Anomaly Detection in Autonomous Driving: A Survey
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

CVPR Workshops 2022: 4487-4498
Abstract
如今,自动驾驶汽车在我们的道路上朝着未来迈出了卓越的步伐。尽管自动驾驶汽车在封闭条件下表现良好,但它们仍难以应对意外情况。这项调查提供了基于相机、激光雷达、雷达、多模态和抽象目标级数据的异常检测技术的广泛概述。我们提供了一个系统化,包括检测方法、角落案例级别、在线应用程序的能力和其他属性。我们概述了最新技术,并指出了当前的研究差距。
1. Introduction
街道上每天都会出现异常情况,也称为角点案例(corner cases),这就是自动驾驶汽车需要应对的原因。这种“罕见事件的长尾”[45]被许多人视为大规模部署自动驾驶汽车的核心障碍[1, 50, 81]。尽管在处理罕见和未知问题方面取得了令人兴奋的进展[47, 91, 92],但检测异常仍然至关重要,这仍然是一项挑战[55]。在自动驾驶(AD)中,有许多级别的拐角情况和多种传感器模式,包括摄像头、激光雷达和雷达。尽管对基于摄像头的方法进行了广泛的调查[14],但对其他传感器或更高抽象层次的角点案例(包括调查)几乎没有研究。在此,我们概述了AD领域中针对不同传感器模态的异常检测方法,包括未明确为AD开发但我们认为适用的方法。
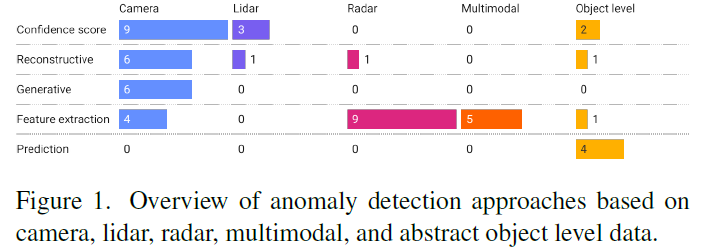
我们在表1-5中描述了模态相机、激光雷达、雷达、多模态和抽象目标级别的异常检测技术。它们的进一步特征在于它们的一般检测方法、角点案例的类型、评估数据集或模拟,以及它们可能的在线应用。我们参照Breitenstein等人将检测方法分为五个概念:“重建、预测、生成、置信分数和特征提取”(“reconstruction, prediction, generative, confidence scores, and feature extraction”)[14]。置信分数技术通常通过后处理得到,而不干扰神经网络的训练,并细分为贝叶斯方法、学到的分数和通过后处理获得的分数。重建方法试图重建常态,并将任何偏离常态的行为视为异常。生成方法与之前的重建方法密切相关,但也考虑了鉴别器的决定或到训练数据的距离。特征提取可以基于手工或学到的特征来确定类别标签或比较各种特征级别上的模态。基于预测的技术预测正常情况下预期的下一帧。图1中提供了一个概述。
我们遵循Breitenstein等人[13]的方法,以像素、域、目标、场景和情况(pixel, domain, object, scene and scenario)为层次对角点案例进行系统化处理,每一个都很难检测到。Heidecker等人[40]扩展了这些基于相机的水平,以纳入激光雷达和雷达传感器。与他们的工作类似,我们交替使用术语“异常”和“角点案例”。在本次调查中,我们将重点放在自然的外部角点案例上。因此,我们排除了传感器层上的异常[40];像素级的异常;以及对抗性攻击导致的异常。
我们列出了所有使用的数据集或模拟环境,并将其标记为具有在线能力的技术,如果它们或具有相同计算复杂度(或更高,用**表示)的类似方法被报告为具有在线性能,或将帧速率命名为高于10 FPS。标记为*的方法不提供推理性能度量,因此标记为脱机(offline)。
2. Anomaly Detection on Camera Data
自动驾驶汽车通常配备不同的摄像头系统,如立体声、单声道和鱼眼摄像头,以确保对环境的丰富感知。因此,摄像机数据中的异常检测具有更强大的视觉感知的巨大潜力。在本节中,我们将根据Fishyscapes(FS)基准[31]引入另外两个标准:辅助数据和重训练。前者表示一种方法在训练过程中是否需要异常数据。然而,重训练规定了方法是否不能使用预训练的模型,而是需要特殊的损失或重新训练,这可能会降低性能[31]。表1中列出了所有基于相机的方法。
Confidence score. 基于置信分数的方法构成了基于神经网络不确定性估计的异常检测基准。作为早期的工作之一,Kendall等人的Bayesian SegNet[51]通过蒙特卡洛随机失活(dropout)抽样得出了语义分割(SemSeg)网络SegNet的不确定性,其中类的方差越高,表示不确定性越高。不确定性可以解释为检测道路障碍物的像素级异常分数[69, 89]。Jung等人[48]提出了检测道路上未知障碍物的类似方法。他们获取了分割网络的分类条件标准化最大logits。这个过程的动机是发现最大logits对于不同的预测类有自己的范围。由此从训练样本中确定平均值和标准差。因此,标准化可归为学到的置信分数方法。除了标准化之外,他们还抑制了类边界,并应用扩展平滑来考虑广泛接受领域中的局部语义。Heidecker等人[41]对Mask R-CNN的认知不确定性建模[39],并量化实例的类别和位置不确定性。他们概述了基于位置和类别不确定性检测异常的标准。由于位置不确定性导致的异常由超出预定义阈值的缩放边界框的标准偏差定义。此外,当任何类别的标准偏差高于预定义阈值时,由于类别不确定性,实例被视为异常。但是贝叶斯分割网络由于其多次前向通过网络,每帧都有蒙特卡洛随机失活,因此推理速度较慢。因此,Huang等人[44]通过帧序列中基于区域的时间聚合来模拟采样过程,并保持网络的在线能力。为了确保运动目标的不确定性估计正确,先前的分割通过光流被扭曲。Bevandic等人[6]提出了一种多任务网络,以同时将输入帧分割成语义,并输出异常概率图。当模型面临异常值时,当概率超过阈值时,后者会覆盖SemSeg,以校准置信分数。最近,Du等人[28]提出了通用学习框架虚拟异常值合成(Virtual Outlier Synthesis,VOS),该框架通过合成虚拟异常值来对比形成神经网络的决策边界。首先,他们估计了倒数第二个潜在空间中的类条件多变量高斯分布。然后,从该学习分布的足够小的ε-似然区域对异常值进行采样。类边界附近的这些虚拟异常值鼓励模型在分布内(ID)和分布外(OOD)数据之间形成一个紧凑的决策边界。此外,他们提出了一种新的训练目标,将自由能作为不确定性度量,其中ID数据具有负能量,虚拟异常值具有正能量。在推理过程中,基于不确定性分数,使用逻辑回归器检测OOD目标。
虽然前一种方法集中于目标层面的异常,但Breitenstein等人[12]是第一个检测集体异常的方法。他们基于引用数据集学习正常数量的类实例。通过Mask R-CNN[39]预测类实例本身以类的离散分布结束。此外,他们还引入了地球移动距离(earth-mover's distance,EMD)的变化进行推断,即地球移动偏差(earth-mover's deviation,EMDEV)。除了分布的比较之外,EMDEV是一个有符号的值,它指示场景是否包含比通常更多或更少的类实例。
Reconstructive. 重建和生成方法主要用于目标级别的异常检测,因为模型学习在没有异常目标的任何辅助数据的情况下复现训练数据的正常性。例如,Vojir等人最近的一项工作[89]提出了重建模块JSR-Net,以基于像素得分检测道路异常。他们通过将已知类别的信息合并到异常分数中来增强训练的SemSeg网络。网络架构由重构和语义耦合模块组成。前者连接到SemSeg网络的主干,以有区别的方式重建道路,这意味着它减少了道路的重建损失,同时增加了剩余环境的损失。在随后的模块中,生成的像素误差图与SemSeg的输出逻辑相耦合,以得到像素级异常分数。扩展模块在增强的道路图像上训练,其中噪声块或输入图像的一部分被随机定位在道路上并被标记为异常。对各种数据集的评估表明,JSR Net与其他数据集相比具有优势[5, 23, 56, 57],同时保持了闭集分割性能。
Ohgushi等人[69]在具有真实和合成道路障碍物的公路数据集上根据LaF基准评估了类似的方法。与Vojir等人相反,他们将SemSeg的熵损失与真实图像和重建图像之间的感知损失相结合,以形成异常图。他们概述了一组后处理步骤,其中最终障碍物得分图取决于语义信息、上述异常图和用于细化局部区域的超像素划分。
Di Biase等人[25]通过将重建误差与分割网络的两个不确定性图相结合,利用图像重新合成[57]。除了分割输出之外,网络还输出软最大熵和距离。类似于[69],感知差异被用作输入图像和合成图像之间的重建损失。所有预测的地图和输入图像在具有三个部分的空间感知相异性模块中进行融合:编码器、融合模块和解码器。在融合模块中,编码和重新合成的输入和语义图像被级联,并用1x1卷积进行融合。通过逐点相关针对联合编码的不确定性和感知差异来评估所得到的特征图。通过对融合的特征进行解码并利用语义信息进行空间感知归一化,提供最终的像素级异常分割。
Generative. 根据FS、LaF和Segment Me If You Can(SMIYC)障碍物跟踪基准,Grcic等人[35]的NFlowJS密集异常检测优于所有当代技术,并代表了当前最先进的基于摄像头的异常检测。NFlowJS被联合训练以在常规图像上生成具有标准化流(NF)的合成负补丁,同时基于这些创建的混合内容图像训练密集预测网络。由此,所生成的负补丁被定义为异常掩模。在训练期间,鼓励判别模型为生成的补丁产生均匀的预测分布。这导致NF的生成性分布远离内部。同时,它被训练为最大限度地提高内点的可能性。这些相反的目标支持在训练数据的边界处生成图像,同时使判别模型对异常敏感。特别是,由于前一方面的原因,合成的异常补丁可能包含与模型以高置信度预测的内层相似的部分。对这种行为的强烈惩罚破坏了模型对实际内部像素的信心。因此,他们发现Jensen Shannon(JS)散度是一种轻微的惩罚高置信度预测的损失。在推断过程中,闭集分割被阈值超过温度缩放软最大值生成的异常图以及输出概率和均匀分布之间的JS散度所掩盖。与以前的生成模型相比,NFlowJS只依赖于训练期间的异常合成,从而提高了实时推理速度。Blum等人[8]还评估了基于NF的方法,并对其FS基准进行了逻辑回归。然而,这些结果与NFlowJS无法相比。
Nitsch等人[68]采用并增强了Lee等人[54]的生成方法来检测目标异常。Lee等人提出了一种辅助生成对抗网络(GAN),它鼓励目标分类器为训练分布之外的样本提供低置信度。Nitsch等人通过事后网络统计扩展了该方法,该统计估计了瓶颈层网络权重上的类条件高斯分布。余弦相似性度量确定分布距离,并基于经验阈值对给定样本进行分类。由于它们只执行分类,因此必须提前完成目标的定位。
类似地,Lis等人[57]采用GAN来重新合成输入图像,并通过外观差异检测目标级别的异常。然而,与[69, 89]相反,图像生成基于最终SemSeg映射,其中解码器基于SemSeg的中间特征空间重建图像。由于SemSeg保留了场景布局,但失去了精确的场景外观,常规的重建错误(如感知损失)将在没有信息结果的情况下输出较高的总体差异。因此,他们提出了一种差异网络,该网络通过具有共享权重的多个VGG16[83]网络对输入和重新合成的图像进行编码。这些特征与卷积编码语义图一起连接,并在所有提取级别上相关。[38, 95]还采用了语义到图像合成,并以条件GAN(cGAN)的形式进行了评估,随后进行了不同性评分。
Löhdefink等人[60]提出了一种检测域移位的方法。自编码器以自监督的方式学习给定数据集的域。该方法通过自编码器峰值信噪比(PSNR)的分布来表征训练数据域。在推断过程中,通过通过EMD比较数据的学习和输入PSNR分布来估计域失配(DM)。评估表明,当面对不同于源域的目标域时,自动编码器的DM度量与SemSeg性能的降低之间存在很强的秩序相关性。虽然推理是实时的,但该方法必须累积一定数量的图像,因为它使用批作为输入。
Feature Extraction. Bolte等人提出了另一种域偏移检测。[10],其中比较了特征图的均方误差(MSE)。对整个数据集或批次评估MSE。类似地,Zhang等人[101]提出了基于VGGNet特征的训练嵌入距离的DeepRoad框架来验证单个输入图像[83]。Bai等人[2]检测城市道路场景中的异常,并将整个输入场景分类为异常。他们通过尺度不变特征变换(SIFT)特征的k均值聚类来识别正常城市场景的一组代表。最后,利用一类支持向量机(一类SVM)对图像进行分类。
总体而言,许多先前概述的技术在没有外部数据的情况下工作,但需要对所提出的扩展模块或整个检测架构进行重训练。
3. Anomaly Detection on Lidar Data
大多数情况下,自动驾驶汽车并不完全依赖摄像头数据。尽管相机数据具有三种传感器模式中最高的分辨率,但它缺乏深度的精确测量。因此,光探测和测距(激光雷达)传感器提供了环境的三维深度图,通常可以在传感器设置中找到。虽然在像素级别上有很多关于激光雷达点云局部去噪的研究[3, 74],但我们对目标和域级别的异常感兴趣,其中整个点簇或外观上的大而恒定的移动被视为异常。尤其是雨、雪和雾等天气条件严重影响数据。表2中列出了所有基于激光雷达的方法。

Confidence score. Zhang等人的最新研究[100]表明,降雨会影响激光雷达测量质量,因为产生的点云更稀疏、噪音更大,平均强度更低。因此,他们的目标是用深度半监督异常检测(DeepSAD)方法量化激光雷达的退化[77]。他们首先将3D激光雷达数据投影到2D强度图像中。然后,DeepSAD将图像转换为一个潜在空间,在那里,所有正常的图像,即无雨的扫描,都落入超球面,所有异常的图像,如受雨影响的图像,都被映射到远离超球面中心的地方。最后,将变换后的测试图像到所学习的超球面中心的距离解释为异常分数。由于模型体系结构将异常定义为那些从超球面落下的异常,我们将所提出的方法列为表2中的学习置信度检测方法。经过训练的DeepSAD在动态模拟测试数据上达到了降雨强度和退化分数之间的Spearman相关性,高达0.82。这表明由于天气条件,异常检测的量化相当准确。尽管该方法是针对下雨和正常天气条件开发的,但我们怀疑所提出的方法可适用于其他天气条件,如雪和雾。
在过去,已经提出了几种架构来检测点云中的对象,如VoxelNet[102]、PointRCNN[82]和PointNet++[73]。然而,这些是基于封闭集设置的,因此只能检测包含在训练集中的类。相反,开放集检测方法能够在定期检测预定义类时将封闭集之外的对象明确分类为未知对象。因此,开放集设置放松了将所有检测分类为预定义类之一的约束。因此,人们期望假阳性率会提高,并且模型会在从未见过的实例上承认对象的新颖性。
Wong等人首次提出了3D点云开放集探测器的想法。[94]。他们提出了一个开放集实例分割(OSIS)网络,该网络学习一种不可知类别的嵌入,将点聚类到实例中,而不管其语义如何。该推断基于鸟瞰(BEV)激光雷达框架,由两个阶段组成:封闭集和开放集感知。在第一阶段,2D卷积的主干提取多尺度特征,然后将其馈送到检测和嵌入头。后者是OSIS的核心,学习类别不可知的嵌入空间。此外,嵌入头生成了可能的闭集类的原型。然后通过学习的嵌入空间将点与已知类别的原型相关联。在第二阶段,剩余的未关联点被视为未知。通过基于密度的带噪声应用程序空间聚类(DBSCAN),将这些目标聚类为未知目标的实例[29]。所概述的方法属于学习置信分数的范畴,因为原型是在训练期间学习的,而未知目标是通过其类别关联的不确定性来识别的。OSIS在两个大规模的非公开数据集上进行了评估。在这里,该技术在检测目标级别上的单点异常方面优于其他基于深度学习的自适应实例分割算法。
OSIS网络后来被用作比较Cen等人[17]开发的度量学习与无监督聚类(MLUC)网络的基准。他们关注两个主要挑战:以高概率识别未知目标的区域,并用适当的边界框包围这些区域的点。在第一个问题的背景下,本文表明,基于度量学习的欧氏距离和(EDS)比朴素的软最大概率度量更适合区分已知和未知目标的区域。他们用嵌入空间的所有原型的欧氏距离表示来代替闭集检测的分类器。基于欧氏距离的概率被合并到损失函数中,使得已知类的嵌入向量接近相应类的相应原型。然而,未知对象被映射到嵌入中心附近,具有较小的EDS。EDS测量闭合集检测的不确定性。因此,EDS低于阈值λEDS的盒子被视为未知目标的区域。与OSIS类似,这些低置信度的边界框随后通过无监督深度聚类来细化。MLUC显著优于OSIS。
Reconstructive. Masuda等人[65]展示了一种检测目标点云是否异常的方法。与前面的方法不同,该技术基于单个封装目标的点云。由于汽车激光雷达提供全环境扫描,因此需要首先通过检测或聚类方法提取感兴趣的单个目标或区域。所提出的VAE基于FoldingNet解码器[98],并学习重建被视为正常的已知目标集合。然后基于重建和作为异常分数的切角距离将点云分类为异常。该方法在ShapeNet[21]数据集上进行了评估,该数据集还包括AD域之外的各种目标。结果很有希望,因为该模型的平均AUC为76.3%,其中已知类别被定义为异常。
总体而言,激光雷达数据中目标层面的异常检测刚刚取得进展,此前研究已经导致了各种封闭集检测架构。
4. Anomaly Detection on Radar Data
雷达是AD中经常使用的第三种传感器模式。与激光雷达传感器相比,它以较低的分辨率和较不详细的空间信息为代价,具有更高的距离。与前两种模式相比,雷达对不断变化的天气和白天条件更为稳健[90]。在下文中,我们专注于为汽车工业中安装的雷达系统设计的异常检测技术,如环绕、远程和近程雷达,并排除基于超宽带和全天候雷达的技术。我们还通过用于检测的方法集(数学、特征工程、机器学习(ML)或深度学习(DL))来描述方法。表3中列出了所有基于雷达的方法。
雷达通过测量电磁多路径波的飞行时间及其反射来估计目标的位置。由于多径传播,雷达甚至可以检测到被遮挡的目标[86]。然而,由于这也会导致噪声、反射和伪影,这一优势被削弱了。特别是反射表面,如高速公路上的护栏或光滑的墙壁,会产生不存在的伪影,通常被称为“幽灵目标”[18, 79, 90]。这些是影响汽车雷达的长期挑战[58]。出于这个原因,由于本次调查侧重于像素级以上的异常,我们特别关注检测重影目标等的方法。
Feature Extraction. Liu等人的最新工作[58]提出了一种多径传播模型,以基于护栏反射的目标距离差来识别和消除重影。所建立的模型和数值结果表明,每辆实车与其对应的幻影目标之间的距离差仅略有不同。相比之下,两个甚至位置相近的真实目标之间的距离差异通常要大得多。所提出的重影消除算法利用了这一发现,因为它基于预先数值确定的最大距离差阈值Δr来区分真实目标和重影目标。虽然这种数学方法在模拟中简单有效,但必须考虑其约束,因为它仅限于具有固定大小的三条车道的高速公路般的驾驶场景。此外,目标和反光护栏之间的距离仅取三个值,并且没有模拟真实车辆的车道变化。Holder等人[43]、Kamann等人[49]、Visentin等人[88]和Roos等人[76]也做了类似的工作。
最新的ML算法被用于检测各种驾驶场景中的雷达异常,而无需上述数学模型的约束。在这种情况下,重影目标通常被定义为一个单独的类。例如,Griebel等人[36]利用PointNet++架构实现了一种DL方法。原始架构使用多尺度分组(MSG)层来提取点云中不同尺度的特征。MSG模块使用循环形式来查询点的相邻信息。他们引入了原始分组模块的扩展,假设异常雷达目标发生在雷达传感器原点周围的环形区域,与汽车目标的距离相同。所谓的多表单分组(MFG)模块是原始循环和新环形查询表单的组合。因此,该模块在多个尺度上合并了两种表单的邻域信息。此外,它们不仅关注多路径异常的检测,如重影目标,还关注由多普勒速度模糊或到达方向估计误差引起的其他单目标异常。后者是局部异常值,属于像素级别。
Kraus等人[52]利用PointNet++不仅区分真实目标和幽灵目标,还将它们分类为(幽灵)行人或(幽灵)自行车。因此,评估仅限于非视距(NLOS)数据集[80],仅包括易受伤害的道路使用者。他们通过在200ms的时间内积累测量数据来应对稀疏雷达数据的挑战。
虽然前一种方法检测单次拍摄的2D雷达数据中的异常,但Chamsedine等人[18]评估了PointNet++架构,以检测密集3D雷达数据中出现的重影目标。与其他常见的3D检测网络[53,102]相比,PointNet++架构能够学习单个点特征,因此非常适合将单个雷达点分类为真实目标或幻影目标。消融研究表明,空间信息的表示形式是重要的,因为球面坐标中的点的额外编码提高了网络的性能。
另一种值得注意的方法是Prophet等人[72]的程序,无论其原因如何,都可以检测重影异常,其中通过扫描的径向速度和阈值来识别初始移动目标,以提高场景理解。然后,为每个被测检测(DUT)定义一组手工特征。这些特征包括DUT参数、车辆运动状态、第一步计算的误差值、静态和移动邻居的数量,以及DUT周围占用网格图(OGM)的计算。此外,它们包括布尔特征,该布尔特征指示在前一帧中DUT周围存在移动邻居检测。因此,该技术是第一个结合时间数据以改进检测的技术。最后,这些特征被输入到ML算法中,如SVM、k近邻分类器(KNN)或RF。根据对36916次检测数据集的后续评估,RF以91.2%的成功率优于所有其他算法。类似地,Ryu等人[79]在一组六个特征上训练多层感知器(MLP),以从跟踪算法中去除重影目标。
Reconstructive. Garcia等人[32]使用由上述占用网格和移动检测图组成的双通道图像作为全卷积网络(FCN)的输入。所提出的架构在编码器和解码器部分中被分段。前者将语义信息提取成较低分辨率的表示,后者重建空间信息并将提取的表示映射回原始图像大小。在生成的概率图中,移动目标被认为是重影检测。该技术在50幅图像的测试集上实现了92%的二值分类精度。
总体而言,许多方法假设,与传统的(即,如表3所示的重建或基于置信度的技术)相比,可以通过其特征集来区分虚假目标和真实目标。尽管如此,我们预计未来的工作将通过考虑时间信息进一步改进,如[72]所示。
5. Anomaly Detection on Multimodal Data
自动驾驶车辆通常配备多种模式。在下文中,我们概述了基于单个传感器之间的不规则性或通过融合信息来识别异常的技术。所有多模态方法见表4。

Feature Extraction. 继之前在雷达数据中检测幽灵目标之后,Wang等人[90]提出了一种多模态技术。Transformers非常适合3D点云,因为它们的注意力机制是排列不变的,这对于传统的神经网络来说很难做到。此外,与前面提到的PointNet++等结构不同,Transformers显式地对点的交互进行建模。作者采用多模态变换网络通过参考激光雷达点来检测雷达幻影目标。雷达点云比激光雷达点云稀疏得多,这阻碍了数据匹配。因此,单个雷达点通过KNN查询周围的激光雷达点,并提供局部特征信息,如“放大镜”。他们对非结构化雷达数据本身进行自我关注,以识别幻影目标,因为这些目标与相应的真实目标具有很高的相关性。注意力模块被堆叠成网络。最后,利用PointNet++的全连接分割头将单个雷达点分类为可能的重影目标。所提出的方法在nuScenes数据集上进行了评估[16]。值得一提的是,幽灵目标的地面真相是通过比较雷达和激光雷达数据生成的。
Sun等人[85]提出了基于RGB-D数据的SemSeg实时融合网络。多模式架构的主要目标是通过结合深度信息来改进图像分割。此外,他们认为多源分割框架还能够检测意外的道路障碍,提供统一的像素级场景理解。然而,对CS数据集[22]的评估没有提供意外障碍的检测性能度量,因为该方法集中于封闭集类的SemSeg。Gupta等人[37]以MergeNet的形式实现了另一种基于RGB-D的道路障碍物检测。正如该架构的名称所暗示的,该模型通过第三个元精简器网络合并了两个网络,即条带网和上下文网。条纹网基于分割成条纹的图像并行提取RGB和深度数据的低级特征。这迫使网络学习窄带信息和一小部分参数内的鉴别特征。此外,这允许更可靠地检测小型道路障碍物。相反,上下文网是在整个RGB图像上训练的,并决定学习高级特征。Refiner网络作为一个元网络,将互补功能结合起来,最终形成一种课程学习形式。因此,MergeNet被训练为区分道路、越野和小型障碍物,我们认为后者是不正常的。
Ji等人[46]提出了一种监督VAE(SVAE),以合并不同维度的多个传感器模态。这对于密集激光雷达数据和低分辨率雷达数据的融合尤其有用。他们在训练后放弃了解码器,并将学习到的编码器用作特征提取器。然后,模态的潜在表示与其他编码模态一起被馈送到全连接层中,以识别车辆的异常操作模式。尽管该方法是为野外机器人设计的,但我们希望它可以应用于其他驾驶场景。
总之,在图1中可以看到,所有的多模态异常检测技术都是基于单个模态提取特征的比较。我们认为,多模态检测可能变得更加相关,因为它拓宽了潜在异常的搜索空间,同时降低了误报的风险。
6. Anomaly Detection on Abstract Object Data
前几节概述了适用于特定传感器模态的异常检测技术。以下方法侧重于更抽象的模式分析,即检测场景中的异常行为,这些场景不一定与传感器模态相关。因此,这些方法旨在检测情景水平上的异常[13],并处理非自我车辆的危险和异常驾驶行为。所有基于抽象目标级别的方法都可以在表5中找到。
Prediction. Yang等人[97]基于隐马尔可夫模型(HMM)评估驾驶车辆的行为,以检测异常场景。马尔可夫模型的观测状态由条件蒙特卡罗密集占用跟踪器(CMCDOT)框架[78]提供,并通过概率占用网格包括实时速度和车辆位置。该框架基于点云和里程数据得出这些观测结果。因此,在模拟多车道公路场景中,流水线可以可靠地推断出两辆非自我车辆的危险和异常驾驶行为。
Bolte等人[9]提出了情况级别的异常检测,其中在一系列传感器数据(即相机图像)上观察到模式。他们考虑了所有的亚型:异常、新奇和危险的情况[13]。由于情况异常的性质,他们量化了移动目标(如行人或汽车)的异常行为。真实帧和预测帧之间的误差被认为是异常分数。预测帧由对抗性自编码器生成,并基于过去的输入帧序列。因此,异常分数也可以解释为模型的不可预测性。使用MSE、PSNR和结构相似性指数度量(SSIM)[93]度量对模型进行评估,并通过阈值确定异常情况。他们通过将输入图像划分为用户特定大小和权重的网格单元来定位异常行为的对象,因为这些目标具有较高的碰撞风险。
Liu等人的论文[59]中概述了一种类似但更全面的方法。他们采用U-Net[75]作为图像到图像的转换模型,基于过去的帧序列预测下一帧。与前一种方法不同[9],他们的框架还考虑了情况的时间信息。它们通过光流约束来扩展其目标函数,以保留移动目标的运动信息。通过Flownet计算光流[26]。他们利用对抗性训练来区分真实图像和伪图像,以进一步提高未来帧预测的性能。异常情况再次由实际帧和预测帧的PSNR超过预定义阈值来识别。
Reconstructive. Stocco等人提出SelfOracle[84]用于检测安全关键的不当行为,如碰撞和失控事件。该架构使用VAE来重建当前场景的一组先前输入图像,并计算相应的重建误差。在正常数据的训练期间,该模型通过最大似然估计将概率分布拟合到观测到的重建误差。然后可以使用估计的分布来确定阈值θ,以区分异常行为和正常行为。参数ε对应于尾部的概率,因此θ控制检测的假阳性率。此外,SelfOracle通过对重建错误序列应用简单的自回归滤波器来实现时间感知异常评分,因为当前错误可能容易受到单帧异常值的影响。虽然他们只在模拟环境中评估SelfOracle,但这种方法似乎很有前途,甚至优于作者对DeepRoad框架的实现。
最后,目标层面的异常检测严重依赖于人类的驾驶行为。因此,随着道路上自动驾驶汽车的兴起,AD将在行为预测方面经历一个很大的概念漂移。
7. Conclusion
在本文中,我们对自动驾驶领域的异常检测技术进行了广泛的综述。而基于Breitenstein等人的调查[14]建立的模型仅限于相机数据,我们描述了不同传感器模态的技术。最近的大多数进展都与基于图像的异常检测有关,而基于激光雷达和雷达的方法仍在努力获得动力。造成这种情况的一个原因是缺乏基准,迄今为止,基准只存在于相机行业。社区缺少标记异常的常见数据集,这使得检测技术的统一比较变得困难。表1-5显示,每种模态可能更适合于检测一种或仅有几种类型的角落案例,例如,基于激光雷达的技术主要关注单点异常。总体而言,最先进的技术尤其能在场景层面上检测到上下文异常,而集体异常则远远落后。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号