[24]给出的。该赌博机算法在每个时间步骤从后验中提取一个样本,并选择该时间步骤的最优动作。为了将Thompson采样原理应用于RL,智能体应该从价值函数的后验中对其进行采样。将Thompson采样简单地应用于RL,即每一个时间步骤都进行重新采样,可能效率极低。智能体还必须对该样本进行几个时间步骤的承诺,以实现深度勘探[21,8]。PSRL算法正是这样做的,并提供了最先进的保证[13,14]。然而,该算法仍然需要求解单个已知的MDP,这对于大型系统来说通常是难以解决的。
我们的新算法,自举DQN,通过从近似后验采样的随机化价值函数来近似这种探索方法。最近,作者提出了RLSVI算法,该算法用于线性参数化价值函数。令人惊讶的是,RLSVI在具有表格基函数的设置中恢复了最先进的保证,但其性能关键取决于价值函数的适当线性表示[16]。我们扩展了这些思想,产生了一种算法,该算法可以用灵活的非线性价值函数表示同时进行泛化和探索。我们的方法简单、通用,几乎与深度RL的所有进展都兼容,计算成本低,调整参数少。
5 Deep Exploration
不确定性估计允许智能体将其探索导向潜在的信息状态和动作。在赌博机中,这种直接探索而不是抖动的选择通常会对有效的算法进行分类。RL中的故事没有那么简单,直接探索不足以保证效率;探索也必须深入。深探索是指在多个时间步骤上进行的探索;它也可以被称为“规划学习”或“远见卓识”的探索。与赌博机问题不同,赌博机问题会平衡立即获得奖励或立即提供信息的动作,RL设置需要在几个时间步骤上进行规划[10]。对于开发,这意味着一个有效的智能体必须考虑几个时间步骤的未来奖励,而不仅仅是短视的奖励。同样,有效的探索可能需要采取既没有立即奖励,也没有立即提供信息的动作。
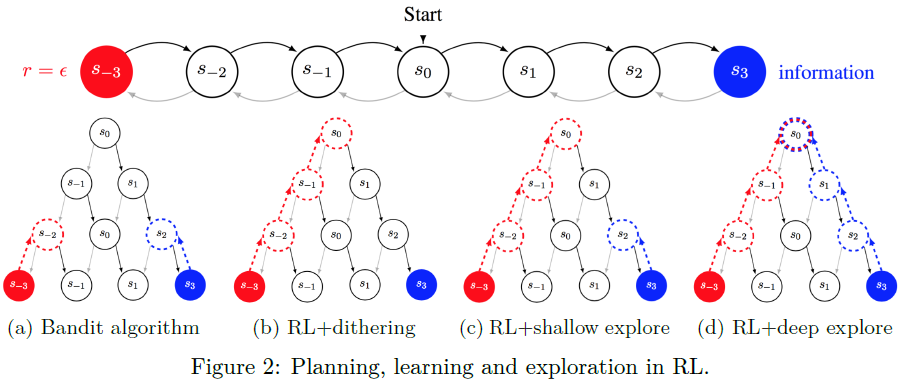
为了说明这种区别,考虑一个简单的确定链{s-3, ... , s+3},从状态s0开始有三步视界。这个MDP对于智能体来说是先验已知的,具有“左”和“右”的确定性操作。除了最左边的状态s-3具有已知的奖励ε>0和最右边的状态s3未知外,所有状态都具有零奖励。为了在从s0开始的三个步骤内达到奖励状态或信息状态,智能体必须在几个时间步骤内规划一致的策略。图2描述了本示例MDP中几种算法方法的规划和前瞻树。动作“左”为灰色,动作“右”为黑色。奖励状态显示为红色,信息状态显示为蓝色。虚线表示智能体可以提前规划奖励或信息。与赌博机算法不同,RL智能体可以规划利用未来的奖励。只有具有深探索能力的RL智能体才能规划学习。
5.1 Testing for deep exploration
我们现在展示了一系列教学性的计算实验,旨在强调深探索的必要性。这些环境可以用图3中长度N>3的链来描述。每一次交互持续N+9个步骤,之后智能体重置到初始状态s2。这些都是简单问题,目的是为了说明,而不是完全现实。在许多实际应用中,可以平衡一种众所周知且略有成功的策略与一种未知但可能更有回报的方法。
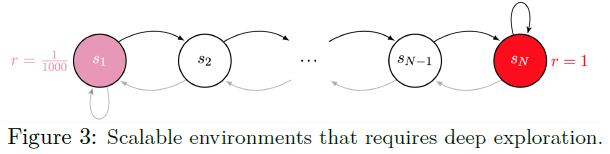
这些环境可以通过有限的表格MDP来描述。然而,我们考虑仅通过原始像素特征与MDP交互的算法。我们考虑两个特征映射![]() 和
和![]() (在{0, 1}N中)。我们给出了Φtherm的结果,由于具有更好的泛化能力,它对所有DQN变体都更有效,但差异相对较小——见附录C。Thompson DQN与自举DQN相同,但每个时间步骤都重新采样。集成DQN使用与自举DQN相同的结构,但具有集成策略。
(在{0, 1}N中)。我们给出了Φtherm的结果,由于具有更好的泛化能力,它对所有DQN变体都更有效,但差异相对较小——见附录C。Thompson DQN与自举DQN相同,但每个时间步骤都重新采样。集成DQN使用与自举DQN相同的结构,但具有集成策略。
我们说,当算法以10的最佳奖励成功完成100个回合时,它已经成功地学习了最佳策略。对于每个链长度,我们在三个种子上运行每个学习算法2000个回合。我们在图4中绘制了学习的中值时间,以及任何浅探索策略的期望学习时间的保守下界99+2N-11[16]。只有自举DQN展示了向需要深探索的长链的优雅扩展。
5.2 How does bootstrapped DQN drive deep exploration?
自举DQN以类似于可证明有效算法PSRL[13]的方式进行探索,但它使用自举神经网络来近似价值的后验样本。与PSRL不同,自举DQN直接对价值函数进行采样,因此不需要进一步的规划步骤。该算法类似于RLSVI,RLSVI也被证明是有效的[16],但使用神经网络代替线性价值函数,使用自举代替高斯采样。对线性设置的分析表明,只要分布{Q1, ... , QK}保持随机乐观[16],或者至少与“正确的”后验一样分散,这种非线性方法就会很好地工作。
自举DQN依赖于网络权重的随机初始化作为诱导多样化的先验。令人惊讶的是,我们发现这种最初的多样性足以为大型和深度神经网络保持对新的和看不见的状态的多样性泛化。这对我们的实验环境是有效的,但并不是在所有情况下都有效。一般来说,可能有必要保持一些更严格的“先验”概念,可能通过使用人工先验数据来保持多样性[15]。简单随机初始化有效性的一个潜在解释是,与监督学习或赌博机不同,在监督学习或赌博机中,所有网络都适合相同的数据,我们的每个Qk头都有一个独特的目标网络。这与随机小批量和灵活的非线性表示一起,意味着即使是初始化时的微小差异,也可能随着它们适应独特的TD误差而变得更大。
自举DQN不要求任何单个网络Qk在每一步都被初始化为正确的“右”策略,这对于大型链N来说是不可能的。为了使算法在本例中取得成功,我们只要求网络以不同的方式推广到它们从未在不常访问的状态下选择的动作。想象一下,在上面的例子中,网络已经达到了状态![]() ,但从未观察到动作右a=2。只要一个头k想象
,但从未观察到动作右a=2。只要一个头k想象![]() ,则TD自举可以通过目标网络将该信号传播回s=1,以驱动深探索。正如我们的实验所示,即使对于相对较小的K,这些在n处的估计传播到至少一个头的期望时间在n中也会优雅地增长。我们通过一段视频来扩展这种直觉,该视频旨在强调自举DQN如何展示深探索https://youtu.be/e3KuV_d0EMk。我们在附录C中对一个困难的随机MDP进行了进一步的评估。
,则TD自举可以通过目标网络将该信号传播回s=1,以驱动深探索。正如我们的实验所示,即使对于相对较小的K,这些在n处的估计传播到至少一个头的期望时间在n中也会优雅地增长。我们通过一段视频来扩展这种直觉,该视频旨在强调自举DQN如何展示深探索https://youtu.be/e3KuV_d0EMk。我们在附录C中对一个困难的随机MDP进行了进一步的评估。
2 相比之下,假设智能体因死亡而立即获得少量奖励;抖动策略在解决这个问题上是没有希望的,就像第5节一样。
6 Arcade Learning Environment
我们现在在Arcade学习环境[1]上对49款Atari游戏的算法进行了评估。重要的是,与第5节中的实验不同,这些领域并不是专门为展示我们的算法而设计的。事实上,许多Atari游戏都是结构化的,因此小额奖励总是表明最优策略的一部分。这对于抖动策略所观察到的强大性能可能至关重要2。我们发现,在这种情况下,通过自举DQN进行探索会产生显著的收益,而不是“贪婪”。自举DQN达到与DQN大致相似的峰值性能。然而,我们改进的探索意味着我们在所有游戏中达到人类表现的速度平均快30%。这意味着通过学习显著提高了累积回报。
我们遵循[25]中关于我们的网络架构的设置,并根据他们的算法对我们的性能进行基准测试。我们的网络结构与DQN[12]的卷积结构相同,只是我们在卷积层后拆分了10个单独的自举头,如图1a所示。最近,几位作者对DDQN进行了架构和算法改进[26,18]。我们不将我们的结果与这些结果进行比较,因为它们的进展与我们关注的问题正交,并且可以很容易地结合到我们的自举DQN设计中。我们实验设置的全部细节见附录D。
6.1 Implementing bootstrapped DQN at scale
我们现在研究如何以计算高效的方式为DQN生成在线自举样本。我们关注三个关键问题:我们需要多少头,我们应该如何将梯度传递到共享网络,以及我们应该如何在线自举数据?为了保持与DQN相当的计算成本,我们做出了重大妥协。
图5a显示了在游戏Breakout中,对于不同数量的头K,自举DQN的累积奖励。更多的头可以更快地学习,但即使是少量的头也能获得自举DQN的大部分好处。我们选择K=10。
共享网络架构允许我们通过反向传播来训练这种组合网络。将K个网络头馈送到共享卷积网络有效地增加了网络的这一部分的学习率。在某些游戏中,这会导致过早和次优收敛。我们通过将梯度归一化1/K找到了最好的最终分数,但这也会导致早期学习速度减慢。详见附录D。
为了实现在线自举,我们使用独立的伯努利掩码w1, ... , wK ≥ Ber(p)。这些标志存储在存储器回放缓存中,并识别在哪些数据上训练哪些头3。然而,当使用共享的迷你批次进行训练时,该算法还需要多有效的1/p次迭代;这在计算上是不可取的。令人惊讶的是,我们发现该算法在不考虑p的情况下表现相似,并且都优于DQN,如图5b所示。这很奇怪,我们在附录D中讨论了这一现象。然而,根据Atari的经验观察,我们选择p=1来节省迷你批次传播。因此,自举DQN在相同的硬件上以与普通DQN相似的计算速度运行4。
3 p=0.5是双或无自举[17],p=1是完全没有自举的集成。
4与DQN相比,我们的实现K=10,p=1在时间增加不到20%的情况下运行。
6.2 Efficient exploration in Atari
我们发现,自举DQN在几个Atari游戏中推动了有效的探索。对于相同数量的游戏体验,自举DQN通常优于ε-贪婪探索的DQN。图6展示了不同游戏选择的这种效果。
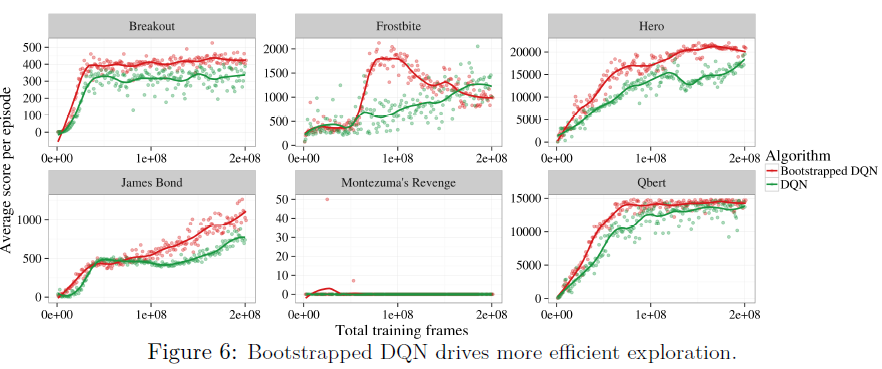
在DQN表现良好的游戏中,自举DQN通常表现更好。自举DQN在Amidar上不能达到人类性能(DQN可以达到),但在Beam Rider和Battle Zone上达到了人类性能(DQN没有)。为了总结这种学习时间的改进,我们考虑了达到人类表现所需的帧数。如果自举DQN在DQN的1/x帧中达到人类性能,我们认为它已经提高了x。图7显示自举DQN通常更快地达到人类性能。
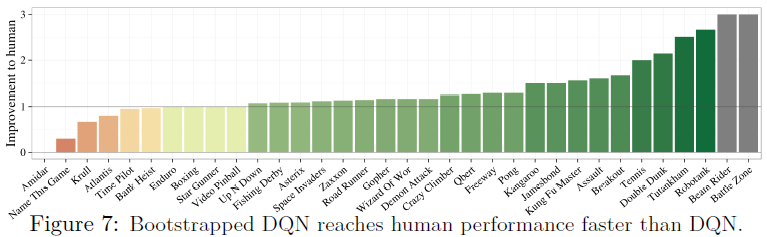
在大多数DQN无法达到人类性能的游戏中,自举DQN本身并不能解决问题。在一些具有挑战性的Atari游戏中,深探索被认为是重要的[25],我们的结果并不完全成功,但仍然很有希望。在Frostbite中,自举DQN比DQN更快地达到第二级,但网络不稳定性会导致性能崩溃。在Montezuma's Revenge中,自举DQN在20M帧后到达第一个关键点(即使在200M帧后,DQN也从未观察到奖励),但没有从这次经验中正确地学习5。我们的研究结果表明,改进的探索可能有助于解决这些剩余的游戏,但也突出了其他问题的重要性,如网络不稳定、奖励削减和时间延长奖励。
6.3 Overall performance
自举DQN的学习速度比DQN快得多。图8显示,在大多数游戏中,自举DQN也会提高最终得分。然而,高效探索的真正好处意味着,就学习的累积奖励而言,自举DQN比DQN高出几个数量级(图9)。在这两张图中,我们将性能相对于完全随机策略进行了归一化。与我们最相似的工作提出了其他几种改进Atari探索的方法[20],它们针对AUC-20进行了优化,AUC-20是20M帧后累积回报的归一化版本。根据他们在他们考虑的14个游戏中的平均度量,我们改进了基本DQN(0.29)和他们的最佳方法(0.37),通过自举DQN获得0.62。我们在附录D.4中列出了这些结果以及所有49个游戏的结果表。
6.4 Visualizing bootstrapped DQN
我们现在提供了更多关于自举DQN如何推动Atari深度探索的见解。在每个游戏中,尽管每个头部Q1, ... , Q10学习了一个高分策略,他们发现的策略非常不同。在视频https://youtu.be/Zm2KoT82O_M中我们同时展示了几个游戏中这些策略的演变。尽管每个头的表现都很好,但他们每个人都遵循一个独特的策略。相比之下,ε-贪婪策略对于较小的ε值几乎无法区分,而对于较大的ε值则完全无效。我们相信,这种深探索是改进学习的关键,因为多样化的经验可以更好地泛化。
抛开探索不谈,自举DQN作为一种纯粹的开发政策可能是有益的。我们可以将所有的头组合成一个单一的集成策略,例如,通过选择头投票最多的动作。这种方法可能有几个好处。首先,我们发现集成策略往往优于任何单个政策。其次,选票在头之间的分布,以衡量最优策略的不确定性。与普通DQN不同,自举DQN可以知道它不知道的东西。在一个应用程序中,执行一个不太了解的操作是危险的,这可能是至关重要的。在视频https://youtu.be/0jvEcC5JvGY中我们在几个游戏中看到了这种集成策略。我们发现,这项策略中的不确定性是可以令人惊讶地解释的:所有头在明显关键的决策点上都达成了一致,但在其他不太重要的步骤上仍然存在差异。
7 Closing remarks
在本文中,我们提出了自举DQN作为一种在复杂环境中进行有效强化学习的算法。我们证明了自举可以为深度神经网络产生有用的不确定性估计。自举DQN在计算上是可处理的,并且自然地可扩展到大规模并行系统。我们相信,除了我们的具体实现之外,随机化价值函数代表了一种很有前途的替代抖动的探索方法。自举DQN实际上结合了对复杂非线性价值函数的有效推广和探索。
APPENDICES
A Uncertainty for neural networks
在本附录中,我们讨论了一些实验设置,以定性评估深度神经网络的不确定性方法。为此,我们生成了二十个噪声回归对xi,yi,其中:
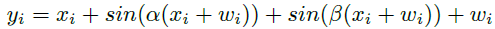
其中,xi从(0, 0.6) ∪ (0.8, 1)均匀抽取,并且wi ~ N(μ=0, σ2=0.032)。我们设置α=4和β=13。这些数值选择都不重要,只是代表了一个高度非线性的函数,它有很多噪声和几个我们应该不确定的清晰区域。我们在图10中展示了回归数据以及生成分布的指示。
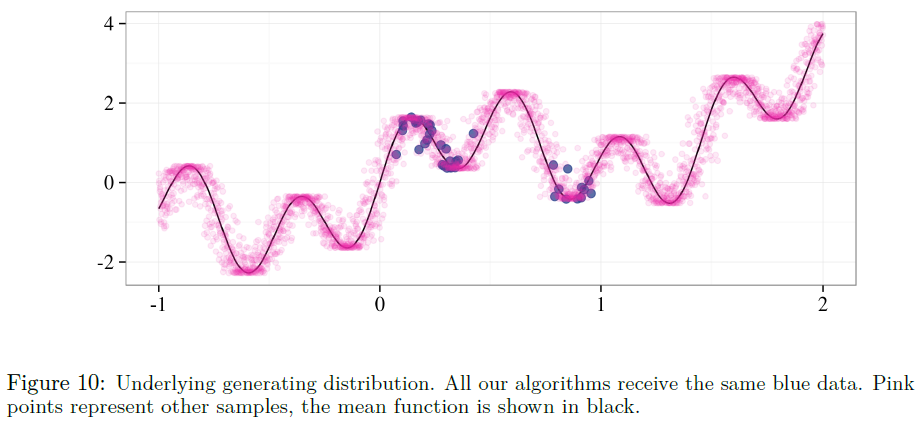
有趣的是,我们没有发现使用dropout为这项任务产生令人满意的置信区间。我们在图11a中给出了这种dropout后验估计的一个例子。
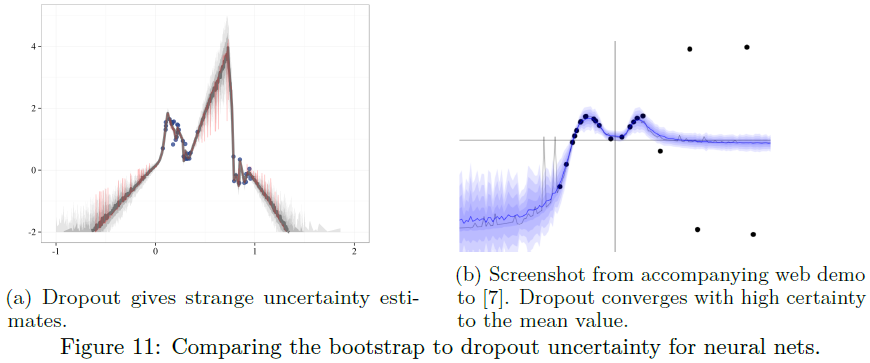
由于几个原因,这些结果不令人满意。首先,对于x=0.75,网络推断出任何实际数据范围之外的后验均值。我们认为这是因为与自举不同,dropout只会从单个神经网络拟合中局部扰动。其次,来自dropout近似的后验样本非常尖锐,看起来不像任何合理的后验采样。第三,在有数据的地区,网络崩溃到几乎为零的不确定性。
我们花了一些时间修改我们的dropout方案来修复这种影响,这对于随机域来说可能是不可取的,我们认为这可能是我们实现的一个假象。然而,经过进一步的思考,我们相信这是一种效果,你会期望dropout后验近似。在图11b中,我们展示了一个取自作者网站[7]的教学示例。
在图的右侧,我们生成了具有大不相同值的噪声数据。使用MSE准则训练神经网络意味着该网络肯定会收敛到噪声数据的均值。任何dropout样本都高度集中在这个均值附近。相比之下,自举神经网络可能包括这些噪声数据的不同子集,因此可能会为我们的设置产生更直观的不确定性估计。请注意,这不一定是近似高斯过程后验的失败,但这种伪影可以由任何同基方差后验共享。[7]的作者提出了一种异方差变体,它可以提供帮助,但不能解决基本问题,即对于训练为收敛的大型网络,所有dropout样本都可能收敛到每个数据点...甚至是异常值。
这一观察结果是另一个更本质的缺陷的关键,即朴素的dropout是深度学习中不确定性的代表。先前的分析认为,dropout是结果p(y)[7]后验分布的变分近似,但它并没有区分风险(模型中固有的随机性)和不确定性(模型参数应用的混乱)。对于Thompson抽样,重要的是只对期望回报的不确定性进行采样,而不是对随机奖励的实现进行采样。从某种角度来看,自举和dropout并没有什么不同。自举可以被视为一种依赖于数据的dropout,其中每个数据点唯一地确定一个掩码(我们称之为自举掩码)。我们的实现考虑了自举掩码,它在convnet中完全共享参数,在头部中完全不同,但我们可能会考虑其他更通用的自举掩码。探索这些想法的变化是未来研究的一个有趣话题。
在本文中,我们重点研究了神经网络不确定性的自举方法。我们喜欢它的简单性、与既定统计方法的联系以及实证的良好表现。然而,本文的关键见解是通过随机化价值函数进行深探索。这与深度神经网络的任何近似后验估计器都是兼容的。我们相信,神经网络的这一不确定性估计领域本身仍然是一个重要的研究领域。
Q值函数的自举不确定性估计比监督问题中没有出现的dropout具有另一个关键优势。与针对随机目标网络训练的随机dropout掩码不同,我们的自举DQN实现针对其自身的时间一致的目标网络进行训练。这意味着我们的自举估计(在[5]的意义上)能够“自举”(在[22]的TD意义上)对其自己的长期价值估计。这对于量化Q的长期不确定性和推动深探索非常重要。
B Bootstrapped DQN implementation
算法1给出了自举DQN的完整描述。它捕获了两种操作模式,其中使用k个神经网络来估计Qk值函数,或者使用一个具有k个头的神经网络来评估k个Q值函数。在这两种情况下,由于这在很大程度上是一个参数化问题,我们将价值函数网络表示为Q,其中Qk是第k个网络或第k个头的输出。
全自举DQN算法的核心思想是自举掩码mt。对于每个价值函数Qk,掩码mt决定它是否应该根据在步骤 t 生成的经验进行训练。在其最简单的形式中,mt是长度为K的二值向量,屏蔽或包括用于在经验的该时间步骤上训练的每个价值函数(即,它是否应该从对应的(st, at, rt+1, st+1, mt)元组接收梯度)。掩码分布M负责生成每个mt。例如,当M产生mt时,其分量是从参数为0.5的伯努利分布中独立提取的,则这对应于双或无(double-or-nothing)自举[17]。另一方面,如果M产生所有值为1的掩码mt,则该算法简化为集成方法。Poisson掩码Mt[k] ~ Poi(1)提供了与标准非参数自举最自然的平行,因为当![]() ,Bin(N, 1/N) → Poi(1)。指数掩码Mt[k] ~ Exp(1)非常类似于Dirichlet过程的标准贝叶斯非参数后验[15]。
,Bin(N, 1/N) → Poi(1)。指数掩码Mt[k] ~ Exp(1)非常类似于Dirichlet过程的标准贝叶斯非参数后验[15]。

周期性地,回放缓存被重放以更新价值函数网络Q的参数。回放缓存B中的第 t 个元组的第k个价值函数Qk的梯度,![]() 为:
为:
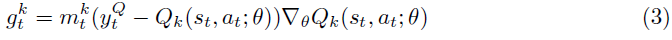
其中![]() 由(2)给出。请注意,掩码
由(2)给出。请注意,掩码![]() 调节梯度,从而产生自举行为。
调节梯度,从而产生自举行为。
C Experiments for deep exploration
C.1 Bootstrap methodology
C.2 A difficult stochastic MDP
C.3 One-hot features
D Experiments for Atari
我们在实验中使用了与[12]相同的49个Atari游戏。智能体的每一步都对应于模拟器的四个步骤,其中相同动作被重复,智能体的奖励值在-1和1之间进行剪裁以保持稳定性。我们评估我们的智能体,并根据原始分数报告性能。
所使用的网络的卷积部分与[12]中使用的部分相同。网络的输入是4x84x84张量,具有最后四个观测值的重新缩放的灰度版本。第一卷积(conv)层具有32个大小为8、步长为4的滤波器。第二conv层具有64个大小为4、步长为2的滤波器。最后一个conv层具有64个尺寸为3的滤波器。我们将最终层之外的网络划分为K=10个不同的头,每个头都是全连接的,并且与DQN的单个头相同[12]。这包括一个与512个单元全连接的层,然后是与每个动作的Q值全连接的另一层。全连接层都使用整流线性单元(ReLU)作为非线性。我们对从每个头部流出的1/K梯度进行归一化。
我们用RMSProp训练网络,动量为0.95,学习率为0.00025,如[12]所示。折扣设置为γ=0.99,目标更新之间的步数设置为τ=10000。我们训练智能体每个游戏总共50M步,相当于200M帧。智能体每1M帧一次,为了在自举DQN中进行评估,我们使用集合投票策略。经验回放包含1M的最新转换。我们通过随机采样32的迷你批次从回放缓存转换为使用与DQN完全相同的迷你批次时间表。对于训练,我们使用了一种ε-贪婪策略,在前1M的时间步骤内从1到0.01线性退火。
D.1 Experimental setup
D.2 Gradient normalization in bootstrap heads
D.3 Sharing data in bootstrap heads
D.4 Results tables



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律