Training Spiking Neural Networks with Local Tandem Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

36th Conference on Neural Information Processing Systems (NeurIPS 2022)
Abstract
脉冲神经网络(SNN)被证明在生物学上比它们的前辈更合理,更节能。然而,对于深度SNN,特别是对于在模拟计算基底上的部署,缺乏有效且通用的训练方法。在本文中,我们提出了一种广义学习规则,称为局部串联学习(Local Tandem Learning,LTL)。LTL规则遵循教师-学生学习方法,通过模拟预先训练的ANN的中间特征表示。通过对网络层的学习进行解耦并利用高度信息的监督信号,我们在CIFAR-10数据集上展示了五个训练阶段内的快速网络收敛,同时具有低计算复杂性。我们的实验结果还表明,这样训练的SNN可以在CIFAR-10、CIFAR-100和Tiny ImageNet数据集上获得与其教师ANN相当的精度。此外,所提出的LTL规则是硬件友好的。它可以很容易地在芯片上实现,以执行快速参数校准,并针对臭名昭著的设备非理想性问题提供鲁棒性。因此,它为在超低功率混合信号神经形态计算芯片上训练和部署SNN提供了无数机会。
1 Introduction
在过去十年中,人工神经网络(ANN)飞跃性地提高了机器的感知和认知能力,并成为许多模式识别任务的事实标准,包括计算机视觉[30、35、52、53、62]、语音处理[39、60]、语言理解[3]和机器人[51]。尽管ANN具有优异的性能,但由于高内存和计算要求,在无处不在的移动和边缘计算设备上部署ANN在计算上非常昂贵。
脉冲神经网络(SNN)是第三代人工神经网络,由于其更大的生物学合理性和实现生物神经网络中观察到的超低功耗计算的潜力,已获得越来越多的研究关注。利用稀疏、脉冲驱动的计算和细粒度并行性,支持SNN高效推理的TrueNorth[2]、Loihi[11]和Tijic[42]等全数字神经形态计算(NC)芯片确实证明了比基于GPU的AI解决方案提高了数量级的功效。此外,新兴的现场混合信号NC芯片[47,54],通过新兴的非易失性技术实现,可以比上述数字芯片进一步提高硬件效率。
尽管神经形态硬件开发取得了显著进展,但如何高效地训练核心计算模型——脉冲神经网络仍然是一个具有挑战性的研究课题。因此,它阻碍了高效神经形态训练芯片的开发以及主流人工智能应用中神经形态解决方案的广泛采用。现有的深度SNN训练算法可分为两类:ANN-SNN转换和基于梯度的直接训练。
对于ANN到SNN的转换方法,他们建议复用来自更容易训练的ANN的网络权重。这可以被视为教师-学生(T-S)学习的具体示例,其以网络权重的形式将知识从教师ANN传递到学生SNN。通过正确确定SNN的神经元发放阈值和初始膜电位,最近的研究表明,ANN的激活值可以与脉冲神经元的发放率很好地接近,在许多具有挑战性的AI基准上实现了近乎无损的网络转换[4,5,7,12,14,21,22,34,46,49,63]。然而,这些网络转换方法仅基于IF神经元模型开发,并且通常需要大的时间窗口以达到可靠的发放率近似值。因此,将这些转换的SNN部署到现有的神经形态芯片上并不简单且有效。
在另一种研究中,基于梯度的直接训练方法将每个脉冲神经元明确建模为自循环神经网络,并利用经典的时间反向传播(BPTT)算法来优化网络参数。在误差反向传播期间,不可微脉冲激活函数通常被连续替代梯度(SG)函数绕过[8,15,38,45,50,58,59,61]。尽管它们与基于事件的输入和不同的脉冲神经元模型兼容,但实际上它们的计算和记忆效率很低。此外,这些SG函数引入的梯度近似误差倾向于在层上累积,在面对深度网络结构和短时间窗口时导致性能显著下降[57]。
通常,SNN学习算法可分为芯片外学习[16,64]和芯片内学习[9,41,43]。上面讨论的几乎所有直接SNN训练方法都属于芯片外学习类别。由于缺乏有效的方法来利用脉冲活动中的高度稀疏性,并且需要存储用于信度分配的非本地信息,这些芯片外方法显示出非常低的训练效率。此外,由于众所周知的设备非理想性问题[6],实际的网络动态将偏离芯片外模拟的网络动态,导致芯片外训练的SNN在部署到模拟计算基板上时精度显著下降[1,24,37,44]。为了解决这些问题,最近的工作提出了局部Hebbian学习[11,28,41]和基于梯度的学习近似[10,19,32,40]形式的片上学习算法,而这些算法的有效性仅在简单的基准上得到了证明,例如MNIST和N-MNIST数据集。
为了解决SNN训练和硬件部署中的上述问题,我们在本文中提出了一种广义SNN学习规则,我们称之为局部串联学习(LTL)规则。LTL规则充分利用了ANN-SNN转换和基于梯度的训练方法。一方面,它很好地利用ANN的高效中间特征表示来监督SNN的训练。通过这样做,我们表明它可以在CIFAR-10数据集上的五个训练阶段内以低计算复杂性实现快速网络收敛。另一方面,LTL规则采用基于梯度的方法进行知识转移,可以支持不同的神经元模型并实现快速模式识别。通过在层内局部传播梯度信息,它还可以减轻SG方法的复合梯度近似误差,并在CIFAR-10、CIFAR-100和Tiny ImageNet数据集上实现近乎无损的知识传输。此外,LTL规则被设计为硬件友好的,它可以仅使用本地信息执行高效的片上学习。在这种片上设置下,我们证明了LTL规则能够解决模拟计算基底的臭名昭著的设备非理想性问题,包括设备失配、量化噪声、热噪声和神经元沉默。
2 Methods
2.1 Spiking Neuron Model

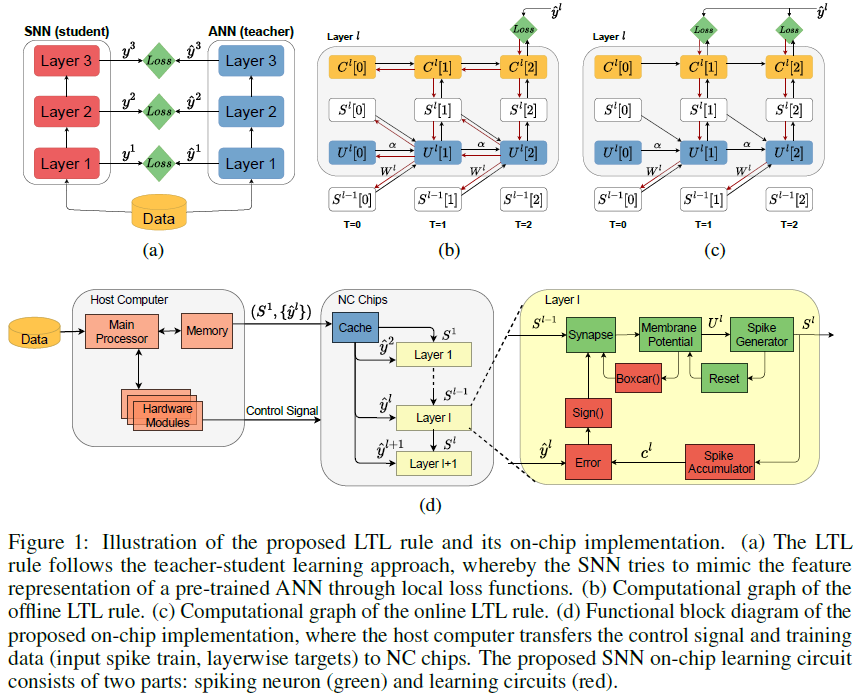
2.2 Local Tandem Learning
如图1(a)所示,LTL规则遵循T-S学习方法[20],由此预训练ANN的中间特征表示通过逐层局部损失函数传递到SNN。与ANN到SNN的转换方法相比,我们在神经元层面而不是突触层面建立了特征表示等价性,这为选择SNN中使用的任何神经元模型提供了灵活性。另一方面,利用所提出的空间局部损失函数,我们简化了端到端直接训练方法中所需的时空信度分配,这可以显著提高网络收敛速度,同时降低计算复杂性。在下文中,我们介绍了LTL规则的两个版本,离线和在线,这取决于是否施加了时间局部性约束。
Offline Learning 遵循T-S学习方法,我们将预训练神经网络的中间特征表示作为知识,并训练SNN以通过分层损失函数重现等效特征表示。特别地,我们在ANN的归一化激活值和SNN的全局平均发放率之间建立了等价性。为了减少这两个量之间的差异,我们采用均方误差(MSE)损失函数,并将其分别应用于每一层。因此,对于任何层 l,局部损失函数Ll定义如下:
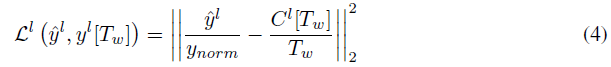
其中![]() 是ANN层的输出。ynorm是一个归一化常数,其取值为所有
是ANN层的输出。ynorm是一个归一化常数,其取值为所有![]() 的99th或99.9th百分位数。与使用最大激活值相比,这可以减轻异常值的影响[48]。Tw是时间窗口大小。
的99th或99.9th百分位数。与使用最大激活值相比,这可以减轻异常值的影响[48]。Tw是时间窗口大小。![]() 是总脉冲计数。PS:在具体实现中,
是总脉冲计数。PS:在具体实现中,![]() 会截断至[0,1]。
会截断至[0,1]。
如图1(b)所示的计算图,我们采用BPTT算法来解决时间信度分配问题,权重梯度可以被导出为:
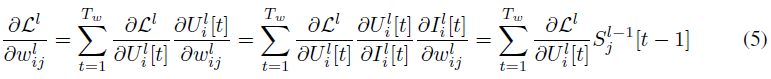
并且
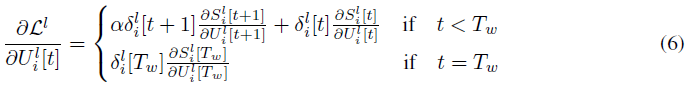
其中
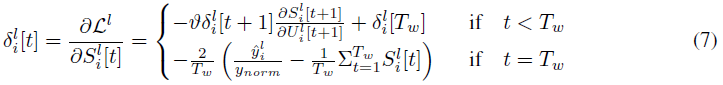
为了解决不可微脉冲激活函数的问题,我们应用了替代梯度方法,即Θ'(x) ≈ θ'(x)。具体来说,我们采用boxcar函数作为θ'(x),以支持方便高效的片上实现。
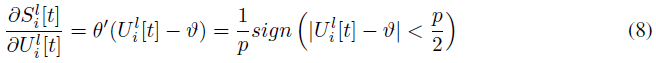
其中p控制允许梯度通过的膜电位范围,我们针对每个数据集分别调整该超参数。通过将公式(8)代入公式(6)和(7),我们可以得出最终形式的权重梯度,并且我们可以根据随机梯度下降方法或其自适应变体来更新权重。有关权重和偏差项的梯度的更详细推导,请参见补充材料第A.1节。
Online Learning 离线LTL规则要求存储中间突触和膜状态变量,以便在误差反向传播期间使用,这对于内存资源有限的芯片上学习是禁止的。为了解决这个问题,我们引入了一个在线LTL规则,其损失函数被设计为在空间和时间上都是局部的。为了实现时间局部性,我们使用可以在每个时间步骤计算的移动平均发放率来代替公式(4)中使用的全局发放率。因此,它产生以下局部损失函数:

与离线版本相比,梯度更新现在要简单得多:
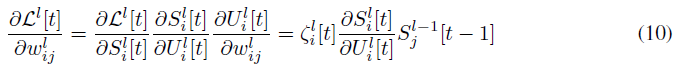
其中![]() 可以直接从公式(9)计算:
可以直接从公式(9)计算:

在线LTL规则的计算图如图1(c)所示。值得注意的是,发放率计算的前几个时间步骤相对带噪。然而,通过将前几个步骤视为预热期,可以很容易地解决这个问题,在此期间不允许参数更新(有关预热期影响的研究,请参见补充材料第C节)。通过这样做,还可以降低总体训练成本。如第3.1节和第3.4节所述,该在线版本可以显著降低计算复杂性,同时实现与离线版本相当的测试精度。
On-chip Implementation 为了方便高效地在芯片上实现所提出的在线LTL规则,我们仔细设计了学习电路,如图1(d)所示。在脉冲累加器处更新输出脉冲计数Cl,并根据公式(9)中定义的分层损失函数将其与本地目标值进行比较。该误差项进一步反馈给神经元以更新突触参数。注意,突触更新由sign(·)和boxcar(·)函数门控,这可以显著减少参数更新的总数。
我们想强调的是,与最近引入的硬件在环(HIL)训练方法相比,所提出的LTL学习规则对硬件更友好[10,19]。HIL训练方法需要双向信息通信,即(1)从NC芯片向主机读取中间神经元状态以执行芯片外训练,以及(2)从主机向NC芯片写入更新的权重。考虑到这两个过程的顺序性以及读取神经元状态的高实现成本(例如,需要为模拟脉冲神经元实现昂贵的模数转换器),HIL训练方法在实践中部署起来很昂贵。
相反,LTL训练规则可以通过同时从在主机上运行的ANN中提取数据批i+1的分层目标并对数据批 i 执行片上SNN训练而在芯片上有效地实现。这与传统的ANN训练类似,其中在CPU上执行下一数据批的数据预处理,同时将当前数据批用于GPU上的ANN训练。唯一的区别是,输入数据由预训练的ANN预处理,以提取所提出的LTL规则的中间层目标。由于ANN的推理可以在主机上并行执行,因此整个训练时间受到以顺序模式运行的NC芯片的限制,在这种模式下,一次只处理一个样本。因此,我们的方法具有更低的硬件和时间复杂性。
3 Experiments
在本节中,我们使用CIFAR-10[29]、CIFAR-100[29]和Tiny ImageNet[55]数据集评估了所提出的LTL规则在图像分类任务中的有效性。我们进行了全面的研究,以证明其在以下方面的优势:1. 准确、快速、高效的模式识别;2. 具有低计算复杂度的快速网络收敛;3. 提供对硬件相关噪声的鲁棒性。有关实验数据集和实现细节的更多信息,请参见补充材料B部分,源代码可在2找到。
2 https://github.com/Aries231/Local_tandem_learning_rule
3.1 Accurate and Scalable Image Classification
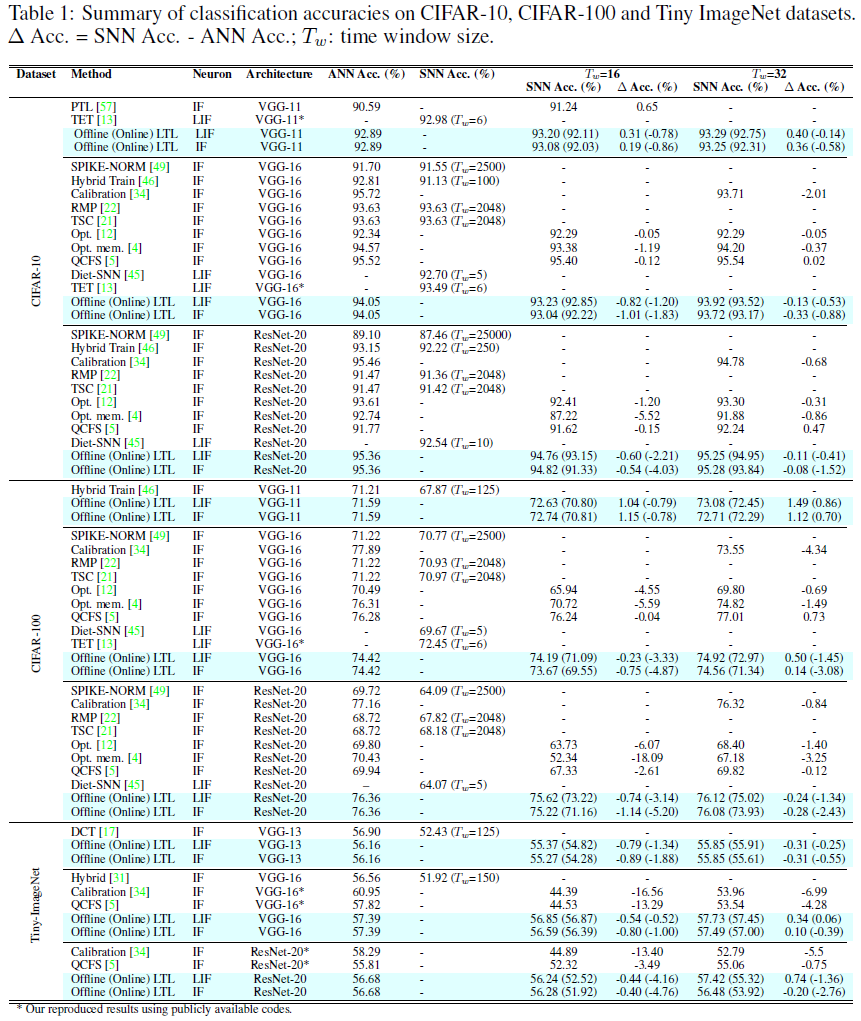
在此,我们根据其他SNN学习规则,包括ANN到SNN的转换[4,5,12,17,21,22,31,34,46,49,57]和直接SNN训练[13,45]方法,报告了CIFAR-10、CIFAR-100和Tiny ImageNet数据集上LTL训练SNN的分类结果。鉴于网络架构和数据准备过程在不同的工作中略有不同,因此,无论何时数据可用,我们都将重点讨论ANN和SNN之间的转换误差。
在CIFAR-10数据集上,如表1所示,我们的LTL离线训练脉冲VGG-11在Tw=16时超过了教师ANN的准确性,这一结果表明,所提出的T-S学习方法在通过本地目标传递知识方面具有很高的效率。此外,LTL规则可以利用提供更大表征能力的更大时间窗口,并进一步提高SNN在Tw=32时的性能。还值得一提的是,通过以可学习的方式传递知识,所提出的LTL规则与不同的神经元模型兼容,通过IF和LIF神经元模型实现的高精度来证明。
尽管与离线版本相比略有下降,但在线训练的SNN仍然可以获得与其教师模型相当的结果,准确率下降不到1%,这表明去除时间步骤之间的时间依赖性对SNN的训练几乎没有影响(关于为什么在线LTL规则可以像离线版本一样有效地执行的详细研究,请参见第D节)。
对于VGG-16模型,我们注意到与教师模型相比,准确度下降了1%以上,这可以通过复合分层表示误差来解释。幸运的是,这样的误差可以用更大的时间窗口很好地解决。具体而言,在Tw=32时,在离线训练设置下,LIF和IF神经元模型与教师ANN的准确度差距分别缩小到0.13%和0.33%。当与其他SOTA学习算法相比时,所提出的LTL规则在最终SNN模型精度和ANN模型的精度下降方面都可以实现类似的性能。同样的结论也可以从CIFAR-100和Tiny ImageNet数据集的结果中得出,因此,所提出的LTL规则是构建高性能SNN的一种通用、可扩展且高效的方法。
3.2 Rapid and Efficient Pattern Recognition
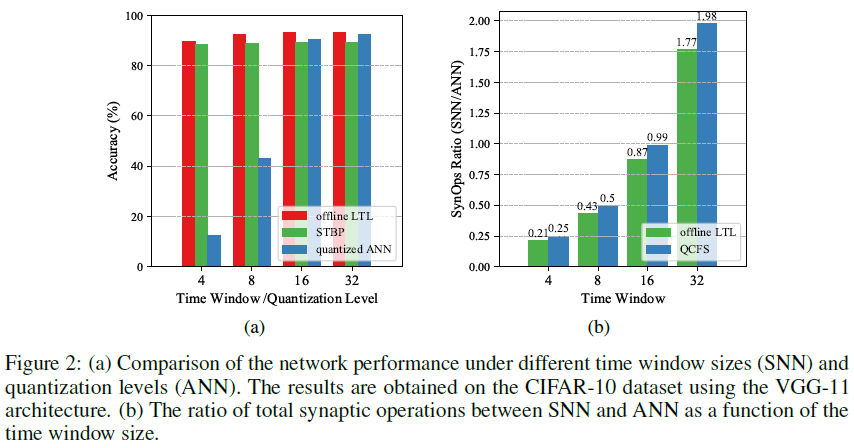
为了实现作为解决模式识别任务的主流ANN的高效替代方案的目标,SNN应该以低发放率进行准确和快速的预测。在此,我们研究所提出的LTL规则是否能够训练能够应对短时间窗口的SNN。具体而言,我们设计了在训练期间将时间窗口Tw从4逐渐增加到32的实验,并将离线LTL规则与CIFAR-10数据集上的STBP[58]学习规则进行了比较。为了确保公平比较,我们使用具有相同实验设置的VGG-11架构,除了LTL规则使用局部目标,STBP规则使用全局目标。我们注意到,SNN的离散神经表示等同于具有量化激活值的ANN[57]。因此,我们还将我们的结果与通过量化感知训练获得的量化ANN进行比较[25]。
如图2(a)所示,我们观察到,当总量化水平低于16时,量化ANN的精度迅速下降,而LTL和STBP训练的SNN即使在Tw=4时也能保持高精度。这表明SNN训练中采用的替代梯度方法在解决激活函数中的不连续性方面可以优于朴素直通估计器[25]。此外,离线LTL规则比STBP规则表现得更好,这可以通过如下事实来解释:替代梯度函数的梯度近似误差不会像STBP训练中那样跨层复合[57]。在VGG-16架构中也观察到了类似的结果(见补充材料第E节)。
为了阐明LTL训练的SNN模型的能量效率,我们遵循常规做法,计算不同Tw下SNN与ANN的总突触操作(SynOps)比率[56]。通常,ANN所需的总SynOps(即FLOP)是一个常数,取决于所使用的特定网络架构,而对于基于发放率的SNN,总计算量通常随Tw线性增加。如图2(b)所示,为了实现与ANN对应物相当的精度,我们的SNN只需要0.43倍的总SynOps(Tw=8)。值得注意的是,在45 nm CMOS技术下,ANN所需的加乘(MAC)操作比SNN中使用的累加(AC)操作贵5倍[23]。因此,我们的SNN可以比主流ANN节省一个数量级的能量。值得注意的是,当将我们的SNN部署到新兴的混合信号NC芯片上时,这一价值可以进一步提高。此外,与QCFS[5](最近引入的ANN-SNN转换方法)相比,所提出的LTL规则需要更少的SynOps,这可能是因为我们网络中保持沉默的神经元比例较高。这可以通过在我们的方法中计算目标脉冲计数时采取的向下舍入操作来解释。
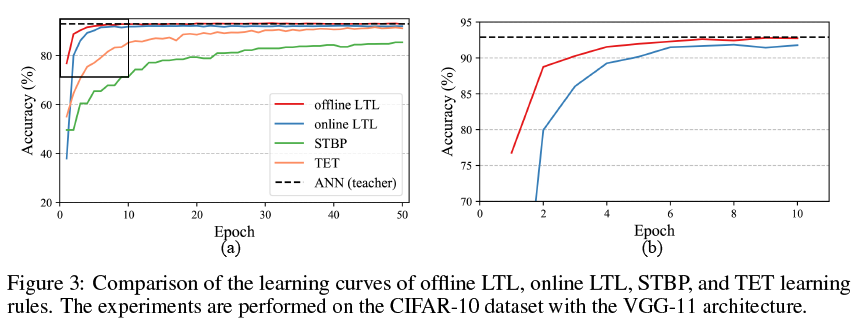
3.3 Rapid Learning Convergence
通过通过局部目标解耦每一层的学习,所提出的LTL规则巧妙地避开了空间信度分配,并将信度分配仅减少到时域。此外,替代梯度学习方法的梯度近似误差随着有效梯度传输距离的减小而减小。受益与此,与使用STBP和TET[13]规则训练的网络相比,网络收敛速度可以显著提高。正如图3所示的学习曲线,离线和在线LTL规则可以在CIFAR-10数据集上的五个epoch内快速收敛。相比之下,对于STBP和TET学习规则,精度在Epoch 50仍在提高。请注意,除了学习目标之外,所有这些实验都遵循相同的设置。在VGG-16架构中也观察到了类似的结果(见补充材料第F节)。
3.4 Low Memory and Time Complexity
在本节中,我们研究了所提出的LTL规则的内存和时间复杂性,并将其与表2中的其他流行学习规则进行了比较。STBP[58]规则要求存储所有时间步骤和层的每个神经元的中间状态,以便在反向传播期间使用,从而产生O(MTwL)内存复杂性,其中M是层中神经元的数量,Tw是时间窗口大小,L是层的总数。如果所有层都并行训练,则离线LTL规则具有与STBP规则相同的内存复杂性。然而,正如稍后将要讨论的,我们可以通过按顺序训练所有层来降低内存复杂性。值得注意的是,通过仅使用本地信息更新网络参数,在线LTL和DECOLLE[26]学习规则不需要存储任何中间状态,导致O(1)内存复杂性。
就时间复杂性而言,STBP规则的每个参数更新都需要NMTw乘法,其中N是一个层的输入神经元数量。由于分层互锁,需要从上到下依次更新所有层,需要O(NMTwL)时间复杂度来更新一次所有网络参数。对于离线LTL,通过解耦层之间的依赖性并并行训练所有层,时间复杂度可以降低到O(NMTw)。如前所述,我们可以通过一个接一个地逐步训练网络层来权衡内存复杂性和时间复杂性。这样,离线LTL规则的内存使用量将减少到O(MTw),而时间消耗将增加到O(NMTwL)。为了验证该训练策略的有效性,我们使用VGG-11架构在CIFAR-10数据集上进行了实验,获得了与所有层同时训练时获得的结果(93.20%)相当的结果(92.98%)。在这项工作中,为了实现最短的训练时间,我们使用并行训练策略作为所有其他报告实验的默认值。其他用户可以根据其可用的计算资源灵活地选择训练策略。
对于在线LTL,通过利用时间局部误差,时间复杂度可以进一步降低到O(NM)。注意,DECOLE需要额外的读出层来计算局部误差,从而比在线LTL需要更多的时间。还值得一提的是,通过用所提出的高效片上实现来选通参数更新,我们可以进一步降低在线LTL的时间复杂性。为了对内存和时间复杂性进行更具体的分析,我们在CIFAR-10数据集上测量了实际的GPU内存使用情况和训练时间,这与早期的理论分析非常吻合(参见补充材料第G节)。总之,通过将低计算复杂性与第3.3节中讨论的快速学习收敛相结合,所提出的LTL规则可以显著提高SNN的训练效率。

3.5 Robust to Hardware-related Noises
模拟计算基板的器件非理想性问题仍然是在超低功率混合信号NC芯片上部署SNN的主要障碍。然而,所提出的LTL规则可以通过以噪声感知方式启用片上训练来解决这一挑战。在这里,我们检查了片上LTL规则在解决硬件相关噪声方面的有效性,并重点关注四个典型的噪声源:设备失配、量化噪声、热噪声和神经元沉默[6]。特别是,我们使用Julian等人[6]引入的噪声模型,这些模型是在DYNAP-SE[36]混合信号神经形态处理器上测量的。因此,它可以忠实地反映真实场景中的实际硬件噪声。为了了解这些噪声的影响,我们首先采用LTL预训练的SNN,并将不同级别的噪声应用于它。然后,我们使用在线LTL规则在给定噪声下校准预训练的SN模型。
Device Mismatch 设备失配导致神经元和突触参数与期望的不同。为了模拟参数失配,我们遵循![]() 将高斯噪声添加到初始网络参数及其参数更新中。在该模型中,σ控制失配水平,我们将其从0.05变化到0.4,以模拟不同的噪声水平。如图4(a)所示,在失配水平σ=0.4的情况下,预训练SNN的精度降低了20%以上。值得注意的是,所提出的LTL规则只需一个训练epoch即可执行快速校准并恢复原始精度。这对于那些具有较差耐久性的设备将是有利的。
将高斯噪声添加到初始网络参数及其参数更新中。在该模型中,σ控制失配水平,我们将其从0.05变化到0.4,以模拟不同的噪声水平。如图4(a)所示,在失配水平σ=0.4的情况下,预训练SNN的精度降低了20%以上。值得注意的是,所提出的LTL规则只需一个训练epoch即可执行快速校准并恢复原始精度。这对于那些具有较差耐久性的设备将是有利的。
Quantization Noise 非易失性存储器设备通常具有有限数量的模拟状态,从而限制每个网络参数的可用位数。为了模拟这样的量化噪声,我们执行训练后量化到比特宽度7, 6, 5, 4, 3。如图4(b)所示,对于比特精度高于3的量化噪声,SNN表现稳健。之后,准确率急剧下降了30%以上。在量化感知训练[25]之后,所提出的LTL规则可以减轻这类噪声的影响,并成功地将精度恢复约17%。然而,由于表征能力降低,所得到的3位精度模型仍然落后于全精度模型约15%。
Thermal Noise 热噪声是神经形态装置固有的,其可以被建模为输入电流上的高斯噪声![]() 。与器件失配噪声类似,我们通过从0.01到0.2改变来模拟不同水平的热噪声。如图4(c)所示,该模型对热噪声高度敏感,并且随着噪声水平的增加,精度稳步下降。我们注意到,LTL规则可以解决这样的噪声,并且在很大程度上只需要一个训练epoch就可以快速恢复精度。
。与器件失配噪声类似,我们通过从0.01到0.2改变来模拟不同水平的热噪声。如图4(c)所示,该模型对热噪声高度敏感,并且随着噪声水平的增加,精度稳步下降。我们注意到,LTL规则可以解决这样的噪声,并且在很大程度上只需要一个训练epoch就可以快速恢复精度。
Neuron Silencing 神经元沉默噪声对应于一部分脉冲神经元没有反应,从而干扰网络动态的情况。我们通过随机屏蔽失败率从10%到50%的神经元输出来模拟神经元沉默噪声。如图4(d)所示,随着失败神经元数量的增加,准确性稳步下降。与其他噪声类型类似,芯片上LTL训练可以快速恢复准确度,即使在50%的神经元出现故障的情况下,准确度也保持在80%以上。
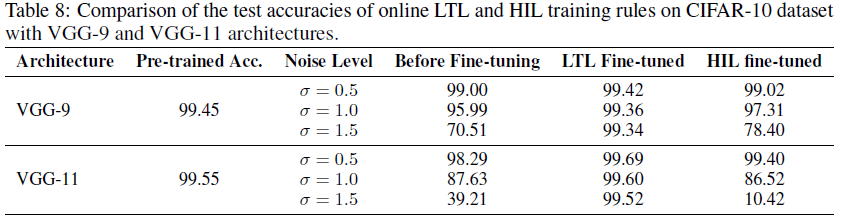
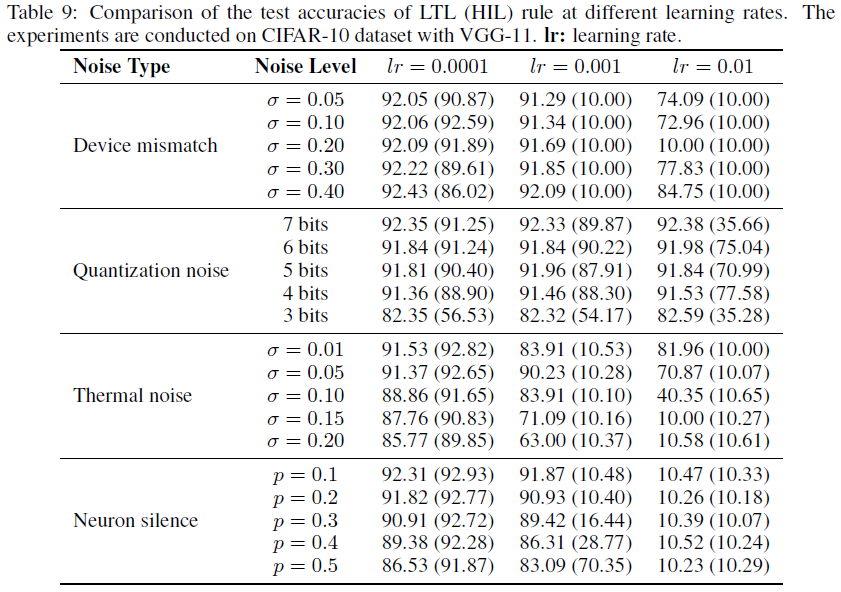
Comparison with the HIL Training Approach 与HIL训练方法相比,所提出的LTL规则具有更好的噪声鲁棒性和可扩展性。为了证明这一点,我们将在线LTL规则与HIL训练方法[10]进行了比较,以解决上述设备相关噪声(有关实验设置和结果的详细信息,请参见补充材料第H节)。LTL规则在小和中等噪声水平下实现了与HIL方法相当的精度(见表7),但在面对更强的噪声水平时,它似乎更稳健(见表8)。此外,LTL规则对学习率的选择更加稳健(见表9)。总之,所提出的LTL学习规则对于解决混合信号NC芯片的器件非理想性既有效又高效。
4 Conclusion
在本文中,我们提出了SNN的本地串联学习(LTL)规则。从教师-学生学习方法中汲取灵感,我们利用易于训练的ANN的高效特征表示来指导SNN的训练。这简化了信度分配问题,并导致网络快速收敛,计算复杂度显著降低。我们还证明了所需的时间信度分配可以用本地可用信息很好地近似,并且我们提供了所提出的LTL规则的有效片上实现。在这种片上设置下,我们证明了LTL规则可以针对各种设备非理想性问题提供鲁棒性。因此,它为在超低功率混合信号NC平台上快速高效地训练和部署SNN提供了无数机会。对于未来的工作,我们将探索在循环神经网络和Transformer架构上提出的教师-学生学习方法,以便处理那些时间丰富的信号,如语音、视频和文本。
Supplementary Materials
A Derivation for gradients
A.1 Offline Learning

B Experimental details
B.1 Datasets
CIFAR-10 [29] 此数据集包含来自10个类的60000张彩色图像。每个图像的大小为32×32×3。所有的图像被分成50000张和10000张,分别用于训练和测试。
CIFAR-100 [29] 此数据集包含来自100个类的60000张彩色图像。每个图像的大小为32×32×3。所有的图像被分成50000张和10000张,分别用于训练和测试。
Tiny ImageNet [55] 此数据集包含来自200个类的110000张彩色图像。每个图像的大小为64×64×3。所有的图像被分成100000和10000张,分别用于训练和测试。
对于所有数据集,我们遵循[17]中使用的类似数据预处理技术,包括调整大小和随机裁剪、随机水平翻转和数据归一化。更多细节可以在我们发布的代码中找到。
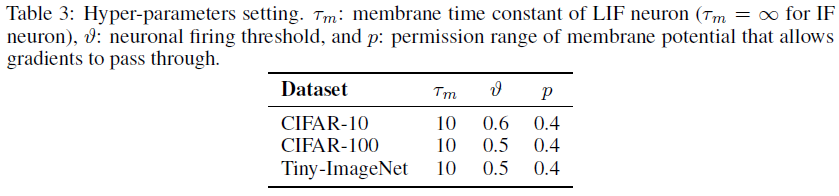
B.2 Hyper-parameters for SNN
我们对不同数据集的SNN超参数进行了微调,如表3所示。
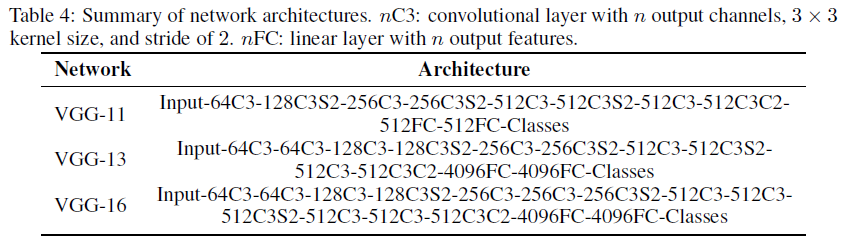
B.3 Network architecture and training configuration
为了便于与其他工作进行比较,我们使用VGG-11、13和16进行了实验,其网络架构总结如下。
对于VGG,将池化层替换为跨度为2的卷积层,并在全连接(FC)层之后应用随机失活。我们使用Pytorch库来加速多GPU机器的训练。我们使用动量为0.9、权重衰减为5e-4的SGD优化器对所有教师ANN进行了200个epoch的训练。对于CIFAR-10、Tiny ImageNet和CIFAR-100数据集,初始学习率分别设置为0.01、0.01和0.1;学习率在60、120和160个epoch衰减10倍。对于LTL训练阶段,我们使用Adam优化器分别为CIFAR-10、CIFAR-100和Tiny ImageNet训练学生SNN 100、50和50个epoch。所有SNN的初始学习率设置为1e-4,其值分别每10个epoch(CIFAR-10)或每5个epoch(CIFAR-100和Tiny ImageNet)衰减5倍。我们在Nvidia Geforce GTX 1080Ti GPU上训练所有模型,其中GPU具有12 GB内存(Tw=16及以下),我们使用的GPU集群具有40 GB内存(Tw=32)。
C Study of the warm-up period on the online learning performance
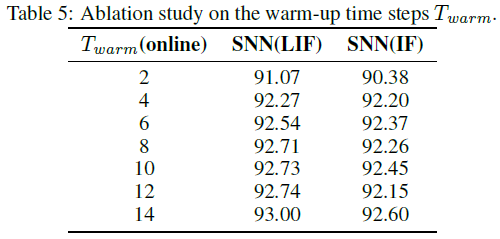
为了研究预热期Twarm对在线学习性能的影响,我们通过逐步增加Twarm进行了一项研究,在此期间不允许参数更新。实验在具有VGG-16和Tw=16的CIFAR-10数据集上进行。如表5中报告的结果所示,很明显,增加Twarm将导致更好的梯度近似,测试精度的提高证明了这一点。
D Online LTL rule perform as effectively as the offline version
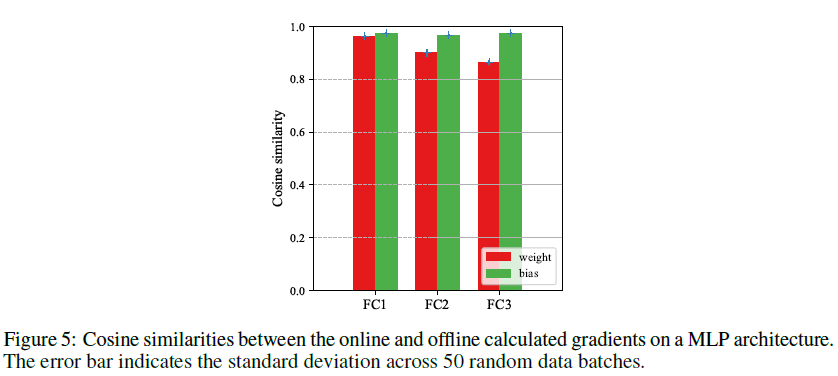
为了进一步阐明为什么在线LTL规则可以像离线版本一样有效,我们进行了一项实验来分析其计算的梯度之间的失配程度。在本实验中,我们首先在MNIST数据集[33]上使用4层MLP架构(即784-800-800-800-10)预训练教师ANN模型。然后,我们随机初始化一个学生SNN模型,并抽取50个随机批次的128个样本来计算每个层的梯度。如图5所示,对于所有隐藏层,离线和在线计算的梯度之间的余弦相似性仍然高于0.86。根据超维计算理论[27],任意两个高维随机向量近似正交。它表明在线估计的梯度非常接近离线计算的地面真实值,并保证可以很好地近似期望的学习动态。
E Rapid and efficient pattern recognition on VGG-16
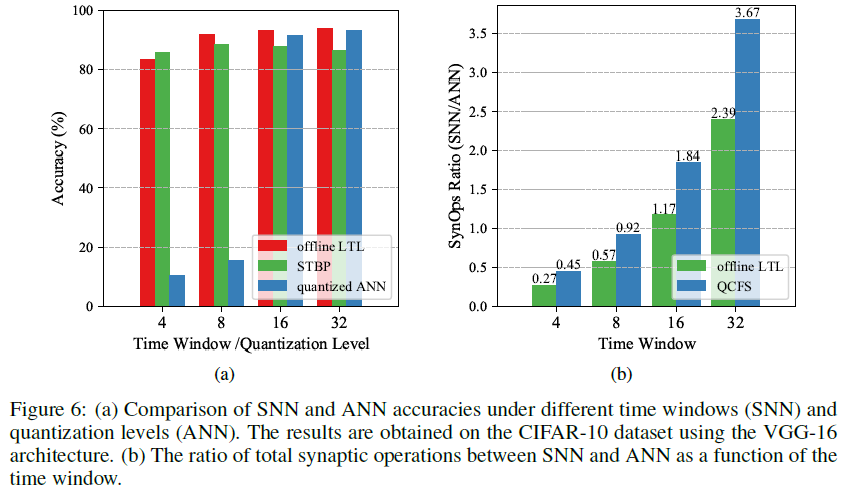
我们在此表明,在VGG-16上也可以获得第3.2节所述的类似结果。如图6(a)所示,LTL和STBP训练的SNN即使在极短的时间窗口(即,Tw=4)下也能保持高精度,而量化的ANN在量化水平低于16时显著退化。此外,与图6(b)所示的模拟版本相比,我们的VGG-16仅能以0.57倍的SynOps总数实现具有竞争力的精度。
F Rapid network convergence for VGG-16 architectures
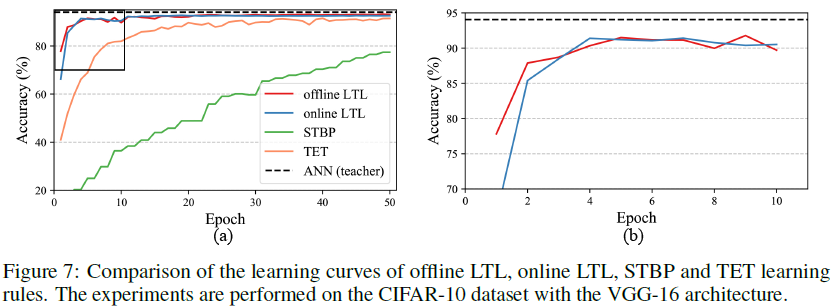
我们在此表明,在VGG-16架构上可以获得第3.3节所述实验的类似结果。离线和在线LTL规则在CIFAR-10数据集上的5个epoch内快速收敛,这比基准STBP和TET规则快得多。
G Empirical analysis on memory and time complexity
我们使用VGG11架构和CIFAR-10数据集测量实际内存消耗和训练时间。我们在下表中列出了10个训练epoch记录的平均结果。通常,对于STBP和离线LTL方法,GPU内存使用量几乎随时间窗口大小(即T=16)线性增加,这遵循我们的理论分析。与STBP规则相比,离线LTL规则需要稍微更多的内存空间来计算逐层损失函数。关于每epoch训练时间,尽管离线和在线LTL规则都明显快于STBP规则,但加速比例比理论上的要差。我们想承认,我们在实现中采用了原始和未优化的Pytorch GPU核。为了实现所需的理论速度,需要定制GPU核,这些核可以跨时间和层并行执行训练,我们将此作为未来的工作。

H Comparison with hardware-in-the-loop training approach
我们将在线LTL规则与硬件在环(HIL)训练方法进行比较,以解决第3.5节中介绍的设备相关噪声。表7报告了不同噪声水平下的微调精度,预训练SNN为92.11%测试精度。这些结果表明,这两种方法在解决低和中等水平的设备噪声方面都可以实现类似的性能。
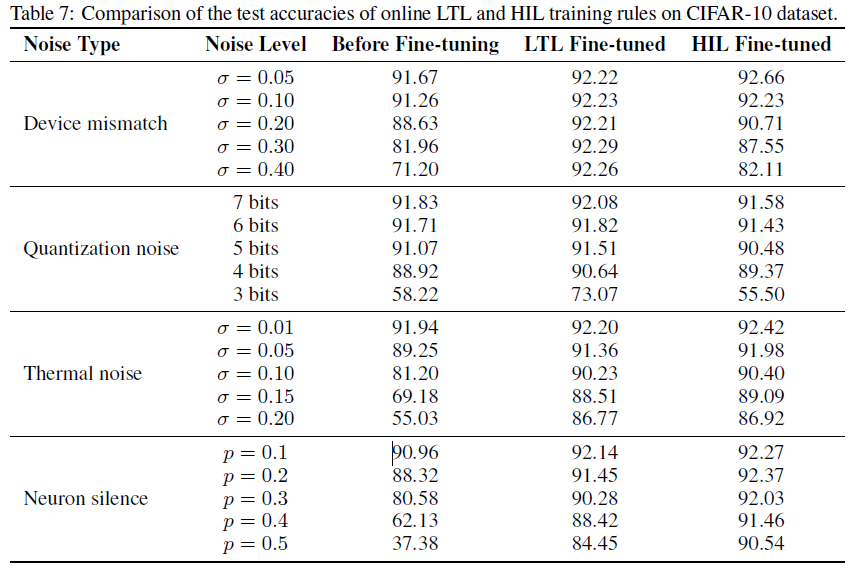
为了证明所提出的逐层训练方法可以实现比HIL训练方法更好的噪声鲁棒性和可扩展性,我们进一步提高了设备噪声水平,并在MNIST数据集上测试了预训练的SNN。如表8中总结的结果,LTL规则对不同级别的噪声具有高度鲁棒性,并且还可以自由扩展到更深的VGG-16架构。相反,随着噪声水平和网络深度的增加,HIL学习方法的性能显著下降。这可以通过以下事实来解释:在每一层估计的梯度往往是有噪声的,并且在训练期间跨层累积的误差。而我们的分层训练方法可以有效地解决这个问题。
如果学习规则对超参数的选择是鲁棒的,这是有益的。为了进一步研究这一观点,我们比较了在线LTL和HIL规则在不同学习率下的性能。如表9所示,LTL规则可以容忍比HIL规则更大的学习率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号