Join the High Accuracy Club on ImageNet with A Binary Neural Network Ticket
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
二值神经网络是网络量化的极端情况,长期以来一直被认为是一种潜在的边缘机器学习解决方案。然而,与全精度方法相比,其显著的精度差距限制了其在移动应用中的创新潜力。在这项工作中,我们重新审视了二值神经网络的潜力,并将重点放在一个令人信服但尚未解决的问题上:二值神经网络如何在ILSVRC-2012 ImageNet上达到关键的精度水平(例如,80%)?我们通过从三个互补的角度增强优化过程来实现这一目标:(1)基于对二值结构及其优化过程的全面研究,我们设计了一种新的二值结构BNext。(2) 我们提出了一种新的知识蒸馏技术,以缓解试图训练极其精确的二值模型时观察到的反直觉过拟合问题。(3) 我们分析了二值网络的数据增强流水线,并使用全精度模型的最新技术对其进行了优化。ImageNet上的评估结果表明,BNext首次将二值模型精度边界提高到80.57%,并显著优于所有现有的二值网络。代码和经过训练的模型可在以下网址获得:(盲URL,见附录)。
1. Introduction
近年来,深度神经网络(DNN)在人工智能研究的几乎所有领域都取得了显著进展。尽管其能力强大,但现代神经网络架构的发展通常伴随着计算预算、内存使用和能耗的增加[10, 14, 21, 29, 44, 46, 47, 51]。另一方面,手机、微型机器人、AR眼镜和自动驾驶系统等常见的边缘计算平台只能提供有限的计算能力和电池寿命。因此,现代神经网络的发展趋势与边缘应用之间存在巨大的技术差距。只有双方共同设计的优化才能最大限度地发挥边缘深度神经网络的潜力。
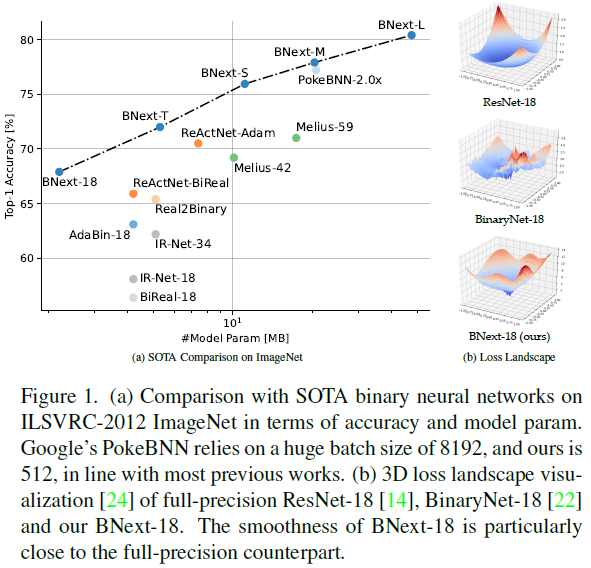
受此启发,研究人员开发了各种技术来压缩和加速现代神经网络(例如,网络剪枝[13]、知识蒸馏[16]、紧凑架构设计[19]、低位量化[2,23])。其中,二值神经网络(BNN)因其在边缘设备上的巨大潜力而受到研究人员的关注[6, 32, 33, 35, 41, 57]。通过将值范围限制为1位(例如,±1),二值量化技术可以将内存需求压缩32倍,并通过用XNOR和位计数操作替换浮点点积,在CPU上实现58倍的理论加速[6, 41]。尽管二值神经网络具有明显的效率优势,但长期以来一直存在优化困难和精度下降问题。先前的工作已经做出了巨大努力,以缩小全精度模型的精度差距,如ResNet-18和ResNet-50[6, 32, 33, 35, 41, 57]。然而,最新的BNN仍然远远落后于最新的全精度传感器,精度降低了约10%[10, 27, 29],这是因为它们的表征能力极度退化(降低了3.4×1038)[49]和优化难度增加。为了解决反向传播中的不可微性问题,BNN训练依赖于梯度估计技术,例如直通估计器(Straight-Through Estimator)[6]。BNN也有一个更粗糙的损失情况,即达到全局最小值的优化路线图比全精度网络更为崎岖(见图1b)。上述问题使BNN的优化变得复杂,因此需要特定的架构设计和优化方法才能获得高度准确的结果。因此,二值神经网络如何在ILSVRC-2012 ImageNet上达到关键精度水平(例如,80%)的问题仍然是一个悬而未决的问题。
在本文中,我们在ILSVRC-2012 ImageNet数据集上构建了BNext,这是第一个精度超过80%的BNN。为了增强表征容量,我们首先构建了一种新型的二值处理单元,该单元具有一种称为Info-RCP的自适应信息重耦合结构。先前的工作[35, 41, 57]利用通道方向缩放来调整每个二值卷积之后的分布。尽管这减轻了二值化导致的信息损失,但这些传统的Real2Binary式设计[35]忽略了二值卷积前后的语义间隙,这导致了次优信息耦合。相反,我们首先通过使用额外的BatchNorm和PReLU层缩放和移动二值卷积输出来减少这种分布差距。然后,我们使用一个轻量级的注意力分支来重塑这个单元的输出分布,该分支将这个二值单元之前和之后的信息作为输入进行组合。随后,通过堆叠多个Info-RCP模块来构建基本BNext块。基于我们对经典二值架构的分析,并受最近视觉Transformer[12, 27]的正则化架构设计的启发,我们提出了一种新的元素式注意力(ELM-Attention)模块,以进一步增强二值基本块。更具体地,每个基本块利用使用乘法的元件旁路来动态校准基本块中的第一信息RCP模块的输出。最后,我们通过使用不同的阶段设计策略堆叠基本块来构建具有不同模型尺寸的BNext族。如图1b所示,与传统的二值ResNet-18相比,BNext-18的损失情况更加平滑和完整,并且非常接近全精度ResNet-18。
优化流水线设计在高精度BNN优化中起着至关重要的作用。与32位DNN相比,BNN拥有更粗糙的损失环境,这为优化全局最小值增加了更多障碍。因此,它需要更细粒度和更灵活的梯度信息来逃避次优收敛。为此,知识蒸馏(KD)是先前工作中常用的技术[30, 32, 35]。然而,当我们试图将BNN的准确度水平从当前的70%提高到80%时,我们观察到,使用标准KD技术,BNN更容易反直觉过拟合。因此,改进教师模型选择和KD流水线设计至关重要。因此,我们提出了一个新的度量,即知识复杂性,作为一个简单而有效的教师模型选择指标。我们进一步使用选定的教师(例如[29, 47]),包括一个主教师模型和一个助理教师组。我们在不同的训练阶段自适应地选择最合适的助理教师,以提高学生的准确性并避免过拟合。助理教师充当高信心预测知识的正则化器。此外,现代DNN[10, 27, 29]通常依赖于精心设计的数据增强流水线。据我们所知,这是第一项彻底验证最近提出的BNN数据增强技术的工作,并基于广泛的实验提供了实践指导。总体而言,如图1a所示,BNext在很大程度上优于所有以前的BNN,是第一个在ImageNet上达到80%准确度水平的二值神经网络。
我们的主要贡献概括如下:
- BNext,一种新颖的二值架构,比现有的流行设计具有更平滑的损失情况,使其更易于优化。
- 多样化连续知识蒸馏技术,它缓解了高精度BNN中的反直觉过拟合问题。
- 基于对最新数据增强技术的公平和全面验证,为BNN提供先进训练流水线。
- 第一个在ImageNet上实现超过80%的顶级精度的BNN,这重塑了我们对BNN潜力的看法。
2. Related Work
BNN Optimization. 二值神经网络很难优化。与32位的神经网络相比,BNN几乎是普遍不可微的。BinaryNet[6]解决了这一挑战,并证明了使用直通估计(straight-through-estimation, STE)技术优化BNN的可行性。后来的工作(例如[11, 25, 33, 52])试图使用STE的不同变体来近似符号函数的梯度,从而改进优化。[15]重新审视了BNN中潜在权重的功能作用,并提出了一种专门的优化器BOP来翻转二值状态。Real2BinaryNet[35]分三个阶段应用知识蒸馏来优化BNN。类似的工作([32, 57])将KD流水线简化为两阶段流程。此外,Liu等人[32]探索了训练策略(例如优化器、权重衰减)如何帮助BNN优化。在本文中,我们首次深入分析了BNN优化与相应架构设计之间的关系。该分析有助于我们理解BNN难以优化的原因以及如何构建高度优化友好的架构。
Knowledge Distillation. 知识蒸馏[16]用于将经过预先训练的教师模型中的暗知识“蒸馏”为学生模型。在最近的研究中,研究人员将注意力转向对这一技术的更深入理解。例如,研究发现,教师和学生的预测分布之间存在惊人的巨大差异,矛盾的是,适合教师的预测分布并不适合学生[45]。Beyer等人[4]表明,某些隐式设计决策会严重影响蒸馏的有效性。Park等人[36]通过建立对学生友好的教师来改进蒸馏过程,并含蓄地揭示了教师和学生之间存在的知识不匹配。同时,现代BNN优化[32, 35, 57]严重依赖于知识蒸馏技术[16, 43]。来自预训练教师的软标签提供了比一个热标签更精细的监督信号。因此,鼓励BNN研究界探索KD技术的最新进展,并将新见解纳入BNN研究。
Modern Neural Network Optimization. 现代深度神经网络[10, 27, 29, 47]在图像分类中的成功不仅依赖于架构设计思想,如注意力机制,还依赖于一系列最新的优化技巧。各种数据增强策略,如MixUp[56]、CutMix[54]、RandAugmentation[7]和Augmentation Repetition[17],被评估为有利于常规32位网络的推广[42]。然而,对于高度精确的BNN,是应该使用常规策略还是应该使用新的BNN特定增强策略仍是一个悬而未决的问题。这项工作首次对BNN的现代优化技巧进行了公平和全面的实证研究,以检查其在大规模图像分类任务中的可行性。详细的消融研究证明了重新审视BNN特定增强策略的必要性,并揭示了可能的解决方案。
3. BNext Architecture Design
在本节中,我们将介绍BNext架构设计的动机和细节。在第3.1节中,我们可视化了最流行的二值神经网络的损失情况,并提供了我们的观察和见解。然后,我们在第3.2节中介绍了BNext架构设计的两个核心模块和BNext模型族的结构。
3.1. Visualizing the Optimization Bottleneck
二值神经网络是由堆叠的1比特卷积构造的轻量级神经网络。在正向传播中,在点积计算之前,使用符号函数将每个1位卷积中的输入![]() 和代理权重
和代理权重![]() 二值化为±1。在反向传播中,符号函数使用hardtanh函数的梯度来近似[22],因此我们可以计算
二值化为±1。在反向传播中,符号函数使用hardtanh函数的梯度来近似[22],因此我们可以计算![]() 的梯度并优化权重
的梯度并优化权重![]() 。在每次迭代期间,
。在每次迭代期间,![]() 的梯度累积在代理权重
的梯度累积在代理权重![]() 中[6]。该过程可以用数学公式表示如下:
中[6]。该过程可以用数学公式表示如下:
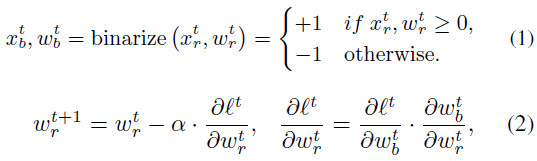
其中![]() ,表示直通估计(STE)策略。r、 b和t分别表示实值变量、二值变量和迭代次数。尽管STE部分解决了不可微问题,但稀疏二值表示和梯度失配问题使BNN遭受严重的精度退化[6, 41]。各种后续设计[3, 32, 33, 35, 41]试图解决BNN的两个核心瓶颈:容量退化和优化困难。为了理解BNN中的优化瓶颈,我们首先关注最流行的BNN架构。具体而言,先前的研究人员已经在BNN中提出了几种有益于性能的结构,例如双残差连接[33]、Real2BinaryNet[35,57]中引入的注意力和自适应分布重塑[32]。然而,这些技术背后的共同见解仍不清楚。
,表示直通估计(STE)策略。r、 b和t分别表示实值变量、二值变量和迭代次数。尽管STE部分解决了不可微问题,但稀疏二值表示和梯度失配问题使BNN遭受严重的精度退化[6, 41]。各种后续设计[3, 32, 33, 35, 41]试图解决BNN的两个核心瓶颈:容量退化和优化困难。为了理解BNN中的优化瓶颈,我们首先关注最流行的BNN架构。具体而言,先前的研究人员已经在BNN中提出了几种有益于性能的结构,例如双残差连接[33]、Real2BinaryNet[35,57]中引入的注意力和自适应分布重塑[32]。然而,这些技术背后的共同见解仍不清楚。
Liu等人[30]通过可视化损失情况,研究了训练策略和优化器对BNN的影响。受此思想启发,我们进一步将其作为指标来分析最流行的二值架构,包括BinaryNet[6]、BiRealNet[33]、Real2BinaryNet[35]及其全精度对应的ResNet-18[14]。我们绘制了每个网络的相应2D损失景观(等高线视图),如图2所示。通过比较图2a和图2b,我们可以看到,直接对网络进行二值化[6]使得损失景观表面非常不连续和崎岖,等高线是非结构化的,并且在图2b中未对齐。高度崎岖的地形表面使BNN更容易收敛为次优最小值,并且对不适当的优化过程更敏感。在图2c中,BiRealNet[33]中提出的双跳连接设计在一定程度上缓解了信息稀疏问题,并允许通过旁路连接实现更连续的信息流。因此,我们可以观察到更加结构化和完整的轮廓,尽管它们仍然显得崎岖不平。Real2BinaryNet[35]建议通过使用可训练注意力模块以数据驱动的方式重塑二进制卷积的输出,从而减少信息瓶颈。与图2b和图2c相比,Real2BinaryNet进一步平坦了全局最小值周围的区域,图2d中每条等高线之间的间隙更均匀,这意味着对初始化和优化更鲁棒。
受可视化中这些发现的启发,我们提出了以下三个假设:(1)激活二值化限制了每个1位卷积层之前可用于前向传播的特征模式。(2) 在二值卷积之后适当地重塑分布对于相邻的1位处理单元之间的特征建模至关重要。(3) 有效的捷径设计提高了BNN正向和反向传播中的信息密度。尽管之前的许多工作基于类似的优化思想[32, 33, 35, 41, 57],但从损失情况来看,与全精度主干相比,它们的优化效果仍然可以提高。这一结论激励我们开发更好的结构设计。
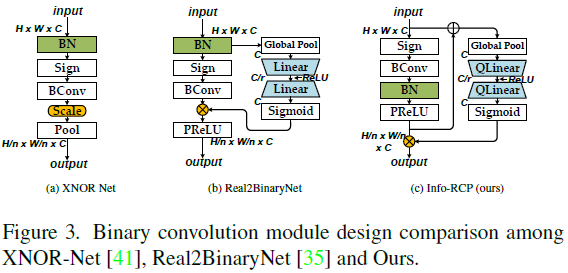
3.2. Building Optimization-Friendly BNNs
本节介绍了BNext网络设计的核心架构组件及其设计思想。
Binary Convolution with Information Recoupling 为了促进信息传播并缓解相邻1位处理单元之间的可能瓶颈,我们构建了一个具有自适应信息整形和耦合的新二值卷积模块,如图3c所示。在前向过程中,二值卷积的输出分布通过随后的批处理范数和PReLU层进行调整。接下来,我们通过移位和缩放设计明确地校准信息流。我们首先使用一个快捷连接,通过元素相加来融合主分支[BConv-BN-PReLU]的输入和输出。输出随后被馈送到一个轻量级的间隙感知挤压和扩展(Squeeze-and-Expand, SE)[20]分支,该分支用于缩放主分支输出。具体而言,主分支之前和之后的两个特征都被视为输入,这使得SE能够感知更多的信息流变化,并通过学习自适应地调整输出分布。在本文的其余部分中,该设计被称为信息重新耦合(InfoRCP)模块。与XNOR Net和Real2Binary Net相比(图3a和图3b),我们的设计提供了一种更加稳健和灵活的卷积后整形机制。我们的消融研究(表4)验证了Info RCP的有效性。同时,我们发现损失景观也变得更加均匀和平滑(图2e),这表明InfoRCP可以有效地促进优化。
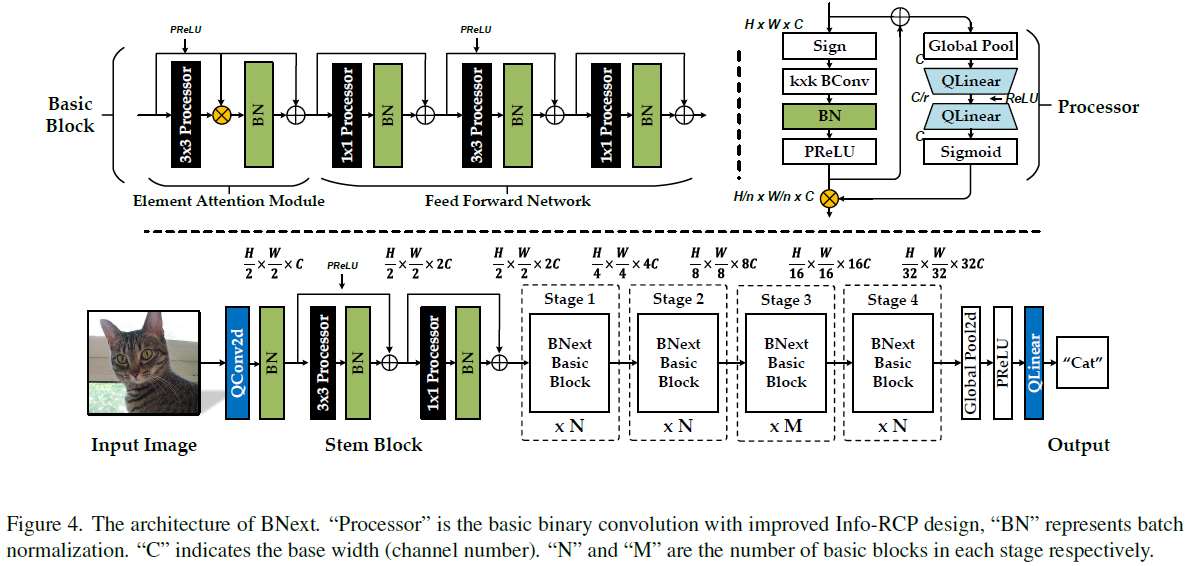
Basic Block Design with ELM-Attention 受第3.1节中的分析和VIT[10, 12, 50]中最近规范化的架构设计思想的启发,我们研究了一种具有增强旁路结构的新型基本模块设计。如图4所示,我们堆叠多个InfoRCP模块(处理器)来构建基本构建块。每个处理器后面跟着一个BatchNorm层。然后,我们使用连续的残差连接来包围每个基本处理器[Info-RCP-BN],这缓解了前向传播中的信息瓶颈。此外,我们利用逐元素旁路乘法来动态校准第一个3×3处理器的输出。元素乘法有助于每个块中的前向特征融合和传播,这可以显著改善损失景观,如图2f所示。最后,通过结合信息RCP和ELMAttension,我们获得了明显更好的损失情况,如图2g所示。它的平滑度已经非常接近全精度主干。
BNext Family Construction 我们通过在不同的阶段设计策略下堆叠基本块来构建BNext系列。为了与现有工作进行公平比较,我们将所提出的块设计应用于流行的主干MobileNetV1,并通过改变每个阶段的块宽度和深度来获得BNext变体。整体BNext系列架构如图4所示。具体来说,我们构建了四个容量不断增加的BNext变体,以测试BNext架构的可扩展性。
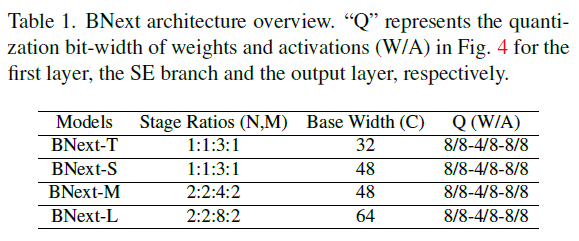
表1显示了BNext网络的配置。C表示输入层的宽度,N和M表示级深比,如图4所示。
4. Knowledge Distillation Strategy
4.1. Knowledge Complexity for Teacher Selection
知识蒸馏(KD)是BNN的基本优化技术[30, 32, 35, 57]。为了在ImageNet上实现80%准确率的目标,我们需要评估哪些教师模型为BNN提供最佳监督。唯一一项研究了教师选择对高精度BNN优化的影响的研究是PokeBNN[57],它使用了高精度VIT教师,而不是ResNet-50[10]。然而,他们报告说,学生模型没有从更准确的老师那里获得准确度,反映出仅仅考虑老师的准确度是不够的。在我们的工作中,我们进行了更全面的调查。如果我们使用更强的全精度教师和标准KD,我们观察到BNext-T和BNext-L上不同程度的过拟合。由于空间的限制,我们在附录(第7.2节)中提供了反直觉过拟合的更多细节。为了解决这个问题,我们提出了一种简单而有效的度量,即知识复杂性(KC),结合了教师选择的准确性和模型紧凑性,以及一种多样化的连续KD方法。
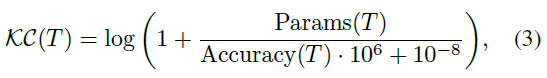
其中T是选定的教师模型,Params是参数的数量,Accuray是教师的测试精度。一般来说,KC定义了教师参数空间复杂性对暗知识有效性的成本。据我们所知,这是第一次针对BNN调查这一问题并提出实际解决方案的工作。
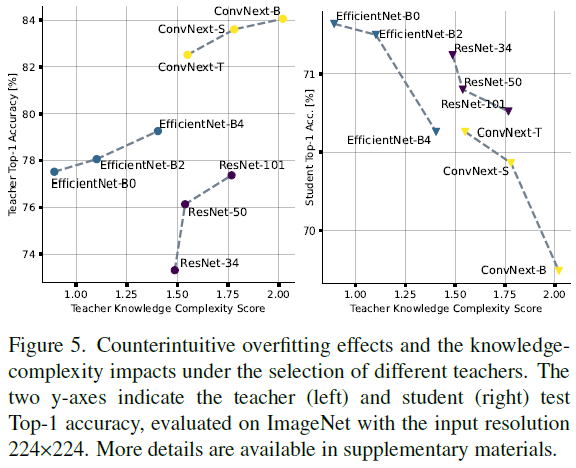
三个流行的DNN族的知识复杂性分析以及相应的教师和学生的top-1准确度如图5所示。BNext-T被用作本研究的学生。作为常识,我们需要一个更强大的老师来控制学生的准确率上限。然而,如图5所示,具有高准确度和高KC的教师很容易导致二值学生出现过拟合问题(学生的top-1准确度显著下降)。一个可能的原因是,在初始训练阶段,用过于复杂的教师训练二值学生时,没有考虑到教师和学生的预测分布之间的巨大差异。在[37]中也获得了类似的观察结果,其中删减的老师比原来的老师工作得更好。因此,我们建议优先选择KC较低的教师进行BNN的KD训练。

4.2. Diversified Consecutive KD
我们开发了一种多样化的连续KD算法(Alg. 1) 进一步提升KD训练的性能。该方法由缺口敏感知识集成和知识提升策略(a gap-sensitive knowledge ensemble and a knowledge-boosting strategy)组成。
A Gap-Sensitive Knowledge Ensemble 我们的核心设计原则是使用知识集成来增加教师知识的多样性。此外,知识集成不是静态的,而是动态地适应知识的难度。为了保证一致的精度上限,我们在训练期间使用相同的强教师![]() 。我们通过增加另一名不太自信的助教
。我们通过增加另一名不太自信的助教![]() 来获得额外的指导,以增强整体知识多样性。二值学生Sθ总是从两位老师那里学习。损失函数的数学公式如下:
来获得额外的指导,以增强整体知识多样性。二值学生Sθ总是从两位老师那里学习。损失函数的数学公式如下:
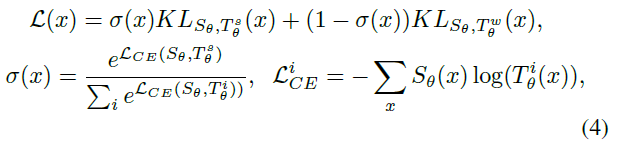
其中CE和KL分别表示交叉熵和KL散度损失[43]。我们计算每个前向传播的学生预测和每个老师预测之间的距离。我们然后使用σ(x)权衡每个知识条目![]() 。因此,我们的动态加权和融合方法限制了容量有限的二值学生S更加关注更复杂的知识。
。因此,我们的动态加权和融合方法限制了容量有限的二值学生S更加关注更复杂的知识。
Knowledge-Boosting Strategy 为了进一步减少BNext-M/L优化中的知识差异,我们开发了一种知识提升策略。如上所述,在整个训练过程中,强教师![]() 是一致的,但辅助教师是从预定义的候选组中选择的。辅助教师将按照准确性和知识复杂性的增加顺序逐一加入KD过程,并具有相同的活动时间长度。通过这种方式,我们在不同的训练阶段使用适应的助手来调整教师知识,从而获得更好的多样性。因此,二值学生可以接收到更多样的监督信息,这些信息具有更鲁棒的正则化,可以有效地解决图5所示的强教师过拟合问题。这是BNext-M/L能够实现如此高精度的重要原因。教师选择规则基于知识复杂性统计。辅助教师组设置的详细说明可在补充材料中找到。
是一致的,但辅助教师是从预定义的候选组中选择的。辅助教师将按照准确性和知识复杂性的增加顺序逐一加入KD过程,并具有相同的活动时间长度。通过这种方式,我们在不同的训练阶段使用适应的助手来调整教师知识,从而获得更好的多样性。因此,二值学生可以接收到更多样的监督信息,这些信息具有更鲁棒的正则化,可以有效地解决图5所示的强教师过拟合问题。这是BNext-M/L能够实现如此高精度的重要原因。教师选择规则基于知识复杂性统计。辅助教师组设置的详细说明可在补充材料中找到。
5. Experiments
在本节中,我们评估了ILSVRC12 ImageNet[8]和CIFAR数据集上的模型和方法。
5.1. Experimental Setups
我们使用AdamW [34]优化器(β1=0.99,β2=0.999),初始学习率为10-3,并且10-3和10-8的权重衰减分别用于非二值和二值参数。我们使用5个epoch的预热来提高学习率,然后使用余弦调度器来降低学习率[38]。我们将STE(Func.1)的反向梯度裁剪范围设置为[-1.5, 1.5]。我们使用硬二值化(Func.1)进行激活和渐进权重二值化,如[11]中所提出的。两种不同的主干网ResNet [14]和MobileNetV1 [19]用于技术评估。该模型在8个Nvidia DGX-A100 GPU上训练。
ImageNet: 我们训练输入分辨率为224x224,512个epoch的批大小为512。RandAugment(7, 0.5) [7]用于增强数据增强。对于BNext优化,我们使用第4.2节所述的多样化连续KD流程,其中ConvNext Tiny [29]作为强教师,[EefficientNet-(B0-B2-B4) [47],ConvNext Tiny]作为候选辅助教师组。
CIFAR: 我们训练批大小为128的模型256个epoch。我们使用标准数据增强随机裁剪、随机水平翻转和归一化[38],并使用交叉熵损失[38]进行优化。CIFAR的结果是五次运行的平均值。
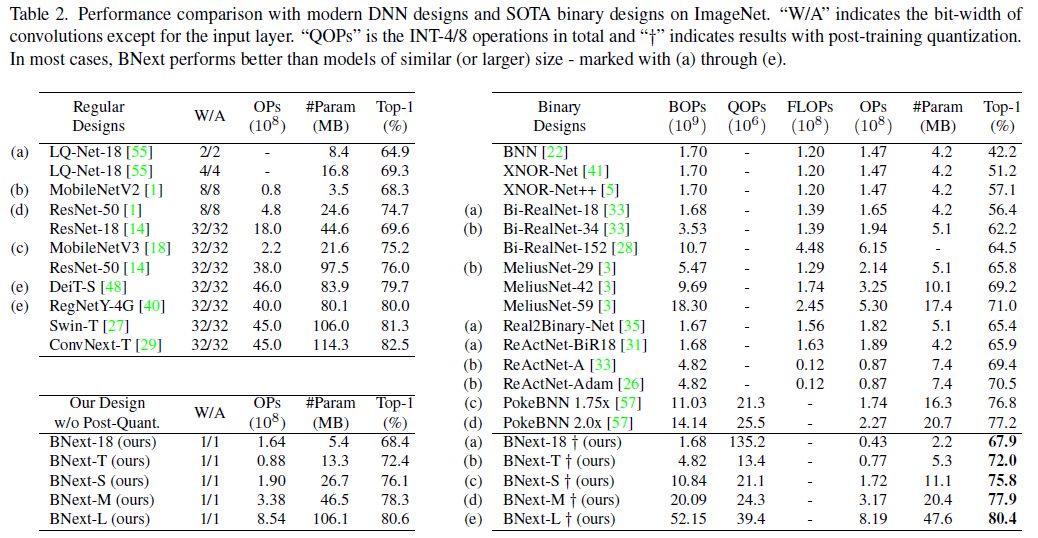
5.2. Performance Evaluation
ImageNet: BNext在ImageNet分类上实现了BNN最新的顶级精度(见表2)。虽然大多数现有的BNN [3, 6, 32, 33, 35, 41, 49]仍然不如32位ResNet-18(69.74%的顶级精度)[14],但BNext-XL将BNN的上限提高到80.57%的关键精度水平。因此,它以10%的精度超过了大多数现有的工作,并实现了接近SOTA 32位设计的结果,如ConvNext [29]、Swin Transformer [27]和RegNetY-4G [40]。与之前的SOTA设计PokeBNN相比,我们的BNext-M在模型尺寸相似的情况下,精度提高了0.7%。BNext架构还依赖于比PokeBNN系列更低的优化要求。PokeBNN在64个TPU-v3芯片上以8192的批大小训练720个epoch[57],而BNext仅使用512个epoch的批大小。与流行的ReActNet[32]设计相比,BNext-Tiny的精度提高了2.6%,操作量减少了10M。为了进一步验证BNext设计的有效性,我们将所提出的技术与ResNet-18主干相结合。我们使用标准的数据扩充,仅ResNet-34作为教师进行公平比较。BNext-18在ImageNet数据集上实现了68.4%的top-1精度,仅比原始ResNet18 [14]低1.2%。同时,性能高于所有现有设计,如BNN [6]、XNOR-Net [41]、BiRealNet [33]、Real2BinaryNet [35]和ReActNet-BIR18 [33]。为了公平比较,我们对OP的计算排除了可忽略的浮点计数[3, 30, 32, 33, 57]。
CIFAR: 我们进一步探讨了BNext(具有ResNet-18主干)在较小数据集CIFAR10上的泛化能力(见表3)。与AdaBNN [49]、ReCU [53]和RBNN [25]等最新设计相比,BNext实现了最佳性能。它超过了最新的作品之一AdaBNN 0.5%,并将32位ResNet的差距缩小到0.8%。补充材料中提供了对CIFAR100的完整评估。
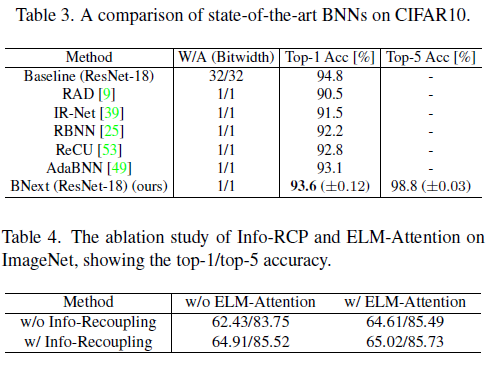
5.3. Ablation Study
我们在详细的消融研究中评估了本文中提出的技术对所提出的模块设计、优化方案、数据增强策略和量化后影响的影响。我们使用BNextTiny进行所有实验,只有标准数据增强和模型训练的交叉熵损失(除非另有说明)。
Module Designs. 我们在表4对所提出的Info-RCP和ELM-Attention模块进行了消融研究。没有这两种结构的基准模型在ImageNet上仅达到62.43%。仅将ELM-Attention添加到BNext-Tiny可将准确率提高到64.91%。仅将Info-RCP添加到BNext-Tiny中可将准确率提高到64.61%。添加两种设计可获得65.02%的最高准确率。因此,两种设计都增强了表征能力,这证实了图2中损失景观比较所提出的期望。
Optimization Schemes. 我们在表5中评估了实验中使用的所有优化方案的有效性。以ResNet-101 [32]为教师的传统知识蒸馏策略被用作骨干。用基于KC(x)(Func.3)的教师选择(Efficient-B0)代替教师将准确率提高了0.57%。这揭示了教师选择在二值网络优化中的重要性。使用间隙敏感集成(Func.4) Efficiency-B0和Efficiency-B2的性能提高了0.05%。通过添加Rand Augmentation[7],进一步实现了0.08%的精度增益。将训练epoch扩展到512,将准确率提高到72.40%。
Data Augmentations. 我们验证了现有流行数据增强的有效性,如Mixup[56]、Cutmix[54]、Augment-Repeat[17]和Rand Augmentation[7]。结果如表6所示。大多数流行的选择[10, 27, 29]对BNext模型优化有害。例如,Augment-Repeat[17]将top-1精度降低了10.08%。Rand Augmentation和Mixup分别提高了泛化能力,但将它们组合在一起会产生次优结果。仅应用Rand Augmentation可实现2.49%的最佳改进。
Quantization Impacts. 我们将训练后量化应用于输入卷积层、输出全连接层和每个SE分支中的层(表7)。在没有量化的情况下,BNext-L达到了80.57%的top-1精度。将8位量化应用于所有层的权重和激活仅将精度略微降低至80.47%。此外,将SE分支中权重的位宽降低到4位(具有8位激活)实现了最终的BNext-L模型,其分类性能80.37%top-1精度仍然高于80%。
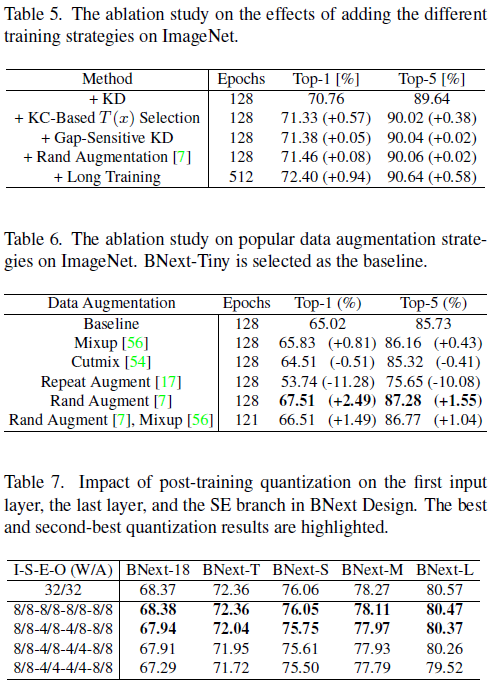
6. Conclusion
在本文中,我们提出了第一个二值神经网络架构,BNext,它在ImageNet上实现了80.57%的Top-1精度。这是通过使用新的Info-RCP和ELM-Attention模块增强优化过程来实现的。更平滑的损失情况和增强的优化允许更好地拟合训练数据,甚至显示出轻微的过拟合,这在以前的BNN架构中是不可能的。为了提高泛化能力并减少任何过拟合,我们提出了多样化连续KD,并在这个过程中发现了一些有趣的现象。ImageNet上的高精度结果表明,BNext作为表征学习的强大特征提取器是足够有效的。
7. Appendix
在本节中,我们提供了更详细的可视化结果和消融研究,由于篇幅有限,这些结果未在主要论文中列出。
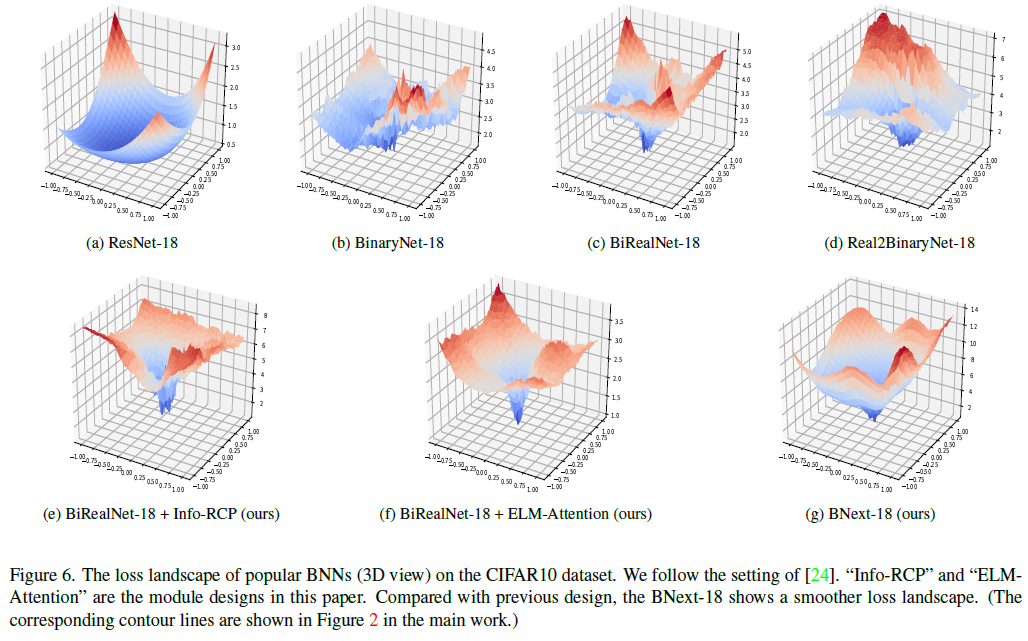
7.1. 3D Loss Landscape Visualization
我们在现有的二值架构设计上使用损失景观可视化技术,如BinaryNet [6]、BiRealNet [33]、Real2BinaryNet [35]及其全精度对应的ResNet-18 [14]。我们绘制了每个网络的相应3D损失景观,如图6所示。它还显示了单独设计的模块(Info-RCP和ELM-Attention)的3D视图以及我们的完整BNext设计(使用两个模块)。很容易看出,二值化使损失的景观表面非常粗糙,但我们的设计可以缓解二值化的问题。因此,BNext的损失景观表面已经接近之前的全精度设计。这解释了为什么BNext可以达到更高精度的边界。
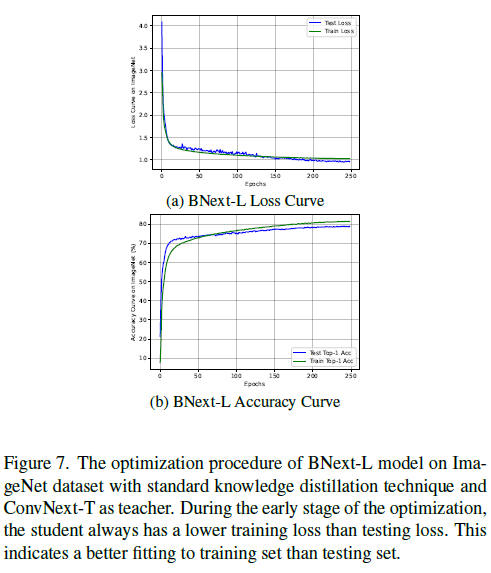
7.2. Counter-Intuitive Overfitting
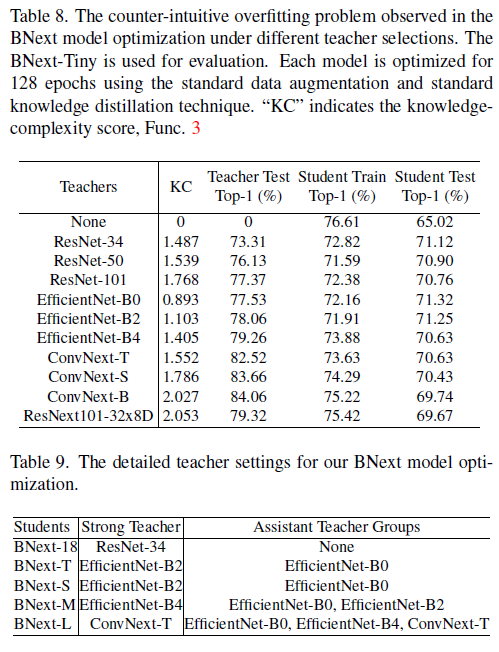
正如在主要工作中所解释的,知识蒸馏长期以来一直是优化二元神经网络的重要选择。当我们将优化目标从70%级别移动到80%级别的二值神经网络时,不可避免地需要从更高精度的预训练深度神经网络寻求帮助。更具体地说,我们需要决定哪个模型最适合作为优化高精度BNN的教师,例如BNext。我们根据经验从几个流行的深度神经网络家族中选择教师,例如ResNet、EfficientNet和ConvNext。在这个过程中,我们观察到BNext设计很容易过拟合强大且高度准确的教师。在表8中,我们可以看到,当作为教师的高准确率全精度模型导致学生模型的高训练精度,但不能很好地泛化,甚至在验证数据上表现更差。例如,当ConvNext Base用作BNextTiny的老师时,学生训练的准确率比使用EfficientNet-B0作为老师高3%,但测试的准确率低1.58%。
对于更大的学生,如BNext-M/L,即使模型容量增加,这种过拟合现象仍然存在。以我们最大的模型BNext-L为例:简单地将标准知识蒸馏与强大的教师ConvNext-T相结合,就会产生一个具有次优泛化能力的学生。从图7中的优化过程可以看出,在训练过程的早期阶段,测试损失总是高于训练损失。同时,与训练曲线相比,测试集上的性能不太稳定。当达到78%的相同测试准确率时,标准KD下的训练准确率已经达到80.23%,这几乎比最终版本的多样化连续KD高出4%。经过256个epoch的训练后,测试集的评估结果比表7中多样化的连续KD结果低1.67%。图7所示的过拟合验证了重新设计BNext优化流水线的必要性。
7.3. Detailed Teacher Selection for BNext Family Optimization
7.4. BNext Model Training Procedure
7.5. BNext Post-Quantization Details
7.6. Detailed CIFAR Evaluation Results
7.7. Code
7.8. Limitations


 浙公网安备 33010602011771号
浙公网安备 33010602011771号