Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Frontiers in neuroscience, 2017, 11: 682
Abstract
脉冲神经网络(SNN)可能提供一种有效的推理方式,因为网络中的神经元很少被激活,计算是由事件驱动的。先前的工作表明,简单的连续值深度卷积神经网络(CNN)可以转换为精确的脉冲等价体。这些网络不包括某些常见操作,如最大池、softmax、批处理归一化和Inception模块。本文介绍了这些操作的脉冲等价体,从而允许转换几乎任意的CNN架构。我们展示了流行的CNN架构(包括VGG-16和Inception-v3)到SNN的转换,这些SNN产生了迄今为止在MNIST、CIFAR-10和具有挑战性的ImageNet数据集上报告的最佳结果。SNN可以根据可用操作的数量来权衡分类错误率,而深度连续值神经网络需要固定数量的操作来实现其分类错误率。从用于MNIST的LeNet和用于CIFAR-10的BinaryNet的示例中,我们发现,错误率增加几个百分点后,SNN可以实现比原始CN减少2倍以上的操作。这突出了SNN的潜力,尤其是当SNN部署在用于嵌入式应用的高效神经形态脉冲神经元芯片上时。
Keywords: artificial neural network, spiking neural network, deep learning, object classification, deep networks, spiking network conversion
1. INTRODUCTION
2. METHODS
2.1. Theory for Conversion of ANNs into SNNs
2.1.1. Membrane Equation
2.1.2. Firing Rates in Higher Layers
2.2. Spiking Implementations of ANN Operators
在本节中,我们介绍了改进深度SNN分类错误率的新方法(Rueckauer等人,2016)。这些方法要么允许更宽范围的ANN转换,要么减少SNN中的近似误差。
2.2.1. Converting Biases
偏差在ANN中是标准的,但之前的SNN转换方法明确排除了偏差。在脉冲网络中,偏差可以简单地以相同符号的恒定输入电流来实现。或者,如Neftci等人(2014)所提出的,可以用与ANN偏差成比例的恒定发放率的外部脉冲输入来呈现偏差,但随后可能必须反转脉冲的符号以说明负偏差。第2.1节中的理论可以应用于具有偏差的神经元的情况,下面的第2.2.2节显示了参数归一化如何也可以应用于偏差。
2.2.2. Parameter Normalization
近似误差的一个来源是,在SNN的时间步进模拟中,神经元被限制在[0, rmax]的发放率范围内,而ANN通常没有这样的约束。Diehl等人(2015)引入了权重归一化作为避免由于过低或过高的发放而导致的近似误差的方法。这项工作表明,通过使用基于数据的权重归一化机制,转换后的SNN的性能显著提高。我们将此方法扩展到具有偏差的神经元的情况,并提出了一种使归一化过程对异常值更加鲁棒的方法。
2.2.2.1. Normalization with biases
基于数据的权重归一化机制基于用于ANN的ReLU单元的线性。通过线性重新缩放所有权重和偏差,可以简单地将其扩展到偏差,使得对于所有训练示例,ANN激活a [如公式(1)中计算的] 小于1。为了保存层内编码的信息,需要对层的参数进行联合缩放。将层 l 中的最大ReLU激活表示为λl = max[al],然后将权重Wl和偏差bl归一化为![]() 和
和![]() 。
。
2.2.2.2. Robust normalization
虽然权重归一化避免了SNN中的发放率饱和,但它可能会导致非常低的发放率,从而增加信息到达更高层之前的延迟。我们将上一段中描述的算法称为“最大范数”,因为归一化因子λl被设置为层内的最大ANN激活,其中激活是使用训练数据的一个子集计算的。这是一种非常保守的方法,可以确保SNN的发放率很可能不会超过最大发放率。缺点是,该程序容易受到导致非常高激活的异常值样本的影响,而对于剩余的大多数样本,发放率将保持显著低于最大发放率。
如图1A所示,这种异常值并不罕见,它描绘了16666个CIFAR10样本的第一个卷积层中所有非零激活的对数尺度分布。观察到的最大激活比99.9百分位数高出三倍以上。图1B显示了同一层中所有ANN单元的16666个样本中最高激活的分布,揭示了数据集中的巨大差异,以及远离绝对最大值的峰值。这种分布解释了为什么按最大值进行归一化会导致SNN的潜在较差分类性能。对于绝大多数输入样本,即使是层内单元的最大激活也将远远低于所选的归一化尺度,这导致层内的发放不足以驱动更高的层,随后导致更差的分类结果。
我们提出了一个更稳健的替代方案,其中我们将λl设置为第 l 层总活动分布的第p百分位4。这种选择丢弃了极端异常值,并增加了更大比例样本的SNN发放率。潜在的缺点是,一小部分神经元会饱和,因此选择归一化尺度需要在饱和和发放不足之间进行权衡。在下文中,我们将百分位p称为“归一化尺度”,并注意到“最大范数”方法在特殊情况下恢复为p=100。表现良好的p的典型值在[99.0, 99.999]的范围内。通常,与发放率太低的情况相比,一小部分神经元的饱和会导致网络分类错误率的降低。该方法可以与ANN训练期间使用的批归一化(BN)相结合(Ioffe和Szegedy, 2015),这将归一化每一层中的激活,因此产生较少的极端异常值。
2.2.3. Conversion of Batch-Normalization Layers
批归一化减少了ANN中的内部协变移位,从而加快了训练过程。BN引入了额外的层,其中执行输入的仿射变换以实现零均值和单位方差。输入x被转换为![]() ,其中均值μ、方差σ以及两个学习参数β和γ都是在训练期间获得的,如Ioffe和Szegdy(2015)所述。在训练之后,这些变换可以被集成到权重向量中,从而保持BN的效果,但不需要在推断期间重复计算每个样本的归一化。具体而言,我们设置了
,其中均值μ、方差σ以及两个学习参数β和γ都是在训练期间获得的,如Ioffe和Szegdy(2015)所述。在训练之后,这些变换可以被集成到权重向量中,从而保持BN的效果,但不需要在推断期间重复计算每个样本的归一化。具体而言,我们设置了![]() 和
和![]() 。这使得将BN层转换为SNN变得简单,因为在转换前一层的权重之后,不需要对BN层进行额外的转换。根据经验,我们发现当BN参数集成到其他权重中时,转换损失较小。如果在训练过程中使用BN,其优势纯粹在于获得性能更好的ANN。
。这使得将BN层转换为SNN变得简单,因为在转换前一层的权重之后,不需要对BN层进行额外的转换。根据经验,我们发现当BN参数集成到其他权重中时,转换损失较小。如果在训练过程中使用BN,其优势纯粹在于获得性能更好的ANN。
2.2.4. Analog Input to First Hidden Layer
由于基于事件的基准数据集很少(Hu等人,2016年;Rueckauer和Delbruck,2016年),传统的基于帧的图像数据库,如MNIST(LeCun等人,1998年)或CIFAR(Krizhevsky,2009年)已用于评估转换SNN的分类错误率。先前的方法(Cao等人,2015;Diehl等人,2015)通常将模拟输入激活(例如灰度级或RGB值)转换为泊松发放率。但这种转换给网络的启动带来了可变性,并削弱了网络的性能。
这里,我们将模拟输入激活解释为恒定电流。根据公式(2),通过将相应的核与模拟输入图像x相乘来获得对第一隐藏层中的神经元的输入:
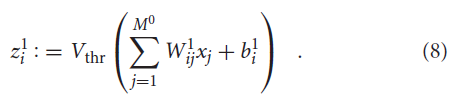
这导致每个神经元 i 有一个恒定的电荷值![]() ,在每个时间步骤将其加到膜电位上。然后,脉冲输出从第一个隐藏层开始。根据经验,我们发现这在神经网络单元的低激活状态下尤其有效,在这种情况下,脉冲神经元的采样不足通常会对成功转换构成挑战。
,在每个时间步骤将其加到膜电位上。然后,脉冲输出从第一个隐藏层开始。根据经验,我们发现这在神经网络单元的低激活状态下尤其有效,在这种情况下,脉冲神经元的采样不足通常会对成功转换构成挑战。
2.2.5. Spiking Softmax
Softmax通常用于深度ANN的输出,因为它会导致归一化和严格正的类似然。以前的ANN到SNN转换方法没有转换softmax层,只是简单地预测了与在刺激呈现过程中出现最多脉冲的神经元对应的输出类别。然而,当最后一层中的所有神经元都接收到负输入时,这种方法就失败了,因此永远不会出现脉冲。
在这里,我们实现了两个版本的脉冲softmax层。第一种是基于Nessler等人(2009)提出的机制,其中输出脉冲由具有固定发放率的外部泊松发生器触发。脉冲神经元不会自己发放,而是简单地积累输入。当外部发生器确定应该产生脉冲时,根据累积的膜电位进行softmax竞争。我们的脉冲softmax函数的第二个变体类似,但不依赖外部时钟。为了确定一个神经元是否应该发放脉冲,我们计算膜电位的softmax值,并使用[0,1]范围内的所得值作为每个神经元泊松过程中的发放率参数。在这两种变体中,刺激呈现过程中的最终分类结果由具有最高发放率的神经元的指数给出,如前所述。我们更喜欢第二种变体,因为它不依赖于额外的超参数。一位评审员提出了第三种变体:由于softmax应用于网络的最后一层,因此可以简单地从基于膜电位计算的softmax推断分类输出,而无需另一种脉冲生成机制。这种简化可以加快推理时间,并可能通过减少随机性来提高准确性。这种方法很有吸引力,因为人们并不坚持使用纯脉冲网络。
2.2.6. Spiking Max-Pooling Layers
大多数成功的ANN使用最大池来空间向下采样特征图。然而,这还没有在SNN中使用,因为用脉冲神经元计算最大值是不平凡的。相反,Cao等人(2015)和Diehl等人(2015)使用了简单的平均池,导致在转换之前训练较弱的ANN。正如Cao等人(2015)所建议的,横向抑制不能正确完成任务,因为它只选择获胜者,而不是实际的最大发放率。另一个建议是使用基于时间到第一个脉冲编码的时序赢家通吃,其中第一个发放的神经元被认为是最大发放的神经元(Masquelier和Thorpe,2007;Orchard等人,2015b)。在这里,我们提出了一种脉冲最大池的简单机制,其中输出单元包含选通函数,该函数只允许来自最大发放神经元的脉冲通过,而丢弃来自其他神经元的脉冲。门控功能通过计算突触前发放率的估计来控制,例如通过计算这些率的在线或指数加权平均值。在实践中,我们发现了几种方法可以很好地工作,但仅展示了使用有限脉冲响应滤波器来控制门控函数的结果。
2.3. Counting Operations
3. RESULTS
3.1. Contribution of Improved ANN Architectures
3.2. Contribution of Improved SNN Conversion Methods
3.3. ImageNet
3.3.1. Transient Dynamics and Voltage Clamp
3.4. Combination with Low-Precision Models
4. DISCUSSION


 浙公网安备 33010602011771号
浙公网安备 33010602011771号